一种基于LSTM神经网络的蒙汉互译方法与流程
本发明属于机器翻译技术领域,特别涉及一种基于lstm神经网络的蒙汉互译方法。
背景技术
蒙古族是中华民族五十六个民族的重要组成之一,是草原游牧民族的典型代表和草原文化的重要传承者,蒙古语则是中国蒙古族同胞使用的主要语言,是蒙古国的官方语言,其使用范围广泛,在国际上具有很重要的地位。伴随着中国经济的快速发展,蒙古族与汉族之间的经济、文化交流越来越广泛,而蒙古族和汉族同胞要进行交流就需要翻译,而人工翻译成本较高,这给蒙古族的经济发展带来了许多不便。
幸运的是,随着大数据时代的到来,人工智能飞速发展,机器翻译越来越成熟,通过计算机蒙古语和汉语之间的互译成为了可能。例如,可以给出一篇中文文章,机器可以自动快速的生成一篇蒙古文文章。近年来,蒙汉机器翻译的研究对于两族文化的价值观相互渗透,促进良好民族关系的建立以及促进和蒙古国之间的对外贸易和文化交流起到了很大的作用。
从20世纪40年代末至今这六十多年的时间里,追随着机器翻译发展的脚步,研究人员也从未停止过机器翻译在蒙汉翻译中应用的研究。
汉语的句子成分和蒙古语的句子成分有所区别,并且在句子的语序上有很大的不同,这给蒙汉机器翻译带来了很大的困难。
早期版本的翻译系统是基于短语的机器翻译,即pbmt(phrase-basedmachinetranslation)。pbmt会将输入的句子分成一组单词或者短语,并将其单独翻译。这显然不是最佳的翻译策略,完全忽略了整个语句和上下文之间的联系。
技术实现要素:
为了克服上述现有技术的缺点,本发明的目的在于提供一种基于lstm神经网络的蒙汉互译方法,从以前的完全忽略整个语句和上下文之间联系的基于统计的蒙汉机器翻译,到充分考虑整个语句和上下文之间联系的基于lstm的神经机器翻译,提高了机器翻译的质量和效率,改进了传统的nmt(neuralmachinetranslation),改变了内蒙古地区机器翻译发展相对落后的现状。
为了实现上述目的,本发明采用的技术方案是:
一种基于lstm神经网络的蒙汉互译方法,采用编码-解码结构,编码器读取源语言句子,编码为维数固定的向量,解码器读取该向量,依次生成目标语言。编码器和解码器均采用lstm神经网络,在编码器中,将输入的源语言句子经过一个双向的lstm神经网络进行编码,其中每个句子表达成一个上下文语义向量,形成上下文语义向量组,所述上下文语义向量作为用户意图的编码;在解码器中,一个lstm神经网络不断循环运行,生成目标语言中的每一个字,在生成每一个字的同时,考虑输入的源语言句子所对应的上下文语义向量,使得生成的内容与源语言的意思相符合。
所述编码器使用双向lstm模型,单向的lstm神经网络某时刻的输出只与当前时刻以及之前的输入信息相关,而双向的lstm神经网络某一时刻的输出不仅与当前时刻以及之前的输入信息相关,还与之后的信息有关,充分的考虑了整个句子与上下文之间的联系。
前向的lstm神经网络
解码器:
在给定源语言句子x和目标语{y1,...,yt-1}的条件下,解码器依次生成目标语言的字yt,在解码层定义条件概率为:
p(yt|y1,...,yt-1,x)=g(yt-1,st,ct)
其中,g是激活函数sigmoid,st是解码器的lstm神经网络在t时刻的隐层状态,ct表示生成过程中的外部输入信息。
翻译准确率的保证
在上文的生成过程中,每一句汉语生成一个上下文语义向量,用来翻译一句原语句,因此,翻译后的目标语句不会脱离文本的原意,同时,后一句的生成结果依赖于前一句的词,因此保证了整个句子的连贯性,保证了翻译的准确率。
训练
在训练的过程中,将解码器的输出向量输入到一个softmax回归层中,选择softmax回归层得到的实际概率分布与期望输出的交叉熵作为损失函数,损失函数为:
y为期望输出,a为实际输出,n为批大小。
为了加速训练,防止陷入局部最优,本发明采用了最小批随机梯度下降算法作为优化算法:
其中,:=为同步更新,
与现有的基于统计的机器翻译方法相比,本发明充分考虑了整个语句和上下文之间的联系,提高机器翻译的效率;其次,利用本质上是lstm的编码器和解码器,保证了较高的翻译质量;最后,通过运用残差学习的形式,提高了翻译的准确性并减少梯度消失。
附图说明
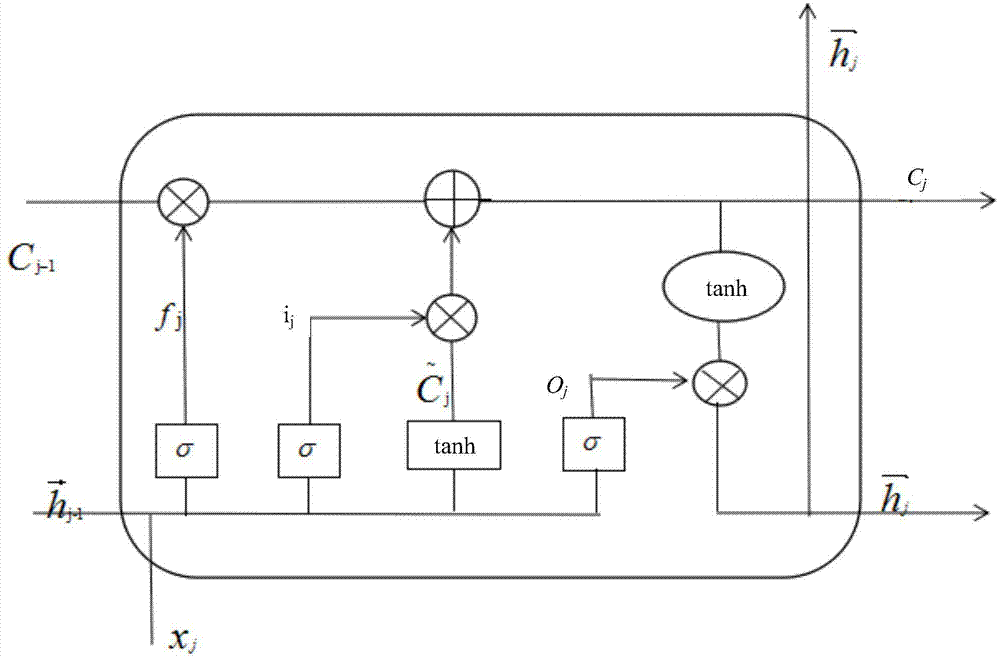
图1为隐层状态的求解原理图。
图2为本发明的汉语到蒙古语的翻译原理示意图。
