面向软件项目的多源异构数据自动收集方法及系统与流程
本发明涉及信息收集技术领域,尤其涉及面向软件项目的多源异构数据自动收集方法及系统。
背景技术:
现有的计算机软件研究中,主要是使用开源软件项目的相关数据,而这些开源软件数据主要是通过以下方法收集的:
一,对于不同项目不同类型的软件项目数据,分别编写爬取程序获取资源。软件研究人员需要人工确定数据在互联网上的地址以及数据源的获取接口,最后根据这些信息编写相对应的爬取程序将数据获取下来。
二,使用通用的网页爬虫框架进行数据抓取。互联网网页爬虫技术较为成熟。网页爬虫利用网页页面中的超链接收集并下载互联网站点中的网页文件。开源社区中有许多成熟的开源爬虫项目可供扩展和使用,如apache开源社区下的nutch项目等。
但是,上述开源软件项目相关的数据收集方法存在以下问题:
(1)对于第一种类型,扩展性差。研究人员需要对于不同数据源的数据类型编写不同的爬取程序。在已有的工作中也有解决数据收集问题可复用的通用方法。但是其中每个不同的爬取模块的入口依然需要研究人员人工查找,针对不同项目的相同类型数据依然需要人工手动提供接口。
(2)对于第二种类型,适用范围有限,通用的网络爬取程序只能收集网页或其他文本文件类型数据,其不适用于结构化的开源数据。而在软件项目数据收集的过程中,现有的爬虫框架无法满足开源软件项目数据结构和数据接口的多样性。
由于现有技术中并不存在一个同时解决已知数据类型和未知数据类型的针对多项目多类型的数据收集问题的自动化方法。因此,研究一种更好的面向软件项目的多源异构数据的数据自动收集方法十分必要。
技术实现要素:
本发明的目的是提供面向软件项目的多源异构数据自动收集方法及系统,该方法及系统能够收集不同类型的数据,扩展性强,可适用范围广。
针对上述目的,本发明所采用的技术方案为:
面向软件项目的多源异构数据自动收集方法,其步骤包括:
1)根据用户输入的软件项目名称及url,并利用通用的基于广度优先的网页爬虫方法,对与该软件项目相关的多个站点中的所有web页面进行爬取;
2)当上述爬取的web页面中的url是已知的数据类型的数据入口地址时,根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,并调用对应的爬取方法进行数据爬取;其中所述调用对应的爬取方法进行数据爬取包括以下步骤:
2-1)对上述创建的多个数据爬取任务进行调度;
2-2)当系统资源足够时,对每个数据爬取任务分配系统资源,并构建存储目录;
2-3)爬取上述每个数据爬取任务中的url目录,并将url目录进行划分;
2-4)根据上述划分的url目录创建多个子线程,并进行多线程数据爬取;
2-5)当上述所有子线程数据爬取结束后,释放系统资源;
3)对上述爬取的数据进行解析并存储到数据库中。
进一步地,步骤2)中判断上述爬取的web页面中的url是否是已知的数据类型的数据入口地址包括以下两个步骤:
1)调用detect方法判断上述爬取的web页面中的url是否是已知的数据类型的资源页面对应的地址,若是则过滤掉以提高爬取效率,否则继续对该web页面中的url进行判断;
2)调用detectentry方法判断上述过滤后得到的web页面中的url是否是已知的数据类型的数据入口地址,若是则根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,否则继续利用上述通用的基于广度优先的网页爬虫方法进行爬取。
