一种病理切片中非常规细胞的分割方法与流程
本发明属于医疗影像数据处理领域,具体涉及一种病理切片中非常规细胞的分割方法。
背景技术
图像实例语义分割(instancesemanticsegmentation)是计算机视觉的一个重要研究方向,其任务是通过计算机算法在图像中使用方形框标出图像中的物体数量,并对框中的每个像素预测类别标签,完成在框中的语义分割。实例语义分割任务在自动驾驶,工业制造,罪犯追踪等场景中都有着重要应用。在医疗影像中,语义分割常常被用于分割图像中的细胞、组织或器官等。
在1998年lecun等人首次提出了卷积神经网络(convolutionalneuralnetwork,ncc)lenet模型被美国许多银行用来识别支票上的手写数字之后。各种不同架构的cnn模型如vgg,resnet等在imagenet竞赛中取得多次比赛的冠军,cnn在图像处理与目标识别领域被广泛应用,成为深度学习在图像处理领域的通用神经网络。cnn在语义分割中也被广泛使用:2014年,long等人提出全卷积神经网络(fullyconvolutionalnetwork,fcn),使得卷积神经网络无需全连接层就可进行密集的像素预测,实现了像素级别的分类,2017年kaiminghe提出的maskr-cnn结构在实例语义分割任务上取得了很好的效果,并在iccv2017会议上获得了最佳论文。
专利cn107886515a公开了一种较快速、鲁棒性将高的图像分割方法,包括:根据多帧图像的特征,确定多帧图像中待分割图像的初始背景区域,进而确定适应于背景区域的基础矩阵;根据背景区域的基础矩阵,确定待分割图像的初始前景区域,根据初始前景区域,对待分割图像进行处理,确定待分割图像的分割结果。专利cn107871321a公开了一种极大提升图像分割精度和速度的方法。
然而,由于医疗影像的分割与自然图像的差异较大,并存在着阴性数量较多的特点,直接将一般的语义分割模型运用在影像上往往效果不好,另外自然图像上的语义分割往往基于目标相对固定的形状特征,在病理切片的分割中,由于病理切片中非常规细胞的形状的容易聚集使大小、形状无规律性,给实例分割任务带来了极大的困难。
技术实现要素:
本发明提供一种病理切片中非常规细胞的分割方法,该分割方法较传统分割方法更精确。
本发明所述的常规细胞为人体正常细胞,非常规细胞与人体正常细胞相对应,为人体非正常形态细胞。
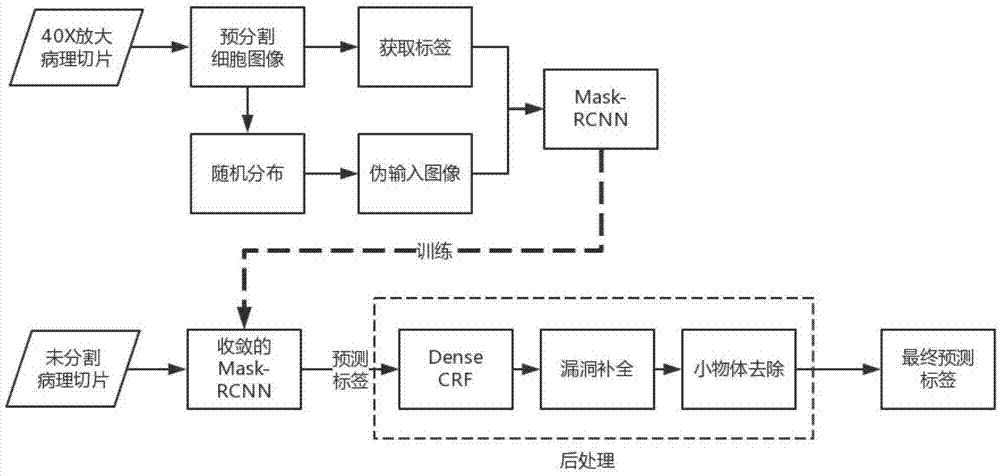
所述的病理切片中非常规细胞的分割方法,具体包括以下步骤:
(1)对电子扫描放大的病理切片进行预分割,得到单个细胞的透明背景的预分割细胞图像,同时对所得预分割细胞图像中的每个像素点分配像素标签;通过贴图方法及二元高斯分布分配法将所需预分割细胞图像随机分布在与输入病理切片大小一致的白色背景上,得到伪输入图像;
所述分配的像素标签包括:背景标签、常规细胞标签和k种非常规细胞标签;对背景标签分配0标签,常规细胞分配1标签,k种非常规细胞分配2至k+1标签,其中k为大于等于1的整数;
所述的预分割方法为:对病理切片中所有常规细胞与非常规细胞使用图像分割工具或专家标记处理为单个细胞的透明背景图像;
作为优选,步骤(1)具体操作步骤为:
对n张电子扫描20~40×放大的病理切片进行预分割,得到m张单个细胞的透明背景的预分割细胞图像,同时对所得m张预分割细胞图像中的每个像素点分配像素标签;通过贴图方法及二元高斯分布分配法将m张预分割细胞图像随机分布在与输入病理切片大小一致的白色背景上,得到伪输入图像;
其中,m取1000~2000之间的整数,n为大于2000的整数,m为介于30至60之间的整数,具体使用数量m随机生成。
所述步骤(1)中将所需预分割细胞图像随机分布在白色背景上的二元高斯分布分配法,具体操作步骤为:
(1-1)在白色背景大小的平面上生成m个服从均值为μ,标准差为σ的二元高斯分布,二元高斯分布的概率分布公式如下:
