一种基于深度学习的贫困生认定方法与流程
本发明属于特征提取和分类算法技术领域,特别涉及一种基于深度学习的贫困生认定方法。
背景技术
经过数十年的发展,中国已经形成了以助学金、国家励志奖学金、助学贷款为主的贫困生资助政策。然而中国与西方发达国家相比,由于没有完善的个人税收体制,难以实现贫困生的精准资助。同时由于人口基数大,也无法实现逐个走访调查,以至于难以实现贫困生的精准资助。近年来针对这种问题,研究者提出了相应的贫困生认定方案,如利用k-means,svm,决策树等。
朱全银等人已有的研究基础包括:朱全银,潘禄,刘文儒,等.web科技新闻分类抽取算法[j].淮阴工学院学报,2015,24(5):18-24;李翔,朱全银.联合聚类和评分矩阵共享的协同过滤推荐[j].计算机科学与探索,2014,8(6):751-759;quanyinzhu,sunquncao.anovelclassifier-independentfeatureselectionalgorithmforimbalanceddatasets.2009,p:77-82;quanyinzhu,yunyangyan,jinding,jinqian.thecasestudyforpriceextractingofmobilephonesellonline.2011,p:282-285;quanyinzhu,suquncao,peizhou,yunyangyan,hongzhou.integratedpriceforecastbasedondichotomybackfillinganddisturbancefactoralgorithm.internationalreviewoncomputersandsoftware,2011,vol.6(6):1089-1093;朱全银等人申请、公开与授权的相关专利:朱全银,胡蓉静,何苏群,周培等.一种基于线性插补与自适应滑动窗口的商品价格预测方法.中国专利:zl201110423015.5,2015.07.01;朱全银,曹苏群,严云洋,胡蓉静等,一种基于二分数据修补与扰乱因子的商品价格预测方法.中国专利:zl201110422274.6,2013.01.02;朱全银,尹永华,严云洋,曹苏群等,一种基于神经网络的多品种商品价格预测的数据预处理方法.中国专利:zl201210325368.6;李翔,朱全银,胡荣林,周泓.一种基于谱聚类的冷链物流配载智能推荐方法.中国专利公开号:cn105654267a,2016.06.08;曹苏群,朱全银,左晓明,高尚兵等人,一种用于模式分类的特征选择方法.中国专利公开号:cn103425994a,2013.12.04;朱全银,严云洋,李翔,张永军等人,一种用于文本分类和图像深度挖掘的科技情报获取与推送方法.中国专利公开号:cn104035997a,2014.09.10;朱全银,辛诚,李翔,许康等人,一种基于k-means和lda双向验证的网络行为习惯聚类方法.中国专利公开号:cn106202480a,2016.12.07。
神经网络算法:
神经网络算法是一种模仿生物神经网络的结构和功能的数学模型或计算模型。神经网络算法主要结构为输入层,隐藏层和输出层。输入层负责输入特征值,输出层则是输出预测结果或分类结果。隐藏层由连接的神经元组成。在深度学习中,为了加深神经网络,增加神经网络层数,引入了激活函数。激活函数通过抛弃部分神经元,达到加深神经网络并提高预测或分类准确率的目的。
交叉熵损失函数:
交叉熵损失函数可以衡量真实结果与预测结果的相似性。和其他损失函数一样,交叉熵损失函数作用是更新神经元连接之间的权值,以达到减少训练误差的目的。与方差损失函数相比,交叉熵损失函数克服了学习速度慢的问题。主要作为由sigmoid、softmax等函数作为输出层函数情况下的损失函数。
sigmoid函数:
sigmoid函数一个在生物学中常见的s型的函数,使用sigmoid函数作为首层神经网络的激活函数可以较大程度上利用特征值,并且它的结果具有概率的特征,将更有利于softmax函数的分类计算。
softmax函数:
