基于用户画像和上下文推理的答复生成技术的制作方法
背景技术:
情感ai聊天系统在近年来渐渐成为人工智能(ai)领域中最重要的方向之一。通过语音和/或文本的聊天,聊天机器人被用作各类产品/应用程序的交互入口。
除了单个用户与聊天机器人进行聊天的场景外,值得注意的是,在社交网络中经常存在很多群,例如,基于qq、脸谱、linkedin(领英)、wechat(微信),line,slack等等构建的群。这些群可以是兴趣群(例如,电影、食物、旅行、音乐等等)、工作群(例如,属于某一公司的一个部门的团队,或者来自不同公司的一些人)、朋友群、同学群或者甚至包含具有家族关系的家族群。如果能够将聊天机器人引入到这种“群聊”中,将会起到积极的作用,可以帮助总结聊天主题和观点,推动聊天的进展,并能够以主动的方式提供实时的在线信息服务。
技术实现要素:
提供本发明实施例内容是为了以精简的形式介绍将在以下详细描述中进一步描述的一些概念。本发明内容并不旨在标识所要求保护主题的关键特征或必要特征,也不旨在用于限制所要求保护主题的范围。
本文公开了一种基于用户画像和上下文推理的答复生成技术,以用于构建群聊取向的聊天机器人,并针对群聊中的主题多样性以及用户查询和答复的不可预估性,提供了解决方案。
上述说明仅是本公开技术方案的概述,为了能够更清楚了解本公开的技术手段,而可依照说明书的内容予以实施,并且为了让本公开的上述和其它目的、特征和优点能够更明显易懂,以下特举本公开的具体实施方式。
附图说明
图1为ai聊天系统的示例性框架;
图2为示例性的群聊界面示意框图;
图3为示例性的名人“乔治华盛顿”的用户维基档案的示例框图;
图4为linkedin中用于“比尔盖茨”的用户维基档案示例框图;
图5为示例性的用户维基档案的提取过程的流程处理示意图;
图6为用户推文的示例性框图;
图7为示例性的键值对档案分类器的应用示意框图;
图8为示例性的针对主题的生命周期状态进行处理的神经网络装置的结构示意图;
图9示例性的描述了通过四层神经网络实施的分类模型的示意框图;
图10为基于概念的知识图谱的示例性框图;
图11为基于推理的答复生成模型的示例性结构框图;
图12为示例性的基于推理的答复生成装置的结构示意图;
图13为示例性的具有可移动性的电子设备的结构框图;
图14为示例性的计算设备的结构框图。
具体实施方式
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。
本文中,术语“技术”、“机制”可以指代例如(一个或多个)系统、(一个或多个)方法、计算机可读指令、(一个或多个)模块、算法、硬件逻辑(例如,现场可编程门阵列(fpga))、专用集成电路(asic)、专用标准产品(assp)、片上系统(soc)、复杂可编程逻辑设备(cpld)和/或上述上下文以及在本文档通篇中所允许的(一项或多项)其它技术。
基于应用场景的概览
针对群聊相关应用场景,本文提出了一种用于构建群聊取向的聊天机器人的解决方案。
群聊(例如,兴趣组、朋友群,家人群,任何类型的短期或长期活动群)在诸如微信、qq、脸书等等的社交网络(sns)应用中变得越来越流行。例如,在qq这款社交网络应用中,存在由qq用户创建的数百万个群,月活跃用户数大约8亿6千万。
而且,越来越多的聊天机器人开始被设计为用于群聊以提供如下功能:(1)以提供情绪消息,从而帮助群里的人们以更流畅的方式彼此沟通;以及(2)通过非可预测的请求实时提供所需信息。
具体地,第(1)功能更多地在于以“纯聊天”作为主要目标,第(2)功能更多地在于满足提供在线服务(例如,旅行订票、产品推荐等等)。
虽然这两个功能也存在于用户与聊天机器人的一对一沟通中,但是,由于以下原因,仍然存在着一些挑战:
与一对一的聊天场景不同,在群聊,主题具有多样性并且是经常是并行的。每个主题都可能是该群聊中的不同的用户组(usergroup)所感兴趣的,每个主题也可能与其他主题相关。如果将一对一聊天看做是“单线程的”,即同一时间只存在一个用户查询(query)和一个主题;那么群聊更像是“多线程的”,即同一时间存在多个活跃主题、多个活跃用户以及它们之间(主题之间、用户之间、主题与用户之间)可能的相互关系。
此外,我们还需要管理:(1)主题之间的关系,例如,从“聚会”到“订饭店”,并且进一步到“食物菜单”,“酒水菜单”,或者关于如何达到聚会地点或者附近的地铁站的“行程”,甚至是“聚会”之后的下一个活动,例如,去ktv唱歌;(2)用户之间的关系;以及(3)用户与主题之间的“结合率”,例如,各个用户对于主题的态度以及相关程度等等。
特别地,下面介绍一下用于群聊的聊天机器人可能需要应对的情况或者任务。。
1、来自每个用户id的非连续的用户查询(也可以称为用户发言或者用户提问)。群聊中的用户发送一个用户查询之后,在聊天机器人能够准备好针对该用户查询的相关答复之前,其他人的用户查询可能会以不可预计的方式发送到群聊中。为了处理该情况,聊天机器人需要按用户和主题来分别管理消息,形成两种类型的用户专用“存储”资源和主题专用“存储”资源。此外,需要注意到的是,一个用户的用户查询可能是对另一用户具有提问性质的用户查询的“答复”。甚至对于一个主题来说,该主题的用户查询也能够扮演诸如主题的开始、主题的延伸、主题的正面/反面评论、主题的执行、主题的结束和评论等不同“角色”,这些“角色”体现了主题的不同状态。对用户查询在主题中扮演的“角色”进行识别/分辨是非常重要的,如果一个用户查询是对于群聊中另一用户查询的“答复”,那么我们实际上能够利用当前群聊场景中的该“问题-答案”关系来用于帮助收集针对群聊的机器学习模型的训练数据(该机器学习模型用于基于当前群聊会话,自动地检测具有提问性质的用户查询及针对该提问的答复)。
2、来自群聊的连续消息。不同的主题也可能以不可预计的方式出现,在“活跃”的主题当中很可能存在主题之间的“潜在的联系”。
针对这种并行但是可能具有相关关联关系的主题,聊天机器人需要对主题的相关信息进行存储,并且在处理某一个主题相时,访问另一主题的存储信息,以获取主题间的关联关系,用于生成更好地适合当前群聊会话情景的答复。
3、聊天机器人的可察觉信息。例如,时间戳(timestamp)、用户id/聊天机器人id(userid/chatbotid)(,用户查询(qurey)等。聊天机器人需要能够识别出上述信息,即识别出何时、针对哪个用户以及针对哪个主题给出相应的答复。
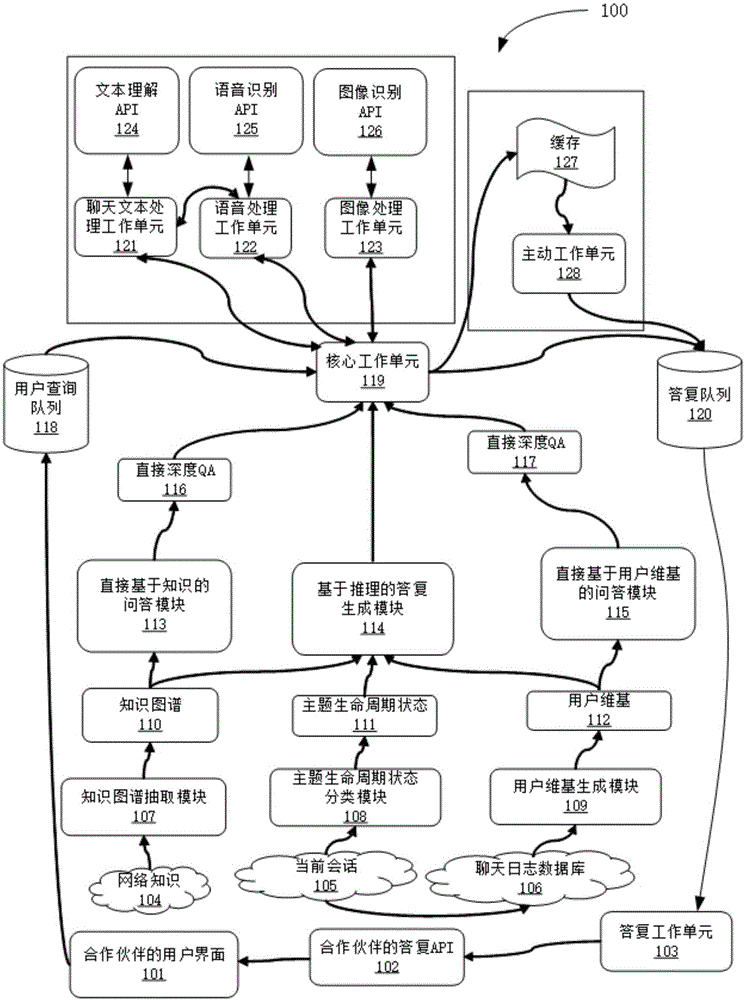
针对上述的需求,本文提出了如图1所示的ai聊天系统的示例性框架100。
图1所示的场景中,合作伙伴的用户界面101用于接收用户查询,这里的用户界面101可以来自于合作伙伴(例如,现有的社交网络、脸谱、微信、line、linkedin(领英)、slack)提供的用户界面,也可以是自己开发的用户界面(基于移动终端或者pc端的用户界面)。如图2所示,其为示例性的群聊界面示意框图200。左侧发言者不限于一个用户或者一个聊天机器人,可以是多个用户和一个聊天机器人,或者多个用户和多个聊天机器人。
