一种滑窗箱型图中值滤波的异常点处理方法与流程
本发明涉及数据驱动的数据预处理技术领域,具体涉及一种适用于复杂工业过程的滑窗箱型图中值滤波的异常点处理方法。
背景技术
在复杂工业过程中,过程变量数据的产生、获取、传输以及转换过程中存在很多干扰,主要可以分为内部干扰和外部干扰。内部干扰主要包括工业过程设备的固有干扰和数据采集系统光敏电阻等基本性质或内部电路引起的干扰;外部干扰主要包括人工调节或天气等原因对工业过程设备的干扰和电磁波或电源等进入数据采集系统内部导致的干扰。由于干扰的存在,使得采集的过程变量数据存在异常点、噪声等,无法直接进行数据分析。
忽略异常点的存在会对数据分析的结果带来不良影响,因此有必要对包含异常点的数据进行数据清洗,包括异常点检测和处理。异常点检测是找出其行为很不同于预期对象的一个检测过程,这些对象被称为异常点或者离群点。目前,常用的异常点检测方法中,主要包括基于统计学的方法和基于各种模型的智能算法方法。基于统计学的异常点检测有基于一元正态分布的方法、基于多元高斯分布的方法、基于格拉布斯检验的方法、基于统计量的方法和基于箱型图分析的方法等;基于各种模型的智能异常点检测有基于pca分析的方法、基于knn聚类的方法和基于rnn回归的方法等。但大多数方法要求数据服从正态分布,因此在非正态分布的情况下不适用。异常点处理不只是要消除错误、冗余和数据噪音,还要能将按不同规则所得的各种数据集一致起来。异常点处理通常采用分箱、聚类、回归、计算机检查和人工检查结合等方法“光滑”数据,并保证数据细节结构不受到破坏和丢失。
箱形图(bp)是一种不需要假定数据服从特定分布形式的异常点检测方法,由于它通过数据分散情况的统计图就可以看出数据的对称性和分散程度等信息,因而在各种领域被广泛使用。箱型图不仅可以直观、客观地识别样本序列中的异常点,而且耐抗性强;但是样本序列数据量大时,bp存在整箱处理容易导致异常点漏判和分箱处理可能造成异常点误判等问题。
中值滤波算法具有运算简单、运行速度快、孤立的噪声点消除效果好等优点,被广泛被用于时间序列和数字图像的噪声预处理中。但是中值滤波不加选择地对时间序列中每个点都进行了中值化处理,虽然可以有效剔除异常点并加以填补,但对非异常点容易造成误滤波;中值滤波另一不足就是滤波窗口选择不合理会导致信号细节结构受到破坏和丢失,处理后的数据波形不够圆滑。
技术实现要素:
有鉴于此,本发明提供了一种滑窗箱型图中值滤波的异常点处理方法,以克服现有技术中针对样本序列数据量大时bp方法的异常点漏判或误判、中值滤波对非异常点容易造成误滤波、中值滤波处理后的数据波形不够圆滑等问题。
为实现上述目的,本发明提出了一种滑窗箱型图中值滤波的异常点处理方法,所述方法包括:
a、获得工业过程中实时采集的过程变量的样本序列,采用滑窗箱的箱型图方法对所述样本序列进行异常点检测;
b、构建异常点检测计数向量,统计每个初判异常点在所有滑窗箱中被检测为异常的次数,若大于设定的异常点检测频数阈值,则判定为真正的异常点,否则,认定为误判予以保留;
c、对判定的异常点数据采用邻域中值滤波方法进行剔除和填补,形成正常的连续时序数据。
经由上述技术方案可知,与现有技术相比,本发明提供的一种滑窗箱型图中值滤波的异常点处理方法,针对样本序列数据量大时bp整箱处理容易导致异常点漏判或分箱处理可能造成异常点误判等问题,根据滑动窗口原理,采用滑窗箱型图方法进行异常点的检测;由于异常点将能被检测出很多次,而非异常点即使被误判但被检测为异常点的次数很少,通过异常点检测频数阈值可对过程变量的时间序列进行异常点的准确判定;其次,最后,结合箱型图分析结果,仅对时间序列中真正的异常点进行邻域中值滤波(nmf)处理,且滤波窗口与箱型图滑动窗口大小保持一致,使经过中值滤波后的数据细节结构不受到破坏和丢失、时间序列波形尽量圆滑,有效提高了数据质量。
附图说明
为了更清楚地说明本发明具体实施方式或现有技术中的技术方案,下面将对具体实施方式或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施方式,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
图1为本发明实施例提供的一种滑窗箱型图中值滤波的异常点处理方法流程示意图;