softmax函数用于处理类别为三个及以上的分类或回归问题,softmax函数是sigmoid函数的一般形式,运用softmax的算法属于有监督学习。
改进的relu激活函数:
relu激活函数在负输入时输出为零的特性,使其容易在训练中出现梯度消失的情况。针对relu的缺点,改进了其在输入为负时的公式,改用作为负输入时的计算公式,其中表示大于0的可调浮点数。
相关专利:
基于数据挖掘的学生贫困状态预测方法:cn106951568a,通过使用spark平台进行数据预处理,再使用决策树算法对学生贫困状态进行预测,能直观、简单地理解。但该方法对噪声的表现不够健壮,扰乱一点,改动一点值就会使决策树发生改变。一种高校贫困生评定方法:cn106934742a,通过提取学生数据的十个特征值,使用三层神经网络进行贫困生评定,能够对隐藏层神经元数目进行自调整。但是该方法准确度不够高,隐藏层深度不够。
技术实现要素:
发明目的:针对现有技术中存在的问题,本发明提出一种准确度高,隐藏层深度足够的基于深度学习的贫困生认定方法。
技术方案:为解决上述技术问题,本发明提供一种基于深度学习的贫困生认定方法,具体步骤如下:
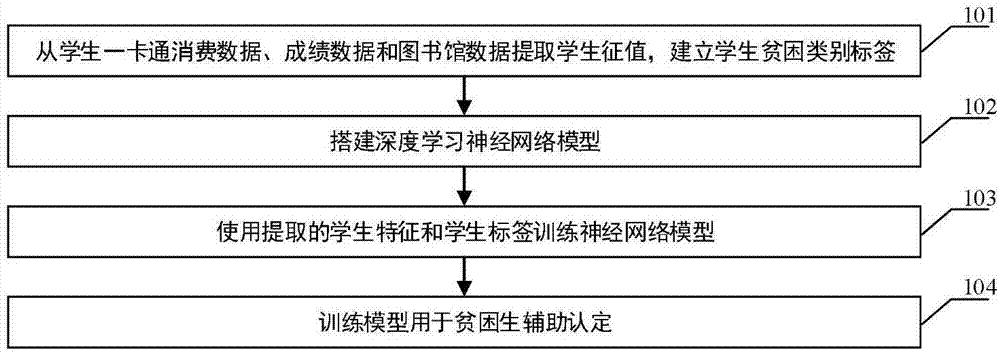
(1)从学生一卡通消费数据、成绩数据和图书馆数据提取学生征值,建立学生贫困类别标签;
(2)搭建深度学习神经网络模型;
(3)使用提取的学生特征和学生标签训练神经网络模型;
(4)训练模型用于贫困生辅助认定。
进一步的,所述步骤(1)中建立学生贫困类别标签的具体步骤如下:
(1.1)设学生一卡通消费数据集为x={x1n,x2n,…,xmn},其中m表示消费类别,n表示学生编号,xmn是一个由消费总金额和消费总次数组成的矩阵;
(1.2)设学生成绩数据集为y={y1,y2,…,yn},n表示学生编号,yn表示学生加权平均分的学校排名;
(1.3)设学生图书馆数据集为z={z1,z2,…,zn},n表示学生编号,zn表示学生图书馆借阅总次数;
(1.4)合并数据集x,y,z形成学生特征矩阵s;
(1.5)将学生分为4个贫困等级,并用one-hot进行编码,作为学生真实标签y*。
进一步的,所述步骤(2)中搭建深度学习神经网络模型的具体步骤如下:
(2.1)用sigmoid函数作为激活函数搭建输入层,26个输入维度,200个神经元;
(2.2)用改进的relu作为激活函数搭建5层神经网络每层200个神经元;
(2.3)用softmax函数作为激活函数搭建最后一层神经网络,共4个神经元;
(2.4)设置交叉熵损失函数作为神经网络的损失函数,rmsprop为优化函数;
(2.5)设置学习效率为0,001,批训练数量为200,迭代400次。
进一步的,所述步骤(3)中使用提取的学生特征和学生标签训练神经网络模型的具体步骤如下:
(3.1)定义循环变量为t,并赋初值t=1;
(3.2)当t<=400执行步骤403,否则执行步骤414;
(3.3)定义循环变量为k,并赋初值k=1;
(3.4)将学生特征矩阵分批,每批包含200个学生的特征矩阵;
(3.5)当k<=7执行步骤405,否则执行步骤407;
(3.6)矩阵sk经过以sigmoid函数为激活函数的神经网络;
(3.7)设第一层神经网络的结果矩阵ck;
(3.8)矩阵ck经过以改进的relu为激活函数5层神经网络;
(3.9)设经过神经网络的结果为矩阵dk;
(3.10)矩阵dk经过以softmax函数作为激活函数的神经网络;
(3.11)设经过最后一层神经网络的结果为y’;
(3.12)计算学生真实标签y*和y’之间的损失,更新神经网络连接函数的权值;
(3.13)k=k+5;
(3.14)模型训练完毕。
进一步的,所述步骤(4)中训练模型用于贫困生辅助认定的具体步骤如下:
(4.1)从一卡通消费数据、成绩数据、图书馆数据提取学生特征值,设特征矩阵为sm;
(4.2)将学生特征矩阵投入训练好的神经网络中;
(4.3)获得学生的类别。
与现有技术相比,本发明的优点在于:
本发明创造性的提出了一种基于深度学习的贫困生认定方法,本方法改变了现有方法非监督学习的状况,使用改进的relu作为隐藏层的激活函数,有效的提高了贫困生认定的准确性。