图2所示的群聊用户界面中,存在三个真实世界的用户(“keizo”、“mike”以及“我”)和一个聊天机器人(例如名字叫做“小冰”)。右侧用户(或“我”)是加入群聊的用户,并且用户界面是从“我”的视角所看到的。在该示例中,聊天机器人“小冰”以非常主动的方式回答每个用户的用户查询。其中,聊天机器人“小冰”可以在不同国家使用不同的名字,例如:在中国地区使用“小冰”或者“xiaoice”作为名字,在日本和印尼使用“rinna”或者“凛菜”作为名字、在美国使用“zo”作为名字,在印度使用“ruuh”作为名字等。
在用户输入区域中,用户能够进行输入文本、发送图片,选择表情符号以及对当前画面进行截图等操作。此外,还可以与ai聊天系统发起语音通话或视频通话。例如,在用户界面中,用户输入了“小冰,你多大了”,该句子作为一个用户查询被传输到用户查询队列118,其中,用户查询队列118可以以多媒体格式(可以包括文本、语音、图像以及视频等方式)存储用户查询。ai聊天系统在处理多种多媒体输入方面,可以存在着一些差异。例如,对于实时语音和视频,ai聊天系统需要更多的工作单元(worker)的副本,以确保该用户查询队列118用户查询列表不会过长,如果用户查询队列118中的过长,则用户会感觉到较长的答复延迟。例如,图1中针对文本、语音以及图像,分别设置了聊天文本处理工作单元121、语音处理工作单元122、图像处理工作单元123,这三个处理单元可以调用与各自对应的文本理解api(应用程序接口)124、语音识别api125、图像识别api126来执行程序处理,并且,这三个工作单元可以接受核心工作单元119的调度和协调。上述的工作单元可以根据需要具体化为程序模块、实例、线程、进程等。
图1中的核心工作单元(coreworker)119将用户查询队列118作为其输入,以先进先出的方式对该用户查询队列118中的用户查询进行处理以生成答复。
基本上,核心工作单元119可以逐一地调用各个工作单元进行有关用户查询的相关处理。例如,核心工作单元119可以调用聊天文本处理工作单元121,执行针对文本形式的用户查询的处理,进一步地,核心工作单元119还可以调用文本理解api124对聊天上下文信息进行处理。此外,聊天文本处理工作单元121还可以包括多个聊天文本处理功能以外的服务单元,例如,时间服务单元,可以针对诸如“请在六点提醒我去hr会议”的用户查询,生成闹钟提醒,再例如天气服务单元,用于针对诸如“明天会下雨么?”、“我明天飞往北京需要带雨伞吗?”的用户查询,提供天气信息方面的答复。
语音形式的用户查询需要被识别并解码为文本才能进行后续处理。语音识别api125用于进行语音到文本的转换任务。此外,在从语音解码出文本之后,语音处理工作单元122将请求聊天文本处理工作单元121执行语言理解、请求分析和答复生成等处理。在聊天文本处理工作单元12生成了答复文本并且返回给语音处理工作单元122之后,语音处理工作单元122将执行文本到语音的转换,并生成能够使用户听到的语音输出。
与语音处理类似地,图像也需要通过图像识别api126来“阅读”和“理解”。即,图像需要被解码为文本。例如,当看到用户输入的狗图像时,图像识别api126能够大概识别出狗的类型/颜色,并以文本形式输出识别出的信息,然后,图像处理工作单元123再根据这些文本形式的图像识别信息,生成答复。当然,由于图像到文本机器学习模型较为成熟,可以直接根据图像生成相应的答复,而不需要再调用图像处理工作单元123进行答复生成的处理,即可以通过图像识别api126直接根据输入的图像生成一些评论或建议作为回复,例如,“好可爱的德国牧羊犬!你一定很爱它”。由于图像到文本模型能够直接训练/使用,因此,对于图像处理工作单元123的访问是可选的。
在图1所示的框架中,还可以插入除了前面介绍的基本的工作单元之外的其他工作单元,从而使得框架具有可扩展。例如,可以插入位置处理工作单元,基于位置处理工作单元能够容易地支持基于位置的服务,例如,针对“订个披萨到我办公室”、“当我快到家时在我接近超市时提醒我”这样的用户查询,可以将位置信息引入到答复的生成处理中,从而能够提供更加灵活的答复方式。
核心工作单元119生成答复后,传输至答复队列120和/或放入缓存127。
缓存127和主动工作单元(proactiveworker)128用于提前准备好答复的序列,从而能够以预先确定的时间流呈现给用户。对于一个用户查询来说,如果存在不超过两个由核心工作单元119生成的答复,则需要对这些答复进行时间延迟设置。
例如,如果用户说“小冰,你吃早饭了么”,并且ai聊天系统生成了两个答复,第一个是“是的,我吃了面包”,并且第二个是“你呢,还是觉得饿么?”。我们需要将第一个答复立即呈现给用户,而对于第二个答复,可以将时间延迟设置为2秒,并通过主动工作单元128来控制将答复放入答复队列120的时机。从而在向用户呈现了第一个答复之后2秒后,将第二个答复展示给用户。缓存127和主动工作单元128一起管理这些待发送的答复、用户的身份以及每个答复的时间延迟。
答复工作单元103从答复队列120中选择一个最优的答复,然后,可以调用合作伙伴的答复api102,将生成的答复提供给合作伙伴的用户界面101呈现给用户。
特别地,图1中还涉及如下几个本文的核心处理模块:
用户维基生成模块109,用于利用用户维基构建算法从已有的聊天日志数据库106提取用户维基112。此外,用户维基生成模块109还会从与用户相关的社交网络的公开信息中提取用户维基112。
主题生命周期状态分类模块108,用于通过采用主题生命周期状态分类算法,来从当前会话105检测主题生命周期状态111。
知识图谱抽取模块107,用于通过使用知识图谱提取算法从网络知识104中挖掘常用领域的知识图谱110。
基于推理的答复生成模块114,用于整合用户维基112、主题生命周期状态111和常用领域的知识图谱110,将这三方面信息应用到答复生成的处理过程中,以生成对于当前群聊场景的最佳答复。
需要注意的是,本文还可以提供基于用户维基112和常用领域的知识图图谱的直接深度问答(qa)功能。例如,一个直接的问题“小冰,你知道我的宠物的名字么?”,而答复可以是“joy,你上周告诉我了”,这是基于用户维基的深度问答功能,再例如,另一问题是“小冰,美国的第一任总统是谁?”,而答复为“乔治华盛顿”,这是基于常用领域的知识图谱而提供的直接深度问答功能。
下面将分别详细介绍一下用户维基生成、主题生命周期状态分类、知识图谱抽取以及基于推理的答复生成这几方面的处理机制。
用户维基生成
用户维基提取的目标在于,基于下面的信息源以维基形式构建用户档案:
1、一对一个人聊天场景中用户和聊天机器人的聊天日志。
2、用户加入的聊天群中用户与聊天机器人的聊天日志。
3、以显式/隐式方式,获得的用户的社交网络信息。
a、隐式方式:例如,“我们来自同一大学”是用于将用户a的已知大学指派给用户b的隐式线索,假设能够知道(1)“我们”表示用户a和用户b,并且(2)用户a的大学是已经知道的。可以将此命名为“实体转移规则”,从而可以使用该规则来从具有相对完善的用户维基档案的种子用户,延伸到用户维基档案相对不完善的关系用户。
b、显式方式:对于另一示例,在一些社交网络应用中,例如,在linkedin上,用户的大学信息能够在由linkedin整理的简历中显式地公开,从而能够以显式方式获得用户维基档案信息的一个示例。
如图3所示,其为示例性的名人“乔治华盛顿”用户维基档案的示例框图300。图3的维基档案以键值对信息的形式进行整理,其中,键值对信息中的键对应了用户属性中涉及的一些实体,例如出生信息、居住地、获得荣誉等,键值对信息中的值所涉及的信息,例如,“1732年2月22日”、“华盛顿……”、“国会金质奖章”。
