一种GK鉴别聚类的茶叶品种分类方法与流程
本发明涉及一种茶叶品种分类方法,具体涉及一种gk鉴别聚类的茶叶品种分类方法。
背景技术
茶叶是世界三大饮料之一,它含有茶多酚、蛋白质和氨基酸等有机物质。岳西翠兰、六安瓜片、施集毛峰、黄山毛峰是安徽地区特有的茶叶品牌,但是在茶叶市场上存在以次充好现象,而普通消费者无法辨认优质名茶和劣质茶叶,往往会受骗上当。不同品种的茶叶其内部的有机物含量不相同,品质也不相同。所以研究一种方法简单、易于操作、检测速度快的茶叶品种的鉴别方法是非常必要的。
近红外光谱检测技术作为一种快速无损检测技术,近年来应用于茶叶品质的检测分析中。近红外光谱检测茶叶后得到漫反射光谱,在不同品种的茶叶上获得的漫反射光谱存在差异,利用这个原理,可以将不同品种的茶叶区分开来,即实现不同品种茶叶的分类。
模糊聚类技术已经有效的应用于大规模数据分析、数据挖掘、模式识别、图像处理等领域,具有重要的理论与实际应用价值。其中最著名的是模糊c-均值(fuzzyc-means,fcm)算法,但fcm并未考虑数据集的结构,为此,gustafson和kessel通过引入模糊协方差矩阵的方法,对fcm进行了相应的改进,提出了gk聚类方法(gk聚类是由gustafson和kessel提出的一种聚类方法,见文献gustafsonde,kesselwc.fuzzyclusteringwithfuzzycovariancematrix[c]//proceedingsoftheieeecdc,sandiego,1979:761~766.)。但是gk聚类方法在聚类过程中无法动态提取鉴别信息和改变数据维数。
技术实现要素:
针对传统gk聚类算法的缺陷和不足,本发明提供了一种gk鉴别聚类方法(gkdcm),结合近红外光谱技术实现茶叶品种的准确鉴别,gkdcm可实现模糊聚类过程中进行近红外光谱数据鉴别信息的提取,达到更高的聚类准确率。
本发明采用的技术方案包括以下步骤:
一种gk鉴别聚类的茶叶品种分类方法,采集茶叶样本近红外光谱,通过多元散射校正msc对茶叶近红外光谱进行预处理、采用主成分分析方法pca对茶叶样本近红外光谱的降维处理,采用线性鉴别分析lda提取茶叶训练样本近红外光谱的鉴别信息,对测试样本进行模糊c均值聚类,利用gk鉴别聚类进行茶叶品种的分类。
进一步,利用gk鉴别聚类进行茶叶品种的分类,具体过程为:
1):初始化设置相关参数,包括茶叶测试样本数n、样本类别数目c、权重指数m、迭代次数初始值r、最大迭代次数rmax以及迭代最大误差参数为ε;
2):计算第r次迭代时的类中心值vi(r)、模糊类间散射矩阵sfb、模糊类内散射矩阵sfw和特征向量ψ;
类中心值vi(r)的计算公式为:
模糊类间散射矩阵sfb、模糊类内散射矩阵sfw、特征向量ψ的计算公式为:
其中
3):将样本xk、类中心值vi(r)分别转化到特征空间rq、rp:
特征空间由ψ1,ψ2,…,ψp组成,特征空间rq、rp分别为yk=xkt[ψ1,ψ2,…,ψp](yk∈rp)、
4):计算第r次迭代时的模糊协方差矩阵
第r次迭代时的模糊协方差矩阵
5):若
与现有技术相比,本发明具有以下明显的优点:
gkdcm聚类方法通过对矩阵
附图说明
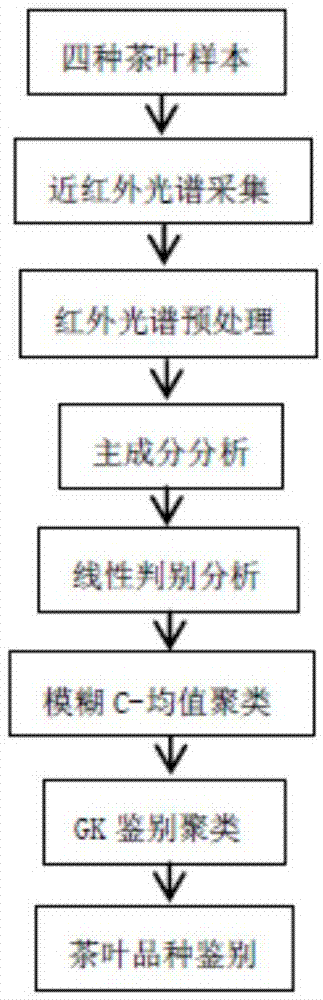
图1为本发明的流程示意图;
图2是茶叶样本的近红外光谱图;
图3是多元散射校正msc处理后的茶叶红外光谱图;
图4是线性判别分析lda处理后得到的三维测试样本;
图5为模糊c均值聚类的模糊隶属度图;
图6为一种gk鉴别聚类的模糊隶属度图。
具体实施方式
以下结合附图说明和具体实施方式对本发明作进一步的详细描述:本发明提出的一种gk鉴别聚类的茶叶品种分类方法可实现模糊聚类过程中进行数据鉴别信息的提取,可以达到更高的聚类准确率,适用于茶叶品种的鉴别分析,本发明的实施流程如图1所示。
实施例:
步骤一、茶叶(安徽四种茶叶)样本近红外光谱采集。
