基于机器学习的影评情感倾向性分析的测试方法与流程
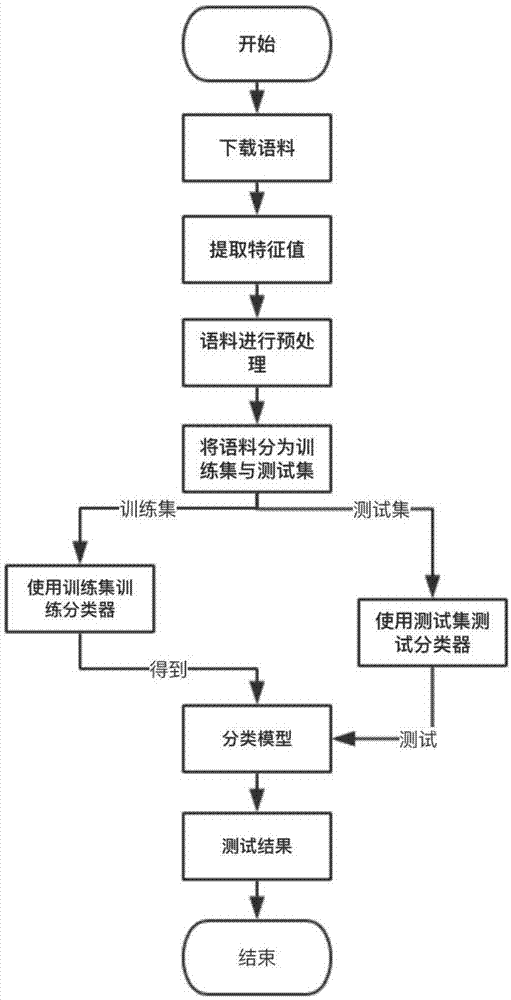
本发明属于自然语言处理领域,涉及一种基于机器学习的影评情感倾向性分析的测试方法。
背景技术:
在各种论坛、购物网站、评论网站、微博等,越来越多的用户在上面发表着自己的意见、看法、态度、情感,如果能分析出用户的情感变化过程,那么这些评论就会为我们提供大量的信息。比如某个电影的评论,某个商品的评价等。根据对带有情感色彩的主观性文本进行分析,识别出用户的态度,是喜欢,讨厌,还是中立。在实际生活中有很多应用,例如通过对微博用户的情感分析,来预测股票走势、预测电影票房、选举结果等,还可以用来了解用户对公司、产品的喜好,分析结果可以被用来改善产品和服务,还可以发现竞争对手的优劣势等等。在现有的技术中,对文本的情感分析主要是基于情感词典的中文情感分析,情感词典中的词语可以是单个字,也可以是词语。根据词典中的情感词情感极性的不同,将情感词典分为褒义词典及贬义词典,根据词典中情感词的极性及情感强度,计算整个句子的情感得分,最后得出句子的情感倾向,然而,该种方法对于一个具有等量的极性不同情感词的影评的情感整体倾向性判断准确性不高。技术实现要素:为了解决影评特征表示的训练集的测试问题,本发明提出如下方案:一种基于机器学习的影评情感倾向性分析的测试方法:步骤1:对影评进行下载;步骤2:选取特征词,根据已下载的影评,提取有意义的情感词的集合作为特征词集,特征词集中的每个词为特征词;步骤3:对已下载的影评处理,使用特征词集将每一条影评均以特征向量表示,其中,积极特征向量的集合为积极特征文本,消极特征向量的集合为消极特征文本,从中选取相同数量积极特征向量与消极特征向量组成特征向量文本;步骤4:将特征向量文本随机划分出训练集,并为训练集的每一特征向量添加积极或消极标签,训练朴素贝叶斯思想构建的分类器,并将特征向量文本随机划分出测试集,所述测试集的各个特征向量未添加积极或消极标签,且测试集用于测试朴素贝叶斯思想构建的分类器。进一步的,所述的训练集中的各特征向量被训练集训练的分类器分类,并计算当前测试的特征向量的不同情感倾向性概率,并归类其为更高概率的情感倾向,且对于该特征向量反映的影评的情感倾向性人为判读,对二者的结果比较,判断该测试集的该特征向量在当前分类器下的情感倾向性分析准确性。进一步的,使用特征词集将每一条影评均以特征向量表示的方法是:判断特征词集中的每一个特征词是否在该影评中出现,如果出现标注1,否则标注0,形成该影评的数组,将每条影评都转化为特征表示形式,作为特征向量。进一步的,所述的测试集的各特征向量被分类器的数学模型以计算,以判断其归类情感倾向,其计算为下式:ci表示分类的特征向量文本,i=0,1,wj表示特征词集中的特征词,j=1,2…n,n是特征词集中的特征词的数量,i=0表示待测影评情感倾向消极分类,i=1表示待测影评情感倾向积极分类,data为测试集中特征向量。有益效果:本发明测试方法以特征表示影评,将特征向量文本随机划分出训练集,并为训练集的每一特征向量添加积极或消极标签,训练朴素贝叶斯思想构建的分类器,并将特征向量文本随机划分出测试集,测试集的各个特征向量未添加积极或消极标签,且测试集用于测试朴素贝叶斯思想构建的分类器。该种测试方法,对于特征表示训练的分类器,能够适应性的作出较为准确的测试。附图说明图1为实施例1中基于机器学习的影评情感倾向性分析方法的流程图;图2为jieba分词提取主干处理结果图;图3为分类结果与伯努利朴素贝叶斯分类结果比较图;其中:实线为本发明的分类结果、虚线为伯努利朴素贝叶斯分类的结果;y轴为准确率、x轴为不同测试样本;图4为分类器构建示意图。具体实施方式实施例1:本实施例针对中文影评的情感倾向性分析,其提出了一种情感倾向的判别方法,主要包括训练方法、测试方法、分析方法,该方案使用机器学习的手段提取特征词、将文本转化为特征表示形式、通过朴素贝叶斯思想构建分类器,其转特征提取采用词性选取,避免因为影评少而没有提取出有意义的特征。