一种针对网页信息无障碍检评估的主动学习方法与流程
本发明涉及的网页无障碍检评估系统的网页抽样领域。
背景技术
互联网社会的蓬勃发展,引领了社会信息化的新潮流。通过互联网的信息交流在如今的信息传播中起到了不可或缺的作用,因而平等的获取信息也日益成为人类社会追求的目标,信息无障碍在信息社会中的地位也越来越重要。
根据中国残疾人联合会统计数据所示,截止于2010年底我国各类残疾人数量约有8502万。随着互联网的高度普及和互联网在日常生活中重要性的不断上升,对于数量众多的老年人、残疾人等特殊人群而言,视觉和听觉上的缺失直接妨碍他们正常获取互联网上的信息。因此如何使这部分人群没有障碍地获取互联网信息显得尤为重要。
为了检测一个网站的信息无障碍水平,需要获取这个网站的信息无障碍的检测结果。由于一个网站包含大量的网页及可能存在的人工检测的干预,直接检测所有网页代价太过昂贵。实际上,我们通常选取一些比较具有代表性的网页进行评估。这使得网站的信息无障碍评估十分倚重选取的网页。采样过疏会导致检测结果不准确,过度采样又会导致评估代价太大。为了解决这个问题,本专利提出了一种主动预测的半监督的机器学习方法来的到整个网站的检测结果。主动预测将网站信息无障碍检测问题通过针对每个检测点建立学习模型转变为一个预测问题,从未避免人工监督的代价昂贵问题。为了实现利用更少的训练数据获取更高的准确度,主动检测利用主动学习技术来选取最具有信息量的网页来训练模型。实验结果表明主动预测可以得到更高的网站信息无障碍的准确度,比已有模型更加准确的反应网站的信息无障碍水平。
随着网络中提供越来越多的信息内容,数以百万计的残疾人将网页作为信息、就业以及娱乐的主要来源。然而,网络冲浪的复杂和困难困扰着他们。为了帮助这些人感知、理解、浏览以及与网页进行交互,出现了网页信息无障碍技术。同时,许多组织开始强调网页信息无障碍的重要性和不可缺少性,如w3c发布了wcag1.0和2008年wcag2.0。这些指南定义了四种信息无障碍的设计原则,即可感知性、可操作性、可理解性以及可靠性,这些原则旨在鼓励设计者确保其网站符合规范。
尽管已经对web可访问性进行了许多发展和努力,但最近的研究报告指出,大多数网站仍然存在许多问题,使残疾人几乎不能从其获取任何有用的信息。为了更好地了解网站的信息无障碍水平,许多评估方法被提出。这些方法包括用户测试,障碍演练,一致性测试和主观评估。然而,在实际评估中,我们经常遇到大量页面的网站。从人力资源评估的角度考虑,直接对所有网页进行评估是非常昂贵的。网站信息无障碍评估中的这个评估瓶颈使得获取所有页面的信息无障碍评估结果不切实际,特别是对于大型网站。
相对于获取网站中所有网页的无障碍检测结果,许多抽样——选取部分网页进行评估——的方法被提出来,比如特设点、均匀随机、随机游走以及分层抽样等。总体来说,信息无障碍的抽样包含以下几个步骤:(1)测定样本的大小;(2)用抽样法选择网页;(3)评估这些抽样。虽然采样方法可以支持可信息无障碍评估,但它使评估结果严重依赖于所选择的评估页面。取样过疏可能会导致评估偏差过大。但是,采样过密将产生较高的评估代价。此外,最近的研究表明,由于网站的基本特性是未知的,评估结果并不能完全信任。此外,抽样方法的质量受到许多因素的影响,如抽样大小、网站大小、所选页面以及无障碍权值等。在这种情况下,许多不必要的因素会渗透并影响评估结果。
为了更好地反映网站的信息无障碍水平,最近的研究中被强烈推荐获取所有网页的信息无障碍结果。为了解决这个问题,我们将人工智能引入信息无障碍评估,并提出了半监督机器学习方法的主动预测,以获得所有页面的信息无障碍评估结果。具体来说,我们首先使用主动学习从网站中选择几个网页,然后将这些选定的样本提供给人类专家和自动化工具进行评估。将评估页面作为培训数据,我们学习一个机器学习模型来预测所有页面的可访问性结果。因此,主动预测克服了网络可访问性评估的评估瓶颈,并获得了反映网站可访问性水平的所有可访问性结果,而不是现有的方法。
