一种实时寻找大数据自身重复规律的方法与流程
大数据或流数据分析。
背景技术:
互联网,移动通讯,导航,网游,感应技术和大规模计算基础设施每天产生海量数据。大数据就是由于其巨大规模,快速变化及增长速度而超出了传统数据库系统的处理能力及传统分析方法的分析能力的数据。
计算自相关函数是一种寻找时间序列或流化大数据自身重复规律的有效方法。自相关,也被称为延迟相关或序列相关,是一个特定的时间序列与延迟了l个时间点的该时间序列本身的相关程度的一个度量。它可以通过一个时间序列的相隔了l个时间点的观察值的协相关除以其标准方差来得到。如果计算了一个时间序列的所有不同延迟值的自相关就得到该时间序列的自相关函数。某个延迟的自相关值为1或接近1可认为时间序列或流化大数据在该延迟后出现自身重复规律,因此计算自相关函数后寻找大数据自身重复规律显而易见,而困难和挑战在于如何实时地在大数据上计算自相关函数。
为了能够实时得到利用了最新数据的自身重复规律,自相关函数可能会在大数据集有变化后需要重新计算。因此,一些(可能很多)数据元素会被重复访问和使用。例如,有可能自相关函数在含有n个数据元素的计算窗口上被计算。当一个数据元素从计算窗口里被去除和一个数据元素被加入计算窗口后,计算窗口里所有的n个数据元素被访问来重新计算自相关函数。
取决于需要,计算窗口的规模可能非常大,例如计算窗口中的数据元素可能分布在云平台的成千上万台计算设备上。在一些数据变化后的大数据上用传统方法重新计算自相关函数无法做到实时处理并且占用和浪费大量计算资源,因此用传统方法实时地寻找大数据自身重复规律不仅浪费大量计算资源也可能无法满足需求地实现。
技术实现要素:
本发明拓展到方法,系统和计算系统程序产品以迭代方式计算大数据的调整后计算窗口的自相关函数从而可以实时地寻找时间序列或流化大数据自身重复规律。为一个调整后计算窗口迭代计算自相关函数包括基于调整前计算窗口的自相关函数的多个组件迭代计算调整后计算窗口的自相关函数的多个组件然后根据需要基于迭代计算的组件生成调整后计算窗口的自相关函数。某延迟的自相关值为1或接近1可认为数据在该延迟后出现自身重复规律。迭代计算自相关函数避免访问调整后计算窗口中的所有数据元素和执行重复计算从而降低数据访问延迟,提高计算效率,节省计算资源和降低计算系统能耗,使得一些实时寻找大数据自身重复规律从不可能变为可能。
对于一个给定的自相关函数迭代算法,假设在同一轮迭代计算中一个给定延迟范围内的每个延迟上所有迭代计算的组件(包括计算窗口的和或平均值)总数为p(p>1)。直接迭代的组件个数为v(1≤v≤p),则间接迭代的组件个数为w=p-v(w≥0)。其中计算窗口的和或平均值是必须迭代计算的特殊组件。和或平均值可以被直接或间接迭代计算。
计算系统初始化存储在一个或多个存储媒体上的一个大数据集的一个调整前计算窗口中指定延迟范围的自相关函数的,包括一个和或一个平均值在内的,两个以上(p,p>1)组件。该两个以上组件的初始化包括从计算设备可读媒体上接收或访问已计算过的组件或基于调整前计算窗口中的数据元素根据组件的定义来计算。
计算系统访问一个要从调整前计算窗口中去除的数据元素和一个要被加入到调整前计算窗口的数据元素。
计算系统通过从调整前计算窗口中去除要去除的数据元素和向调整前计算窗口加入要加入的数据元素来调整调整前计算窗口。
计算系统在指定延迟范围内的每一个延迟上直接迭代计算并存储调整后计算窗口的自相关函数的一个或多个(v,1≤v≤p)组件。这可通过一个循环来实现:设定一个延迟初始值,迭代计算给定延迟的自相关的v个组件,存储计算的v个组件,调整延迟为在给定延迟范围内的一个新值,迭代计算新的给定延迟的自相关的v个组件,存储新计算的v个组件,不断重复这个过程直到给定延迟范围内的所有延迟的自相关的v个组件都被迭代计算和保留。对于一个给定延迟l直接迭代计算这v个组件包括:访问调整后计算窗口两端不包括新加入数据元素在内的各l个数据元素;访问调整前计算窗口的v个组件;基于访问的数据元素从v个组件中的每个组件中数学地去除被去除的数据元素的贡献;以及向v个组件中的每个组件数学地加入被加入的数据元素的贡献而避免访问和使用调整后计算窗口中的所有数据元素来降低数据访问延迟,节省计算资源和降低能耗和提高计算效率。
计算系统根据需要在指定延迟范围内的每一个延迟上间接迭代计算调整后计算窗口的自相关函数的w=p-v个组件。这可通过一个循环来实现:设定一个延迟初始值,间接迭代计算给定延迟的自相关的w个组件,调整延迟为在给定延迟范围内的一个新值,间接迭代计算新的给定延迟的自相关的w个组件,不断重复这个过程直到给定延迟范围内的所有延迟的自相关的w个组件都被间接迭代计算。对于一个给定延迟l间接迭代计算w个组件包括逐个地间接迭代计算给定延迟上w个组件中的每一个组件。间接迭代计算一个给定延迟上的组件包括:访问并使用给定延迟上除该组件之外的一个或多个组件来计算该组件。这一个或多个组件可能是经过初始化的,直接迭代计算的或间接迭代计算的。
计算系统根据需要初始化一个延迟,在给定延迟上基于一个或多个迭代计算的组件计算调整后计算窗口给定延迟上的自相关,调整延迟为在给定延迟范围内的一个新值,然后在新的给定延迟上基于一个或多个迭代计算的组件计算调整后计算窗口新给定延迟上的自相关,不断重复这个过程直到调整后计算窗口给定延迟范围内所有延迟上的自相关都被计算。当w>0时,间接迭代w个组件的循环和计算自相关的循环可以合并成一个循环。
计算系统可以持续地访问一个要去除的数据元素和一个要加入的数据元素,调整调整前计算窗口,直接迭代计算并存储给定延迟范围内每个不同延迟上的v(1≤v≤p)个组件,根据需要间接迭代计算给定延迟范围内每个不同延迟上的w=p-v个组件和根据需要生成调整后计算窗口给定延迟范围内每个不同延迟上的自相关函数。计算系统可以根据需要多次重复这个过程。
本简述是以简化的方式介绍一些选择的概念,它们将在下面被进一步详细描述。本简述即不是为了鉴定权利要求的主题的关键特点或必要特点,也不是为了用于帮助确认权利要求的主题所包括的范围。
本发明的其它特征和优点将在下面的描述中体现出来,会部分地从描述中明显体现,或从本发明的实践中学到。本发明的特征和优点可从附加的权利要求书中特别指出的方法设备及其组合中实现和得到。本发明的这些和其它特征将在下面的描述和附加的权利要求书或本发明的实践中变得更加全面和清晰。
附图说明
为描述能够获得本发明的上述的和其它的优点和特点的方式,上面简述的本发明的一个更具体的描述将通过参照下列附加的图表中所显示的特定的实施方案来展现出来。这些图表只是描述了本发明的典型实施方案,因此它们不应被理解或解释为对本发明的范围的限制:
图1图示了一个支持迭代计算自相关函数的例子计算系统的高层概括。
图1-1图示了一个为大数据迭代计算自相关函数并且所有组件都是直接迭代计算的例子计算系统架构100a。