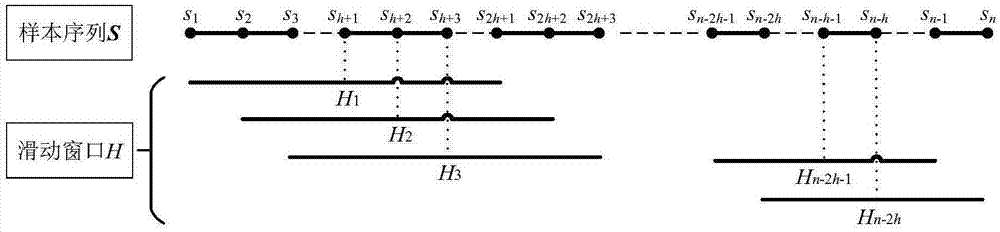
图2为本发明实施例提供的滑窗箱型图的滑动窗口示意图;
图3为本发明实施例提供的箱型图及其主要统计量;
图4为本发明实施例提供的滑窗箱型图分析图;
图5为本发明实施例提供的1#关键过程变量处理效果图;
图6为本发明实施例提供的2#关键过程变量处理效果图;
图7为本发明实施例提供的3#关键过程变量处理效果图;
图8为本发明实施例提供的4#关键过程变量处理效果图。
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
此外,下面所描述的本发明不同实施方式中所涉及的技术特征只要彼此之间未构成冲突就可以相互结合。
实施例1
如图1所示,本实施例提供了一种滑窗箱型图中值滤波的异常点处理方法,包括以下步骤:
a、针对工业过程中实时采集的过程变量的时间序列,采用一种滑窗箱的箱型图方法对样本序列进行异常点检测;
b、构建异常点检测计数向量,统计每个初判的异常点在所有滑窗箱中被检测的次数,若大于设定的异常点检测频数阈值,则认定为正式的异常点,否则,认定为误断予以保留;
c、对判定的异常点数据采用邻域中值滤波方法进行剔除和填补,形成正常的连续时序数据;
具体地,在步骤a中,针对过程变量时间序列的一种滑窗箱型图检测异常点的具体方法包括:
通过机理分析,选取了与加氢裂化过程数据建模目标变量相关性强的过程变量n个,通过采样m次可以得到被选取的工序间的变量的时间序列:si=[si,1,si,2,...,si,m]t,i=1,2...,n,获得过程变量的时间序列为:s=[s1,s2,...,sn]。进一步的,在步骤a中,滑窗箱型图检测异常点的具体方法包括:
(1)获取样本序列s=[s1,s2,...,s38],借鉴滑窗原理(sw),定义一个特定长度的邻域区间为滑箱窗口h,滑窗h含有奇数个元素。
(2)通过滑箱窗口h对样本序列s进行遍历,得到滑窗矩阵sw=[sw1,sw2,...,swn],其中,
即样本序列前h个点、后h个点不进行以其为中心的滑窗处理,其中h=(h-1)/2。
(3)bp箱型图主要包括五个统计量:下限(最小值),下四分位数(第一四分位数),中位数(第二四分位数),上四分位数(第三四分位数),上限(最大值)。对每个滑窗向量swi计算箱型图的五个统计量,根据箱型图分析检测异常点。下面分别介绍各统计量的定义及计算公式。
①下四分位数[q1]
下四分位数指的是将样本中所有数值由小到大排列后第25%的数字或分成四等份数值最小的分割点的数值。一般情况下,对于一个样本序列s=[s1,s2,...,sn],首先将样本中所有数值由小到大排列得到序列s′=[s′1,s′2,...,s′n]。为了得到四分位数,首先需确定四分位数的位置,其计算公式如下:
其中,p代表四分位数的位置,i表示四分位数的序号,n表示样本序列中包含的元素个数。根据四分位数的位置,就可计算相应的四分位数。
因此,下四分位数的位置为:
则下四分位数
式中,
②中位数[q2]
中位数指的是将样本中所有数值由小到大排列后第50%的数字或处于中间位置的数值。中位数的位置为:
则中位数
式中,
③上四分位数[q3]
上四分位数指的是将样本中所有数值由小到大排列后第75%的数字或分成四等份数值最大的分割点的数值。上四分位数的位置为:
则上四分位数
式中,
④下限[min]
下限指的是非异常范围内的最小值。一般用四分位距(interquartilerange,iqr),确定限制线的位置。四分位全距iqr的计算公式为:
iqr=q3-q1
则下限min由下面公式确定:
min=min(smin={s|s∈5∧s≥q1-1.5iqr})
式中,smin代表样本序列s大于或等于的理想下限q1-1.5iqr的元素,min表示取最小值。
⑤上限[max]
上限指的是非异常范围内的最大值。上限max的计算公式为:
max=max(smax={s|s∈s∧s≤q3+1.5iqr})
式中,smax代表样本序列s小于或等于的理想上限q1+1.5iqr的元素,max表示取最大值。
其中两个t形的盒须即为下、上限,q1-1.5iqr和q1+1.5iqr范围内称为内限,内限以外的数据点即为异常点。此外,两个t形的盒须分别延伸至q1-3iqr和q1+3iqr范围内最小、最大值处为外限,外限外的数据点为极端异常点。