附图说明
图1为本发明的总体流程图;
图2为图1中建立学生类别标签的流程图;
图3为图1中搭建神经网络模型的流程图;
图4为图1中使用提取的学生特征和学生标签训练神经网络模型的流程图;
图5为图1中训练模型用于贫困生辅助认定的流程图。
具体实施方式
下面结合附图和具体实施方式,进一步阐明本发明。
如图1-5所示,本发明包括如下步骤:
步骤一:如附图2,从学生一卡通消费数据,成绩数据和图书馆数据提取学生特征步骤101从步骤201到步骤205:
步骤201:设学生一卡通消费数据集为x={x1n,x2n,…,xmn},其中m表示消费类别,n表示学生编号,xmn是一个由消费总金额和消费总次数组成的矩阵;
步骤202:设学生成绩数据集为y={y1,y2,…,yn},n表示学生编号,yn表示学生加权平均分的学校排名;
步骤203:设学生图书馆数据集为z={z1,z2,…,zn},n表示学生编号,zn表示学生图书馆借阅总次数;
步骤204:合并数据集x,y,z形成学生特征矩阵s;
步骤205:将学生分为4个贫困等级,并用one-hot进行编码,作为学生真实标签y*;
步骤二:如附图3,搭建神经网络模型步骤102从步骤301到步骤304:
步骤301:用sigmoid函数作为激活函数搭建输入层,26个输入维度,200个神经元;
步骤302:用改进的relu作为激活函数搭建5层神经网络每层200个神经元;
步骤303:用softmax函数作为激活函数搭建最后一层神经网络,共4个神经元;
步骤304:设置交叉熵损失函数作为神经网络的损失函数,rmsprop为优化函数;
步骤305:设置学习效率为0,001,批训练数量为200,迭代400次;
步骤三:如附图4,使用提取的学生特征和学生标签训练神经网络模型步骤103从步骤401到步骤414:
步骤401:定义循环变量为t,并赋初值t=1;
步骤402:当t<=400执行步骤403,否则执行步骤414;
步骤403:定义循环变量为k,并赋初值k=1;
步骤404:将学生特征矩阵分批,每批包含200个学生的特征矩阵;
步骤405:当k<=7执行步骤405,否则执行步骤407;
步骤406:矩阵sk经过以sigmoid函数为激活函数的神经网络;
步骤407:设第一层神经网络的结果矩阵ck;
步骤408:矩阵ck经过以改进的relu为激活函数5层神经网络;
步骤409:设经过神经网络的结果为矩阵dk;
步骤410:矩阵dk经过以softmax函数作为激活函数的神经网络;
步骤411:设经过最后一层神经网络的结果为y’;
步骤412:计算学生真实标签y*和y’之间的损失,更新神经网络连接函数的权值;
步骤413:k=k+5;
步骤414:模型训练完毕;
步骤四:如附图5,训练模型用于贫困生辅助认定步骤104从步骤501到步骤503;
步骤501:从一卡通消费数据、成绩数据、图书馆数据提取学生特征值,设特征矩阵为sm;
步骤502:将学生特征矩阵投入训练好的神经网络中;
步骤503:获得学生的类别。
为了更好的说明本方法的有效性,通过对datacastle0.89g数据集进行测试,对比了使用relu,elu,prelu和本发明改进的relu作为隐藏层的激活函数搭建的神经网络,实验结果表明,使用改进的relu作为隐藏层的激活函数函数搭建的神经网络,训练准确度明显高于其它三种神经网络模型。
本发明可与计算机系统结合,从而自动完成贫困生推荐。
本发明创造性的提出了一种基于深度学习的贫困生认定方法,先从一卡通消费数据、图书馆数据、成绩数据提取学生特征,将学生分为4个贫困等级并用one-hot编码,将编码结果作为学生类别标签。再使用提取的特征和类别标签训练搭建的神经网络模型。最后提取待确定类别的学生特征,将特征放入训练好的神经网络模型,得到学生类别。
以上所述仅为本发明的实施例子而已,并不用于限制本发明。凡在本发明的原则之内,所作的等同替换,均应包含在本发明的保护范围之内。本发明未作详细阐述的内容属于本专业领域技术人员公知的已有技术。
- 还没有人留言评论。精彩留言会获得点赞!