一种深度神经网络训练方法与流程
本发明提出了一种深度神经网络的训练方法,属于机器学习领域。
背景技术
近年来,随着深度学习的发展,各种深度学习网络模型交替出现,为图像分类带来了新的解决方案。为了提升深度学习网络的分类性能,一方面可以通过改变网络结构,还可以通过训练方法的改进,本发明正是提出了一种新的训练方法对深度神经网络进行训练,从而实现图像的分类问题。
通常深度学习卷积网络一般使用softmax函数实现分类功能,但是这种网络很容易丢失输入样本图像的类内距和类间距信息。将度量学习融入深度卷积网络的学习过程中,可以有效地捕捉到输入样本的类内距和类间距信息,扩大不同类样本之间的距离,减小同类样本之间的距离,有效地提高网络最终的识别结果。
技术实现要素:
本发明的目的是提供一种深度神经网络训练方法,神经网络经过不断的前向传播和反向传播来调整网络中的权值矩阵,使网络的损失函数降到最低,并保持稳定范围之内,最终完成训练。
本发明解决其技术问题所采用的技术方案是:
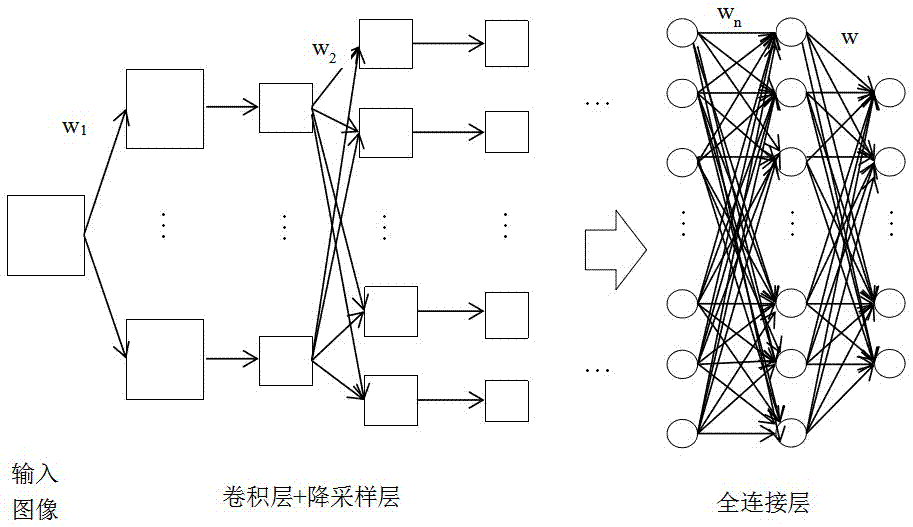
卷积神经网络,主要包括输入层、卷积层、降采样层和全连接层组成。输入层是待处理的输入数据或图像,卷积层和降采样层交替出现实现自动提取特征信息,全连接层实现图像分类功能,全连接层的最后一层是输出层。卷积神经网络的学习过程是一种有监督学习,本质上是输入到输出的映射,它的训练样本集是包含的是一系列向量对(x,yp),其中x表示输入向量,yp表示是理想输出向量。卷积神经网络可以自主地学习到图像中的特征,找到输出到输出之间的映射关系,而不需要提前设计出输入到输出之间的计算公式。卷积神经网络训练之前,需要初始化网络中的权值。一般使用不同的小随机数初始化权值,不同的初始值可以保证网络中的每个权值的更新过程都是不同的,而小的随机数能避免网络由于初始权值过大引起网络训练失败。
网络的训练过程包括两个阶段:
1.前向传播阶段
前向传播的过程是从样本集中选择一个样本,将样本送入网络,然后得到网络的实际输出值。在这个过程中,网络首先通过数据层读取样本的输入数据,然后经过网络各个层级进行数据处理,网络会在输出层得到实际输出结果。包括如下步骤:
(1)计算每个输入图像的特征和对应类中心特征之间的余弦距离作为损失函数,即基于余弦距离的centerloss;
(2)计算softmaxloss损失函数。
2.反向传播阶段
反向传播的过程是为了调整权值矩阵,根据网络实际输出值和理想输出值之间的误差,利用极小值误差反向传播到输入层,调整网络每层的权值矩阵w。包括如下步骤:
(a)根据softmaxloss损失函数,分别计算出该损失函数对输出层的参数quote
(b)根据基于余弦距的centerloss损失函数,分别计算出该损失函数对每个类的中心特征的quote
(c)根据softmaxloss损失函数和基于余弦距离的centerloss损失函数计算出的偏导数,更新网络中的参数quote
本发明和现有技术相比,具有以下优点和效果:神经网络经过不断的前向传播和反向传播来调整网络中的权值矩阵,使网络的损失函数降到最低,并保持稳定范围之内,最终完成训练。基于余弦距离的centerloss度量学习模块,通过计算每个样本和对应类中心之间的余弦距离作为损失函数,考虑到了输入特征图的方向信息,同类样本之间相互靠近,网络输出的特征具有明显的判别性,可以提高网络最终的识别结果。
附图说明
图1为本发明卷积神经网络结构。
图2为本发明网络训练流程。
具体实施方式
下面结合附图并通过实施例对本发明作进一步的详细说明,以下实施例是对本发明的解释而本发明并不局限于以下实施例。
1.损失函数计算:
训练时,将基于softmaxloss和基于余弦距离的centerloss相结合,对应的损失函数如下:
quote
其中,quote
网络中quote
quote
其中,quote
网络中quote
quote
其中,quote
2.参数更新:
卷积神经网络的参数在更新时,使用随机梯度下降法。我们将网络中的参数分为三部分,分别是输出层的参数quote
在卷积神经网络和基于余弦距的centerloss相结合的网络中,输出层的参数quote
quote
quote
其中,quote
quote
在(6)式中,quote
网络中每个类的中心特征的quote
quote
quote
其中,quote
网络中其他层参数quote
quote
quote
其中,quote
quote
其中,quote
quote
其中,quote
训练流程如图2所示。
本说明书中所描述的以上内容仅仅是对本发明所作的举例说明。本发明所属技术领域的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,只要不偏离本发明说明书的内容或者超越本权利要求书所定义的范围,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!