本实施例公开的技术方案如下:一种基于机器学习的影评情感倾向性分析方法,包括以下步骤:步骤1:编写爬虫对豆瓣电影影评进行下载,下载的影评形成语料库;步骤(a):获取豆瓣中待下载电影的网址。步骤(b):下载每个电影对应的影评、电影名、评价人、评分、评论时间等信息,保存为csv格式。步骤2:提取特征,形成该语料库的特征集合:根据以下载的影评(即语料库中的各影评),提取语料库中各影评的有意义的情感词作为特征词,该步骤中,如果采用单一的方法,会导致无法提取较多有价值的特征词,所以在一种实施例中,结合下面两种方式提取特征词,能够提高对有价值特征词对提取率。步骤(a):使用jieba分词对语料库中所有影评进行分词处理,并提取出形容词、成语、区别词、动词的词语作为特征集合。步骤(b):使用jieba分词对语料库中所有影评进行提取主干处理,并提取其中主干词语加入特征集合。步骤(c):特征集合中可能存在停用词,因而使用停用词典去除停用词。步骤3:对影评进行处理,形成特征表示文本:步骤(a):使用jieba分词对语料库中每个影评进行分词,使用步骤2中得到的特征集合,判断特征集合中的每一个特征词是否在该影评中出现,如果出现标注1,否则标注0,形成该影评的数组,即将每条影评都转化为特征表示形式,需要说明的是,在本发明中,影评的特征向量即是指代影评的特征表示之后的文本。步骤(b):在语料库中的影评,由上述步骤,均以特征表示之后的文本表示,这些影评的特征表示之后的文本表示形成特征向量文本。步骤(c):去除无任何特征的特征表示之后的文本。步骤(d):为了减小由于积极与消极影评数量的不同而对分析结果造成的影响,在一种方案中,于特征向量中提取相同数量的积极和消极的特征表示的文本,形成本实施例中使用的特征向量文本,将特征向量文本随机划分出训练集,训练集中,每一个特征表示之后的文本添加积极或消极标签,1(true)表示积极,0(false)表示消极。需要说明的是,由于每个影评都较短,本实施例采用伯努利朴素贝叶斯算法的思想,统计的是词是否出现,而不是词出现了多少次。步骤4:使用朴素贝叶斯思想构建分类器,并改进使其更适合影评文本分类。基于朴素贝叶斯思想构建分类器的构建及改进的方法如下:步骤(a):分析朴素贝叶斯分类器,朴素贝叶斯分类的定义如下:1、设x={a1,a2,...,am}为一个待分类项,而每个a为x的一个特征属性。2、有类别集合c={y1,y2,...,yn}。3、计算p(y1|x),p(y2|x),...,p(yn|x)。4、如果p(yk|x)=max{p(y1|x),p(y2|x),...,p(yn|x)},则x∈yk。贝叶斯文本分类就是基于这个公式,即:其中p(ci)为第i个文本类别出现的概率,p(w1,w2...wn|ci)为文本类别为ci时出现特征向量(w1,w2...wn)的概率,p(w1,w2...wn)为特征向量出现的概率。在本实施例中,假设特征词在文本中出现的概率是独立的,也就是说词和词之间是不相关的,那么联合概率就可以表示为乘积的形式,如下:对于固定的训练集合来说,上式中p(w1)p(w2)…p(wn)是一个固定的常数,那么在进行分类计算的时候可以省略掉这个分母的计算,如是得到:p(ci|w1,w2...wn)=p(w1|ci)p(w2|ci)...p(wn|ci)p(ci)步骤(c):使用朴素贝叶斯思想构建分类器并改进。将朴素贝叶斯思想转化成计算公式,通过大量的训练文本得到p(ci),p(wn|ci),为了防止由于因子太小而导致结果溢出问题,使用对数进行处理。即得到l得到(p(ci))、l得到(p(wn|ci))并带入测试数据得到测试数据在不同分类中的评分。即:通过对影评分析,可以得出一个结论,相对于词语来说,积极词语出现在积极影评中的概率远远高于积极词语出现在消极影评中的概率。相反,消极词语出现在消极影评中的概率远远高于消极词语出现在积极影评中的概率。即某个词语出现在某类文本中的概率是特定的,可以利用某个词语出现的概率来影响最后的p(ci|w1,w2…wn)值。即:最后只要计算不同类别下p(ci|w1,w2...wn)的大小并取最大值即可。