其中,x,y表示水平方向与垂直方向坐标值,ρ为x与y之间的相关系数,
m为介于30至60之间的整数;
(1-2)将m个预分割细胞图像摆放在空白背景上,使其中心坐标与(2-1)生成的m个中心点坐标重合,细胞间的重叠部分使用透明度α合成边界;所述α介于0.2至0.5之间;
(1-3)通过调整σ矩阵中数值大小来微调细胞之间的间距和摆放形状;
(1-4)通过调整均值μ的数值调整细胞的整体位置。
使用步骤(1)生成伪输入图像的优点在于:每次的训练图像都是人为生成,并且能够同时获取完整的像素标签,使用这种方法能够重复生成大量的训练数据,并且有效降低标注时间与成本,并且此方法的精度与完全人工标记的训练样本相比精度不会相差太多。
(2)根据步骤(1)中分配的像素标签,对伪输入图像中的每个细胞分配一个细胞边界方框位置并根据步骤(1)中分配的像素标签标记边界方框内细胞图像的每个像素点的标签,记为真值标签,保持真值标签与步骤(1)中对应的单个细胞像素一致;
所述的分配边界方框位置的具体方法为:分别取得细胞真值标签不等于0的坐标中,最小x坐标x1、最大的x坐标x2、最小y坐标y1与最大y坐标y2,分配以(x1,y1)为左上角顶点,宽为x2–x1,高为y2-y1的边界框。
(3)将步骤(1)中生成的伪输入图像与步骤(2)中的得到的真值标签作为训练数据训练mask-rcnn模型,所述的mask-rcnn使用resnet-121为基础网络,网络的训练过程使用单阶段训练方式,直接使用rpn损失函数与faster-rcnn损失函数相加作为最终损失函数,使用学习率为lr的随机梯度下降法最小化目标损失函数,直至收敛,获得收敛的maskrcnn模型,使其具有检测非常规细胞边界方框与预测方框内像素标签的能力;
所述lr的取值范围为10-5至10-3之间;
所述rpn损失函数为边界框回归损失与二分类损失函数之和;
所述faster-rcnn损失函数为边界框回归损失、多分类交叉熵损失与mask交叉熵损失之和,
其中,边界框回归损失使用smoothl1函数:
其中,
多分类交叉熵损失crossentropy计算公式如下:
其中,p、q表示预测分布与真实分布,
(4)将未经过标记的新病理切片,输入步骤(3)得到的收敛的mask-rcnn模型,检测出b个最有可能含有非常规细胞的边界方框以及方框中每个像素点的概率值t,若t大于阈值t,则认为该像素为背景像素,记为0,否则取t最大值处的非常规细胞类别作为预测标签,所述预测标签使用后处理方法输出最终预测标签,作为分割结果;
其中,b为10~100之间的整数,t为0.01~0.5之间的正数。
所述的后处理方法具体步骤为:
(4-1)使用稠密条件随机场(densecrf)算法对概率图进行处理,得到边缘平滑的预测标签图;
(4-2)使用泛洪填充方法补全预测图内部的空洞部分;
(4-3)使用小物体去除的方法去除预测预测标签中尺寸小于一个细胞大小的物体。
本发明优选稠密条件随机场算法的有点在于:该算法输入预测分类概率图,输出的处理后的分类概率图能够将颜色相近,位置相近的像素点分配相同的的标签,使预测图像更加合理,与图像预测更加接近真实分布。
与现有技术相比,本发明具有以下有益效果:
(1)使用标注图像较少,有效降低病理切片标注工作量,节省时间;
(2)短时间内产生大量训练数据,能够较好地的大量数据进行拟合,使预测图像更加合理,使图像预测更加接近真实分布,提高传统分割方法的精确度。
附图说明
图1为本发明具体实施方法的架构图。
图2为本发明具体实施方法中mask-rcnn模型的整体结构。
图3为本发明具体实施方法中预测图像方框(右图)与医生标注的图像(左图)对比图。
具体实施方式
为了进一步理解本发明,下面结合具体实施方法对本发明提供的一种病理切片中非常规细胞的分割方法进行具体描述,但本发明并不限于此,该领域技术人员在本发明核心指导思想下做出的非本质改进和调整,仍然属于本发明的保护范围。
