一种基于半监督集成学习的软测量建模方法与流程
本发明涉及一种基于半监督集成学习的软测量建模方法,属于复杂工业过程建模和软测量领域。
背景技术
化工、冶金和发酵等工业过程中的一些重要质量变量,往往无法通过在线仪表测量,而通过实验室离线分析的方式又存在严重的滞后。基于数据的软测量建模方法,无需深入了解过程的机理知识,具有维护成本低、低测量延迟等优点,近年来在工业过程建模中得到了广泛应用。传统的软测量建模方法仅考虑工业过程中的有标签样本信息,丢弃了大量的无标签样本,然而实际过程中,有标签样本的数量远远少于无标签样本,此时采用常规的软测量建模方法无法达到理想中的精度。基于半监督学习思想的软测量建模方法在利用少量的有标签样本的同时,又可以结合无标签样本中包含的隐含信息,得到广泛的关注与应用。
目前主流的半监督学习方法有生成式方法、半监督svm方法、基于图的方法和基于分歧的方法。前面三种半监督学习方法均采用单一学习机对无标签样本进行利用,而基于分歧的方法利用多个学习机,通过学习机之间的差异实现对无标签样本的利用。因为半监督集成学习起源于基于分歧的半监督学习方法,所以它有效结合了半监督学习与集成学习的优点,既具有半监督学习利用无标签样本扩充少量的有标记样本的优点,又具有集成学习增强分类器间的差异性提升整体分类器性能的优点。其中,tri-training算法被广泛应用于分类问题上,tri-training克服了协同训练算法对样本集冗余视图的假设要求,具有更好的泛化性能;但是tri-training通过采用三个学习机中的两个学习机(或分类器)对未标记样本的一致性,对未标记样本进行选择标记,因此会有两个置信度指标产生,存在不方便对未标记样本进行选择的问题。
目前实际工业过程中主导变量的获取频率远远低于辅助变量,基于半监督学习思想的软测量建模方法存在模型预测性能不高、对关键变量预测不够精确的问题,从而导致产品质量低且生产成本高的问题。
技术实现要素:
为了解决目前存在的由于实际工业过程中主导变量的获取频率远远低于辅助变量,基于半监督学习思想的软测量建模方法存在模型预测性能不高,对关键变量预测不够精确的问题,本发明提供了基于半监督集成学习的软测量建模方法所述技术方案如下:
一种基于半监督集成学习的软测量建模方法,所述方法包括:
步骤1:采集过程有标签样本集l={xl,yl},l表示有标签;和无标签样本集u={xu},u表示无标签,对无标签样本集u采用bagging算法生成三个无标签样本子集u1、u2、u3;
步骤2:利用有标签样本子集建立初始软测量模型,fi=learn(li),learn为软测量建模方法,初始有标签样本子集li=l,i=1,2,3;
步骤3:对于u1中的每一个样本xu,采用近邻法分别从l2和l3中选择出num个距离近的样本,得到近邻样本集ω2和ω3;
步骤4:如式(1)采用f2和f3对xu进行预测,得到xu的伪标记yu,2和yu,3,{xu,yu,j}被称为伪标记样本,对添加伪标记样本后的有标签样本子集建立如式(2)所示的软测量模型;
yu,j=fj(xu),j=2,3(1)
步骤5:根据式(3)计算xu在学习机f2和f3下对应的置信度指标
