一种基于电子发票的数据挖掘方法与流程
本发明涉及电子发票领域,具体是一种基于电子发票的数据挖掘方法。
背景技术:
随着信息的高速发展,电子发票作为信息时代的产物,与普通发票一样,采用税务局统一发放的形式给商家使用。自2013年6月27日我国内地首张电子发票在北京诞生以来,电子发票在各地得到大力推广实施,呈现持续较快发展态势。仅2016年北京市电子发票服务平台的电子发票数据累计近2亿份。
电子发票数据是真实的消费原始数据,可是发票信息无法直观的体现出商品属性维度,同时没有很好的电子发票数据挖掘的方法,所以,如何从这些数据中找出某种规律,发现有用信息,越来越受到关注。因此,针对这一现状,迫切需要开发一种基于电子发票的数据挖掘方法,以克服当前实际应用中的不足。
技术实现要素:
本发明的目的在于提供一种基于电子发票的数据挖掘方法,以解决上述背景技术中提出的问题。
为实现上述目的,本发明提供如下技术方案:
一种基于电子发票的数据挖掘方法,包括以下步骤:
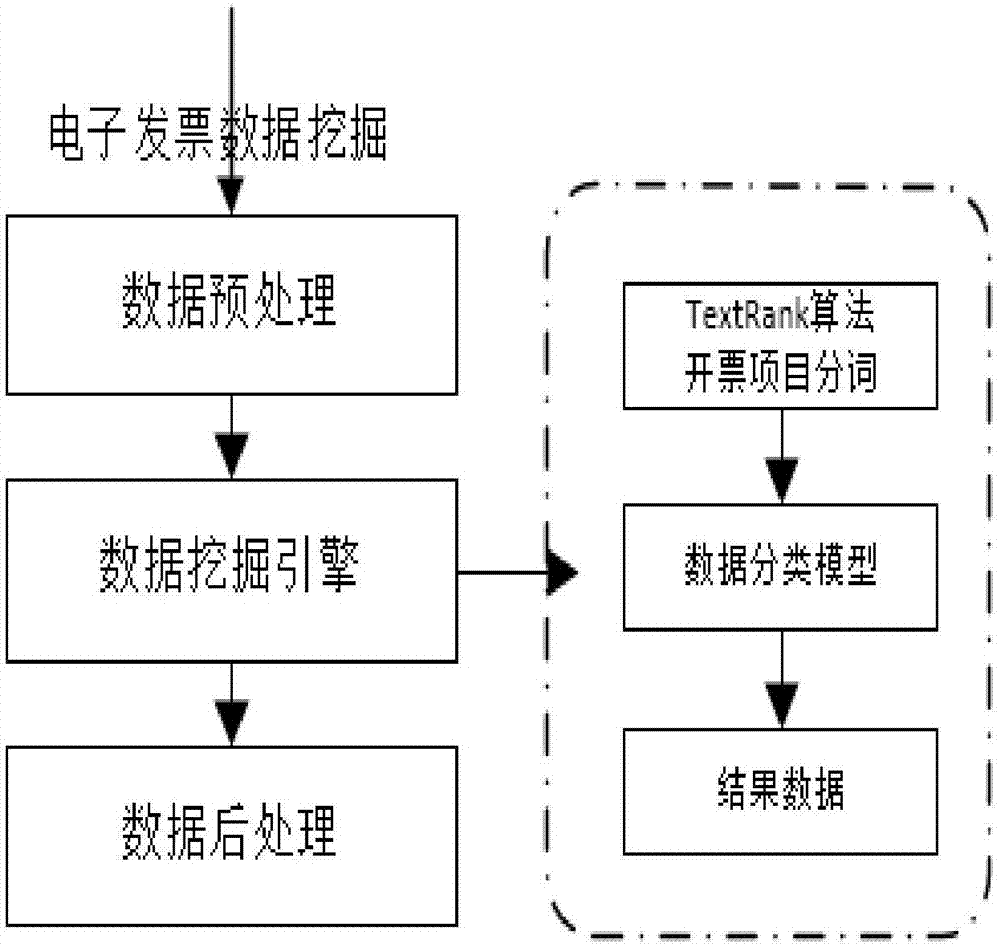
s1,数据预处理,采集电子发票数据并提取发票中有价值的信息,定义数据分类模型;
s2,数据挖掘引擎,根据中文分词算法结合数据分类模型,将数据归类;
s3,数据后处理,对挖掘的数据进行清洗、转化和标准化。
进一步的,在步骤s1中,采集电子发票数据并提取发票中有价值的信息具体为:销售方信息、购买方信息、开票时间、开票项目、金额、数量和税率信息。
进一步的,在步骤s1中,定义数据分类模型即为根据数据特征定义数据分类约束,建立数据分类模型。
进一步的,根据数据特征定义数据分类约束的方法为:前期通过原始初始化约束数据的方式创建数据分类模型;数据挖掘过程中通过机器学习方式,不断完善数据分类模型。
进一步的,在步骤s2中,根据中文分词算法结合数据分类模型,将数据归类的步骤为:先对开票项目进行中文分词,然后根据关键词与数据分类模型规则匹配,最后得出开票项目的归类。
进一步的,对开票项目进行中文分词的方法为:通过textrank算法提取关键词,pagerank的计算公式为:
进一步的,所述关键词与数据分类模型规则匹配可为:关键词与数据分类模型,通过中文相似度匹配算法得出相似度系来判断匹配;若相似度达到一定范围,则自动匹配数据的分类;否则将关键词数据打标签,存放至未匹配表中,通过数据训练,持续完善数据分类模型中的约束数据。
进一步的,在步骤s3中,对挖掘的数据进行清洗、转化、标准化的步骤为:对已有商品属性的电子发票数据,根据原数据属性,将数据清洗为不同维度的数据。
与现有技术相比,本发明的有益效果是:
该基于电子发票的数据挖掘方法,包含数据预处理、数据挖掘引擎和数据后处理,具体应用算法可自行自定义,满足了复杂的个性化需求;填补当前电子发票领域数据挖掘分析的空白,将海量的电子发票数据中存在的价值充分挖掘,同时本发明还适用于发票领域其他票种数据的挖掘。
通过对电子发票挖掘的数据,建立多维分析模型,可以分析商品消费规模、结构、速度等变化规律,预测消费趋势,区域购买力的实现程度,为相关部门制定促进消费政策、引导行业发展、进行市场宏观调控提供决策参考。
本发明所公开的数据挖掘方法能够将电子发票数据按照行业模型、商品模型、时间模型等进行主题分析,除电子发票外,其他票据的挖掘分析也可采用。
附图说明
图1为本发明的步骤流程图。
图2为本发明的机器学习方式流程图。