在步骤b中,采用计数向量判定异常点的具体方法包括:
由于滑窗箱处理可以使每个变量的每个采样点都被滑动窗口多次遍历,异常点将能被检测出很多次,而非异常点即使被误判但被检测为异常点的次数很少,因此通过设置异常点检测次数阈值来判定该点是否为异常点。
定义一个异常点检测计数向量oc并初始化
oc=[oc1,oc2,...,ocn]=0
若滑窗向量swi的箱形图检测出第j个点为异常点,则
oci-h-1+j=oci-h-1+j+1
然后根据异常点检测效果和多次实验经验,设定一个异常点检测次数阈值tv来判定该点是否为异常点,即当oci≥tv时,则si为异常点;当oci<tv时,则si为正常点。
在步骤c中,对判定的异常点进行中值滤波处理的具体方法包括:
针对一维时间序列,邻域中值滤波(nmf)的具体方法就是把时间序列中的一点的值用该点的邻域区间内各点值的中位值代替。对于一个样本序列s=[s1,s2,...,sn],将样本中所有数值由小到大排列得到序列5′=[s′1,s′2,...,s′n],则该时间序列的中值为:
定义一个特定长度的邻域区间为窗口h,此窗口与滑箱窗口大小保持一致。窗口大小为奇数,使待处理的异常点位于窗口正中间,然后将该点的值用窗口内各点值的中位值代替,那么邻域中值滤波(nmf)的输出结果为:
mi=med{si}=med{si-h,...,si,...,si+h},i=1,2,...,n
其中h=(h-1)/2。然而,滑动窗口会导致时间序列前h个点、后h个点无法进行中值滤波。为了处理上述问题,一般情况下,将原时间序列前后增加h个0,即将样本时间序列s=[s1,s2,...,sn]扩充为sl=[01,...,0h,s1,s2,...,sn,01,...,0h];若时间序列足够长且前h个点、后h个点对后续步骤无影响,可忽略该问题。
实施案例2
如图2-8所示,在上述实施例的基础上,本实施例提供了一种加氢裂化过程异常点处理方法,采用了上述的一种滑窗箱型图中值滤波的异常点处理方法,包括以下步骤:
a、针对工业过程中实时采集的过程变量的时间序列,采用一种滑窗箱的箱型图方法对样本序列进行异常点检测;
b、构建异常点检测计数向量,统计每个初判的异常点在所有滑窗箱中被检测的次数,若大于设定的异常点检测频数阈值,则认定为正式的异常点,否则,认定为误断予以保留;
c、对判定的异常点数据采用邻域中值滤波方法进行剔除和填补,形成正常的连续时序数据;
在本实施例中,根据其所应用的连续生产流程-加氢裂化生产过程,基于相对生产流程的多工序间的关键过程变量,从中选取相关性强的主要工序间变量作为连续生产流程关键变量,通过采样得到这些变量的时间序列并组成原始数据矩阵,采用滑窗箱型图进行异常点的检测;通过异常点检测频数阈值对各过程变量的时间序列进行异常点的判定;仅对判定的异常点进行邻域中值滤波,使数据的细节结构免遭破坏,时间序列尽量平滑,有效提高了数据质量。
具体地,在步骤a中,针对过程变量时间序列的一种滑窗箱型图检测异常点的具体方法包括:
通过加氢裂化过程的机理分析,选取了与数据建模目标相关性强的过程变量38个,每5分钟采样一次数据,共采样126720次。得到被选取的过程变量的时间序列:si=[si,1,si,2,...,si,126720]t,i=1,2...,38,获得过程变量的时间序列为:s=[s1,s2,...,s38]。
进一步的,在步骤a中,滑窗箱型图检测异常点的具体方法包括:
(1)获取样本序列s=[s1,s2,...,s38],借鉴滑窗原理(sw),定义一个特定长度的邻域区间为滑箱窗口h,根据现场经验时滞分析设置滑窗h大小为45。
(2)通过滑箱窗口h对样本序列s进行遍历,得到滑窗矩阵sw=[sw1,sw2,...,sw38],其中,
如图2所示,样本序列前h个点、后h个点不进行以其为中心的滑窗处理,其中h=22,n=126720。
(3)bp箱型图主要包括五个统计量:下限(最小值),下四分位数(第一四分位数),中位数(第二四分位数),上四分位数(第三四分位数),上限(最大值),如图3所示。对每个滑窗向量swi计算箱型图的五个统计量,根据箱型图分析检测异常点。下面分别介绍各统计量的定义及计算公式。
①下四分位数[q1]