进一步地,步骤2)中所述数据爬取任务包括软件项目相关信息以及需要爬取的数据类型;其中所述软件项目相关信息包括软件项目名称、软件项目爬取开始时间、软件项目url。
进一步地,步骤2-2)中所述存储目录包括存储文件目录和爬取任务记录;其中所述存储文件目录是指“软件项目名称/资源名称”形式的文件目录;所述爬取任务记录包括软件项目名称、数据类型、存储地址、任务状态。
面向软件项目的多源异构数据自动收集系统,包括多任务多线程数据爬取模块、多源异构软件项目数据自动收集模块和数据解析存储模块;
所述多任务多线程数据爬取模块用于对多个数据爬取任务进行统一的调度,并对不同类型的数据实现不同的爬取方法,以根据不同数据类型的数据入口地址自动调用不同的爬取方法对不同类型的数据爬取任务进行数据爬取;
所述多源异构软件项目数据自动收集模块用于根据用户输入的软件项目名称及url自动化探测该软件项目数据的数据类型及其对应的数据入口地址,并根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,在所述多任务多线程数据爬取模块中调用对应的爬取方法对数据进行收集;
所述数据解析存储模块用于对所述多源异构软件项目数据自动收集模块收集的数据进行解析并存储到数据库中。
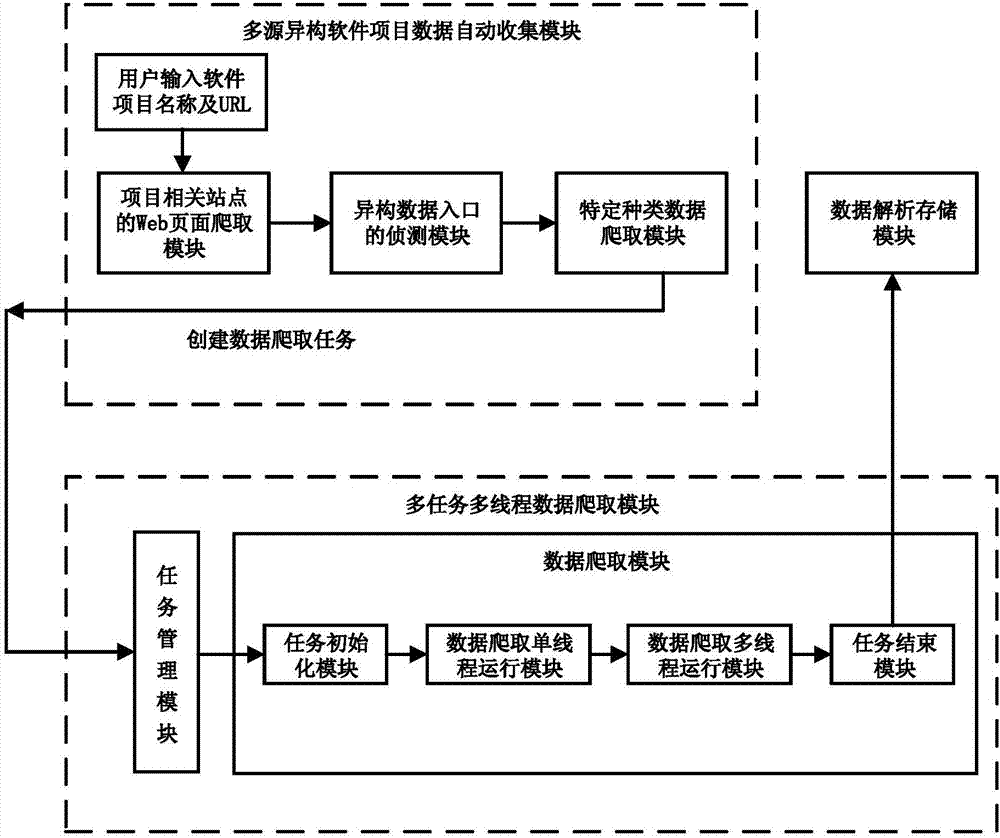
进一步地,所述多任务多线程数据爬取模块包括任务管理模块和数据爬取模块;其中所述数据爬取模块包括任务初始化模块、数据爬取单线程运行模块、数据爬取多线程运行模块和任务结束模块;
所述任务管理模块用于对多个数据爬取任务进行统一的调度;
所述任务初始化模块用于为上述每个数据爬取任务分配系统资源,并构建存储目录;
所述数据爬取单线程运行模块用于爬取上述每个数据爬取任务中的url目录,并将url目录进行划分;
所述数据爬取多线程运行模块用于根据上述划分的url目录创建多个子线程,并进行多线程数据爬取;
所述任务结束模块用于对上述所有子线程数据爬取结束后释放系统资源,并记录所述数据爬取模块的结束状态。
更进一步地,所述任务结束处理模块还用于对所述数据爬取模块发生异常结束处理时进行异常错误处理。
进一步地,所述多源异构软件项目数据自动收集模块包括项目相关站点的web页面爬取模块、异构数据入口的侦测模块和特定种类数据爬取模块;
所述项目相关站点的web页面爬取模块用于根据用户输入的软件项目名称及url,并利用通用的基于广度优先的网页爬虫方法,对与该软件项目相关的多个站点中的所有web页面进行爬取;
所述异构数据入口的侦测模块用于对上述爬取的web页面进行判断,如果该web页面中的url是已知的数据类型的数据入口地址,则将该数据类型的数据入口地址分发到对应的特定种类数据爬取模块;
所述特定种类数据爬取模块用于根据从所述异构数据入口的侦测模块获取的已知的不同数据类型的数据入口地址,创建其对应的数据爬取任务,并在所述多任务多线程数据爬取模块中调用对应的爬取方法进行数据爬取。
更进一步地,所述异构数据入口的侦测模块中的判断方法包括以下两个步骤:
1)调用detect方法判断上述爬取的web页面中的url是否是已知的数据类型的资源页面对应的地址,若是则过滤掉以提高爬取效率,否则继续对该web页面中的url进行判断;