图3为本发明的发票样例图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1~3,本发明实施例中,一种基于电子发票的数据挖掘方法,包括以下步骤:
s1,数据预处理,采集电子发票数据并提取发票中有价值的信息,定义数据分类模型;
s2,数据挖掘引擎,根据中文分词算法结合数据分类模型,将数据归类;
s3,数据后处理,对挖掘的数据进行清洗、转化和标准化。
进一步的,在步骤s1中,采集电子发票数据并提取发票中有价值的信息具体为:销售方信息、购买方信息、开票时间、开票项目、金额、数量和税率信息等。
进一步的,在步骤s1中,定义数据分类模型即为根据数据特征定义数据分类约束,建立数据分类模型;
所述根据数据特征定义数据分类约束的方法为:前期通过原始初始化约束数据的方式创建数据分类模型;数据挖掘过程中通过机器学习方式(见图2所示),不断完善数据分类模型。
进一步的,在步骤s2中,根据中文分词算法结合数据分类模型,将数据归类的步骤为:先对开票项目进行中文分词,然后根据关键词与数据分类模型规则匹配,最后得出开票项目的归类;
所述对开票项目进行中文分词的方法为:通过textrank算法提取关键词,pagerank的计算公式为:
所述关键词与数据分类模型规则匹配可为:关键词与数据分类模型,通过中文相似度匹配算法(编辑距离算法)得出相似度系来判断匹配;若相似度达到一定范围,则自动匹配数据的分类;否则将关键词数据打标签,存放至未匹配表中,通过数据训练,持续完善数据分类模型中的约束数据。
在实际应用中,所述中文分词算法具体可为:主要是针对发票信息中的开票项目进行分词,例如一张发票(见图3)的开票项目为“小米红米3s全网通2gb内存16gbrom经典金色移动联通电信4g手机双卡双待”,进行中文分词后的信息为“手机,小米,金色,2gb,3s,rom,经典,内存,移动,联通,电信”。
在实际应用中,所述数据归类可为:将开票项目的分词结果与数据分类模型匹配,挖掘出发票信息中消费商品的内在价值,如“销售时间:2017年1月2日;销售价格699元;商品分类:通信器材;商品名称:小米手机;品牌:小米;颜色:金色;支持运营商:移动,联通,电信;规格:2gb,3s;其他:经典,内存”。
进一步的,在步骤s3中,对挖掘的数据进行清洗、转化、标准化的步骤为:对已有商品属性的电子发票数据,根据原数据属性,将数据清洗为不同维度(行业、品牌、商品、时间等)的数据。
在实际应用中,所述挖掘的数据进行清洗、转化、标准化具体可为:首先检查数据一致性,处理无效值和缺失值等,发现并纠正数据中可识别的错误;其次将数据进行标准化转化。
该基于电子发票的数据挖掘方法,包含数据预处理、数据挖掘引擎和数据后处理,具体应用算法可自行自定义,满足了复杂的个性化需求;填补当前电子发票领域数据挖掘分析的空白,将海量的电子发票数据中存在的价值充分挖掘,同时本发明还适用于发票领域其他票种数据的挖掘。
通过对电子发票挖掘的数据,建立多维分析模型,可以分析商品消费规模、结构、速度等变化规律,预测消费趋势,区域购买力的实现程度,为相关部门制定促进消费政策、引导行业发展、进行市场宏观调控提供决策参考。
本发明所公开的数据挖掘方法能够将电子发票数据按照行业模型、商品模型、时间模型等进行主题分析,除电子发票外,其他票据的挖掘分析也可采用。
以上的仅是本发明的优选实施方式,应当指出,对于本领域的技术人员来说,在不脱离本发明构思的前提下,还可以作出若干变形和改进,这些也应该视为本发明的保护范围,这些都不会影响本发明实施的效果和专利的实用性。
- 还没有人留言评论。精彩留言会获得点赞!