图3为本发明的蒙古语到汉语的翻译原理示意图。
具体实施方式
下面结合附图和实施例详细说明本发明的实施方式。
基于lstm神经网络的蒙汉互译方法,采用编码-解码结构,编码器和解码器都是通过lstm实现。
其中编码器使用双向lstm模型,前向的lstm神经网络
图1是隐层状态的计算原理,该图被称为memoryblock(记忆块),主要包含了三个门(forgetgate、inputgate、outputgate)与一个记忆单元(cell)。方框内上方的那条水平线,被称为单元状态(cellstate),它就像一个传送带,可以控制信息传递给下一时刻。
隐层状态的求解步骤:
第一步:首先决定什么信息可以通过cellstate。
这个决定由“forgetgate”层通过sigmoid来控制,它会根据上一时刻的输出hj-1和当前输入xj来产生一个0到1的fj值,来决定是否让上一时刻学到的信息cj通过或部分通过。0表示完全不允许通过,0-1之间的值表示部分通过,1表示允许完全通过。
如下:
fj=sigmod(wf*xj+wfhj-1+bf)
其中:wf和bf表示遗忘门包含的神经元中调教好的参数。
第二步:产生需要更新的新信息。
这一步包含两部分,第一部分是“inputgate”层通过sigmoid来决定哪些值用来更新,ij的值为1时表示不需要更新,0或者0-1之间时需要更新。第二部分是tanh层用来生成新的候选值
其中:其中:wi和bi表示输入门包含的神经元中调教好的参数。wc和bc表示记忆单元包含的神经元中调教好的参数。
第一步和第二步结合起来就是丢掉不需要的信息,添加新信息的过程:
第三步:决定模型的输出。
首先是通过sigmoid层来得到一个初始输出,然后使用tanh将cj值缩放到-1到1间,再与sigmoid得到的输出逐对相乘,从而得到前向隐层状态
其中:wo和bo表示输出门包含的神经元中调教好的参数。
用同样的方法计算出
在给定源语言句子x和目标语{y1,...,yt-1}的条件下,解码器依次生成目标语言的字yt,在解码层定义条件概率为:
p(yt|y1,...,yt-1,x)=g(yt-1,st,ct)
其中,g是激活函数sigmoid,st是解码器的lstm神经网络在t时刻的隐层状态,ct表示生成过程中的外部输入信息。
翻译准确率的保证
在上文的生成过程中,每一句汉语生成一个上下文语义向量,用来翻译一句原语句,因此,翻译后的目标语句不会脱离文本的原意,同时,后一句的生成结果依赖于前一句的词,因此保证了整个句子的连贯性,保证了翻译的准确率。
训练
在训练的过程中,将解码器得到的向量输入一个softmax回归层中,得到可能结果的概率分布。选择softmax得到的实际概率分布于期望输出的交叉熵作为损失函数。损失函数为:
y为期望输出,a为实际输出,n为批大小。
为了加速训练,防止陷入局部最优,对神经元里面的参数w和b进行调整,该过程称为梯度下降,本发明采用了最小批随机梯度下降算法作为优化算法:
其中,:=为同步更新,
以下是汉蒙互译的两个具体实施例。
实施例1,汉译蒙:
参照图2,首先,图2的下半部分,(x1,...,xt)表示一个汉语句子的t个字,将用户输入的t个字按顺序经过一个双向的lstm网络进行编码,形成一个上下文语义向量组
具体的翻译步骤如下:
1.编码器读取输入的源语言句子x=(x1,...,xi);
2.编码器采用循环神经网络将读到的x编码为隐层状态,形成一个上下文语义向量组
3.编码器采用循环神经网络逆向将读到的x编码为隐层状态,与步骤2同样的方法得到后向隐层状态,从而形成一个上下文语义向量组
4.编码器将前向和后向状态链接在一起得到每个字的解释向量
5.解码器的lstm神经网络不断循环运行,生成t时刻的隐层状态st;
6.解码器在给定源语言句子x和目标语{y1,...,yt-1}的条件下,依次生成目标语言的字yt。将编码器计算出来的对输入的源语言的编码向量输入给解码器的rnn单元,然后,解码器会根据循环神经网络单元计算概率向量。即对于目标语言句子中的每一个字的概率进行计算。最后,根据计算得到的概率采样生成目标语言。
实施例2,蒙译汉:
与汉译蒙同样的方法,参照图3,图3的下半部分,(x1,...,xt)表示一句蒙语的t个字,系统将用户输入的t个字按顺序经过一个双向的lstm网络进行编码,形成一个上下文语义向量组
- 还没有人留言评论。精彩留言会获得点赞!