其中ωj为无标签样本xu分别从l2和l3中选取出的近邻样本集,yi为num个近邻样本的真实标签值,fj(xi)为xi对应的初始模型预测结果,f′j(xi)为添加伪标记样本xu之后建立的软测量模型的预测结果;
步骤6:根据threshold选择置信度高的无标签样本并对其添加标记,对应的标记值为
步骤7:同理可利用u2和u3对l2和l3进行样本扩充;
步骤8:重复上述步骤2-步骤7t次,直至达到最大迭代次数或l1、l2、l3不再发生改变;
步骤9:利用更新后的有标签样本集l1、l2、l3,建立软测量回归模型,得到fi=learn(li);
步骤10:对于新来样本,分别采用模型fi,i=1,2,3进行预测,采用均值融合方式,对各模型的预测值进行融合,得到最终的预测输出值。
可选的,采用tri-training回归算法估计出缺失的主导变量值,建立融合的单一置信度计算方式对无标签进行选择标记,采用集成学习的思想建立差异性的模型。
所述基于半监督集成学习的软测量建模方法可应用于化工、冶金和发酵等工业过程中。
本发明提供的技术方案带来的有益效果是:
通过采用tri-traininggpr算法估计缺失的主导变量样本,采用bagging算法将无标签样本集划分为三个无标签样本子集,对有标签样本集训练三个学习机;利用训练的学习机对无标签样本进行标记,提出一种新的置信度指标取代传统tri-training中两个置信度指标的计算,若伪标记样本的置信度满足阈值要求,将此伪标记样本添加到学习机的有标签样本集中,扩充三个有标签样本子集,根据扩充后的有标签样本子集,建立对应的gpr模型,对新到来的查询样本进行预测,采用均值融合方式对三个模型的预测输出进行融合,得到最终的预测输出。从而实现了对关键变量进行准确的预测,达到了提高产品质量低并且降低了生产成本的目的。
附图说明
为了更清楚地说明本发明实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
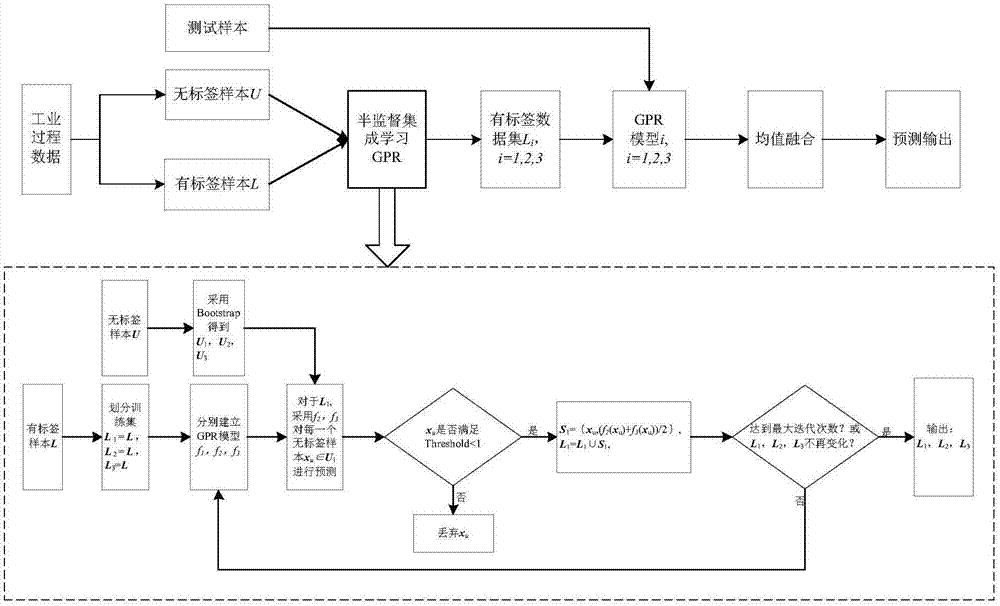
图1是本发明实施例提供的ssegpr建模步骤方法流程图;
图2是本发明实施例提供的不同标签率下各种方法预测的标准误差(root-mean-squareerror,rmse);
图3是在25%标签率下各种方法的预测结果散点图。
具体实施方式
为使本发明的目的、技术方案和优点更加清楚,下面将结合附图对本发明实施方式作进一步地详细描述。
实施例一:
本实施例结合常见的化工过程——脱丁烷塔过程为例,参见图1,实验数据来自于脱丁烷塔e过程,运用本发明提供的基于半监督集成学习的软测量建模方法对丁烷浓度进行预测:
步骤1:采集过程有标签样本集l={xl,yl},l表示有标签;和无标签样本集u={xu},u表示无标签,对无标签样本集u采用bagging算法生成三个无标签样本子集u1、u2、u3。
步骤2:利用有标签样本子集建立初始gpr模型,fi=gpr(li),初始有标签样本子集li=l,i=1,2,3。
步骤3:对于u1中的每一个样本xu,采用近邻法分别从l2和l3中选择出num个距离近的样本,得到近邻样本集ω2和ω3。
