一种面向传感器动态增加的行为识别模型更新方法及系统与流程
该发明涉及普适计算、增量学习技术和行为识别领域,特别涉及一种面向传感器动态增加的行为识别模型更新方法及系统。
背景技术:
近年来,大量研究表明执行日常行为的能力是人类身体健康的重要指标。实时、准确的行为识别可以有效监测人们的日常运动,为老年人提供跌倒预警等。微型、可穿戴式传感器件的诞生与发展为日常行为监护提供了新的途径。其体积小、功耗低等特性使得长时间、实时的行为识别成为可能。随着可穿戴设备的日益普及,用户的可穿戴设备数量会不断增加从而导致可用于行为识别的传感器数目不断增加。如何利用少量具有新传感器的数据提升原有模型的识别性能,是可穿戴行为识别中面临的一个重要挑战。
传统的基于传感器的行为识别方法对离线收集到的标定数据建立分类模型。但这些模型无法适应实际应用的变化。随着新型可穿戴设备的出现,更多的传感器可以用来提高行为识别的性能。文献[farseeva,chuats.tweetfit:fusingmultiplesocialmediaandsensordataforwellnessprofilelearning[c]//aaai.2017:95-101.mla]中也提到,多种传感器能够实现更好的行为识别性能。然而,要将一个新的传感器整合到预先训练好的行为识别模型中是十分困难的。新的传感器的出现将导致输入数据的特征维度,即特征种类相应增加,从而导致预先训练的行为识别模型的失效。为了充分利用新传感器采集到的数据,传统方法只能抛弃现有的模型,并重新获取数据训练一个新模型。这种处理方式将导致存储在原模型中的信息和旧数据被抛弃。众所周知,数据标注是一项费时费力的工作。重新训练行为识别模型将会极大地浪费时间和人力。所以,如何调整现有的行为识别模型使其适用于新传感器的出现,同时使用最小的时间和空间成本,是一个巨大的挑战。
针对上述问题,很多学者和研究人员进行了相关研究。专利cn201610182598.x在特征选择方面使用前向序列选择算法得到最佳特征矢量,使用relief-f进行特征增强处理。在模型构建阶段训练得到一个基分类器和3个弱分类器,集成4个分类器对人体行为进行决策。专利cn201710292408.4使用lstm模型对传感器获得的数据进行建模,训练神经网络参数得到识别模型,能够处理相对较少数据的建模,但无法应对传感器数量动态增加的情况。专利wo2015123373-a1公开了一种行为识别设备。该设备在资源受限环境下利用惯性传感器收集数据,通过提供基于多种因素的额外分析来提高行为识别的准确性。
虽然多种机器学习方法已经成功应用于行为识别领域,但是他们在可塑性和动态适应性方面尚存在一些不足:
1、面对新增传感器,传统行为识别方法由于输入维度不一致导致模型不适用,无法充分利用新增设备采集到的数据,导致资源的极大浪费。
2、为充分利用新增传感器数据,传统行为识别方法需要抛弃已有模型,重新收集数据构建新模型。这种方式虽然能够充分利用所有可穿戴设备检测用户行为,但会造成已有模型知识的浪费以及导致大量的标定工作。
因此,急需设计一种面向传感器数目动态增加的鲁棒的行为识别方法,当可用的传感设备数目动态增加之后,能够以较小的时空代价,利用来自新传感器的数据提升已有模型的精度。
技术实现要素:
针对上述问题,本发明涉及一种面向传感器动态增加的行为识别模型更新方法,包括:模型构建步骤,通过初始传感器获取用户行为的初始数据,并提取初始特征数据以构建行为识别模型;增量特征数据获取步骤,通过该初始传感器和新增传感器获取用户行为的增量数据,定义增量特征并提取增量特征数据;模型更新决策步骤,以该行为识别模型中的决策树预测结果之间的平均互信息,及该预测结果和与其对应的用户实际行为之间的互信息,获得该行为识别模型的每棵决策树的多样性评分,将多样性评分小于更新阈值的决策树作为待更新决策树;模型动态更新步骤,以该增量特征数据更新所有待更新决策树,以实现该行为识别模型的更新。