图1-2图示了一个为大数据迭代计算自相关函数并且部分组件以直接迭代方式计算而部分组件以间接迭代方式计算的例子计算系统架构100b。
图2图示了一个为大数据迭代计算自相关函数的例子方法流程图。
图3-1图示了计算窗口向右移动时从计算窗口中去除和加入的数据元素。
图3-2图示了在大数据上迭代计算自相关函数并计算窗口向右移动时需要被访问的数据元素。
图3-1图示了计算窗口向左移动时从计算窗口中去除和加入的数据元素。
图3-2图示了在大数据上迭代计算自相关函数并计算窗口向左移动时时需要被访问的数据元素。
图4-1图示了自相关函数的定义以及计算自相关函数的传统方程。
图4-2显示了第一个自相关函数迭代计算算法(迭代算法1)用的方程。
图4-3显示了第二个自相关函数迭代计算算法(迭代算法2)用的方程。
图4-4显示了第三个自相关函数迭代计算算法(迭代算法3)用的方程。
图5-1显示了用于一个计算实例的第一个计算窗口。
图5-2显示了用于一个计算实例的第二个计算窗口。
图5-3显示了用于一个计算实例的第三个计算窗口。
图6-1图示了计算窗口规模为4延迟上限为2时,传统自相关函数算法和迭代自相关函数算法的计算工作量对比。
图6-2图示了计算窗口规模为1,000,000延迟上限为2时,传统自相关函数算法和迭代自相关函数算法的计算工作量对比。
具体实施方法
计算自相关函数是寻找时间序列或流化大数据自身重复规律的有效方法。一个指定的延迟上限maxl或延迟范围(minl,maxl)可用于指明计算自相关函数时的延迟范围。自相关函数中某个延迟的自相关值为1或接近1时可认为时间序列或流化大数据在该延迟后出现自身重复规律。本发明公开了一种以迭代方式计算大数据的调整后计算窗口的自相关函数从而可以实时地寻找时间序列或流化大数据自身重复规律的方法,系统和计算设备程序产品。一个计算系统包含一个或多个基于处理器的计算设备。每个计算设备包含一个或多个处理器。该计算系统包含一个或多个存储媒体。该一个或多个存储媒体中的至少一个上有一个数据集。来自该数据集的,涉及到自相关函数计算的多个数据元素组成一个调整前的计算窗口。计算窗口规模n(n>1)指明数据集的一个计算窗口中的数据元素个数。本发明的实施方案包括基于调整前计算窗口的自相关函数的多个组件迭代计算调整后计算窗口的自相关函数的多个组件,然后根据需要基于迭代计算的组件生成调整后计算窗口的自相关函数。迭代计算自相关函数只需要访问和使用迭代计算的组件,新加入和去除的数据元素及部分其它数据元素而避免访问调整后计算窗口中的所有数据元素和执行重复计算从而提高计算效率,节省计算资源和降低计算系统能耗,使得一些实时寻找大数据自身重复规律从不可能变为可能。
在本文中,一个计算窗口是包含做自相关函数计算的数据元素的数据集。一个计算窗口类似于一个在流数据或时间序列数据上计算自相关函数的移动窗口。在本发明的实施方案的描述里,计算窗口里的数据元素有顺序。
实时流数据处理和流化的大数据处理的区别是当处理流化的大数据时,所有历史数据都可以被访问,所以不需要额外用缓冲区存储新接收的数据元素。
在本文中,自相关函数的一个组件是出现在自相关函数定义公式中或其定义公式的任何转换中的一个量或表达式。自相关函数是它自己最大的组件。以下是一些自相关函数的组件的例子。
自相关函数可基于一个或多个组件或它们的组合被计算,所以多个算法支持迭代自相关函数计算。
一个组件可以被直接迭代计算或间接迭代计算。它们的区别是当一个组件被直接迭代计算时该组件是通过该组件在前一轮计算的值来计算的,而当该组件被间接迭代计算时该组件是用该组件之外的其它组件计算的。
对于一个给定的组件,它也许在一个算法中被直接迭代计算但在另一个算法中被间接迭代计算。
计算窗口的和或平均值是必须迭代计算的特殊组件。对于任意一个算法,至少会有两个组件被迭代计算,其中一个组件是和或平均值,这两个以上组件可以被直接或间接迭代计算,但高效的方式是至少有一个组件被直接迭代计算。对于一个给定的算法,假设在同一轮迭代计算中迭代计算的给定延迟范围内每个延迟上的自相关的不同组件的总数是p(p>1),如果直接迭代计算的组件个数是v(1≤v≤p),那么间接迭代计算的组件的个数是w=p-v(0≤w<p)。可能这些组件都被直接迭代计算(这种情况下v=p>1并且w=0)。但是,无论自相关函数的结果是否在一个特定的轮次被需要和访问,直接迭代计算的组件都必须被计算。
对于一个给定算法,如果一个组件被直接迭代计算,则该组件必须被计算(即每当一个已有的数据元素被从调整前计算窗口中去除和每当一个数据元素被加入到调整前计算窗口中时)。但是,如果一个组件被间接迭代计算,则该组件可以通过使用该组件之外的其它一个或多个组件来根据需要,即只有当自相关函数需要被计算和访问时,被计算。这样,当自相关函数在某一个迭代计算轮次不被访问时,可以只有少量的组件需要被迭代地计算。一个间接迭代计算的组件也许会被用于下一轮另一个组件的间接迭代计算,在这种情况下,该间接迭代计算的组件的计算不可省略。
自相关函数可以根据需要被计算。当自相关函数在每次计算窗口有变化而不需要被访问时,计算系统只需要为每次数据变化迭代计算和或平均值以及除了和或平均值之外的两个以上组件。迭代计算这些组件避免了访问之前的所有输入和做重复计算因此提高计算效率。自相关函数可以在需要被访问时由计算系统基于迭代计算的组件来生成。
本发明的实施方案包括基于为调整前计算窗口计算的多个组件迭代计算调整后的计算窗口的自相关函数的多个组件。
计算系统初始化一个给定规模n(n>1)的调整前计算窗口的一个和或一个平均值或一个和及一个平均值,以及自相关函数的一个或多个(共p个,(p>1))其它组件。该两个以上组件的初始化包括从一个或多个计算设备可读媒体上访问或接收已经计算过的组件或根据其定义基于该调整前计算窗口中的数据元素来计算。
计算系统访问一个要从该调整前计算窗口中去除的数据元素和一个要被加入到该调整前计算窗口中的数据元素。
计算系统调整调整前计算窗口通过:从该调整前计算窗口中去除要被去除的数据元素和向该调整前计算窗口中加入要被加入的数据元素。
计算系统在指定延迟范围内的每一个延迟上直接迭代计算并存储调整后计算窗口的自相关函数的一个或多个(v,1≤v≤p)组件。这可通过一个循环来实现:设定一个延迟初始值,迭代计算给定延迟的自相关的v个组件,存储计算的v个组件,调整延迟为在给定延迟范围内的一个新值,迭代计算新的给定延迟的自相关的v个组件,存储新计算的v个组件,不断重复这个过程直到给定延迟范围内的所有延迟的自相关的v个组件都被迭代计算和保留。对于一个给定延迟l直接迭代计算这v个组件包括:访问调整后计算窗口两端不包括新加入数据元素在内的各l个数据元素;访问调整前计算窗口的v个组件;基于访问的数据元素从v个组件中的每个组件中数学地去除被去除的数据元素的贡献;以及向v个组件中的每个组件数学地加入被加入的数据元素的贡献而避免访问和使用调整后计算窗口中的所有数据元素来降低数据访问延迟,节省计算资源和降低能耗和提高计算效率。