2)调用detectentry方法判断上述过滤后得到的web页面中的url是否是已知的数据类型的数据入口地址,若是则分发到对应的特定种类数据爬取模块,否则继续利用上述通用的基于广度优先的网页爬虫方法进行爬取。
更进一步地,所述特定种类数据爬取模块爬取的数据类型包括邮件、文档、代码、bug信息、版本控制信息;其中每种数据类型都有其对应的数据入口地址,并根据不同的数据入口地址分别实现detect方法、detectentry方法和对应的数据爬取任务创建程序。
本发明的有益效果在于:本发明提供面向软件项目的多源异构数据自动收集方法及系统,该系统首先通过多任务多线程数据爬取模块对多个数据爬取任务进行统一的调度,并对不同类型的数据实现不同的爬取方法,以根据不同数据类型的数据入口地址自动调用不同的爬取方法对不同类型的数据爬取任务进行数据爬取;之后多源异构软件项目数据自动收集模块利用其提供的一种软件项目数据自动收集机制以根据用户输入的软件项目名称及url自动化探测该软件项目数据的数据类型及其对应的数据入口地址,并根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,在所述多任务多线程数据爬取模块中调用对应的爬取方法对数据进行收集。本发明的优点具体包括:
1.能够自动收集不同来源不同类型的软件项目数据,通用性强,扩展性强。
2.对异构数据使用了多任务多线程数据爬取模块,使得针对不同类型数据的爬取可以在多任务多线程数据爬取模块中进行调度,提高了爬取效率。
3.有效减少了数据的重复收集,大大提高了资源使用率。
附图说明
图1为本发明提供的面向软件项目的多源异构数据自动收集方法示意图。
图2为本发明一种多任务多线程软件项目数据爬取方法流程图。
图3为本发明提供的面向软件项目的多源异构数据自动收集方法流程图。
具体实施方式
为使本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合所附图作详细说明如下。
本发明提供面向软件项目的多源异构数据自动收集方法,如图1所示,该方法步骤包括:
1)项目相关站点的web页面爬取模块根据用户输入的软件项目名称及url,并利用通用的基于广度优先的网页爬虫方法,对与该软件项目相关的多个站点中的所有web页面进行爬取;
2)异构数据入口的侦测模块对上述爬取的web页面进行判断,如果该web页面中的url是已知的数据类型的数据入口地址,则将该数据类型的数据入口地址分发到对应的特定种类数据爬取模块;
3)特定种类数据爬取模块根据从所述异构数据入口的侦测模块获取的已知的不同数据类型的数据入口地址,创建其对应的数据爬取任务,并在所述多任务多线程数据爬取模块中调用对应的爬取方法进行数据爬取;其中在所述多任务多线程数据爬取模块中调用对应的爬取方法进行数据爬取包括以下步骤:
3-1)任务管理模块对上述创建的多个数据爬取任务进行调度;
3-2)当系统资源足够时,任务初始化模块对每个数据爬取任务分配系统资源,并构建存储目录;
3-3)数据爬取单线程运行模块爬取上述每个数据爬取任务中的url目录,并将url目录进行划分;
3-4)数据爬取多线程运行模块根据上述划分的url目录创建多个子线程,并进行多线程数据爬取;
3-5)任务结束模块对上述所有子线程数据爬取结束后,释放系统资源;
4)数据解析存储模块对上述爬取的数据进行解析并存储到数据库中。