本发明所述的行为识别模型更新方法,其中模型构建步骤具体包括:以滑动窗口方法处理该初始数据,以得到该初始特征数据;以该初始特征数据构建随机森林分类器,得到该行为识别模型。
本发明所述的行为识别模型更新方法,其中增量特征数据获取步骤具体包括:通过该初始传感器获取用户行为的第一增量数据;通过该新增传感器获取用户行为的第二增量数据;以滑动窗口方法处理该第一增量数据,以得到对应该初始传感器的第一特征数据;以滑动窗口方法处理该第二增量数据,以提取该增量特征并得到对应该新增传感器的第二特征数据;结合该第一特征数据和该第二特征数据以得到该增量特征数据。
本发明所述的行为识别模型更新方法,通过以下方法获得多样性评分:
本发明所述的行为识别模型更新方法,其中模型动态更新步骤具体包括:子树修改步骤,以落入某个待更新决策树的节点的某一该增量特征作为分裂属性,在该节点下构建新的子树;叶子节点分裂步骤,当某个待更新决策树的叶子节点中的用户行为的种类大于1且落入该叶子节点的样本数量大于分裂阈值时,对该叶子节点进行分裂。
本发明还涉及一种面向传感器动态增加的行为识别模型更新系统,包括:模型构建模块,用于通过初始传感器获取用户行为的初始数据,并提取初始特征数据以构建行为识别模型;增量特征数据获取模块,用于通过该初始传感器和新增传感器获取用户行为的增量数据,定义增量特征并提取增量特征数据;模型更新决策模块,用于确定行为识别模型的更新过程中的待更新决策树;模型动态更新模块,用于以该增量特征数据更新所有待更新决策树,以实现该行为识别模型的更新。
本发明所述的行为识别模型更新系统,其中所述初始模型构建模块包括:初始数据获取模块,用于以滑动窗口方法处理该初始数据,以得到该初始特征数据;模型构建训练模块,用于以该初始特征数据构建随机森林分类器,得到该行为识别模型。
本发明所述的行为识别模型更新系统,其中所述增量特征数据获取模块包括:增量数据获取模块,用于通过该初始传感器获取用户行为的第一增量数据,并通过该新增传感器获取用户行为的第二增量数据;增量数据处理模块,用于获取该增量特征数据,其中以滑动窗口方法处理该第一增量数据,以得到对应该初始传感器的第一特征数据,并以滑动窗口方法处理该第二增量数据,以提取该增量特征并得到对应该新增传感器的第二特征数据;结合该第一特征数据和该第二特征数据以得到该增量特征数据。
本发明所述的行为识别模型更新系统,其中所述模型更新决策模块通过以下公式获得多样性评分:
本发明所述的行为识别模型更新系统,其中所述模型动态更新模块包括:子树修改模块,用于在待更新决策树下构建新的子树;其中以落入某个待更新决策树的节点的某一该增量特征作为分裂属性,在该节点下构建新的子树;叶子节点分裂模块,用于对待更新决策树的叶子节点进行分裂;其中当某个待更新决策树的叶子节点中的用户行为的种类大于1且落入该叶子节点的样本数量大于分裂阈值时,对该叶子节点进行分裂。
附图说明
图1是本发明实施例的行为识别模型更新方法的工作流程示意图。
图2是本发明实施例的行为识别模型更新方法的流程图。
图3是本发明实施例的构建行为识别模型的流程图。
图4是本发明实施例的获取增量特征数据的流程图。
图5a是本发明实施例的行为识别模型中单棵决策树示意图。
图5b、5c是本发明实施例的行为识别模型决策树生长机制示意图。
图6是本发明实施例的测试精度试验对比示意图。
图7是本发明实施例的训练时间试验对比示意图。