已经提出了选择要评估的页面子集的各种抽样方法,例如特设,均匀随机和随机游走以及分层抽样等,而不是获取网站的所有可访问性结果。一般来说,抽样过程web可访问性评估中的方法包括以下步骤[5]:(1)确定采样大小;(2)采用抽样方式选择页面;(3)评估这些样品。虽然采样方法可以支持可访问性评估,但它使评估结果严重依赖于所选择的评估页面。取样可能会导致评估偏大。但是,过采样仍将产生较高的评估费用。此外,最近的研究表明,评估结果不能完全信任,因为网站的基础性质是未知的。此外,抽样方法的质量受到许多因素的影响,如抽样大小,网站大小,所选页面,可访问性度量等。在这种情况下,许多不必要的因素可能会渗透并影响评估结果。
为了更好地反映网站的可访问性水平,最近研究结果中强烈推荐获取所有网页的可访问性结果。为了解决这个问题,我们将人工智能引入网站信息无障碍评估,并提出了半监督机器学习方法的主动预测,以获得所有页面的信息无障碍评估结果。具体来说,我们首先使用主动学习从网站中选择几页,然后将这些选定的样本提供给人类专家和自动化工具进行评估。将评估页面作为培训数据,我们学习一个机器学习模型来预测所有页面的信息无障碍评估结果。因此,主动预测克服了网站信息无障碍评估的评估瓶颈,并获得了反映网站信息无障碍水平的所有结果。
技术实现要素:
本发明要克服现有技术的上述缺点,提出一种针对网页信息无障碍检评估的主动学习方法。
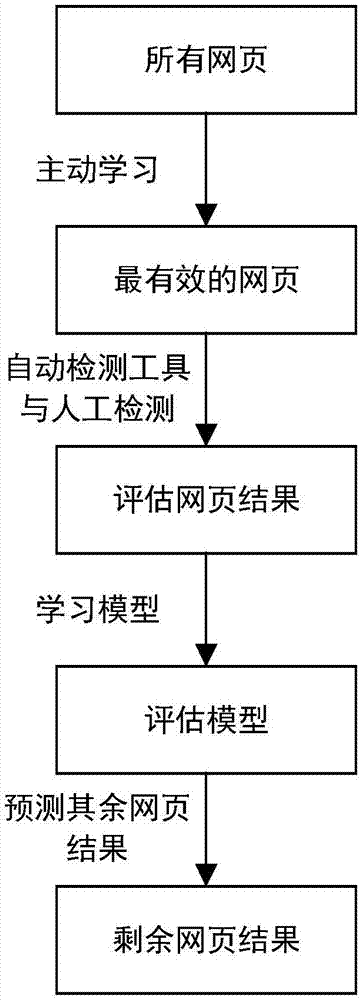
本发明针对网页信息无障碍检评估的主动学习方法,包括以下步骤:
1)通过主动学习方法选取最有效的网页。
2)通过评估选择的网页对其进行信息无障碍检测。
3)运用评估的网页作为训练集来学习预测模型。
4)预测其余网页的无障碍检测结果。
步骤1)中所述的最有效的网页,基本组成如下:最有效的网页指:如果被标记并作为训练集、最能提升预测结果的网页。
步骤2)中所述的信息无障碍检测具体包括网页的可感知性、可操作性、可理解性、鲁棒性检测。
步骤3)中所述的预测模型采用svms学习预测模型。
本发明的优点是在网站信息无障碍检评估中,花费较小的代价即可获得较高的检测准确度。特别是对于包含众多网页的网站,网页全部检测或者过度采样会导致检测代价高昂,采样过疏又会导致检测结果可能出现较大误差。通过本发明主动学习方法建立学习模型,将会在可接受的代价范围内,获取网站信息无障碍较高的评估准确度。
附图说明
图1是本发明的方法流程图。
具体实施方式
参照附图,进一步说明本发明:
一种针对网页信息无障碍检评估的主动学习策略,该方法包括以下步骤:
1)通过主动学习方法选取最有效的网页;
2)通过评估选择的网页对其进行信息无障碍检测;
3)运用评估的网页作为训练集来学习预测模型;
4)预测其余网页的无障碍检测结果。
步骤1)中所述的最有效的网页,基本组成如下:最有效的网页指:如
果被标记并作为训练集、最能提升预测结果的网页。
步骤2)中所述的信息无障碍检测具体包括:网页的可感知性、可操作性、可理解性、鲁棒性检测。
步骤3)中所述的预测模型采用svms学习预测模型。
本说明书实施例所述的内容仅仅是对发明构思的实现形式的列举,本发明的保护范围的不应当被视为仅限于实施例所陈述的具体形式,本发明的保护范围也及于本领域技术人员根据本发明构思所能够想到的等同技术手段。
- 还没有人留言评论。精彩留言会获得点赞!