步骤(d):使用上述训练集得到p(ci)、p(wj|ci)、p(ci|wj)等参数的值:计算p(ci),其包括消极类概率与积极类概率:消极类概率:积极类概率:ci表示分类的特征向量文本,i=0,1。按类别计算所述特征词集中的特征词在训练集的该类特征向量文本中出现的概率:计算p(wj|ci),其包括特征词在训练集中消极特征向量文本中出现的概率与特征词在训练集中积极特征向量文本中出现的概率:特征词在训练集中消极特征向量文本中出现的概率:p(wj|c0)=[p(w0|c0),p(w1|c0),p(w2|c0),…,p(wn|c0)]特征词在训练集中积极特征向量文本中出现的概率:p(wj|c1)=[p(w0|c1),p(w1|c1),p(w2|c1),…,p(wn|c1)]ci表示分类的特征向量文本,i=0,1,wj表示特征词集中的特征词,j=1,2…n,n是特征词集中的特征词的数量。计算所述特征词集中的特征词能够分别出现在训练集的每类向量文本中的概率:计算p(ci|wj),其包括特征词能够出现在训练集的消极类中的概率与特征词能够出现在训练集的积极类中的概率:特征词能够出现在训练集的消极类中的概率:p(c0|wj)=[p(c0|w0),p(c0|w1),p(c0|w2),…,p(c0|wn)]特征词能够出现在训练集的积极类中的概率:p(c1|wj)=[p(c1|w0),p(c1|w1),p(c1|w2),…,p(c1|wn)]ci表示分类的特征向量文本,i=0,1,wj表示特征词集中的特征词,j=1,2…n,n是特征词集中的特征词的数量。以上是对训练步骤作出的详细公开。步骤5:将特征向量文本随机划分出测试集,测试集中,每一个特征表示之后的文本不添加积极或消极标签,用测试集对训练完成的模型进行测试、修改参数:步骤(a):使用训练集训练得到分类模型,在测试集数据上进行测试,对未标注的测试集数据进行分类。步骤(b):对公式中log(p(ci))、三项中的任意两项添加参数,平衡三者对最后结果的影响(注:参数在0~1之间)。将比对测试结果进行分析,调整参数。步骤(c):修改参数、重复测试寻找最优参数,并与朴素贝叶斯分类器进行比较。以上是对测试步骤作出对详细公开。上述基于机器学习的文本倾向性分析,通过大量的影评文本从中得到频率较高的词语作为特征,把影评文本变成使用特征表示,利用朴素贝叶斯、支持向量机等学习算法进行情感分类。由于自然语言是复杂的,一个词语在不同的语句中会有不同的情感极值,任何情感词典都无法概括情感词的所有特点,所以本发明改进基于机器学习进行影评倾向性分析,由于大家都采用词频较高的词语作为特征,如果数据不够多的,训练出来的分类器的效果将十分不理想,本文提出利用词语的词性、句子主干及少量的人工干扰来提取特征,然后利用得到的特征把所有影评文本转化为特征表示的形式,进而通过朴素贝叶斯思想构建分类器。该方法对计算机性能要求很低、选出的特征不会受频率的干扰、更适合影评分类、速度快、准确率较高。实施例2:作为实施例1中的技术方案的举例补充,图1显示了本发明分析方法的流程,本实施例采用jieba分词对大量文本进行分词并选取特定词性词语,且使用jieba分词提取句子主干词,取两者并集,对下载到的影评根据其评分进行分类,包括积极与消极两类。并将影评文本转化为特征表示的形式,使用分类算法构建分类器,再进行必要的后处理。下面以数据集中一个影评为例,结合图1对本发明加以详细说明。步骤1、影评下载,编写爬虫对豆瓣电影对影评进行下载。如下载到的其中一个电影评论如下:步骤2、对该影评提取特征:2.1使用jieba分词对所有影评进行分词处理,并提取出形容词、成语、区别词、动词的词语作为特征集合。例句影评提取词性后的结果如下:注:以上为被提取出来的结果,被淘汰的词语没有被列出来。2.2使用jieba分词对所有影评提取主干处理,并提取其中主干词语加入特征集合。例句影评分词并提取主干处理后的结果如下:2.3特征集合中可能存在停用词,使用停用词典去除停用词。步骤3:对影评进行处理,每条影评都转化为特征表示形式。使用jieba分词对每个影评进行分词,用上述特征词集表示每个影评,例句影评:国产类型片的里程碑,2个多小时节奏全程紧绷清晰,真热血真刺激。