一种基于智能制造过程的多源异构数据存储方法与流程
本发明涉及数据处理技术领域,特别涉及基于智能制造过程的多源异构数据存储方法。
背景技术:
随着电子信息技术的发展,电子生产企业在生产流水线上安装了越来越多的传感器,为将来的产品故障排查提供数据支撑,也为减少残次品提供了数据支撑。
电子生产流水线上的传感器种类繁多,所产生的数据有结构化、半结构化和非结构化的大量多源异构数据。在多源异构数据的存储上,现有方法有很多不足之处;在进行传感器数据存储时,没有把传感器由于宕机、断电、源器件损坏等导致实时数据缺失的情况和数据存储融合联系在一起。
在对多源异构数据进行存储时,大多数方案以存储和查看的效率为重,在提高存储效率和减少数据存储冗余度方面都表现出色的方法较少。传统的多源异构数据存储方案中,在进行数据存储时,缺少扩展性强、易于表示的多源异构数据关系映射方案;并且很难尽可能的消除语义定义的差异,给多源化异构数据的融合造成了困难。
技术实现要素:
为了克服上述现有技术的不足,本发明提供了一种基于智能制造过程的多源异构数据存储方法,可填补传感器因各种原因导致的缺失数据,保证数据采集的完整性。
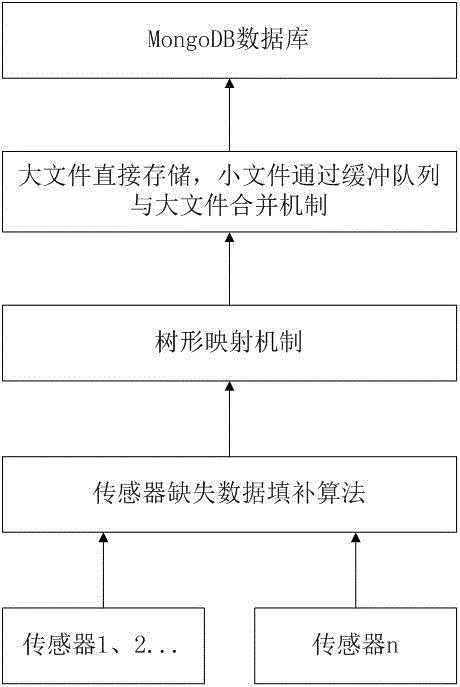
通过使用mongodb存储结构化、半结构化文件,音频、视频采用mongodb内置的gridfs文件系统进行存储。
针对多源异构数据存储创建树形映射方案,使得多源异构数据在存储上具有良好的扩展性。
使用大文件直接存储、小文件通过缓冲队列与大文件合并的方法;这种方法增加了存储率,减少了存储空间浪费。
通过存储传感器数据时做出缺失数据填补的方式确保传感器数据完整的存储。
根据树形映射机制,将不同传感器数据放在不同的块中进行存储;父节点表示子节点的语义以及相互映射关系;这种存储方式,给多源异构数据的存储增加了扩展性,提高了访问效率和存储效率。
叶子节点通过大文件直接存储方式存储;小文件通过缓冲队列存储的方式进行数据的存储;降低了存储空间的冗余度。
附图说明
图1为基于智能制造过程的多源异构数据存储方法图。
图2为传感器缺失数据填补流程图。
图3为树形映射结构方案图。
图4为大文件直接存储,小文件通过缓冲队列与大文件合并流程图。
图5为多源异构数据存储方案图。
具体实施方式
针对智能制造生产线上传感器传输中断、宕机所产生的数据不完整问题,引入了一种面向统一数据模型的缺失数据填补算法。
该算法采用改进的混沌遗传优化方法估计不完整数据的均值和协方差对应的最佳参数;再根据已知数据利用改进(mcmc)方法估计缺失数据,解决了调控数据中的缺失问题。
该算法能通过较少的迭代次数获得最优的缺失数据解值;通过算法的计算使缺失数据的估计值更加准确,有效的保证了数据的准确性和完整性。
针对手机生产线上产生的多源异构数据数据库,选取mongodb数据库进行存储;音频、视频采用mongodb内置中的gridfs文件系统进行存储;片键使用哈希片键。
进行数据存储时,产品为根节点,传感器名称作为子节点,实际存储的数据作为叶子节点;比如温湿度传感器,它的叶子节点就是实际存储的数据。根节点数据用来表示其与子节点之间的映射关系;子节点数据用来表示它与叶子节点的映射关系。
叶子节点通过大文件直接存储,小文件通过缓冲队列进行存储的方式进行数据的存储;为了减少存储空间的冗余,大文件直接存储,小文件通过缓冲队列与大文件进行合并。
实现时,考虑存储结构一个块空间大小;大文件的定义为,大于等于块大小的一半;小文件定义为小于块大小的一半。
进行文件存储时,先通过文件大小判断语句,判断当前要存储的文件是否为大文件;如果是大文件则直接选择新的空块进行存储;如果是小文件,首先将小文件和已存储的大文件块大小进行相加判断。
若此小文件和已有大文件块空间相加后超过块大小,则此小文件暂时存放在缓冲队列中;为了避免缓冲队列过长增加存储时间,缓冲队列设定为10个文件;当小文件再次到来时,先进行小文件与已有大文件块占据空间总和进行计算;若合并后空间没有超过块大小则合并,若超过则将小文件加入缓冲队列;再用缓冲队列中的小文件进行存储判断;找到当前适合合并的小文件就进行合并。
与现有技术相比,本发明的优点有以下四点。
通过传感器数据缺失填补算法,在保证传感器数据不缺失的情况下进行数据的存储。
在确保了数据完整性的情况下,使用树形映射结构进行存储;叶子节点存放对应类型的数据,子节点存放子节点与叶子节点的映射关系,根节点存放根节点与子节点的映射关系;这样利于数据的表示和存储;增加了多源异构数据存储的扩展方便性。
针对手机生产线上产生的多源异构数据数据库,选取mongodb数据库进行存储;音频、视频采用mongodb内置的gridfs文件系统进行存储;片键使用哈希片键;使得存储、简单方便、快速。
对于同类型数据通过大文件直接存储;小文件通过缓冲队列和大文件进行的合并;这种方法增加了存储空间的利用率。
技术特征:
技术总结
本发明属于数据处理技术领域,具体涉及一种基于智能制造的多源异构数据存储方法。该方法包括以下步骤:多源异构数据采集;引入传感器缺失数据填补算法确保存储数据完整;选择可以有效存储多源异构数据的数据库;根据创建的树形映射方法进行多元异构数据存储映射;根据提出的大文件直接存储小文件通过缓冲队列与大文件进行合并方法进行多元异构数据的存储。本发明公开了一种基于智能制造的多源异构数据存储方法,其具体有以下有益效果:确保传感器数据无缺失存储;树形映射机制更加清楚表述数据之间相互关系,增加了异构数据存储的扩展性,方便查找和存储;大文件直接存储,小文件通过缓冲队列与大文件合并存储减少了存储空间浪费。
技术研发人员:王忠民;樊武东;贺炎;宋国豪;陈彦萍
受保护的技术使用者:西安邮电大学
技术研发日:2018.04.11
技术公布日:2019.10.25
- 还没有人留言评论。精彩留言会获得点赞!