采集岳西翠兰、六安瓜片、施集毛峰、黄山毛峰四种安徽品牌茶叶,每种茶叶的样本数为65,合计260个样本,所有茶叶样本被研磨粉粹后经40目筛过滤;实验室温度和相对湿度保持相对不变,antarisii近红外光谱分析仪开机预热1个小时;采用反射积分球模式采集茶叶近红外光谱,近红外光谱分析仪扫描每个样品32次以获取样品的漫反射光谱均值;光谱扫描的波数为10000~4000cm-1,扫描间隔为3.857cm-1,采集到每个茶叶样品的光谱是1557维的数据;每个样本采样3次,取其平均值作为后续模型建立的实验数据。四种茶叶样本的近红外光谱如图2所示。
步骤二、对茶叶红外光谱预处理:利用多元散射校正(msc)对茶叶近红外光谱进行处理。
先计算步骤一茶叶近红外光谱的平均值,然后将每个茶叶样本的近红外光谱与平均值做线性回归,计算每个茶叶样本的近红外光谱相对于平均值的线性平移量和倾斜偏移量,最后,在每个茶叶样本的近红外光谱中减去线性平移量同时除以倾斜偏移量以实现茶叶近红外光谱的多元散射校正(msc);茶叶红外光谱经过多元散射校正后的结果如图3所示。
步骤三、采用主成分分析方法(pca)对茶叶样本近红外光谱进行降维处理,将茶叶样本近红外光谱从高维数据变换为低维数据。
将步骤二中经过多元散射校正(msc)处理后的茶叶样本近红外光谱按行排列组成矩阵,对该矩阵进行数据标准化,使其均值变为零,然后计算矩阵的协方差矩阵并对协方差矩阵进行特征分解计算特征值和特征向量,将特征值从大到小排列,取前7个最大特征值(分别为:22.69,1.19,0.47,0.18,0.05,0.03,0.01)对应的7个特征向量,将260个茶叶样本的近红外光谱数据投影到这7个特征向量上,从而将近红外光谱从1557维压缩到7维。
步骤四、采用线性鉴别分析(lda)提取茶叶训练样本近红外光谱的鉴别信息。
将步骤三中经过pca处理后的茶叶样本近红外光谱数据分为两个部分:从每类茶叶样本中选取22个样本组成茶叶样本训练集,剩余43个样本组成茶叶样本测试集。用茶叶样本训练集计算得到类内散射矩阵sw和类间散射矩阵sb,对矩阵
步骤五、设置模糊c-均值聚类(fcm)的权重指数m=2.0,最大迭代数rmax=100,误差上限值ε=0.00001;对步骤四的茶叶样本测试集进行模糊c均值聚类(fcm),fcm为迭代计算方法,通过迭代计算下面式子:
上式中,uik为第k个测试样本xk隶属于第i类的模糊隶属度,m为权重指数;vi是第i类的类中心值,c为类别数,n为样本数。
fcm的模糊隶属度如图5(图中hs、la、sg、yx分别代表黄山毛峰、六安瓜片、施集毛峰、岳西翠兰)所示,其作为gk鉴别聚类的初始模糊隶属度u(0):
步骤六:用gk鉴别聚类进行茶叶品种的判定:
1)初始化:设置茶叶测试样本数n=172,样本类别数目c=4,权重指数m=2.0;设置迭代次数初始值r=1和最大迭代次数rmax=100;设置迭代最大误差参数为ε=0.00001;
2)计算第r(r=1,2,…,rmax)次迭代时的类中心值
其中,
3)计算模糊类间散射矩阵sfb和模糊类内散射矩阵sfw:
其中,c为类别数,上标t代表矩阵转置运算,
计算可得:第39次迭代时,模糊类间散射矩阵sfb和模糊类内散射矩阵sfw为:
4)计算特征向量
其中,
特征值λ对应的特征向量
5)将样本xk∈rq转化到特征空间(由ψ1,ψ2,…,ψp组成)
yk=xkt[ψ1,ψ2,…,ψp](yk∈rp)
其中,p和q均为样本的维数,ψp为第p个特征向量;
计算可得:
6)同样将vi(r)转换到特征空间rp:
计算可得:
7)计算第r次迭代时的模糊协方差矩阵
其中;yk为xk经转换后得到的样本;
计算可得:第39次迭代时迭代结束,
第i=0类模糊协方差矩阵为:
第i=1类模糊协方差矩阵为:
第i=2类模糊协方差矩阵为:
第i=3类模糊协方差矩阵为:
8)计算第r次迭代时的模糊隶属度值
上式中
上式中,
9)若
实验结果为:迭代终止rmax=39,模糊隶属度值如图6所示,可以将测试样本的茶叶划分为四个类别,聚类准确率为100%。
聚类中心
所述实施例为本发明的优选的实施方式,但本发明并不限于上述实施方式,在不背离本发明的实质内容的情况下,本领域技术人员能够做出的任何显而易见的改进、替换或变型均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!