这些键值对形式的信息整理方法,也被诸如linkedin等若干社交网络应用采用,如图4所示,linkedin中用于“比尔盖茨”的用户维基档案示例框图400。
下面介绍一下提取用户维基档案的处理过程。如图5所示,其为描述性的用户维基档案的提取过程的流程处理示意图500。
为了从用户的聊天日志和社交网络挖掘用户维基信息,本文提出了一种数据收集途径以及一种机器学习模型(图5中的键值对档案分类器505)。
数据收集途径如图5中,左侧所示出的处理过程s501~s505,其中,s501~s503的处理用来收集训练键值对档案分类器505的训练数据,s504的所收集的数据和用户的聊天日志一起作为键值对档案分类器505的输入数据。在本文中,主要使用到社交网络中的两类信息,一类是档案信息,这类信息是经过社交网络整理的知识类信息(例如维基百科)或者用户账户的公开信息(如图3或者图4中的档案信息示例),这两种信息可以认为是可信的,可以作为事实基础。另一种是内容信息,也就是用户在社交网络上发布的信息,比如推文、脸书上的帖子等。
下面介绍一下用户维基档案提取的详细处理过程:
s501:从社交网络的档案信息中获取键值对信息。例如,从谷歌+,linkedin,脸书等社交网络的用户维基档案中获取一些键值对信息,这些键值对信息可以作为基础事实。
s502:获得包含处理过程s501中的键值对信息中的值的社交网络的内容信息,例如,获取包含“哈佛大学”的比尔盖茨的推文。这些推文作可以作为正面示例。
s503:解析处理过程s502中获取的社交网络的内容信息的句法依赖关系并且提取结构特征(例如,n元依赖关系弧),生成用于训练键值对档案分类器的特征训练数据。
s504:使用处理过程s503中生成的训练数据对机器学习分类器进行训练,生成键值对档案分类器。有了处理过程s503生成的特征训练数据以及处理过程s501中获取的能够作为基础事实的键值对信息,就可以对机器学习分类器进行训练,生成键值对档案分类器。在后续使用键值对档案分类器进行在线处理的过程中,也可以根据在线处理获得的结果继续对键值对档案分类器进行训练,从而使得键值对档案分类器对数据的处理更加准确。
上述的处理过程s501~s503完成了针对键值对档案分类器506的训练过程,并且也获得一些键集合,
s505:从用户的社交网络的内容信息中获取与用户相关的键值对信息。在该处理过程中,可以根据已经确定的键集合和实体转移规则,来从例如用户的推文、脸书、linkedin上发布的内容信息中获取键值对信息。本文中的实体转移规则:是将已经确定的用户的键值对信息(例如前面提到的名人的维基档案信息)和该用户的社交网络的内容信息(例如,该名人发布的推文)之间的对应规律或者结构特征等,应用在社交网络中,并进行种子用户的延伸,从而提取出更多的键值对信息。
s506:将处理过程s505获取的键值对信息和用户的聊天日志输入到键值对档案分类器中进行处理,输出将键值对信息指派给用户作为用户维基档案的正确率。
如图6所示,其为本文的用户推文的示例框图600。通过对该名为斯蒂文(steven)的推文的分析,其在推文中使用了“我也要去usc”的表达,usc识别为大学名称,并且其使用了某已知用户的推文的类似的表达“去usc”,而该已知用户的维基档案信息中,包含了作为确认信息的“大学-usc”这样的键值对。从而,可以基于“实体转移规则”,将“大学-usc”的键值对信息指派给用户斯蒂文,不过基于实体转移规则的用户维基档案不能够被信任为100%正确,需要利用经过训练的键值对档案分类器来对将“大学-usc”的键值对信息指派给用户斯蒂文作为用户维基档案的正确率,根据该正确率再最终确认是否将采信该键值对信息。
如图7所示,其为示例性的键值对档案分类器的应用示意框图700。图7中,键值对档案分类器701的输入数据为键值对信息702和用户的聊天日志703,其输出为键值对信息702被分配给用户的正确率704(将该键值对信息作为用户维基档案的正确率),以及扩展的训练数据705,该训练数据可以对键值对档案分类器701进行进一步训练,以提高键值对档案分类器701准确性。
在输入到键值对档案分类器701之前,还会进行一下特征提取,生成特征向量,然后再输入到键值对档案分类器701中进行处理。
键值对档案分类器701的输入数据,例如为:<user(用户信息),key(键值对信息中的键),value(键值对信息中的值),userlog(从个人或者群组聊天中获取的会话日志),usersocialnetworks(用户的社交网络信息)>。这些输入数据通过键值对档案分类器701处理后,输出将键值对信息<key,value>分配给当前用户作为维基档案的正确率,例如,如果正确率大于0.5可以认为能够作为该用户的维基档案。
此外,在进行特征提取的过程中,可以使用如下特征模板,该特征模块包括下面的特征集合,特征集合中各个特征项目可以任意进行组合,即选择其中的一项或者任意多项的组合形成特征模块:
1、键值对<key,value>在当前用户的档案数据库中出现的频率;
2、键值对<key,value>在与当前用户具有社会关系的其他用户的社交网络的内容信息中出现的频率;
3、键值对<key,value>在当前用户的聊天日志中被提及的频率。
4、键与值的稠密向量之间的文本词向量余弦相似度分数。
5、当前用户的聊天日志中的键与值之间的平均距离(距离=一个用户查询/文本消息中键与值之间的单词的数目)。
6、键值对信息中的键;
7、键值对信息中的值;
8、键值对信息<key,value>;
9、当前用户在其维基档案已经具有键;
10、作为输入数据的键值对信息中的值与当前用户的维基档案中的当前的键的现有值之间的编辑距离相似度;
11、当前用户的维基档案中当前的键的现有值与作为输入数据的键值对信息中的值之间的文本词向量相似度。
主题生命周期状态分类
本文训练了用于对一个主题的生命周期状态进行分类的多层循环神经网络(rnn)。如前所述,将一个主题的生命周期分类为多个潜在时间敏感状态,例如“开始、生长或退化,结束或取消,讨论后”,主题的生命周期就是从一个状态转换到下一个状态。例如,我们使用下面两个示例示出了这些状态。
场景1:
用户:我感到孤独;
聊天机器人:看个电影怎么样?(聊天机器人的主题的开始,“看个电影”这个答复可以是根据知识图谱中的三元组“看个电影→治愈→孤独”来生成的),(主题=看个电影,状态=开始);
用户:好的,有什么建议(关于看电影)?(主题=看个电影,状态=延伸);
聊天机器人:“蜘蛛侠”怎么样,最晚的一场?(主题=蜘蛛侠,状态=开始;父主题=看个电影,状态=延伸);
用户:听起来不错(主题=蜘蛛侠,状态=正面意图;父主题=看个电影,状态=延伸);
聊天机器人:最近的电影院要十分钟的距离并且下一场是30分钟后开始,你要买票么?(主题=票,状态=开始;父主题=蜘蛛侠,状态=正面意图;第二父主题=看个电影,状态=延伸);
用户:当然,订吧(主题=票,状态=确认;父主题=蜘蛛侠,状态=正面意图;第二父主题=看个电影,状态=延伸);
聊天机器人:好的,订了并且这里有一个电影的视频简介;
(一天后)
用户:电影很有趣(主题=蜘蛛侠,状态=结束并且正面评论;第二父主题=看个电影,状态=结束);