计算系统根据需要在指定延迟范围内的每一个延迟上间接迭代计算调整后计算窗口的自相关函数的w=p-v个组件。这可通过一个循环来实现:设定一个延迟初始值,间接迭代计算给定延迟的自相关的w个组件,调整延迟为在给定延迟范围内的一个新值,间接迭代计算新的给定延迟的自相关的w个组件,不断重复这个过程直到给定延迟范围内的所有延迟的自相关的w个组件都被间接迭代计算。对于一个给定延迟l间接迭代计算w个组件包括逐个地间接迭代计算给定延迟上w个组件中的每一个组件。间接迭代计算一个给定延迟上的组件包括:访问并使用给定延迟上除该组件之外的一个或多个组件来计算该组件。这一个或多个组件可能是经过初始化的,直接迭代计算的或间接迭代计算的。
计算系统根据需要初始化一个延迟,在给定延迟上基于一个或多个迭代计算的组件计算调整后计算窗口给定延迟上的自相关,调整延迟为在给定延迟范围内的一个新值,然后在新的给定延迟上基于一个或多个迭代计算的组件计算调整后计算窗口新给定延迟上的自相关,不断重复这个过程直到调整后计算窗口给定延迟范围内所有延迟上的自相关都被计算。当w>0时,间接迭代w个组件的循环和计算自相关的循环可以合并成一个循环。
计算系统可以持续地访问一个要去除的数据元素和一个要加入的数据元素,调整调整前计算窗口,直接迭代计算并存储给定延迟范围内每个不同延迟上的v(1≤v≤p)个组件,根据需要间接迭代计算给定延迟范围内每个不同延迟上的w=p-v个组件和根据需要生成调整后计算窗口给定延迟范围内每个不同延迟上的自相关函数。计算系统可以根据需要多次重复这个过程。
本发明的实施方案可以包括或利用包含计算设备硬件,例如一个或多个处理器和以下更详细描述的存储设备,专用的或通用的计算设备。本发明实施方案的范围也包括物理的及其它用于携带或存储计算设备可运行指令和/或数据结构的计算设备可读媒体。这些计算设备可读媒体可以是通用或专用计算设备可访问的任何媒体。存储计算设备可运行指令的计算设备可读媒体是存储媒体(设备)。携带计算设备可运行指令的计算设备可读媒体是传输媒体。因此,以举例而非限制的方式,本发明的实施方案可以包括至少两种不同类型的计算设备可读媒体:存储媒体(设备)和传输媒体。
存储媒体(设备)包括随机存取存储器(ram),只读存储器(rom),电可擦除可编程只读存储器(eeprom),只读光盘存储器(cd-rom),固态硬盘(ssd),闪存(flashmemory),相变存储器(pcm),其它类型存储器,其它光学磁盘存储,磁盘存储器或其它磁性存储设备,或任何其它能用于存储所需要的以计算设备可运行指令或数据结构形式构成的程序代码并且其可以被通用或专用计算设备访问的媒体。
一个“网络”被定义为使计算设备和/或模块和/或其它电子设备能够传输电子数据的一个或多个数据链接。当信息被网络或另外的通讯连接(有线,无线,或有线和无线的组合)传输或提供给计算设备时,计算设备把连接视为传输媒体。传输媒体可包括用于携带所需要的以计算设备可运行指令或数据结构形式构成的程序代码,并且其可以被通用或专用计算设备访问的一个网络和/或数据链接。以上的组合也应包括在计算设备可读媒体的范围之内。
此外,在应用不同计算设备组件时,计算设备可运行指令或数据结构形式的程序代码可以从传输媒体自动传输到存储媒体(设备)(或反过来)。例如,从网络或数据链接上接收的计算设备可运行指令或数据结构可以被暂存进网络接口模块(例如,nic)中的随机存取存储器中,然后最终传输到计算设备的随机存取存储器和/或到计算设备的一个较小易变的存储媒体(设备)。所以,应当理解存储媒体(设备)可以被包括在也(或甚至主要)应用传输媒体的计算设备组件里。
计算设备可运行指令包括,例如,指令和数据,当被处理器运行时,使得通用计算设备或专用计算设备去执行一个特定功能或一组功能。计算设备可运行指令可以是,例如,二进制,中间格式指令例如汇编代码,或甚至源代码。虽然描述的客体是用结构特征和/或方法动作的具体语言描述的,应当理解在附加的权利要求书中定义的客体不一定局限于以上描述的特征或动作。而是,描述的特征或动作仅是以实现权利要求的例子形式而公开的。
本发明的实施方案可以在由多种类型的计算设备配置的网络计算环境中实现,这些计算设备包括个人电脑,台式机,笔记本电脑,信息处理器,手持设备,多处理系统,基于微处理器或可编程的电子消费品,网络电脑,小型计算机,主计算机,超级计算机,移动电话,掌上电脑,平板电脑,呼机,路由器,交换机及类似产品。本发明的实施方案也可以应用于通过网络互联(即可通过有线数据链接,无线数据链接,也可以是有线数据链接与无线数据链接的结合)的执行任务的本地或远程计算设备构成的分布式系统环境。在分布式系统环境中,程序模块可以被存储在本地或远程存储设备上。
本发明的实施方案也可以在云计算环境里实现。在本描述及后续的权利要求书中,“云计算”被定义为一个使得能够按需通过网络访问到可配置计算资源的共享池的模型。例如,云计算可以被市场利用去提供普及和方便的按需访问可配置计算资源的共享池。可配置计算资源的共享池可以通过虚拟化很快预备并且以低管理开销或低服务提供商互动来提供,然后做相应的调整。
云计算模型可以包括各种特征例如,按需自服务,宽带网络访问,资源收集,快速收放,计量服务等等。云计算模型也可以各种服务模式来体现,例如,软件做为服务(“saas”),平台做为服务(“paas”),以及设施做为服务(“iaas”)。云计算模型也可以通过不同的部署模型例如私有云,社区云,公共云,混合云等等来部署。
下面的章节中会给出几个例子。
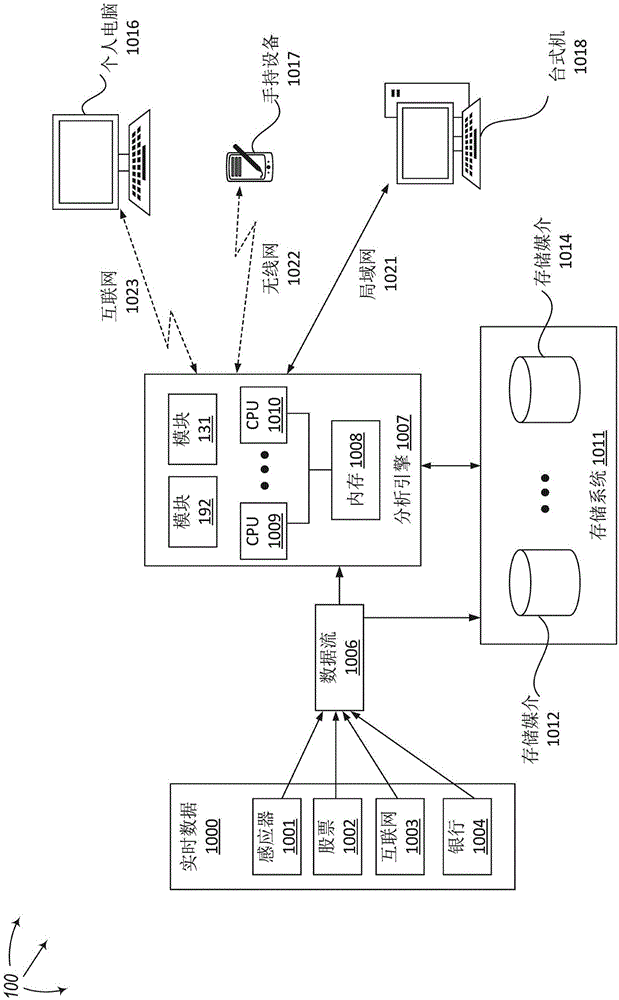
图1图示了为大数据迭代计算自相关函数的一个例子计算系统100的高层概述。参考图1,计算系统100包括由不同网络,例如局域网1021,无线网1022和互联网1023等等,连接的多个设备。多个设备包括,例如,数据分析引擎1007,存储系统1011,实时数据流1006,以及可以安排数据分析任务和/或查询数据分析结果的多台分布的计算设备,例如个人电脑1016,手持设备1017和台式机1018等等。
数据分析引擎1007可以包括一个或多个处理器,例如cpu1009和cpu1010,一个或多个系统内存,例如系统内存1008,及组件计算模块131和自相关函数计算模块192。模块131的细节会在其它图表中更详细地图示(例如,图1-1和图1-2)。存储系统1011可以包括一个或多个存储媒体,例如存储媒体1012和存储媒体1014,其可以用于存放大数据集。例如,1012和或1014可以包括数据集123(见图1-1和图1-2)。存储系统1011里的数据集可以被数据分析引擎1007访问。