下四分位数指的是将样本中所有数值由小到大排列后第25%的数字或分成四等份数值最小的分割点的数值。一般情况下,对于一个样本序列s=[s1,s2,...,sn],首先将样本中所有数值由小到大排列得到序列s′=[s′1,s′2,...,s′n]。为了得到四分位数,首先需确定四分位数的位置,其计算公式如下:
其中,p代表四分位数的位置,i表示四分位数的序号,n表示样本序列中包含的元素个数。根据四分位数的位置,就可计算相应的四分位数。
因此,下四分位数的位置为:
则下四分位数
式中,
②中位数[q2]
中位数指的是将样本中所有数值由小到大排列后第50%的数字或处于中间位置的数值。中位数的位置为:
则中位数
式中,
③上四分位数[q3]
上四分位数指的是将样本中所有数值由小到大排列后第75%的数字或分成四等份数值最大的分割点的数值。上四分位数的位置为:
则上四分位数
式中,
④下限[min]
下限指的是非异常范围内的最小值。一般用四分位距(interquartilerange,iqr),确定限制线的位置。四分位全距iqr的计算公式为:
iqr=q3-q1
则下限min由下面公式确定:
min=min(smin={s|s∈s∧s≥q1-1.5iqr})
式中,smin代表样本序列s大于或等于的理想下限q1-1.5iqr的元素,min表示取最小值。
⑤上限[max]
上限指的是非异常范围内的最大值。上限max的计算公式为:
max=max(smax={s|s∈s∧s≤q3+1.5iqr})
式中,smax代表样本序列s小于或等于的理想上限q1+1.5iqr的元素,max表示取最大值。
图3中两个t形的盒须即为下、上限,q1-1.5iqr和q1+1.5iqr范围内称为内限,内限以外的数据点即为异常点。此外,两个t形的盒须分别延伸至q1-3iqr和q1+3iqr范围内最小、最大值处为外限,外限外的数据点为极端异常点。
在步骤b中,采用计数向量判定异常点的具体方法包括:
由于滑窗箱处理可以使每个变量的每个采样点都被滑动窗口多次遍历,异常点将能被检测出很多次,而非异常点即使被误判但被检测为异常点的次数很少,因此通过设置异常点检测次数阈值来判定该点是否为异常点,如图4所示。
定义一个异常点检测计数向量oc并初始化
oc=[oc1,oc2,...,ocn]=0
若滑窗向量swi的箱形图检测出第j个点为异常点,则
oci-h-1+j=oci-h-1+j+1
然后根据异常点检测效果和多次实验经验,设定一个异常点检测次数阈值tv来判定该点是否为异常点,本实施案例中tv=5,即当oci≥5时,则si为异常点;当oci<5时,则si为正常点。
在步骤c中,对判定的异常点进行中值滤波处理的具体方法包括:
针对一维时间序列,邻域中值滤波(nmf)的具体方法就是把时间序列中的一点的值用该点的邻域区间内各点值的中位值代替。对于一个样本序列s=[s1,s2,...,sn],将样本中所有数值由小到大排列得到序列s′=[s′1,s'2,...,s'n],则该时间序列的中值为:
定义一个特定长度的邻域区间为窗口h,此窗口与滑箱窗口大小保持一致。窗口大小为奇数,使待处理的异常点位于窗口正中间,然后将该点的值用窗口内各点值的中位值代替,那么邻域中值滤波(nmf)的输出结果为:
mi=med{si}=med{si-h,...,si,...,si+h},i=1,2,...,11
其中h=(h-1)/2。然而,滑动窗口会导致时间序列前h个点、后h个点无法进行中值滤波。为了处理上述问题,一般情况下,将原时间序列前后增加h个0,即将样本时间序列s=[s1,s2,...,sn]扩充为sl=[01,...,0h,s1,s2,...,sn,o1,...,0h];若时间序列足够长且前h个点、后h个点对后续步骤无影响,可忽略该问题。本案例中,h=45,h=22,采样点为126720个,所以前后22个点数量太少不足以影响时间序列,故忽略该问题。
图5-8展示了加氢裂化流程中几个关键变量一段时间内的采样数据由滑窗箱型图中值滤波处理的效果图。从图中可以看出,异常点基本被检测出来,少数非异常点被误判为异常点,但经过中值滤波处理后误判产生的影响较小。总之,滑窗箱型图中值滤波方法很好地实现了时间序列的异常点检测与处理,并保证了时间序列尽量平滑。
- 还没有人留言评论。精彩留言会获得点赞!