聊天机器人:我很高兴你喜欢这个电影。
场景2
用户:我感到孤独;
聊天机器人:看个电影怎么样?(聊天机器人的主题的开始),(主题=看个电影,状态=开始);
用户:不感兴趣(对于看电影)(主题=看个电影,状态=反面意图);
聊天机器人:那蓝调音乐如何?(主题=蓝调音乐,状态=开始;“蓝调音乐”这个答复可以是根据知识图谱中的三元组“蓝调音乐→搭配→孤独”来生成的);
用户:听起来不错(主题=蓝调音乐,状态=正面意图);
(这里播放音乐)
用户:我喜欢这个(主题=蓝调音乐,状态=结束且正面评论)。
从场景1和场景2容易发现的是,主题检测和主题的生命周期状态能够有助于引导聊天机器人进行接下来答复以及总结如何给用户长时间聊天的主题。而且,需要注意的是,可用主题的范围可以通过一些知识图谱来获取。
主题的生命周期状态的数目可以根据需要而设定,并且可以通过使用细粒度的情感分析系统来执行正面/反面评论分析。
本文利用了分级的循环神经网络(rnn)来编码会话信息并且通过softmax函数将对会话进行编码后的嵌入向量投射到候选状态的列表中。
如图8所示,其为针对主题的生命周期状态进行处理的神经网络装置的结构示意图,其包括输入层处理模块801、句子内rnn层802、句子间rnn层803、softmax函数处理模型804。
输入层处理模块801,用于将会话中的多个句子中的每个词进行向量化,生成句子的词向量表示;
句子内rnn层处理模块802,用于对多个句子的词向量表示进行处理,生成整个句子的句子向量表示;
句子间rnn层处理模块803,用于将句子内rnn层输出的多个句子向量表示进行处理,输出会话的会话向量表示;
softmax函数处理模块804,用于根据会话向量表示确定给定生命周期状态列表中各个标题对应的状态概率。
如图9所示,其示例性的描述了通过四层神经网络实施的分类模型的示意框图900。在该图中,每个矩形代表向量,箭头表示诸如矩阵向量乘法的函数。图9中各层的向量是由图8中各个模块处理生成的,具体的:
(1)输入层901:该层数据的处理由图8中的输入层处理模块801执行。在输入层901中,将会话中的多个句子(图中用句子1~m表示)中的每个词进行向量化,生成句子的词向量表示。
输入层可以表示为一组向量inputx:
inputx=[x1/t1,x2/t2,…,xm/tm]…………………………………式(1)
其中,x1~xm为每个句子1~m对应的词向量表示,t1~tm表示每个句子对应的主题,主题t1~tm可能存在相同的主题。在每个句子对应的词向量表示中,也是包含了多个向量(或者说是多个向量构成的矩阵),以句子1为例,其对应的词向量包括向量w1,1~w1,n1、句子2对应的词向量包括向量w2,1~w2,n2、句子m对应的词向量包括向量wm,1~wm,nm。
(2)句子内rnn层902。该层的处理由图8中的句子内rnn层802。该层的目的在于生成整个句子到向量的嵌入。该层中针对每个句子采用双向并发(bi-directionalrecurrent)的rnn处理,公式表示如下:
ht+1=rnn(whhht+wxhxt+bh)………………………………式(2)
其中,whh、wxh以及bh为从输入层901到句子内rnn层902的变换参数,向量ht可以视为每轮计算生成的上下文向量表示,向量xt对应每轮计算时用到的句子中的词向量。
设t为用于展开循环轮次的步骤的数目,并且向量ht是经过句子内rnn层902的处理生成最终向量,需要注意的是,在两个方向上执行循环运算,即,从左到右和从右到左。因此,向量ht是两个方向上的向量的级联形成的结果:
ht=[htleft-to-right,htright-to-left]t……………………………………式(3)
(3)句子间rnn层903。该层的处理由图8中的句子间rnn层处理模块803。该层处理的目的在于获得整个会话的稠密向量表示。与前一层采用的算法一样,仍然是从前层获取向量ht作为输入,双向并发(bi-directionalrecurrent)的rnn处理,生成各个句子对应的向量表示g1~gm,然后对向量g1~gm进行拼接,生成对应于整个会话的向量j。其中,m是输入会话中句子的数目。
(4)输出层904。在输出层904中,将句子间rnn层903生成的向量j输入到softmax函数中进行处理,生成主题t1到主题tm的状态概率列表(共有m个主题),在该状态概率列表中,每个主题t对应于k个状态,每个状态对应于一个概率值pi,因此,i的范围从(1,1)到(m,k),softmax函数输出的状态概率列表是一个m×k的概率值矩阵。
知识图谱
在本文中,采用的知识图谱的主要为基于概念的知识图谱,如图10所示,其为本文基于概念的知识图谱示例性框图1000。图中,使用多个图来直观地表达概念,例如,火车,狗,猫,老鼠,视窗,ie等等。
基本上来说,图中的一个节点是对应于一个真实世界对象的“概念”,其是可看见或仅可思考的。例如,“狗”是这样的可看见的概念而“经济”是不具有直接可见形式的,是仅能够在思想上进行推断/思考的概念。另一方面,图中的一个边是图形中两个节点之间的“谓语形式”或“属性形式”的关系描述。
基于推理的答复生成模型
如图11所示,其为本文中基于推理的答复生成模型的示例性结构框图1100。其中,模型在接收到用户查询1101后,通过使用注意力函数f1,针对存储向量m(基于外部存储源而生成的向量)进行多轮次的迭代处理,从而生成较为优化的答复。下面将对模型的处理机制进行详细说明。
存储向量m:
外部存储被向量化后,表示为存储向量m。存储向量m是词向量的列表,m={mi},其中i=1…n,其中,mi是固定维度向量。例如,在推理图的搜索空间中,mi是每个词或者知识的向量表示。这些向量表示来源于双向rnn编码器对外部知识、上下文等的向量化编码。在图11中,存储向量m可以来自四个存储源,并且每个存储源具体为表示相关词序列或依赖关系弧的单词向量的列表。
其中,外部存储源包括:用户维基档案存储1105、会话存储1106、主题生命周期状态存储1107、开放领域的知识图谱1108,这些存储源在本文的前部分也都介绍过。
注意力向量xt:
注意力向量xt是基于当前内部状态向量st和存储向量m,通过注意力函数f1生成的,具体函数关系可以表示为:
xt=f1(st,m)……………………………………………………式(4)
内部状态向量st:
通常初始状态s1是用户输入的用户查询的最后单词向量表示,内部状态向量的第t个时间步骤由st表示。内部状态向量的顺序由rnn建模,具体函数关系可以表示为:
st+1=rnn(st,xt)………………………………………………式(5)
其中,xt是前述的注意力向量。
终止门:
终止门根据当前的内部状态向量st生成随机变量tt=p(f2(st)),tt是双值随机变量(tt=0表示状态未结束或者tt=1表示状态结束),函数f2是一个单层神经网络,用于判断st是否到了结束的状态,函数p为sigmoid函数,相当于把函数f2的输出结果映射到[0,1]概率区间上。如果tt为真(true),则模型停止进行下一轮次的处理,并由答复生成模块1104在时间步骤t执行答复解码的处理,生成答复;如果tt为假(false),则根据式(4)更新注意力向量xt+1,并且将该向量馈送到状态网络以更新下一内部状态st+1。