通常,数据流1006可以包括来自不同数据源的流数据,例如,股价,音频数据,视频数据,地理空间数据,互联网数据,移动通讯数据,网游数据,银行交易数据,传感器数据,和/或闭合字幕数据等。这里举例描绘了几个,实时数据1000可以包括从感应器1001,股票1002,互联网1003和银行1004等等实时收集的数据。数据分析引擎1007可以接收来自数据流1006的数据元素。来自不同数据源的数据可以被存储在存储系统1011并且为大数据分析所访问,例如数据集123可以来自不同的数据源并且为大数据分析所访问。
请理解图1是以非常简化的形式介绍一些概念,例如,分布设备1016和1017可能经过防火墙才联到数据分析引擎1007,数据分析引擎1007从数据流1006和/或存储系统1011访问或接收的数据可能经过数据过滤器筛选,等等。
图1-1图示了为大数据集迭代计算自相关函数,其所有(v=p>1)组件被直接迭代计算,的例子计算系统架构100a。关于计算系统架构100a,这里将先只介绍该架构中的主要部件的功能和相互关系,而关于这些部件如何协作共同完成迭代自相关函数计算的过程将在后面结合图2中描述的流程图一起介绍。图1-1图示了图1显示的1006和1007。参考图1-1,计算系统架构100a包括组件计算模块131和自相关函数计算模块192。组件计算模块131可以是通过高速数据总线与一个或多个存储媒体紧密耦合的或通过一个网络,如局域网,广域网,甚至互联网与由存储系统管理的一个或多个存储媒体松散耦合的。相应地,组件计算模块131和任何其它连接的计算设备和它们的组件,可以在网络上发送和接收消息相关数据(例如,互联网协议(“ip”)数据报和其它使用ip数据报的高层协议,例如,用户数据报协议(“udp”),实时流协议(“rtsp”),实时传输协议(“rtp”),微软媒体服务器(“mms”),传输控制协议(“tcp”),超文本传送协议(“http”),简单邮件传送协议(“smtp”),等等)。组件计算模块131的输出会被作为自相关函数计算模块192的输入,自相关函数计算模块192可以生成自相关函数193。
通常,存储媒体121可以是一个单个局部存储媒体也可以是一个被一个存储管理系统管理的由多个物理上分布的存储设备组成的复杂存储系统。
存储媒体121包含一个数据集123。通常,数据集123可以包含来源于不同种类的数据,例如,股价,音频数据,视频数据,地理空间数据,互联网数据,移动通讯数据,网游数据,银行交易数据,传感器数据,闭合字幕数据,和实时文字等。
如图所示,数据集123包括存储在存储媒体121的多个存储单元的多个数据元素。例如,数据元素101,102,103,104,105,106,107,108,109,和110分别存储在存储单元121a,121b,121c,121d,121e,121f,121g,121h,121i,以及121j,等等,……还有多个数据元素存储在其它存储单元。
参考计算系统架构100a,通常组件计算模块131包含为直接迭代计算调整后计算窗口的一组n个数据元素的v(v=p>1)个组件的v个组件计算模块。v是迭代计算自相关函数的给定算法中直接迭代计算的组件的个数,它随着使用的迭代算法不同而不同。如图1-1中所示,组件计算模块131包含一个组件cd1计算模块161和一个组件cdv计算模块162,它们之间还有v-2个其它组件计算模块,它们可以是组件cd2计算模块,组件cd3计算模块,……,以及组件cdv-1计算模块。每个组件计算模块计算给定延迟的特定的组件。延迟会在一个指定的延迟范围内变化,例如,从1变到一个指定的延迟上限maxl,或者从一个指定的延迟下限minl变到一个指定的延迟上限maxl。例如,maxl=10,则对于相同的输入数据自相关将分别在延迟l=1,延迟l=2,延迟l=3,…延迟l=10被计算。延迟范围可作为计算系统的输入。通常,maxl的值被设置为小于计算窗口规模的1/4。延迟初始化模块171可以初始化一个延迟值。在一个给定延迟上,v个组件被计算,然后被存储在存储空间,例如组件cd1被计算后被存储在存储空间172,组件cdv被计算后被存储在存储空间173等。存储空间(如172和/或173)可以是内存中的一个或多个数组或硬盘上的一个或多个文件。然后,延迟被延迟更新模块175更新为给定延迟范围内的一个新值,例如通过加1或减1。然后v个组件计算模块为同一个计算窗口用新延迟值再计算v个组件,然后计算的v个组件被存储在存储空间。该过程可被重复直到给定延迟范围内的每个延迟上的v个组件都被计算。理论上,对于同一个计算窗口,一共会有v*maxl个组件被计算和存储。但实际上,由于并不是所有组件都和延迟有关,它们不会随着延迟的变化而变化(例如,和或平均值等),对同一个计算窗口只需要计算一次。因此组件计算模块131对同一个计算窗口实际计算的组件个数少于v*maxl。131实际计算的组件个数取决于使用的特定的迭代算法。如图1-1所示,组件计算模块131包含组件cd1计算模块161和组件cdv计算模块162。它们之间还有计算组件cd2,……,cdv-1的v-2个组件计算模块。每个组件计算模块包含一个为第一个调整前计算窗口初始化一个组件的初始化模块和一个为调整后计算窗口直接迭代计算该组件的算法。例如,组件cd1计算模块161包含初始化模块132来初始化给定延迟上的组件cd1和迭代算法133来迭代计算给定延迟上的组件cd1,组件cdv计算模块162包含初始化模块138来初始化给定延迟上的组件cdv和迭代算法139来迭代计算给定延迟上的组件cdv。
初始化模块132可以在初始化组件cd1时使用或在自相关函数计算被重置时使用。同样,初始化模块138可以在初始化组件cdv时使用或在自相关函数计算被重置时使用。
一旦自相关在给定延迟范围内所有延迟上的组件被组件计算模块131计算和存储。计算系统可根据需要开始另一个循环来计算给定延迟范围的自相关函数。参考图1-1,计算系统架构100a还包括延迟初始化模块191,自相关函数计算模块192,自相关193和延迟更新模块194等。延迟初始化模块191可以设置一个初始延迟值(如设置延迟l=1,l=minl或l=maxl)。延迟更新模块194可将延迟更新为给定延迟范围内的一个新值(如给延迟l加1或减1或以其它方式枚举)。对于一个给定延迟,自相关计算模块192可基于一个或多个迭代计算的给定延迟上的组件计算给定延迟上的自相关。通过循环计算出给定延迟范围内所有延迟上的自相关则得到指定延迟范围的自相关函数。
如图1-1所示,100a包括两个循环,一个循环用于通过调整前计算窗口给定延迟范围内所有延迟上的组件迭代计算调整后计算窗口给定延迟范围内所有延迟上的组件,另一个循环用于基于调整后计算窗口给定延迟范围内所有延迟上的组件计算调整后计算窗口给定延迟范围的自相关函数。使用两个分开的循环的优点是当不是每次有数据更新都要计算自相关函数时,计算系统可以只执行迭代计算组件的循环,而只有自相关函数被访问时,才执行计算自相关函数的循环。其缺点是需要额外空间和时间来存储迭代计算的组件。这两个循环完全可以合并成一个循环,这种情况下就不需要172和173,但是对于每次数据变化,无论自相关函数被访问与否自相关函数都会被计算。