假设特征词集为[很好,喜欢,…,国产,里程碑,小时,节奏,全程,清晰,热血,刺激,…,共鸣,无聊]则该例句的特征表示为:[0,0,…,1,1,1,1,1,1,1,1,…,0,0]。为了减小由于积极与消极影评数量的不同而对分析结果造成的影响,在一种方案中,于特征向量中提取相同数量的积极和消极的特征表示的文本,形成本实施例中使用的特征向量文本,将特征向量文本随机划分出训练集,训练集中,每一个特征表示之后的文本添加积极或消极标签,1(true)表示积极,0(false)表示消极。如例句影评被随机至训练集,则其特征表示形式,即在首位置插入标识符,0表示消极、1表示积极。则其特征表示文本为:[1,0,0,…,1,1,1,1,1,1,1,1,…,0,0]。步骤4:算法实现:通过训练集得到以下三部分。计算p(ci),其包括消极类概率与积极类概率:消极类概率:积极类概率:ci表示分类的特征向量文本,i=0,1。按类别计算所述特征词集中的特征词在训练集的该类特征向量文本中出现的概率:计算p(wj|ci),其包括特征词在训练集中消极特征向量文本中出现的概率与特征词在训练集中积极特征向量文本中出现的概率:特征词在训练集中消极特征向量文本中出现的概率:p(wj|c0)=[p(w0|c0),p(w1|c0),p(w2|c0),…,p(wn|c0)]特征词在训练集中积极特征向量文本中出现的概率:p(wj|c1)=[p(w0|c1),p(w1|c1),p(w2|c1),…,p(wn|c1)]ci表示分类的特征向量文本,i=0,1,wj表示特征词集中的特征词,j=1,2…n,n是特征词集中的特征词的数量。计算所述特征词集中的特征词能够分别出现在训练集的每类向量文本中的概率:计算p(ci|wj),其包括特征词能够出现在训练集的消极类中的概率与特征词能够出现在训练集的积极类中的概率:特征词能够出现在训练集的消极类中的概率:p(c0|wj)=[p(c0|w0),p(c0|w1),p(c0|w2),…,p(c0|wn)]特征词能够出现在训练集的积极类中的概率:p(c1|wj)=[p(c1|w0),p(c1|w1),p(c1|w2),…,p(c1|wn)]ci表示分类的特征向量文本,i=0,1,wj表示特征词集中的特征词,j=1,2…n,n是特征词集中的特征词的数量。步骤5:使用测试集对训练完成的模型进行测试,使用得到的分类模型,在特征向量文本中随机生成测试集,使用其数据进行测试,对未标注的测试集的影评的特征表示之后的文本进行分类,比对测试结果进行分析,以判断当前训练模型的准确性。5.1.获取到想要分类的影评的特征表示的数组,即特征表示后的文本;5.2.分别计算该条影评的特征词wi在两类文档中出现的概率。即:为了防止结果过小或过大我们对p(wj|ci)数组的一项取对数与该条影评特征表示数组相乘并求和,得到倾向评分(反映概率)。设得到的消极的评分为f0;积极的评分f1;5.3.计算该条影评每个特征词分别出现在两类词语中的概率。即:为了防止结果过小或过大我们对p(ci|wj)数组的一项取对数与该条影评特征表示数组想成并求和得到倾向评分。设得到的消极的评分为g0;积极的评分g1;5.4.评分合并该条影评在消极中的最终评分为:该条影评在积极中的最终评分为:对于例句影评,其概率结果为:积极概率消极概率预测结果是否正确-38.352214246565453-41.408669267263221积极是对于上述评分,数据属于不同类别的评分,哪个值更大,则属于哪个类别的可能性就越大,例如一组数据-28.5338768667小于-23.4792674766,则其属于消极的可能性就会大一些。以上所述,仅为本发明创造较佳的具体实施方式,但本发明创造的保护范围并不局限于此,任何熟悉本
技术领域:
的技术人员在本发明创造披露的技术范围内,根据本发明创造的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明创造的保护范围之内。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1