答复生成模块1104:答复生成模块1104的动作是在终止门变量为真时触发,通过函数rnn解码器来逐词生成作为答复的句子。具体函数关系可以表示为:
at=p(f3(st))………………………………………………式(6)
其中,at代表答复中的第t个词,函数f3为rnn解码器,函数p在这里表示softmax函数,用于输出答复中每个候选词的概率分布。
此外,本文还使用两个sigmoid函数来计算两个状态:
意图状态1102:意图状态包括情绪关怀或者任务取向,f4=sigmoid(w4*st+b4),其中,w4和b4为线性组合模型的参数,其中w4是映射矩阵参数,b4是偏移量参数。
答复状态1103:答复为是,未答复为否。f5=sigmoid(w5*f4+b5),w5和b5为线性组合模型的参数,其中w5是映射矩阵参数,b5是偏移量参数。
上述的基于推理的答复生成模型可以实现为一种答复生成装置,如图12所示,其为本文提供的基于推理的答复生成装置的结构示意图1200,该装置包括注意力模型处理模块1201、内部状态向量生成模块1202、逻辑回归判别模块1203,注意力模型处理模块和内部状态向量生成模块在逻辑回归判别模块的控制下,进行多轮次的内部状态向量的迭代处理,
注意力模型处理模块1201,用于根据当前轮次的内部状态向量和外部存储向量生成当前轮次的注意力向量。
内部状态向量生成模块1202,用于至少根据用户查询向量生成初始的内部状态向量,并至少根据前一轮次的内部状态向量和当前轮次的注意力向量生成当前轮次的内部状态向量。具体地,内部状态向量生成模块的处理可以进一步具体为:根据用户查询向量、基于用户查询向量生成的初始的意图状态向量以及初始的回复状态向量,生成初始的内部状态向量,并根据前一轮次的内部状态向量、基于该前一轮次的内部状态向量生成的当前轮次的注意力向量生成当前轮次的内部状态向量。其中,意图状态向量可以包含情绪关怀和/或任务取向方面的信息。注意力模型处理模块1201和内部状态向量生成模块1202之间会进行多轮次的循环迭代处理,直至逻辑回归判别模块1203判定满足了终止条件。
逻辑回归判别模块1203,用于对当前轮次的内部状态向量进行判别,确定是否终止迭代处理。
另外,还可以包括答复信息生成模块1204,用于在迭代处理终止时,根据最终轮次的内部状态向量,生成答复信息。
此外,还可以包括存储向量生成模块1205,用于根据用户维基存储数据、会话内容存储数据、会话主题存储数据以及开放领域知识存储数据中的一项或者任意多项的组合,生成外部存储向量。
电子装置实现示例
本文的电子装置可以是具有可移动性的电子设备,也可以是较少移动的或者非移动的计算设备。本文的电子装置至少具有处理单元和存储器,存储器上存储有指令,处理单元从存储器上获取指令,并执行处理,以使电子装置执行动作。
在一些例子中,上述图1至图12涉及的一个或多个模块或者一个或多个步骤或者一个或多个处理过程,可以通过软件程序、硬件电路,也可以通过软件程序和硬件电路相结合的方式来实现。例如,上述各个组件或者模块以及一个或多个步骤都可在芯片上系统(soc)中实现。soc可包括:集成电路芯片,该集成电路芯片包括以下一个或多个:处理单元(如中央处理单元(cpu)、微控制器、微处理单元、数字信号处理单元(dsp)等)、存储器、一个或多个通信接口、和/或用于执行其功能的进一步的电路和可任选的嵌入的固件。
如图13所示,其为示例性的具有可移动性的电子设备1300的结构框图。该电子设备1300可以是小型因素便携式(或移动)电子设备。这里所说的小型因素便携式(或移动)电子设备可以是:例如,蜂窝电话、个人数据助理(pda)、笔记本电脑、平板电脑、个人媒体播放器装置、无线网络观看装置、个人头戴装置、专用装置或包括以上功能中的任何一个的混合装置。电子设备1300至少包括:存储器1301和处理器1302。
存储器1301,用于存储程序。除上述程序之外,存储器1301还可被配置为存储其它各种数据以支持在电子设备1300上的操作。这些数据的示例包括用于在电子设备1300上操作的任何应用程序或方法的指令,联系人数据,电话簿数据,消息,图片,视频等。
存储器1301可以由任何类型的易失性或非易失性存储设备或者它们的组合实现,如静态随机存取存储器(sram),电可擦除可编程只读存储器(eeprom),可擦除可编程只读存储器(eprom),可编程只读存储器(prom),只读存储器(rom),磁存储器,快闪存储器,磁盘或光盘。
存储器1301耦合至处理器1302并且包含存储于其上的指令,所说的指令在由处理器1302执行时使电子设备执行动作,作为一种电子设备的实施例,该动作可以包括:实现图1至图12对应的示例所执行的相关处理流程、处理逻辑以及程序模块等。该电子设备1300可以作为分布式系统中的主机和/或交换机执行相应的功能逻辑。
对于上述的处理操作,在前面方法和装置的实施例中已经进行了详细说明,对于上述的处理操作的详细内容同样也适用于电子设备1300中,即可以将前面实施例中提到的具体处理操作,以程序的方式写入在存储器1301,并通过处理器1302来进行执行。
进一步,如图13所示,电子设备1300还可以包括:通信组件1303、电源组件1304、音频组件1305、显示器1306、芯片组1307等其它组件。图13中仅示意性给出部分组件,并不意味着电子设备1300只包括图13所示组件。
通信组件1303被配置为便于电子设备1300和其他设备之间有线或无线方式的通信。电子设备可以接入基于通信标准的无线网络,如wifi,2g、3g、4g以及5g或它们的组合。在一个示例性实施例中,通信组件1303经由广播信道接收来自外部广播管理系统的广播信号或广播相关信息。在一个示例性实施例中,通信组件1303还包括近场通信(nfc)模块,以促进短程通信。例如,在nfc模块可基于射频识别(rfid)技术,红外数据协会(irda)技术,超宽带(uwb)技术,蓝牙(bt)技术和其他技术来实现。
电源组件1304,为电子设备的各种组件提供电力。电源组件1304可以包括电源管理系统,一个或多个电源,及其他与为电子设备生成、管理和分配电力相关联的组件。
音频组件1305被配置为输出和/或输入音频信号。例如,音频组件1305包括一个麦克风(mic),当电子设备处于操作模式,如呼叫模式、记录模式和语音识别模式时,麦克风被配置为接收外部音频信号。所接收的音频信号可以被进一步存储在存储器1301或经由通信组件1303发送。在一些实施例中,音频组件1305还包括一个扬声器,用于输出音频信号。
显示器1306包括屏幕,其屏幕可以包括液晶显示器(lcd)和触摸面板(tp)。如果屏幕包括触摸面板,屏幕可以被实现为触摸屏,以接收来自用户的输入信号。触摸面板包括一个或多个触摸传感器以感测触摸、滑动和触摸面板上的手势。触摸传感器可以不仅感测触摸或滑动动作的边界,而且还检测与触摸或滑动操作相关的持续时间和压力。
上述的存储器1301、处理器1302、通信组件1303、电源组件1304、音频组件1305以及显示器1306可以与芯片组1307连接。芯片组1307可以提供处理器1302与电子设备1300中的其余组件之间的接口。此外,芯片组1307还可以提供电子设备1300中的各个组件对存储器1301的访问接口以及各个组件间相互访问的通讯接口。