本实施例中的病理切片以宫颈癌病理切片为例,具体实施方法架构图如图1所示,包括:
(1)将训练数据中8000张电子扫描40×放大的宫颈癌病理切片中,所有单个常规细胞与非常规细胞使用图像分割工具处理为1500个单独的透明背景的细胞图像,即预分割细胞图像,并给每张预分割图像的每个像素点分配像素标签;
所述分配的像素点标签包括:背景标签、常规细胞标签和4种非常规细胞标签,本实施例中,非常规细胞具体分为高级别鳞状上皮病变细胞(hsil);低级别鳞状上皮病变细胞(lsil),非典型鳞状细胞(ascus)以及鳞状上皮癌(sqca),对背景标签分配0标签,常规细胞分配1标签,hsil,lsil,ascus以及sqca分别分配标签为2、3、4和5;
(2)对步骤(1)生成的预分割细胞图像,每次训练中使用贴图方法处理其中的50张图像,将50张预分割细胞图像通过二元高斯分布分配法随机分布在与步骤(1)中输入病理切片大小一致的白色背景上,得到伪输入图像;
所述的二元高斯分布分配法,包括以下具体操作步骤:
(2-1)在白色背景大小的平面上生成50个服从均值为μ=(220,300),标准差为
其中,x,y表示水平方向与垂直方向坐标值,ρ为x与y之间的相关系数,
(2-2)将50个预分割细胞图摆放在空白背景上,使其中心坐标与(2-1)生成的50个中心点坐标重合,细胞间的重叠部分使用透明度30%合成边界,使边界看起来接近真实病理切片;
(2-3)通过调整σ矩阵中数值大小来微调细胞之间的间距和摆放形状;
(2-4)通过调整均值μ的数值调整细胞的整体位置
调整结束后,μ=(225,289),
(3)根据步骤(2)中生成的伪输入图像与步骤(1)中生成的像素标签,对伪输入图像中的每个细胞,分配一个细胞边界方框位置与该边界方框内每个像素点的标签,分配的各像素标签与步骤(1)中对应的单个细胞像素一致;
(4)将步骤(2)中生成的伪输入图像与步骤(3)中的分配标签作为训练数据训练mask-rcnn模型,所述mask-rcnn模型的整体结构如图2所示:该mask-rcnn模型使用resnet-121为基础网络,网络的训练过程使用单阶段训练方式,直接使用rpn损失函数与faster-rcnn损失函数相加作为最终损失函数进行收敛;最后,使用学习率为0.0001的sgd优化算法最小化rpn损失函数与faster-rcnn损失函数之和,在训练280轮次后,获得收敛的mask-rcnn模型;使其具有检测非常规细胞边界方框与预测方框内像素标签的能力;
所述rpn损失函数为边界框回归损失与二分类损失函数之和,所述faster-rcnn损失函数为边界框回归损失、多分类交叉熵损失与mask交叉熵损失之和,其中crossentropy计算公式如下:
其中p,q表示预测分布与真实分布,
边界框回归损失使用smoothl1函数:
其中,
(5)将未经过标记的新病理切片,输入步骤(4)训练得到的收敛的mask-rcnn模型,检测出30个最有可能含有4种非常规细胞的边界方框以及方框中每个像素点的概率值t,若t大于阈值0.2,则认为该像素为背景像素,记为0,否则取t最大值处的非常规细胞类别作为预测标签,并记录其概率值t;
(6)将步骤(5)得到的预测标签使用后处理方法使预测结果更加稳定合理,输出最终预测标签,其结果如图3中的右图所示,与医生标注的图像(左图)非常接近,说明本发明的方法能够有效的预测出非常规细胞的位置和类别。
所述的后处理方法的具体步骤如下:
(6-1)使用稠密条件随机场(densecrf)算法对概率图进行处理,得到边缘平滑的预测标签图;
(6-2)使用泛洪填充方法补全预测图内部的空洞部分;
(6-3)使用小物体去除的方法去除预测预测标签中尺寸小于一个细胞大小的物体。
- 还没有人留言评论。精彩留言会获得点赞!