基于K-means与多任务关联学习结合的多分类方法与流程
本发明属于机器学习及多分类领域,涉及一种基于k-means与多任务关联学习相结合的多分类方法。
背景技术:
多分类中一个经典的拆分策略是“一对其余”(onevs.rest,简称ovr):在一个n分类任务中,分别将其中一个类作为正类,其余所有类作为负类,训练n个二分类器。在预测阶段,将未知样本同时提交给所有二分类器,并将所有二分类器的结果进行集成,给出最终判断。在实际应用时,目前已有方法主要存在两大问题,一是在ovr中正负样本不均衡的问题,当样本分布不均衡时,常规分类器通常将少数类样本误认为噪声,从而导致分类结果偏向于多数类,导致分类精度很低;二是训练每个二分类器时都会使用全部训练样本,这样会增加算法的时间复杂度。
为了解决ovr中遇到的上述问题,并提高多分类的准确率。本发明首先采用k-means方法对数据集进行下采样,获得平衡数据集的同时减少训练样本。接着采用多任务关联学习的方法对下采样后的数据进行分类,充分利用训练集包含的信息。本发明采用的k-means与多任务关联学习器相结合的方法能有效提高多分类正确率。
技术实现要素:
本发明的目的在于针对现有技术的不足,提出一种基于k-means与多任务关联学习结合的多分类方法。
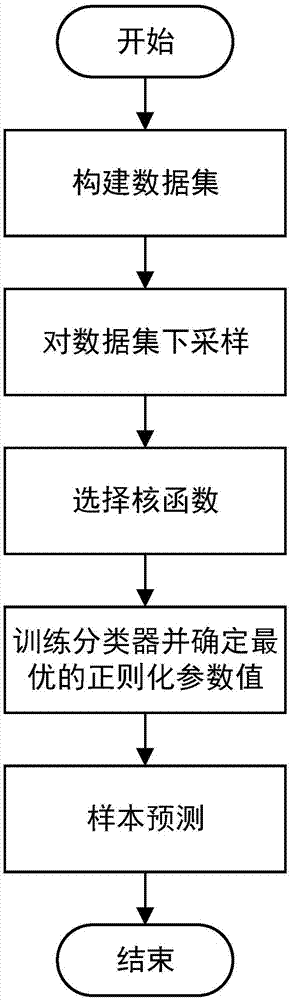
本发明方法包括以下步骤:
步骤(1)、构建数据集
采用数据库中的任一数据集作为样本数据集,分别将样本数据集中n个类别样本中的一类样本作为正类,标记为+1,其余所有样本作为负类,标记为-1,构建出n个训练子集ci=1,2...n。
步骤(2)、利用k-means方法对数据集下采样
对于步骤(1)中构造的每个训练子集ci=1,2...n,指定每个子集中正类样本数ci+为聚类中簇的个数k;对训练子集中的负类样本采用k-means方法聚为ci+个簇,并保留每个簇的聚类中心作为数据集中的负类,这样就获得了正负样本数相等的训练子集。
步骤(3)、选择核函数
多任务关联学习方法中使用核函数把特征映射到高维空间;由于高斯核在通用性方面具有优势,因此本发明中采用高斯核:
其中σ>0为高斯核的带宽,xi、xj表示训练集中任一样本,k()表示核矩阵。
步骤(4)、训练多任务关联学习器,确定正则化参数λ1和λ2的值
将步骤(2)中下采样得到的每个训练子集作为一个分类任务用来训练多任务关联学习器;训练出n个二分类器cli=1,2...n。在多任务关联学习方法中,需要指定两个优化参数λ1和λ2,在λ1∈{10-1,10-2,10-3,10-4,10-5}和λ2∈{10-2,10-3,10-4,10-5}中确定使分类器获得最高分类准确率的λ1和λ2值。
步骤(5)、样本预测
将每个待测样本x同时提交给所有二分类器,获得n个预测结果,对这n个结果进行集成后给出该样本所属类别。
本发明的有益效果是:
本发明的关键在于将k-means方法与多任务关联学习方法组合在一起进行多分类。使用k-means下采样解决了多分类中训练样本不均衡的问题,并减小了训练集的数据量,有利于加快计算速度并减少计算机系统资源的占用。多任务关联学习算法有较强的分类能力,引入该算法作为分类器保证了组合算法的分类准确率,并使组合算法更具通用性。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合具体实施例对本发明做进一步的分析。
本实施例采用uci数据库中的wine数据集作为训练的样本数据集。在运用基于k-means与多任务关联学习相结合的多分类算法进行多分类过程中具体包括以下步骤,如图1所示:
步骤(1)、构建数据集
wine数据集中的数据共有3类,标签分别为“1”“2”“3”,因此需要构建3个训练子集,第一个子集c1将标签为“1”的样本标记为+1,标签为“2”“3”的样本标记为-1;第二个子集c2将标签为“2”的样本标记为+1,标签为“1”“3”的样本标记为-1;第三个子集c3将标签为“3”的样本标记为+1,标签为“1”“2”的样本标记为-1。
步骤(2)、利用k-means方法对数据集下采样
对于子集c1中标记为-1的全部样本,用k-means方法进行下采样,聚成c1+(c1+是c1中标记为+1的样本的个数)个簇,并选取这c1+个簇的质心作为c1数据集中的负类,替换掉c1中标记为-1的样本,这样就获得了正负样本数相等的数据子集。对其余训练子集c2和c3执行同样的操作。
步骤(3)、选择核函数
选择高斯核作为核函数,本实例中高斯核的带宽参数σ指定为1。
步骤(4)、训练多任务关联学习器,确定正则化参数λ1和λ2的值
将(2)中获得的每个训练子集随机抽取一半作为训练集tr,另一半作为验证集te,用来训练多任务关联学习器,得到3个二分类器cl1,cl2和cl3,分别对应原始数据集中的类别“1”“2”“3”。通过试验的方法在λ1∈{10-1,10-2,10-3,10-4,10-5}和λ2∈{10-2,10-3,10-4,10-5}中确定在验证集te上获得最高分类准确率的λ1和λ2值。
步骤(5)、样本预测
对于待预测的样本x,将x分别提交给分类器cl1,cl2和cl3,若只有一个分类器将该样本标记为正类(+1),则认为该样本属于该分类器所对应的类别。
上述实施例并非是对于本发明的限制,本发明并非仅限于上述实施例,只要符合本发明要求,均属于本发明的保护范围。
技术特征:
技术总结
本发明公开了一种基于K‑means与多任务关联学习结合的多分类方法;本发明将K‑means方法与多任务关联学习方法组合在一起进行多分类。使用K‑means下采样解决了多分类中训练样本不均衡的问题,并减小了训练集的数据量,有利于加快计算速度并减少计算机系统资源的占用。多任务关联学习算法有较强的分类能力,引入该算法作为分类器保证了组合算法的分类准确率,并使组合算法更具通用性。
技术研发人员:薛梦凡;韩磊;彭冬亮;薛安克;郭云飞;陈志坤;石义芳
受保护的技术使用者:杭州电子科技大学
技术研发日:2018.04.28
技术公布日:2018.11.06
- 还没有人留言评论。精彩留言会获得点赞!