图8是本发明实施例的测试时间试验对比示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图,对本发明提出的一种面向传感器动态增加的行为识别模型更新方法及系统进一步详细说明。应当理解,此处所描述的具体实施方法仅仅用以解释本发明,并不用于限定本发明。
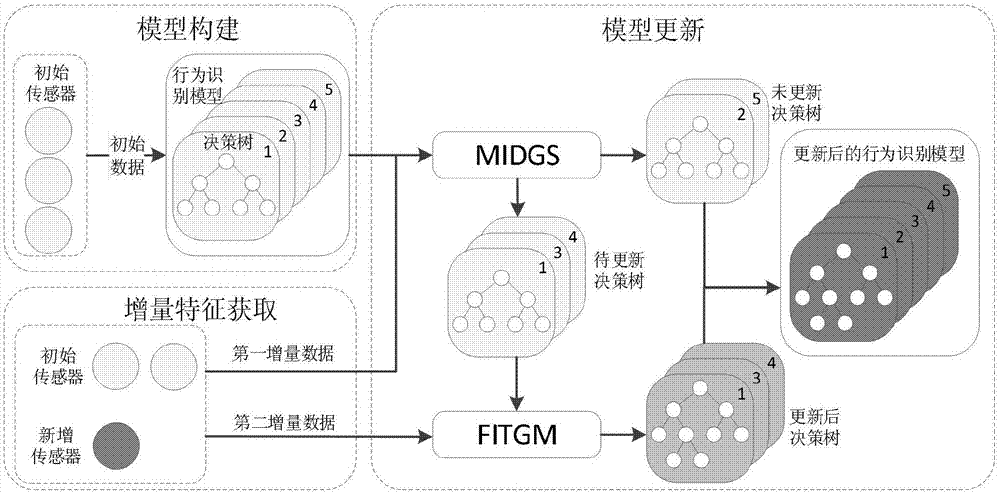
图1是本发明实施例的面向传感器动态增加的行为识别模型更新方法的工作流程示意图。图2是本发明实施例的行为识别模型更新方法的流程图。请参阅图1,首先现有的传感器(初始传感器)采集到一个用户或用户群的行为数据作为初始数据,以构造行为识别模型用于用户行为的识别;在行为识别模型后续使用过程中,通过已有的初始传感器和新加入的传感器(新增传感器)获取一个用户或用户群的行为数据作为增量数据,定义增量特征并提取增量特征数据;根据基于互信息的多样性生成策略判断行为识别模型中的哪些决策树需要更新,以确定待更新决策树;对待更新决策树使用特征增量树生长机制进行更新,以更新行为识别模型。具体步骤如图2所示:
步骤s1,构建用户的行为识别模型;
步骤s2,获取增量特征数据;
步骤s3,选取待更新决策树,以增量特征数据更新行为识别模型。当用户传感器数量增加时,跳回步骤s2继续进行行为识别模型的更新。
一、构建行为识别模型
本发明行为识别模型构建过程采用智能硬件设备内置的加速度传感器、陀螺仪等收集到的数据进行行为识别模型构建。
图3是本发明实施例的构建行为识别模型的流程图。如图3所示,行为识别模型构建步骤具体包括:
步骤s11,读取初始传感器(加速度计,陀螺仪等)的包含用户行为类别的行为数据作为初始数据;
步骤s12,利用滑动窗口方法滑动截取的固定时间长度(如5秒)的初始数据,通过预处理算法对每一个窗口数据进行处理,预处理算法包括但不限于数据滤波等;
步骤s13,对预处理得到的数据使用滑动窗口进行截取,相邻窗口间有50%的重叠,每个窗口提取到的特征包括但不限于:均值,标准差,最小值,最大值,众数,区间,过均值点次数,直流分量,快速傅里叶变换后的峰值、均值、标准差能量熵等;
步骤s14,将提取的特征与用户行为类别组合成初始特征数据以供构建随机森林分类器使用;
步骤s15,训练初始随机森林模型,设置树为100棵,每棵树最少划分2个节点,得到行为识别模型。
二、获取增量特征数据
图4是本发明实施例的获取增量特征数据的流程图。如图4所示,行为识别模型构建步骤具体包括:
步骤s21,读取初始传感器(加速度计,陀螺仪等)的包含用户行为类别的行为数据作为第一增量数据;
步骤s22,读取新增传感器(加速度计,陀螺仪等)的行为数据包含用户行为类别的行为数据作为第二增量数据;
步骤s23,利用滑动窗口方法滑动截取的固定时间长度(如5秒)的第一增量数据,通过预处理算法对每一个窗口数据进行处理,预处理算法包括但不限于数据滤波等;对预处理得到的数据使用滑动窗口进行截取,相邻窗口间有50%的重叠,每个窗口提取到的特征包括但不限于:均值,标准差,最小值,最大值,众数,区间,过均值点次数,直流分量,快速傅里叶变换后的峰值、均值、标准差能量熵等;将提取的特征与用户行为类别组合成第一特征数据
步骤s24,以步骤s23的方法处理第二增量数据,获得第二特征数据,同时获得第二增量数据的增量特征;
步骤s25,将第一特征数据和第二特征数据结合,得到增量特征数据以供更新行为识别模型使用。
三、行为识别模型更新
图5a是本发明实施例的行为识别模型单棵决策树示意图。如图5a所示,行为识别模型可以对初始传感器的用户行为数据进行识别,但通过新增传感器获得增量行为数据后,行为识别模型无法利用新增传感器数据提升已有模型的行为识别性能,需要进行模型的动态更新,模型动态更新主要包括基于互信息的多样性生成策略和特征增量树生长机制。