图1-2图示了为大数据集迭代计算自相关函数并且部分(v(2≤v<p,p≥3)个)组件直接迭代计算,部分(w=p-v)组件间接迭代计算的一个例子计算系统架构100b。在一些实现中,计算系统架构100b和100a之间的区别是架构100b包括组件计算模块135。除此之外,和100a有同样标记号的部分都按同样的方式工作。为了不重复之前在100a描述里面解释过的东西,只有不同的部分会在这里讨论。100b里面的数字v和100a里面的数字v可能不同,因为有些100a里被直接迭代计算的组件会在100b里被间接迭代计算。在100a中,v=p≥3,但在100b中,2≤v<p。参考图1-2,计算系统架构100b包括组件计算模块135。组件计算模块131的输出可以作为组件计算模块135的输入,计算模块131和135的输出可以作为自相关函数计算模块192的输入,自相关函数计算模块192可以生成自相关函数193。组件计算模块135通常包括w=p-v个组件计算模块来间接迭代计算w个组件。例如,组件计算模块135包括组件计算模块163用于间接迭代计算组件ci1,组件计算模块164用于间接迭代计算组件ciw,以及它们之间的其它w-2个组件计算模块。间接迭代计算w个组件包括逐个地间接迭代计算w个组件的每一个。间接迭代计算一个组件包括访问和使用除该组件本身之外的一个或多个组件。那一个或多个组件可以是被初始化,直接迭代计算或间接迭代计算过的。
图2图示了为大数据迭代计算自相关函数的一个例子方法200的流程图。方法200会分别结合计算系统架构100a和100b的组件和数据一起描述。
方法200包括设定一个延迟上限maxl(maxl>1)或一个延迟范围(minl,maxl)其中1≤minl<maxl,在该延迟范围内设定延迟l的一个延迟值并初始化计算窗口规模n(n>2(maxl+1))(201)。
方法200包括初始化一个数据集的指定规模为n的调整前计算窗口的延迟为l的自相关函数的v(1≤v≤p,p>1)个组件(202)。例如,对于计算设备100a和100b,方法200可根据组件的定义访问和利用存储在存储媒体121上的数据集123的一个计算窗口中的数据元素初始化该计算窗口的v个组件。组件计算模块131可以访问计算窗口122中的数据元素101,102,103,104,105,106,107,和108。初始化模块132可以用数据元素101到108初始化给定延迟的组件cd1141。如图所示,组件cd1141包含贡献151,贡献152和其它贡献153。贡献151是数据元素101对给定延迟的组件cd1141的贡献。贡献152是数据元素102对给定延迟的组件cd1141的贡献。其它贡献153是数据元素103到108对给定延迟的组件cd1141的贡献。同样,初始化模块138可以用101到108初始化给定延迟的组件cdv145。如图所示,组件cdv145包含贡献181,贡献182和其它贡献183。贡献181是数据元素101对给定延迟的组件cdv145的贡献。贡献182是数据元素102对给定延迟的组件cdv145的贡献。其它贡献183是数据元素103到108对给定延迟的组件cdv145的贡献。
方法200包括保存延迟为l的v个组件(210)。例如参考图1-1和图1-2,组件计算模块131可将132初始化的延迟为l的组件cd1141保存在存储空间172。类似地,组件计算模块131可将138初始化的延迟为l的组件cdv145保存在存储空间173。
方法200包括判断是否给定延迟范围内的所有延迟上的v个组件都被计算(211)。如果否,则方法200包括更新延迟l(212),继续迭代计算新延迟上的v个组件直到给定延迟范围内的所有延迟上的v个组件被计算和保存。如果是,则方法200包括或者根据需要(如自相关函数被访问)计算给定延迟范围内的自相关函数或者访问下一个要被从调整前计算窗口中去除和下一个要被加入到调整前计算窗口中的数据元素从而开始新一轮迭代计算(这时调整后计算窗口成为新一轮迭代计算的“调整前计算窗口”)。例如参考图1-1和图1-2,如果131没有完成给定延迟范围内所有延迟上的v个组件的迭代计算,则175会更新延迟,131会继续迭代计算新延迟上的v个组件直到给定延迟范围内所有延迟上的v个组件的迭代计算都完成。100a或100b根据需要启动191,192和194计算给定延迟范围内所有延迟上的自相关193,或者访问要从计算窗口中去除的数据元素102和要加入计算窗口的数据元素109开始下一个计算窗口的迭代计算。
方法200包括当v<p即不是所有组件都被直接迭代计算时,根据需要逐个地间接迭代计算延迟为l的自相关的w=p-v个组件中的每一个组件基于被计算组件之外的一个或多个组件(214)。这w个组件只有当自相关函数被访问时才会被计算。例如,参考图1-2其部分组件被直接迭代计算而部分组件被间接迭代计算:延迟初始化模块191初始化一个延迟值(213),组件计算模块135间接迭代计算w个组件(214),包括计算模块163可基于组件ci1之外的一个或多个组件来间接迭代计算组件ci1,计算模块164可基于组件ciw之外的一个或多个组件来间接迭代计算组件ciw,其它w-2个组件计算模块间接迭代计算组件ci2到ciw-1。这一个或多个组件可以是初始化,直接迭代计算,或间接迭代计算过的。自相关计算模块192基于一个或多个直接和或间接迭代计算的组件计算给定延迟的自相关193。计算系统100b将判断是否给定延迟范围内每个延迟上的w个组件都被计算(216)。否,则更新模块194将延迟更新为给定延迟范围内的一个新延迟值(217),重复以上计算直到给定延迟范围内所有延迟值上的w个组件都被间接迭代计算;是,100b则访问要从计算窗口中去除的数据元素102和要加入计算窗口的数据元素109开始新一轮下一个计算窗口的迭代计算。
方法200包括根据需要计算一个给定延迟延迟范围内所有延迟上的自相关函数。其包括当自相关函数被访问时,初始化延迟值(213),自相关计算模块192基于一个或多个初始化或直接和或间接迭代计算的组件计算给定延迟的自相关193(215)。延迟更新模块194将延迟更新为给定延迟范围内的一个新延迟值(216),重复以上计算直到给定延迟范围内每个延迟值上的自相关193被计算(217)。参考图1-1中191至194的循环和图1-2中191,135,192,193,194的循环。图1-2中间接迭代计算组件和计算自相关函数的循环被合并成一个。
方法200包括访问一个要被从调整前计算窗口中去除的数据元素和一个要被加入到调整前计算窗口的数据元素,并设定延迟l的一个初始值(203)。例如,参考100a和100b,数据元素101和数据元素109可在数据元素101-108被访问后被访问。数据元素101被从存储媒体121的121a位置访问。数据元素109被从存储媒体121的121i位置访问。延迟初始化组件171可以设置延迟l为1或一个指定的延迟上限maxl。