步骤4:如式(1)采用f2和f3对xu进行预测,得到xu的伪标记yu,2和yu,3,{xu,yu,j}被称为伪标记样本,对添加伪标记样本后的有标签样本子集建立如式(2)所示的软测量模型;
yu,j=fj(xu),j=2,3(1)
步骤5:根据式(3)计算xu在学习机f2和f3下对应的置信度指标
其中ωj为无标签样本xu分别从l2和l3中选取出的近邻样本集,yi为num个近邻样本的真实标签值,fj(xi)为xi对应的初始模型预测结果,f′j(xi)为添加伪标记样本xu之后建立的软测量模型的预测结果。
步骤6:threshold值越小代表置信度越高,选择置信度高的无标签样本对其添加标记,对应的标记值为
步骤7:同理可利用u2和u3对l2和l3进行样本扩充。
步骤8:重复上述步骤2-步骤7t次,直至达到最大迭代次数或l1、l2、l3不再发生改变。
步骤9:利用更新后的有标签样本集l1、l2、l3,建立gpr模型,得到fi=gpr(li)。
给定数据集{x,y},其中x∈rn×m,y∈rn×1,n样本点数,m是样本维数。输入输出之间满足式(5)所示
y=f(x)+ε(5)
式中ε是均值为0,方差为
y~n(0,c)(6)
式中c为n×n的协方差矩阵,其i行j列元素定义为cij=c(xi,xj;θ),协方差矩阵通过核函数计算得到,文中选取平方指数协方差核函数,定义如式(7)所示
式中δij=1仅在i=j时成立,否则δij=0,l为方差尺度,
对于新来的样本xq,其对应的gpr模型输出均值和方差如式(8)和(9)所示
其中c(xq)=[c(xq,x1),...,c(xq,xn)]是新来样本与训练样本间的协方差矩阵,c是训练样本之间的协方差矩阵,c(xq,xq)是新来样本的自协方差。
步骤10:对于新来样本,分别采用模型fi,i=1,2,3进行预测,采用均值融合方式,对各模型的预测值进行融合,得到最终的预测输出值。
图2是在不同标签率下各种方法预测的标准方差rmse;图3是25%标签率下不同方法的预测结果散点图;由图可知,基于半监督集成学习的软测量建模方法能够有效的利用无标签样本信息,能够较准确的预测丁烷浓度。
本发明实施例通过采用tri-traininggpr算法估计缺失的主导变量样本,采用bagging算法将无标签样本集划分为三个无标签样本子集,对有标签样本集训练三个学习机;利用训练的学习机对无标签样本进行标记,提出一种新的置信度指标取代传统tri-training中两个置信度指标的计算,若伪标记样本的置信度满足阈值要求,将此伪标记样本添加到学习机的有标签样本集中,扩充三个有标签样本子集,根据扩充后的有标签样本子集,建立对应的gpr模型,对新到来的查询样本进行预测,采用均值融合方式对三个模型的预测输出进行融合,得到最终的预测输出。从而实现了对关键变量进行准确的预测,达到了提高产品质量低并且降低了生产成本的目的。
本发明实施例中的部分步骤,可以利用软件实现,相应的软件程序可以存储在可读取的存储介质中,如光盘或硬盘等。
以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!