在一些例子中,上述图1至图12涉及的一个或多个模块或者一个或多个步骤或者一个或多个处理过程,可以通过具有操作系统和硬件配置的计算设备来实现。
图14其为示例性的计算设备1400的结构框图。例如,本文中的交换机和主机(发送端主机和接收端主机)可在与静态计算机实施例中的计算设备1400相似的一个或多个计算设备中实现,包括计算设备1400的一个或多个特征和/或替代特征。此处所提供的对计算机1400的描述只是为了说明,并不是限制性的。实施例也可以在相关领域的技术人员所知的其它类型的计算机系统中实现。
如图14所示,计算设备1400包括一个或多个处理器1402、系统存储器1404,以及将包括系统存储器1404的各种系统组件耦合到处理器1402的总线1406。总线1406表示若干类型的总线结构中的任何一种总线结构的一个或多个,包括存储器总线或存储器控制器、外围总线、加速图形端口,以及处理器或使用各种总线体系结构中的任何一种的局部总线。系统存储器1404包括只读存储器(rom)1408和随机存取存储器(ram)1410。基本输入/输出系统1412(bios)储存在rom1408中。
计算机系统1400还具有一个或多个以下驱动器:用于读写硬盘的硬盘驱动器1414、用于读或写可移动磁盘1418的磁盘驱动器1416、以及用于读或写诸如cdrom、dvdrom或其他光介质之类的可移动光盘1422的光盘驱动器1420。硬盘驱动器1414、磁盘驱动器1416,以及光驱动器1420分别通过硬盘驱动器接口1424、磁盘驱动器接口1426,以及光学驱动器接口1428连接到总线1406。驱动器以及它们相关联的计算机可读介质为计算机提供了对计算机可读指令、数据结构、程序模块,及其他数据的非易失存储器。虽然描述了硬盘、可移动磁盘和可移动光盘,但是,也可以使用诸如闪存卡、数字视频盘、随机存取存储器(ram)、只读存储器(rom)等等之类的其他类型的计算机可读存储介质来储存数据。
数个程序模块可被储存在硬盘、磁盘、光盘、rom或ram上。这些程序包括操作系统1430、一个或多个应用程序1432、其他程序1434以及程序数据1436。这些程序可包括例如用于实现图1至图12对应的示例所执行的相关处理流程、处理逻辑以及程序模块等的程序。
用户可以通过诸如键盘1438和指点设备1440之类的输入设备向计算设备1400中输入命令和信息。其它输入设备(未示出)可包括话筒、控制杆、游戏手柄、卫星天线、扫描仪、触摸屏和/或触摸平板、用于接收语音输入的语音识别系统、用于接收手势输入的手势识别系统、诸如此类。这些及其他输入设备可通过耦合到总线1406的串行端口接口1442连接到处理器1402,但也可以通过其他接口(诸如并行端口、游戏端口、通用串行总线(usb)端口)来进行连接。
显示屏1444也通过诸如视频适配器1446之类的接口连接到总线1406。显示屏1444可在计算设备1400外部或纳入其中。显示屏1444可显示信息,以及作为用于接收用户命令和/或其它信息(例如,通过触摸、手指姿势、虚拟键盘等等)的用户界面。除了显示屏1444之外,计算设备1400还可包括其他外围输出设备(未示出),如扬声器和打印机。
计算机1400通过适配器或网络接口1450、调制解调器1452、或用于通过网络建立通信的其他手段连接到网络1448(例如,因特网)。可以是内置的或外置的调制解调器1452可以经由串行端口接口1442连接到总线1406,如图14所示,或者可以使用包括并行接口的另一接口类型连接到总线1406。
如此处所用的,术语“计算机程序介质”、“计算机可读介质”以及“计算机可读存储介质”被用于泛指介质,诸如与硬盘驱动器1414相关联的硬盘、可移动磁盘1418、可移动光盘1422、系统存储器1404、闪存卡、数字视频盘、随机读取存储器(ram)、只读存储器(rom)以及其它类型的物理/有形存储介质等。这些计算机可读存储介质与通信介质(不包括通信介质)相区别且不重叠。通信介质通常在诸如载波等已调制数据信号中承载计算机可读指令、数据结构、程序模块或者其它数据。术语“已调制数据信号”是指使得以在信号中编码信息的方式来设定或改变其一个或多个特征的信号。作为示例而非限制,通信介质包括诸如声学、rf、红外线的无线介质和其它无线介质以及有线介质。各个实施例也针对这些通信介质。
如上文所指示的,计算机程序和模块(包括应用程序1432及其他程序1434)可被储存在硬盘、磁盘、光盘、rom或ram上。这样的计算机程序也可以通过网络接口1450、串行端口接口1442或任何其他接口类型来接收。这些计算机程序在由应用程序执行或加载时使得计算机1400能够实现此处所讨论的实施例的特征。因此,这些计算机程序表示计算机系统1400的控制器。
这样,各个实施例还涉及包括储存在任何计算机可用存储介质上的计算机指令/代码的计算机程序产品。这样的代码/指令当在一个或多个数据处理设备中执行时,使数据处理设备如此处所描述的那样操作。可包括计算机可读存储介质的计算机可读存储设备的示例包括诸如ram、硬盘驱动器、软盘驱动器、cdrom驱动器、dvddom驱动器、压缩盘驱动器、磁带驱动器、磁性存储设备驱动器、光学存储设备驱动器、mem设备、基于纳米技术的存储设备等的存储设备以及其它类型的物理/有形计算机可读存储设备。
示例条款
a:一种装置,包括:注意力模型处理模块、内部状态向量生成模块、逻辑回归判别模块,所述注意力模型处理模块和内部状态向量生成模块在所述逻辑回归判别模块的控制下,进行多轮次的内部状态向量的迭代处理,
所述注意力模型处理模块,用于根据当前轮次的内部状态向量和外部存储向量生成当前轮次的注意力向量;
内部状态向量生成模块,用于至少根据用户查询向量生成初始的内部状态向量,并至少根据前一轮次的内部状态向量和当前轮次的注意力向量生成当前轮次的内部状态向量;
逻辑回归判别模块,用于对当前轮次的内部状态向量进行判别,确定是否终止迭代处理。
b:根据段落a所述的装置,其中,所述内部状态向量生成模块具体用于,根据用户查询向量、基于用户查询向量生成的初始的意图状态向量以及初始的回复状态向量,生成初始的内部状态向量,并根据前一轮次的内部状态向量、基于该前一轮次的内部状态向量生成的当前轮次的注意力向量生成当前轮次的内部状态向量。
c:根据段落a所述的装置,其中,还包括:外部存储信息向量生成模块,用于根据用户维基存储数据、会话内容存储数据、会话主题存储数据以及开放领域知识存储数据中的一项或者任意多项的组合,生成所述外部存储向量。
d:根据段落a所述的装置,其中,还包括:
答复信息生成模块,用于在迭代处理终止时,根据最终轮次的内部状态向量,生成答复信息。
e:根据段落b所述的装置,其中,所述意图状态向量包含情绪关怀和/或任务取向方面的信息。
f:一种方法,包括:
从用户的社交网络的第一内容信息中获取与用户相关的至少一个第一键值对信息,
将所述第一键值对信息和用户的聊天日志输入到键值对档案分类器中进行处理,输出所述至少一个第一键值对信息作为用户维基档案的正确率。
g:根据段落f所述的方法,其中,还包括:
从社交网络的档案信息中获取至少一个第二键值对信息;
获取包含所述第二键值对信息的值的社交网络的第二内容信息;
解析所述第二内容信息的句法依赖关系并提取结构特征,生成用于训练所述键值对档案分类器的特征训练数据,
使用所述训练数据对机器学习分类器进行训练,生成所述键值对档案分类器。