(一)基于互信息的多样性生成策略
为了提升集成分类器中决策树的多样性,本发明提出了一种基于互信息的多样性生成策略。
在多样性生成的过程中,如何度量个体学习器对集成分类器多样性发挥的作用是一个重要的挑战。为此本发明提出了一个新的多样性评分规则—基于互信息的多样性评分规则。其能够同时考虑到单个分类器的精确度和冗余性。
在信息论领域,互信息被提出用于度量两个变量间相关性:
i(x1,x2)的值越大意味着x1和x2的相关性更高。
同样地,可以利用互信息进行多样性度量,i(hi,y)可以用来度量第i棵决策树的预测结果与用户的实际行为之间的相关性,i(hi,hk)可以用来度量第i棵决策树的预测结果和第k棵决策树的预测结果之间的冗余度。基于互信息的多样性评分规则可以形式化如下:
其中s(hi)为行为识别模型中的第i棵决策树的多样性评分,
(2)式中的第一项i(hi,y)表示第i棵决策树的输出与样本真实类别的互信息,用于度量相关性,其值越大,证明第i棵决策树的精度越高。
(2)式中的第二项
则根据公式(2)可知,s(hi)值越大,表示第i棵决策树的具有较高的精度,并且与其他决策树的冗余度较低。因此,本发明选择s(hi)值小的决策树作为需要更新的决策树,其余决策树保持不变。通过该策略,可在保证集成分类器识别精度的基础上,最大化决策树之间的差异性。这种集成多样性度量策略即为基于互信息的多样性生成策略(midgs)。
要想最大化集成学习器的多样性,选出合适比例的决策树来进一步更新是非常重要的。本发明提出了两种确定进一步更新的决策树比例的方法。方法一是根据s的值对决策树进行排序,然后选择一定比例的决策树进行进一步生长。另一种方法是定义一个指定的更新阈值。s的取值小于这个更新阈值的决策树(待更新决策树)被选择进行更新。对待更新决策树进行更新后,将更新后决策树与未更新决策树结合,以得到更新后的行为识别模型。
(二)特征增量树增长机制
图5b、5c是本发明实施例的行为识别模型决策树生长机制示意图。决策树的精度越高,集成分类器的性能也越好。因此本发明针对由midgs策略得到的需要更新的决策树提出了一种增量树生长机制,如图5a所示,利用新增传感器数据提升现有随机森林行为识别模型,即特征增量树增长机制(fitgm),增量树生长机制包括两种树结构操作。图5b和图5c给出了fitgm两种操作的图示。
1、对子树进行修改
随着新传感器的出现,相应的会得到一些新的特征。当一个新的特征在某个决策树节点取得更好的评分,那么我们就抛弃当前的划分以及当前节点的子节点并以新特征作为分裂属性,重新构建新的子树,如图5b所示。常用的评分方法有信息增益和基尼系数,信息增益是特征选择中的一个重要指标,其定义为一个特征能够为分类系统带来多少信息,带来的信息越多,特征越重要;基尼指数用于判断样本的杂乱程度,总体内包含的类别越杂乱,基尼指数就越大。虽然利用新增传感器获得的特征数据(增量特征)更新决策树的子树有提升决策树性能的可能性,但是它也可能会导致更多的时间消耗以及存储在已有树结构中信息的丢失。因此,我们提出两个约束条件来限制对子树的修改:
(1)新增样本数要满足公式3或者公式4;
(2)新特征的评分优于当前划分的评分,即score(fnew)>scorenode。
(1)和(2)同时用来确保对子树的修改得到的收益比丢弃当前子树的开销要大。
其中ninc是增量特征的数据块中包含的样本数,d是节点深度(假定根节点深度为1,其子节点深度为2)。
n≥nnode(4)
其中nnode是已落入当前节点的样例数。