方法200包括调整调整前计算窗口,包括:从调整前计算窗口中去除要去除的数据元素和向调整前计算窗口中加入要加入的数据元素(204)。例如,数据元素101被从计算窗口122去除,数据元素109被加入到计算窗口122,然后计算窗口122转变成调整后计算窗口122a。
方法200包括为调整后计算窗口直接迭代计算延迟为l的自相关函数的v个组件(205),其包括:访问调整后计算窗口两侧不包括新加入的数据元素在内的各l个数据元素(206);访问为调整前计算窗口初始化或计算的延迟为l的自相关的v个组件(207);利用访问的数据元素从v个组件中的每一个组件数学地去除被去除的数据元素的任何贡献(208);及利用访问的数据元素向v个组件中的每一个组件数学地加入被加入的数据元素的任何贡献(209)。其细节描述如下。
为调整后计算窗口直接迭代计算指定延迟l的自相关函数的v个组件包括访问调整后计算窗口两侧不包括新加入的数据元素在内的各l个数据元素(206)。例如,如果指定延迟l=1,迭代算法133可访问数据元素102及数据元素108。如果指定延迟l=2,迭代算法133可访问数据元素102和103及数据元素107和108……。类似地,如果指定延迟l=1,迭代算法139可访问数据元素102及数据元素108。如果指定延迟l=2,迭代算法139可访问数据元素102和103及数据元素107和108……。
为调整后计算窗口直接迭代计算延迟为l的自相关函数的v个组件包括访问调整前计算窗口的延迟为l的自相关函数的v(1≤v≤p)个组件(207)。例如,当延迟l=1时,迭代算法133可访问延迟为1的组件cd1141,当延迟l=2时,迭代算法133可访问延迟为2的组件cd1141……。类似地,当延迟l=1时,迭代算法139可访问延迟为1的组件cdv145,当延迟l=2时,迭代算法139可访问延迟为2的组件cdv145……。
为调整后计算窗口直接迭代计算指定延迟l的自相关函数的v个组件包括利用访问的数据元素从v个组件中的每一个组件数学地去除被去除的数据元素的任何贡献(208)。例如,当延迟l=2时,直接迭代计算延迟为2的组件cd1143可包括贡献去除模块133a利用访问的数据元素101,102和103从延迟为2的组件cd1141中数学地去除贡献151。类似地,直接迭代计算延迟为2的组件cdv147可包括贡献去除模块139a利用访问的数据元素101,102和103从延迟为2的组件cdv145中数学地去除贡献181。贡献151和181来自于数据元素101。
为调整后计算窗口直接迭代计算延迟为l的自相关函数的v个组件包括利用访问的数据元素从v个组件中的每一个组件数学地加入被加入的数据元素的任何贡献(208)。例如,当延迟l=2时,直接迭代计算延迟为2的组件cd1143可包括贡献加入模块133b利用访问的数据元素107,108和109向延迟为2的组件cd1141中数学地加入贡献154。类似地,直接迭代计算延迟为2的组件cdv147可包括贡献加入模块139b利用访问的数据元素107,108和109向延迟为2的组件cdv145中数学地加入贡献184。贡献154和184来自于数据元素109。
如图1-1和1-2所示,组件cd1143包括贡献152(来自数据元素102的贡献),其它贡献153(来自数据元素103-108的贡献),以及贡献154(来自数据元素109的贡献)。类似地,组件cdv147包括贡献182(来自数据元素102的贡献),其它贡献183(来自数据元素103-108的贡献),以及贡献184(来自数据元素109的贡献)。
当自相关函数被访问并且v<p(即,不是所有组件都被直接迭代计算)时,方法200包括根据需要间接迭代计算给定延迟范围内每个延迟上的自相关的w=p-v个组件(213,214,216,217)。这些组件只有当自相关函数被访问时才会被计算。例如,参考图1-2其部分组件直接迭代计算,部分组件间接迭代计算,计算模块163可以基于组件ci1之外的一个或多个组件来间接迭代计算组件ci1,计算模块164可以基于组件ciw之外的一个或多个组件来间接迭代计算组件ciw。这一个或多个组件可以是初始化,直接迭代计算,或间接迭代计算过的。循环214,216到217枚举给定延迟范围内的每个延迟并对于每个延迟执行上述的间接迭代计算。
方法200包括在需要的基础上计算自相关函数。其包括当自相关函数被访问时,初始化延迟值(213),自相关计算模块192基于一个或多个初始化或直接和或间接迭代计算的组件计算给定延迟的自相关193(215)。延迟更新模块194将延迟更新为给定延迟范围内的一个新延迟值(216),重复以上计算直到给定延迟范围内每个延迟值上的自相关193被计算(217)。当自相关函数被访问时,方法200包括可根据需要间接迭代计算延迟为l的w个组件(214)。例如,在架构100b中,计算模块163可基于组件ci1之外的一个或多个组件间接迭代计算ci1,及计算模块164可基于组件ciw之外的一个或多个组件间接迭代计算ciw,……。一旦给定延迟范围内所有延迟的自相关被计算,方法200包括访问下一个要被去除的数据元素和下一个要被加入的数据元素。
随着更多数据元素的访问203-212可以被重复,213-217可以根据需要被重复。例如,在数据元素101和109被访问或接收以及组件cd1143到组件cdv147范围内的组件被计算之后,数据元素102和数据元素110可以被访问(202)。每调整一次计算窗口则开始新一轮的迭代计算,原来的“调整后计算窗口”将成为新一轮迭代计算的“调整前计算窗口”。一旦一个要去除的数据元素和一个要加入的数据元素被访问或接收,方法200包括从新的调整前计算窗口中去除要去除的数据元素和向新的调整前计算窗口加入要加入的数据元素来调整新的调整前计算窗口(203)。例如,计算窗口122a可在去除数据元素102和加入数据元素110之后转变为计算窗口122b。然后计算系统把122b作为新的“调整前计算窗口”重复以上描述过的迭代计算过程。