h:根据段落g所述的方法,其中,从用户的社交网络的第一内容信息中获取与用户相关的至少一个第一键值对信息包括:
根据预设的键集合,利用实体转移规则,从所述第一内容信息中获取所述第一键值对信息。
i:根据段落f所述的方法,其中,将所述第一键值对信息和用户的聊天记录输入到键值对档案分类器中进行处理包括:
根据预设的特征模板,对所述第一键值对信息和用户的聊天记录进行特征提取,生成特征向量,并输入到所述键值对档案分类器中进行处理,所述特征模板包括如下一项或者任意多项特征项目的组合:
所述第一键值对信息在用户的档案数据库中出现的频率;
所述第一键值对信息在与所述用户具有社会关系的其他用户的社交网络的内容信息中出现的频率;
所述第一键值对信息在所述用户的聊天日志中被提及的频率;
所述第一键值对信息中的键与值的稠密向量之间的文本词向量余弦相似度分数;
所述用户的聊天日志中的所述键与所述值之间的平均距离;
所述第一键值对信息中的键;
所述第一键值对信息中的值;
所述第一键值对信息;
所述用户当前的维基档案中是否已经具有所述第一键值对信息中的键;
所述第一键值对信息中的值与所述用户的维基档案中的键对应的值之间的编辑距离相似度;
所述用户当前的维基档案中键对应的值与所述第一键值对信息中的值之间的文本词向量相似度。
j:一种电子装置,包括:
处理单元;以及
存储器,耦合至所述处理单元并且包含存储于其上的指令,所述指令在由所述处理单元执行时使所述装置执行动作,所述动作包括:
从用户的社交网络的第一内容信息中获取与用户相关的至少一个第一键值对信息,
将所述第一键值对信息和用户的聊天日志输入到键值对档案分类器中进行处理,输出所述至少一个第一键值对信息能够作为用户维基档案的正确率。
k、根据段落j所述的电子装置,其中,所述动作还包括:
从社交网络的档案信息中获取至少一个第二键值对信息;
获取包含所述第二键值对信息的值的社交网络的第二内容信息;
解析所述第二内容信息的句法依赖关系并提取结构特征,生成用于训练所述键值对档案分类器的特征训练数据,
使用所述训练数据对机器学习分类器进行训练,生成所述键值对档案分类器。
l:根据段落j所述的电子装置,其中,从用户的社交网络的第一内容信息中获取与用户相关的至少一个第一键值对信息包括:
根据预设的键集合,利用实体转移规则,从所述第一内容信息中获取所述第一键值对信息。
m:一种电子装置,包括:
处理单元;以及
存储器,耦合至所述处理单元并且包含存储于其上的指令,所述指令在由所述处理单元执行时使所述装置执行动作,所述动作包括:
生成注意力模型处理模块、内部状态向量生成模块、逻辑回归判别模块,其中,所述注意力模型处理模块和内部状态向量生成模块在所述逻辑回归判别模块的控制下,进行多轮次的内部状态向量的迭代处理,
所述注意力模型处理模块,用于根据当前轮次的内部状态向量和外部存储向量生成当前轮次的注意力向量;
内部状态向量生成模块,用于至少根据用户查询向量生成初始的内部状态向量,并至少根据前一轮次的内部状态向量和当前轮次的注意力向量生成当前轮次的内部状态向量;
逻辑回归判别模块,用于对当前轮次的内部状态向量进行判别,确定是否终止迭代处理。
n:根据段落m所述的电子装置,其中,所述内部状态向量生成模块具体用于,根据用户查询向量、基于用户查询向量生成的初始的意图状态向量以及初始的回复状态向量,生成初始的内部状态向量,并根据前一轮次的内部状态向量、基于该前一轮次的内部状态向量生成的当前轮次的注意力向量生成当前轮次的内部状态向量。
o:根据段落m所述的电子装置,其中,所述动作还包括:生成外部存储信息向量生成模块,该外部存储信息向量生成模块用于根据用户维基存储数据、会话内容存储数据、会话主题存储数据以及开放领域知识存储数据中的一项或者任意多项的组合,生成所述外部存储向量。
p:根据段落m所述的电子装置,其中,所述动作还包括:生成答复信息生成模块,所述答复信息生成模块,用于在迭代处理终止时,根据最终轮次的内部状态向量,生成答复信息。
q:根据段落n所述的电子装置,其中,所述意图状态向量包含情绪关怀和/或任务取向方面的信息。
r:一种装置,包括:
输入层处理模块,用于将会话中的多个句子中的每个词进行向量化,生成句子的词向量表示;
句子内rnn层处理模块,用于对多个句子的词向量表示进行处理,生成整个句子的句子向量表示;
句子间rnn层处理模块,用于将所述句子内rnn层输出的多个句子向量表示进行处理,输出所述会话的会话向量表示;
softmax函数处理模块,用于根据所述会话向量表示确定给定生命周期状态列表中各个标题对应的状态概率。
s:一种电子装置,包括:
处理单元;以及
存储器,耦合至所述处理单元并且包含存储于其上的指令,所述指令在由所述处理单元执行时使所述装置执行动作,所述动作包括:生成输入层处理模块、句子内rnn层处理模块、句子间rnn层处理模块以及softmax函数处理模块,
其中,输入层处理模块,用于将会话中的多个句子中的每个词进行向量化,生成句子的词向量表示;
句子内rnn层处理模块,用于对多个句子的词向量表示进行处理,生成整个句子的句子向量表示;
句子间rnn层处理模块,用于将所述句子内rnn层输出的多个句子向量表示进行处理,输出所述会话的会话向量表示;
softmax函数处理模块,用于根据所述会话向量表示确定给定生命周期状态列表中各个标题对应的状态概率。
结语
系统的多个方面的硬件与软件实现之间区别不大;使用硬件还是软件通常(但并不总是,因为在某些背景下,硬件与软件之间的选择可以变得显著)是表示成本与效率权衡的设计选择。存在可以实现在此描述的处理和/或系统和/或其它技术(例如,硬件、软件,以及/或固件)的各种承载工具,并且优选承载工具将随着部署该处理和/或系统和/或其它技术的背景而改变。例如,如果实现方确定速度和准确度最重要,则该实现方可以选择主要硬件和/或固件承载工具;如果灵活性最重要,则该实现方可以选择主要软件实现;或者,此外又另选地,该实现方可以选择硬件、软件,以及/或固件的一些组合。
前述详细描述已经经由使用框图、流程图,以及/或示例阐述了该装置和/或处理的各种实施方式。至于这种框图、流程图,以及/或示例包含一个或更多个功能和/或操作,本领域技术人员应当明白,这种框图、流程图,或示例内的每一个功能和/或操作可以单独地和/或共同地,通过宽范围的硬件、软件、固件,或者实际上其任何组合来实现。在一个实施方式中,在此描述的主旨的几个部分可以经由专用集成电路(asic)、现场可编程门阵列(fpga)、数字信号处理器(dsp),或其它集成格式来实现。然而,本领域技术人员应当认识到,在此公开的实施方式的一些方面整个地或者部分地可以等同地在集成电路中实现,实现为运行在一个或更多个计算机上的一个或更多个计算机程序(例如,实现为运行在一个或更多个计算机系统上的一个或更多个程序),实现为运行在一个或更多个处理器上的一个或更多个程序(例如,实现为运行在一个或更多个微处理器上的一个或更多个程序),实现为固件,或者实际上实现为其任何组合,并且根据本公开,设计电路和/或编写用于软件和/或固件的代码完全处于本领域技术人员的技术内。另外,本领域技术人员应当清楚的是,在此描述的主题的机制能够按多种形式作为程序产品分配,并且在此描述的主题的例示性实施方式适用,而与被用于实际执行该分配的特定类型的信号承载介质无关。信号承载介质的示例包括但不限于,以下:可记录型介质,如软盘、硬盘驱动器(hdd)、质密盘(cd)、数字通用盘(dvd)、数字磁带、计算机存储器等;和传输型介质,如数字和/或模拟通信媒介(例如,光纤线缆、波导管、有线通信链路、无线通信链路等)。