2、分裂叶子节点
在特征增量学习阶段,随着增量数据的到来,数据分布也会发生相应变化。为了适应数据分布的动态变化,本发明采用了类似于orf-saffari[saffaria,leistnerc,santnerj,etal.on-linerandomforests[c]//computervisionworkshops(iccvworkshops),2009ieee12thinternationalconferenceon.ieee,2009:1393-1400.]的决策树在线生长策略,其中当某叶子节点中的用户行为种类大于1且落入叶子节点的新增样本数量大于分裂阈值时,则对叶子节点进行分裂。阈值具体使用时可以自己调整。选择具有最好分裂评分的属性对叶子节点进行分裂,如图5c所示。
三、本发明的相关实验
为了进一步验证本发明提出的面向传感器动态增加的行为识别模型更新方法及系统的有效性以及说明本发明的使用方法,发明人还以运动行为识别为例进行了实验。实验采用加州大学欧文分校(universityofcaliforniairvine)用于机器学习数据库的日常运动行为数据集dailyandsportsactivitiesdataset,以下简称dsads,其中包含4名男性和4名女性共计8名参与者采集的19类日常运动行为。
(一)数据获取
在实验中采用三类传感器:3轴加速度计、3轴陀螺仪、3轴磁力计,分别固定在身体的五个部位:躯干,左右臂,左右腿,即共15个传感器。运动行为主要采集19种,这19种行为主要包括:坐、站、平躺、侧躺、上下楼、站在电梯里、在电梯里走动、在停车场走、在跑步机上以4公里/时的速度行走、在跑步机上以4千米/时的速度在15个倾斜的位置上行走、在跑步机上以8千米的速度跑步、踏步运动、在交叉训练器上训练、在水平位置骑自行车、在垂直位置骑自行车、划船、跳跃、打篮球。
(二)特征提取
从获取到的运动行为数据中提取特征。这些特征包括两大类:(1)时域特征,即在序列随时间变化的过程中,所具有的与时间相关的一些特征,包括均值,标准差,最小值,最大值,众数,区间,过均值点次数(2)频域特征,通常被用来发现信号中的周期性信息:直流分量,快速傅里叶变换后的峰值、均值、标准差、能量熵等。单个传感器提取27维特征,共提取15个传感器的405维特征。
(三)分类
经过特征提取后得到初始分类器所需的特征向量,为了说明本发明方法的有效性,采用常规机器学习方法随机森林重训练模型作为对比实验,采用测试精度和训练时间作为性能测试标准。其中测试精度是指分类正确的样本占所有样本的比例,训练时间是指构建可识别新类的行为识别模型所需的训练时间。实验过程中,选择单个传感器数据提取特征初始分类器,在新增传感器不断出现时分别采用本发明的方法或者使用随机森林进行重训练。实验结果如图6、7、8所示。由图6可以看出,本发明的面向传感器动态增加的行为识别模型更新方法,featureincrementalrandomforest,以下简称firf,在dsads测试集上的测试精度始终高于随机森林方法重训练,randomforest-retrain,以下简称rf-retrain,证明该方法是一种解决传感器数量动态增加的有效方法。由图7可知本发明的方法firf所需的训练时间远远小于rf-retrain,在时间消耗上有明显优势。由图8可知,本发明得到的firf的测试时间基本与rf-retrain一致,甚至更优,可知其构建的模型冗余度低。实验证明,本发明所提出的特征增量随机森林能够利用新增传感器数据更新已有行为识别模型,利用较少的训练时间得到具有较高精度和较低冗余度的行为识别模型。
- 还没有人留言评论。精彩留言会获得点赞!