方法200包括基于调整前计算窗口的v个组件为调整后计算窗口直接迭代计算延迟为l的自相关函数的v个组件(205),这包括访问调整后计算窗口两端不包括新加入的数据元素在内的各l个数据元素(206),访问v个组件(207),从v个组件中的每一个组件数学地去除被去除的数据元素的任何贡献(208),及向v个组件中的每一个组件数学地加入被加入的数据元素的任何贡献(209)。例如,参考100a和100b,当延迟l=1时,迭代算法133可用于为计算窗口122b直接迭代计算延迟为1的组件cd1144基于为计算窗口122a计算的延迟为1的组件cd1143(205)。迭代算法133可访问数据元素103及数据元素109(206)。迭代算法133可访问延迟为1的组件cd1143(207)。直接迭代计算延迟为1的组件cd1144包括贡献去除模块133a从延迟为1的组件cd1143中数学地去除贡献152也即数据元素102的贡献(208)。直接迭代计算延迟为1的组件cd1144包括贡献加入模块133b向延迟为1的组件cd1143中数学地加入贡献155也即数据元素110的贡献(209)。类似地,当延迟l=1时,迭代算法139可用于为计算窗口122b直接迭代计算延迟为1的组件cdv148基于为计算窗口122a计算的延迟为1的组件cdv147。迭代算法139可访问数据元素103及数据元素109。迭代算法139可访问延迟为1的组件cdv147。直接迭代计算延迟为1的组件cdv148包括贡献去除模块139a从延迟为1的组件cdv147中数学地去除贡献182也即数据元素102的贡献。直接迭代计算延迟为1的组件cdv148包括贡献加入模块139b向延迟为1的组件cdv147中数学地加入贡献185也即数据元素110的贡献。
如图所示,延迟为l的组件cd1144包括其它贡献153(来自数据元素103-108的贡献),贡献154(来自数据元素109的贡献),及贡献155(来自数据元素110的贡献),延迟为l的组件cdv148包括其它贡献183(来自数据元素103-108的贡献),贡献184(来自数据元素109的贡献),及贡献185(来自数据元素110的贡献)。
方法200包括根据需要间接迭代计算给定延迟的w个组件和自相关函数。
方法200包括,根据需要即只有自相关函数被访问时,间接迭代计算给定延迟的w个组件和自相关函数。如果自相关函数不被访问,方法200包括继续为下一个计算窗口访问或接收下一个要去除的数据元素和下一个要加入的数据元素(203)。如果自相关函数被访问,方法200包括间接迭代计算给定延迟范围内所有延迟上的自相关的w个组件(213,214,216,217),基于迭代计算的组件计算给定延迟范围内所有延迟上的的自相关(213,215,216,217)。
当下一个要去除的数据元素和要加入的数据元素被访问,组件cd1144可被用来直接迭代计算下一个组件cd1,组件cdv148可被用来直接迭代计算下一个组件cdv。
图3-1图示了在大数据上迭代计算自相关函数时从计算窗口300a中去除的数据元素和加入到计算窗口300a中的数据元素。计算窗口300a向右边移动。参考图3-1,一个已有的数据元素总是从计算窗口300a的左边被去除,一个数据元素总是被加入到计算窗口300a的右边。
图3-2图示了在大数据上迭代计算自相关函数时从计算窗口300a访问的数据。对于计算窗口300a,前n个数据元素被访问用来为第一个计算窗口初始化给定延迟范围内所有延迟的两个以上组件,然后根据需要间接迭代计算w=p-v个组件及自相关函数。随着时间推移,一个最老的数据元素如第(m+1)个数据元素被从计算窗口300a中去除,一个数据元素如第(m+n+1)个数据元素被加入到计算窗口300a。调整后计算窗口的给定延迟范围内每个延迟上的一个或多个组件然后被直接迭代计算基于为第一个计算窗口计算的组件。延迟l=1时,共有4个数据元素被访问,包括被去除的数据元素,一个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及一个与被加入的数据元素相邻的数据元素。延迟l=2时,共有6个数据元素被访问,包括被去除的数据元素,2个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及2个与被加入的数据元素相邻的数据元素。延迟为l=maxl时,共有2*(maxl+1)个数据元素被访问,包括被去除的数据元素,maxl个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及maxl个与被加入的数据元素相邻的数据元素。然后根据需要间接迭代计算给定延迟的w=p-v个组件及自相关函数。然后计算窗口300a通过去除一个老数据元素和加入一个新数据元素再次被调整,……。对于一个给定的迭代算法,v是个常数,间接迭代w=p-v个组件的操作数也是一个常数,所以对于一个给定的延迟范围,数据访问量和计算量被减少并且是常数。计算窗口规模n越大,则数据访问量和计算量的减少就越显著。
图3-3图示了在大数据上迭代计算自相关函数时从计算窗口300b中去除的数据元素和加入到计算窗口300b中的数据元素。计算窗口300b向左边移动。参考图3-3,一个新数据元素总是从计算窗口300b的右边被去除,一个老数据元素总是被加入到计算窗口300b的左边。
图3-4图示了在大数据上迭代计算自相关函数时从计算窗口300b访问的数据。对于计算窗口300b,前n个数据元素被访问用来为第一个计算窗口初始化给定延迟的两个或多个组件,然后根据需要间接迭代计算w=p-υ个组件及自相关函数。随着时间推移,一个数据元素如第(m+n)个数据元素被从计算窗口300b中去除,一个数据元素如第m个数据元素被加入到计算窗口300b。调整后计算窗口的给定延迟范围内每个延迟上的自相关的一个或多个组件然后被直接迭代计算基于为第一个计算窗口计算的组件。延迟l=1时,共有4个数据元素被访问,包括被去除的数据元素,一个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及一个与被加入的数据元素相邻的数据元素。延迟l=2时,共有6个数据元素被访问,包括被去除的数据元素,2个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及2个与被加入的数据元素相邻的数据元素。延迟为l=maxl时,共有2*(maxl+1)个数据元素被访问,包括被去除的数据元素,maxl个与被去除的数据元素相邻的数据元素,被加入的数据元素,以及maxl个与被加入的数据元素相邻的数据元素。然后根据需要间接迭代计算给定延迟的w=p-υ个组件及自相关函数。然后计算窗口300b通过去除一个新数据元素和加入一个老数据元素再次被调整,……。对于一个给定的迭代算法,υ是个常数,间接迭代w=p-v个组件的操作数也是一个常数,所以对于一个给定的延迟范围,数据访问量和计算量被减少并且是常数。计算窗口规模n越大,则数据访问量和计算量的减少就越显著。
以下的部分有一些自相关函数的组件的例子和迭代自相关函数计算算法的例子。
图4-1图示自相关函数的定义。假设x=(xm+1,xm+2,……,xm+n)是一个包含参与自相关函数计算的数据元素的一个规模为n的调整前计算窗口。该计算窗口可以向右或向左两个方向移动。例如,当要计算最新数据的自相关时,该计算窗口向右移动。这时,一个数据被从该计算窗口的左侧去除,一个数据被加入到该计算窗口的右侧。当要复查老数据的自相关时,该计算窗口向左移动。这时,一个数据被从该计算窗口的右侧去除,一个数据被加入到该计算窗口的左侧。这两种情况下用于迭代计算组件的方程是不同的。为了区别它们,定义前种情况调整后计算窗口为xi,后种情况调整后计算窗口为xii。每当自相关函数的任何组件由于数据集中数据元素的变化而需要被重新计算时,开始新一轮的迭代计算。在新一轮的迭代计算里,原来的调整后计算窗口变成新一轮计算的调整前计算窗口。