本领域技术人员应当认识到,按在此阐述的方式来描述装置和/或处理,并且此后,使用工程实践将这样描述的装置和/或处理集成到数据处理系统中是本领域内常见的。即,在此描述的装置和/或处理的至少一部分可以经由合理量的实验而集成到数据处理系统中。本领域技术人员应当认识到的是,通常的数据处理系统通常包括以下中的一个或更多个:系统单元外壳、视频显示装置、诸如易失性和非易失性存储器的存储器、诸如微处理器和数字信号处理器的处理器、诸如操作系统、驱动器、图形用户接口,以及应用程序的计算实体、诸如触摸板或触摸屏的一个或更多个交互式装置,以及/或包括反馈回路和控制电动机的控制系统(例如,用于感测位置和/或速度的反馈;用于移动和/或调节组件和/或数量的控制马达)。通常的数据处理系统可以利用任何合适商业可获组件来实现,如通常在数据计算/通信和/或网络通信/计算系统中找到的那些。
在此描述的主题有时例示了包含在不同的其它组件内或与其相连接的不同组件。要明白的是,这样描绘的架构仅仅是示例性的,并且实际上,可以实现获得相同功能的许多其它架构。在概念意义上,用于获得相同功能的组件的任何排布结构都有效地“关联”,以使获得希望功能。因此,在此为获得特定功能而组合的任两个组件都可以被看作彼此“相关联”,以使获得希望功能,而与架构或中间组件无关。同样地,这样关联的任两个组件还可以被视作彼此“可操作地连接”,或“可操作地耦接”,以获得希望功能,并且能够这样关联的任两个组件也可以被视作可彼此“操作地耦接”,以获得希望功能。可操作地耦接的具体示例包括但不限于,物理上可配合和/或物理上交互的组件和/或可无线地交互和/或无线地交互的组件和/或逻辑上交互和/或逻辑上可交互组件。
针对在此实质上使用的任何复数和/或单数术语,本领域技术人员可以针对背景和/或应用在适当时候从复数翻译成单数和/或从单数翻译成复数。为清楚起见,各种单数/多数置换在此可以确切地阐述。
本领域技术人员应当明白,一般来说,在此使用的,而且尤其是在所附权利要求书中(例如,所附权利要求书的主体)使用的术语通常旨在作为“开放式”措辞(例如,措辞“包括(including)”应当解释为“包括但不限于”,措辞“具有(having)”应当解释为“至少具有”应当解释为“包括但不限于”等)。本领域技术人员还应当明白,如果想要特定数量的介绍权利要求列举,则这种意图将明确地在该权利要求中陈述,并且在没有这些列举的情况下,不存在这种意图。例如,为帮助理解,下面所附权利要求书可以包含使用介绍性短语“至少一个”和“一个或更多个”来介绍权利要求列举。然而,使用这种短语不应被认作,暗示由不定冠词“一(a)”或“一(an)”介绍的权利要求列举将包含这种介绍权利要求列举的任何特定权利要求限制于仅包含一个这种列举的发明,即使同一权利要求包括介绍性短语“一个或更多个”或“至少一个”以及诸如“一(a)”或“一(an)”的不定冠词(例如,“一(a)”或“一(an)”通常应当被解释成意指“至少一个”或“一个或更多个”);其对于使用为介绍权利要求列举而使用的定冠词来说同样保持为真。另外,即使明确地陈述特定数量的介绍权利要求列举,本领域技术人员也应当认识到,这种列举通常应当被解释成,至少意指所陈述数量(例如,“两个列举”的仅有的列举在没有其它修饰语的情况下通常意指至少两个列举,或者两个或更多个列举)。而且,在使用类似于“a、b,以及c等中的至少一个”的惯例的那些实例中,一般来说,这种句法结构希望本领域技术人员在意义上应当理解这种惯例(例如,“具有a、b,以及c中的至少一个的系统”应当包括但不限于具有单独a、单独b、单独c、a和b一起、a和c一起、b和c一起,以及/或a、b以及c一起等的系统)。在使用类似于“a、b,或c等中的至少一个”的惯例的那些实例中,一般来说,这种句法结构希望本领域技术人员在意义上应当理解这种惯例(例如,“具有a、b,或c中的至少一个的系统”应当包括但不限于具有单独a、单独b、单独c、a和b一起、a和c一起、b和c一起,以及/或a、b以及c一起等的系统)。本领域技术人员还应当明白的是,实际上,呈现两个或更多个另选术语的任何转折词和/短语(无论处于描述、权利要求书中,还是在附图中)应当被理解成,设想包括这些术语、这些术语中的任一个,或者两个术语的可能性。例如,短语“a或b”应当被理解成,包括“a”或“b”或“a和b”的可能性。
本说明书中针对“实现方式”、“一个实现方式”、“一些实现方式”,或“其它实现方式”的引用可以意指,结合一个或更多个实现方式描述的特定特征、结构,或特性可以被包括在至少一些实现方式中,但不必被包括在所有实现方式中。前述描述中不同出现的“实现方式”、“一个实现方式”,或“一些实现方式”不必全部针对同一实现方式而引用。
虽然利用不同方法和系统描述和示出了特定示例性技术,但本领域技术人员应当明白,在不脱离要求保护的主题的情况下,可以进行各种其它修改,并且可以代替等同物。另外,在不脱离在此描述的中心概念的情况下,可以进行许多修改以使适应针对要求保护的主题的教导的特定情况。因此,要求保护的主题不限于所公开的特定示例,而是这种要求保护的主题还可以包括落入所附权利要求书及其等同物的范围内的所有实现。
尽管已经用结构特征和/或方法动作专用的语言描述了本主题,但要理解,所附权利要求书中定义的主题不必限于所描述的具体特征或动作。而是,这些具体特征和动作是作为实现该权利要求的解说性形式而公开的。
除非另外具体声明,否则在上下文中可以理解并一般地使用条件语言(诸如“能”、“能够”、“可能”或“可以”)表示特定示例包括而其他示例不包括特定特征、元素和/或步骤。因此,这样的条件语言一般并非旨在暗示对于一个或多个示例以任何方式要求特征、元素和/或步骤,或者一个或多个示例必然包括用于决定的逻辑、具有或不具有用户输入或提示、在任何特定实施例中是否要包括或要执行这些特征、元素和/或步骤。
除非另外具体声明,应理解联合语言(诸如短语“x、y或z中至少一个”)表示项、词语等可以是x、y或z中的任一者、或其组合。
本文所述和/或附图中描述的流程图中任何例行描述、元素或框应理解成潜在地表示包括用于实现该例程中具体逻辑功能或元素的一个或多个可执行指令的代码的模块、片段或部分。替换示例被包括在本文描述的示例的范围内,其中各元素或功能可被删除,或与所示出或讨论的顺序不一致地执行,包括基本上同步地执行或按相反顺序执行,这取决于所涉及的功能,如本领域技术人也将理解的。
应当强调,可对上述示例作出许多变型和修改,其中的元素如同其他可接受的示例那样应被理解。所有这样的修改和变型在此旨在包括在本公开的范围内并且由以下权利要求书保护。
本领域普通技术人员可以理解:实现上述各方法实施例的全部或部分步骤可以通过程序指令相关的硬件来完成。前述的程序可以存储于一计算机可读取存储介质中。该程序在执行时,执行包括上述各方法实施例的步骤;而前述的存储介质包括:rom、ram、磁碟或者光盘等各种可以存储程序代码的介质。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!