所述数据爬取任务包括软件项目相关信息以及需要爬取的数据类型;且所述软件项目相关信息包括软件项目名称、软件项目爬取开始时间、软件项目url等。
所述多任务多线程数据爬取模块包括任务管理模块和数据爬取模块;其中所述数据爬取模块包括任务初始化模块、数据爬取单线程运行模块、数据爬取多线程运行模块和任务结束模块;且所述数据爬取模块用于对不同类型的数据实现不同的爬取方法,并根据不同数据类型的数据入口地址自动调用不同的爬取方法对不同类型的数据爬取任务进行数据爬取。请参考图2,该图为本发明一种多任务多线程软件项目数据爬取方法流程图。
所述任务管理模块用于对多个数据爬取任务进行统一的调度;其实现方法包括以下步骤:
步骤1,创建一个待执行任务队列,从数据库中导入尚未完成的任务。
步骤2,在系统资源足够的情况下,取任务队列中的一个任务,并执行该任务初始化模块。
步骤3,每当有任务结束时,自动执行步骤2。
所述任务初始化模块用于为上述每个数据爬取任务分配系统资源并构建存储目录;其实现方法包括以下步骤:
步骤1,为任务获取一个系统线程。从系统线程池中获取一个线程,如果线程池达到容量上线则将该任务放入等待队列;当有线程被释放时,则等待队列中的任务获取该线程,且之后的步骤都利用该线程运行。
步骤2,建立存储文件目录。根据抓取资源所属开源项目在文件系统中建立“软件项目名称/资源名称”形式的文件目录,如果该文件目录已经存在,则返回此目录路径。
步骤3,建立爬取任务记录。在数据库中插入一条该资源爬取任务记录,记录中包括软件项目名称、数据类型、存储地址、任务状态等。
所述数据爬取单线程运行模块用于爬取上述每个数据爬取任务中的url目录,并将url目录进行划分;其实现方法包括以下步骤:
步骤1,根据入口url、不同的数据类型,先将需要爬取的数据的url目录爬取下来。
步骤2,将步骤1中的url目录根据事先定义的多线程个数,分成多分,之后传递给数据爬取多线程运行模块进行爬取。
步骤3,创建多个子线程,分别执行数据爬取模块的多线程部分,将步骤2中的url进行爬取。
所述数据爬取多线程运行模块用于根据上述划分的url目录创建多个子线程,并进行多线程数据爬取;其实现方法包括以下步骤:
步骤1,循环获取url列表中的数据地址。
步骤2,资源爬取。利用统一的网络资源获取接口,将对应的数据资源爬取下来,并存储到相应路径下。
步骤3,资源解析储存。对爬取的数据进行解析,并将解析的结构化数据存储到数据库中。
所述任务结束模块用于为数据爬取模块结束处理时提供必要的处理,例如释放系统资源;并且记录所述数据爬取模块的结束状态。同时在数据爬取模块发生异常结束处理时,所述任务结束模块进行异常错误处理。其实现方法包括以下步骤:
步骤1,错误崩溃记录。任务如果未正常结束而强制退出时,在数据库中将该任务的记录标记为错误,并将捕捉到的错误信息记录下来。
步骤2,将系统资源释放。将该任务所占有的线程移除出线程池,并将线程结束掉,同时关闭所有的网络连接。
所述多源异构软件项目数据自动收集模块又包括项目相关站点的web页面爬取模块、异构数据入口的侦测模块和特定种类数据爬取模块。请参考图3,该图为本发明提供的面向软件项目的多源异构数据自动收集方法流程图。
所述项目相关站点的web页面爬取模块用于根据用户输入的软件项目名称及url,并利用通用的基于广度优先的爬虫方法,对与该软件项目相关的多个站点中的所有web页面进行爬取。其实现方法包括以下步骤:
步骤1:根据输入的主站点url和软件项目名称,爬取该url对应的web页面。
步骤2:对在步骤1中获取的web页面进行解析,并获取其中所有与主站点url集合相同前缀的url,并将url添加进url列表中,之后获取url列表中的一个url。
步骤3:对于步骤2中获取的url,利用异构数据入口的侦测模块的detect方法进行判定,如果是已知的数据类型的资源页面对应的地址,则过滤掉。
步骤4:根据步骤3中过滤后得到的web页面中的url,利用异构数据入口的侦测模块的detectentry方法进行判定,如果是已知的数据类型的数据入口地址,则转特定数据收集(即分发到对应的特定种类数据爬取模块),否则转步骤2。其中在detectentry方法中,针对每种不同的数据类型,事先构造其数据入口地址应当符合的url正则表达式以及url对应的web页面中应当包含的关键字集合,如果url符合该正则表达式并且包含关键字集合则判定该url是已知的数据类型的数据入口地址;其中每种数据类型的正则表达式和关键字集合都为人为制定,根据需求进行修改。
所述异构数据入口的侦测模块用于对上述爬取到的web页面进行判断,如果该web页面中的url是已知的数据类型的数据入口地址,则将其分发到对应的特定种类数据爬取模块,如果该url不是已知的数据类型的数据入口地址,则继续利用上述通用的基于广度优先的爬虫方法进行爬取,以免进行重复爬取。所述对上述爬取到的web页面进行判断包括以下两个步骤:
步骤1:调用对应特定种类数据爬取模块的detect方法,判断上述爬取的web页面中的url是否是已知的数据类型的资源页面对应的地址,若是则过滤掉以提高爬取效率,否则继续对该web页面中的url进行判断;
步骤2:调用对应特定种类数据爬取模块的detectentry方法,判断上述过滤后得到的web页面中的url是否是已知的数据类型的数据入口地址,若是则根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,否则继续利用上述通用的基于广度优先的网页爬虫方法进行爬取。
所述特定种类数据爬取模块用于根据从所述异构数据入口的侦测模块获取的已知的不同数据类型的数据入口地址,创建其对应的数据爬取任务,并在所述多任务多线程数据爬取模块中调用对应的爬取方法进行数据的爬取。所述爬取的数据类型有:邮件、文档、代码、bug信息、版本控制信息等。其中某些数据又可以细分为几种子类。邮件数据有:mbox、mhonarc、googlegroup等;文档数据有:stackoverflow、官方tutorials等;代码库有:git、svn等;bug信息有:bugzilla、jira等。每种类型数据都有其对应的数据入口地址,并根据不同的数据入口地址分别实现detect方法、detectentry方法和对应的数据爬取任务创建程序。
所述数据解析存储模块用于对上述多源异构软件项目数据自动收集模块收集的数据进行解析与存储。同上述所述特定种类数据爬取模块,所述收集的数据依然包含多种类型的数据,每种类型数据都有其对应的数据格式,并根据其包含的具体内容设计存储模式,并存储到数据库中。对于邮件数据,包含信息有:发送人、发送时间、主题、正文等;对于代码库数据,包含信息有:版本号、修改内容、修改人员等;对于文档数据,包含信息有:段落结构化信息、文档内容、对应版本等;对于bug数据,包含信息有:bug内容、修改内容、提出人、修改时间等。其具体实现方法包括以下步骤:
步骤1:从上述存储目录中读取爬取的数据,根据其格式进行解析。
步骤2:对不同类型数据中解析出的信息进行筛选,并存储到数据库中。
下面为一具体实施例,来解释说明本发明。在本实施例中,用户需要eclipse项目的各类软件项目数据,其具体步骤包括:
(1)启动多任务多线程数据爬取模块中的任务管理模块,从数据库中导入尚未完成的任务,比如:eclipse邮件收集任务,eclipse代码收集任务,eclipse文档收集任务等等。
(2)启动多源异构软件项目数据自动收集模块对软件项目数据进行收集;其具体包括:
步骤1:根据用户输入的主站点url和软件项目名称,爬取该url对应的web页面。例如主站点为https://eclipse.org/,创建web页面类型的数据爬取任务对该站点进行网页爬取。
步骤2:对在步骤1中获取的web页面进行解析,并获取其中所有与主站点url相同前缀的url,并将url添加进url列表中,之后获取url列表中的一个url。例如urlhttps://dev.eclipse.org/mailman/listinfo,其中就包含了主站点的url前缀。
步骤3:对于步骤2中的url,利用异构数据入口的侦测模块的detect方法进行判定,如果是已知的数据类型的资源页面对应的地址,则过滤掉以提高爬取效率,否则继续对该url进行判断。例如http://dev.eclipse.org/mhonarc/lists/4diac-dev/maillist.html该页面就是一个mhonarc类型的email数据,通过异构数据入口的侦测模块可以判断出来。
步骤4:根据步骤3中过滤后得到的url,利用异构数据入口的侦测模块的detectentry方法进行判定,如果是已知的数据类型的数据入口地址,则根据已知的不同数据类型的数据入口地址创建其对应的数据爬取任务,否则继续利用上述通用的基于广度优先的网页爬虫方法(即转上述步骤2)进行爬取。
步骤5:将上述创建的数据爬取任务添加到所述多任务多线程数据爬取模块中的任务管理模块进行统一的调度,之后进行数据的爬取。
(3)多任务多线程数据爬取模块根据事先定义好的数据类型,加载相对应的数据爬取任务,并调用对应的爬取方法进行数据爬取;其中所述调用对应的爬取方法进行数据爬取包括以下步骤:
步骤1:当系统资源足够时,对每个数据爬取任务分配系统资源,并构建存储目录。例如/crawlerdata/eclipse/各种类型数据名称。
步骤2:爬取上述每个数据爬取任务中的url目录,并将url目录进行划分;
步骤3:根据上述划分的url目录创建多个子线程,并进行多线程数据爬取;
步骤4:当上述所有子线程数据爬取结束后,释放系统资源;并且在数据爬取模块发生异常结束处理时,进行异常错误处理。
(4)对上述爬取的数据进行解析并存储到数据库中;其进一步包括以下子步骤:
步骤1:从存储目录/crawlerdata/eclipse/email中读取邮件的数据,根据其格式进行解析。
步骤2:对不同类型数据中解析出的信息进行筛选,并存储到数据库中。例如email中的寄信人、收信人、时间戳、正文等内容。
以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。
- 还没有人留言评论。精彩留言会获得点赞!