方程401和402是分别为第k轮计算调整前计算窗口x里的所有数据元素的总和sk和平均值
为展示如何利用组件迭代计算自相关函数,三个不同的迭代自相关函数算法被提供作为例子。每当计算窗口有一个数据变化时新的一轮计算就开始了(例如,122→122a→122b)。一个和或平均值是计算自相关函数的基本组件。迭代计算一个和或平均值的方程是被所有例子迭代自相关函数计算算法都用到的迭代组件方程。
图4-2说明第一个例子迭代自相关函数计算算法(迭代算法1)可用到的方程。方程401和402可分别被用来初始化组件sk和/或
图4-3说明第二个例子迭代自相关函数计算算法(迭代算法2)可用到的方程。方程401和402可分别被用来初始化组件sk和/或
图4-4说明第三个例子迭代自相关函数计算算法(迭代算法3)可用到的方程。方程401和402可分别被用来初始化组件sk和/或
为展示三个例子迭代自相关函数算法以及它们与传统算法的比较,下面给出三个具体计算的例子。使用3个计算窗口的数据。对于传统算法,所有3个计算窗口的计算过程完全相同。对于迭代算法,第一个计算窗口进行多个组件的初始化,第二个和第三个计算窗口进行迭代计算。
图5-1,图5-2,图5-3分别显示了用于一个计算实例的第一个,第二个,和第三个计算窗口。计算窗口503包括大数据集501的头4个数据元素:8,3,6,1。计算窗口504包括大数据集501的4个数据元素:3,6,1,9。计算窗口505包括大数据集501的4个数据元素:6,1,9,2。该计算实例假设计算窗口从左向右移动。大数据集501可以是大数据或流数据。计算窗口规模502(n)是4。
首先用传统算法分别计算计算窗口503,504和505的自相关函数。
为计算窗口503计算延迟上限为2的自相关函数:
没有任何优化的情况下,为规模为4的计算窗口计算延迟上限为2的自相关函数共有3次除法,9次乘法,9次加法和14次减法。
相同的方程和过程可被用来分别为图5-2显示的计算窗口504计算延迟上限为2的自相关和为图5-3显示的计算窗口505计算延迟上限为2的自相关。计算窗口504延迟上限为2的自相关
下面用迭代算法1分别计算计算窗口503,504,和505的自相关函数。
为规模为4的计算窗口503计算自相关函数:
为计算窗口503计算延迟上限为2的自相关函数:
1.用方程402,410,411,和412分别初始化第1轮的组件
2.用方程413计算第1轮的自相关ρ(1,1)和ρ(2,1):
为计算窗口503计算延迟上限为2的自相关函数时共有3个除法,11个乘法,9个加法和11个减法。
为规模为4的计算窗口504计算自相关函数:
1.用方程415,416,417,和418分别迭代计算第2轮的组件
ss2=ss1+xm+1+42-xm+12=110+92-82=110+81-64=127
2.用方程419计算第2轮的自相关ρ(2,1)和ρ(2,2):
计算窗口504迭代计算延迟上限为2的自相关函数时共有3个除法,16个乘法,16个加法和11个减法。
为规模为4的计算窗口505计算自相关函数:
1.用方程415,416,417,和418分别迭代计算第3轮的组件
ss3=ss2+xm+1+42-xm+12=127+22-32=127+4-9=122
2.用方程419计算第3轮的自相关ρ(3,1)和ρ(3,2):
为计算窗口505计算延迟上限为2的自相关函数时共有3个除法,16个乘法,16个加法和11个减法。
下面用迭代算法2分别计算计算窗口503,504,和505的自相关函数。
为规模为4的计算窗口503计算自相关函数:
1.用方程402,426,和427初始化第1轮的组件
2.用方程428计算第1轮的自相关ρ(1,1)和ρ(1,2):
为计算窗口503计算延迟上限为2的自相关函数时共有3个除法,9个乘法,9个加法和14个减法。
为规模为4的计算窗口504计算自相关函数:
1.用方程430,431,和432分别迭代计算第2轮的组件
2.用方程433计算第2轮的自相关ρ(2,1)和ρ(2,2):
计算窗口504迭代计算延迟上限为2的自相关函数时共有3个除法,13个乘法,18个加法和11个减法。
为规模为4的计算窗口505计算自相关函数:
1.用方程430,431,和432分别迭代计算第3轮的组件
2.用方程433计算第3轮的自相关ρ(3,1)和ρ(3,2):
计算窗口505迭代计算延迟上限为2的自相关函数时共有3个除法,13个乘法,18个加法和11个减法。
下面用迭代算法3分别计算计算窗口503,504,和505的自相关函数。
为规模为4的计算窗口503计算自相关函数:
1.用方程402,439,和440初始化第1轮的组件
2.用方程441计算第1轮的自相关ρ(1,1)和ρ(1,2):
为计算窗口503计算延迟上限为2的自相关时共有3个除法,9个乘法,9个加法和14个减法。
为规模为4的计算窗口504计算自相关函数:
1.用方程443,444,和445分别迭代计算第2轮的组件
2.用方程446计算第2轮的自相关ρ(2,1)和ρ(2,2):
计算窗口504迭代计算延迟上限为2的自相关时共有3个除法,13个乘法,15个加法和13个减法。
为规模为4的计算窗口505计算自相关函数:
1.用方程443,444,和445分别迭代计算第3轮的组件
2.用方程446计算第3轮的自相关ρ(3,1)和ρ(3,2):
计算窗口505迭代计算延迟上限为2的自相关函数时共有3个除法,13个乘法,15个加法和13个减法。
在以上三个例子中,平均值被用于迭代自相关函数计算。和也可被用于自相关函数迭代计算,只是操作数不同。另外,上述三个例子中的计算窗口是从左向右移动。当计算窗口从右向左移动时其计算过程类似只是应用一组不同的方程。
图6-1图示了n=4延迟上限为2时,传统自相关函数算法和迭代自相关函数算法的计算量。如图所示,任何一个迭代算法和传统算法的除法操作,乘法操作,加法操作和减法操作个数都差不多。
图6-2图示了n=1,000,000延迟上限为2时,传统自相关函数算法和迭代自相关函数算法的计算量。如图所示,任何一个迭代算法都比传统算法少很多乘法操作,加法操作和减法操作。迭代算法把需要在成千上万台计算机上处理的计算只在单机上就能完成从而大大提高计算效率,减少计算资源,降低计算系统能耗。
本发明可以在不脱离其思想或本质特征的情况下以其它特定的方式来实现。本申请描述的实现方案从各个方面来说是仅作为示范性的而不是限制性的。因此,本发明的范围由附加的权利要求书而不是前面的描述来指明。与权利要求书中权利要求的含义和范围等价的所有变化都包含在它们的范围内。
- 还没有人留言评论。精彩留言会获得点赞!