基于多极情感分析的用户行为预测系统及其方法与流程
本发明涉及人工智能分析中自然语言处理领域,更具体地说,涉及一种基于多极情感分析的用户行为预测系统及其方法。
背景技术:
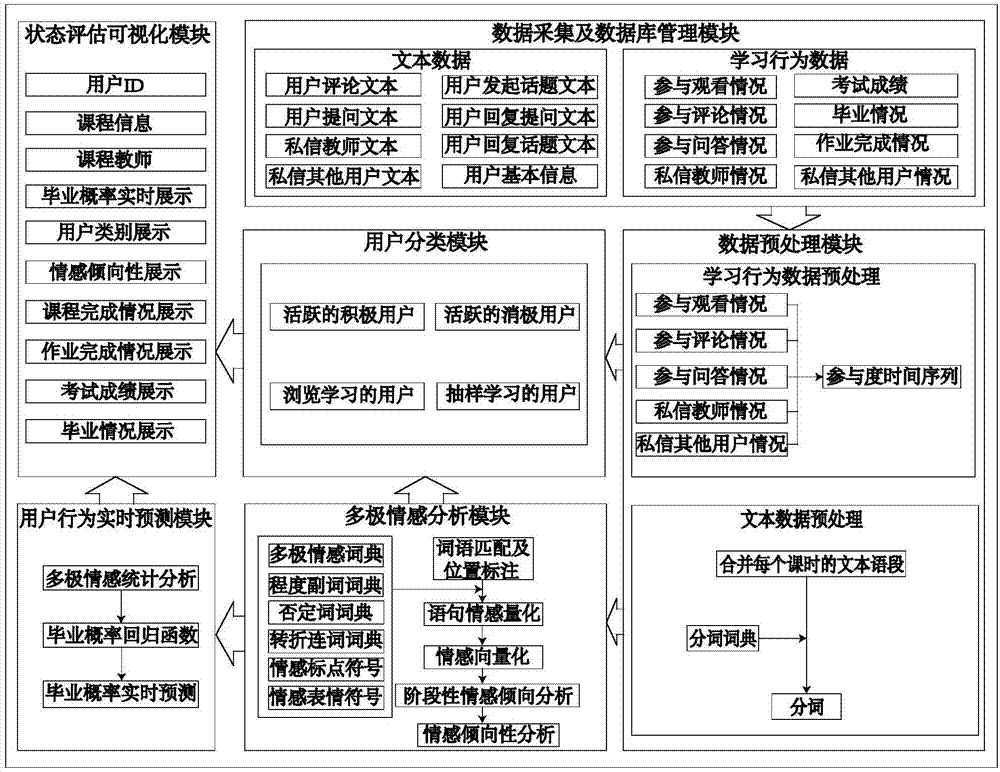
情感分析作为用户行为分析的重要组成部分,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。情感分析技术一方面可以通过对用户评论的筛选与归类,从中挖掘用户对产品或服务的意见,并基于这些意见对用户行为进行预测,从而制定科学合理的运营策略;另一方面,通过对大量文本进行情感分析,可以有效监控网络舆情,预测网络舆论走向,及时监测舆情危机并做出预警,从而维护网络安全,构建和谐网络环境。目前,基于情感分析的预测方法主要分为两类,一类是基于机器学习的回归预测方法,另一类是基于情感词典的统计学习预测方法。其中,基于机器学习的回归预测方法需要建立分类器模型,并通过大量文本数据完成分类器模型的训练,利用该分类器模型分析用户的情感特征,最终将用户的情感特征输入回归预测模型。而基于情感词典的统计学习预测方法将情感词作为判别情感倾向的依据,首先,需要匹配文本数据中的情感词,赋予不同词性的词语以相应的情感影响强度值;其次,结合情感表达规则对语句情感进行量化计算;最后,将情感量化值输入统计学习模型进行预测。上述基于情感分析的预测方法的局限性在于:主要分析两极化情感倾向(正面情绪与负面情绪),分析结果具有模糊性;情感词典后期扩展性差,无法匹配未收录的情感词,导致对语句情感分析的误判;未考虑转折性连词对语句情感极性的转移作用,影响情感量化结果准确性;统计学习预测模型只与前一时间点的情感特征关联。因此,使用现有的基于情感分析的预测方法难以达到理想的效果。技术实现要素:本发明的目的在于克服现有情感分析的预测方法中所存在的不足,提出一种结构合理,预测准确,效果佳的基于多极情感分析的用户行为预测系统,并提供科学合理,适用性强的方法。实现本发明的目的之一采用的技术方案是:一种基于多极情感分析的用户行为预测系统,其特征是,它包括:用于采集网络数据并进行分类管理,进而构建系统数据库的数据采集及数据库管理模块;基于分词词典将每个课时的文本语段进行分词处理,并将参与观看情况、参与评论情况、参与问答情况、私信教师情况和私信其他用户情况五项用户行为表示为时间序列,从而合并运算构建用户参与度时间序列的数据预处理模块;基于多种词性词典对分词处理后的语段进行词语匹配与位置标注,而后对语句情感进行量化处理,实现语句的情感量化,最终通过加权计算处理分析用户的阶段性情感倾向与情感倾向性的多极情感分析模块;通过分析网络学习用户的情感倾向性与用户行为将用户分为活跃的积极用户、活跃的消极用户、游览学习的用户和抽样学习的用户四类的用户分类模块;用于实时预测用户行为的用户行为实时预测模块;用于展示用户id、课程信息、课程教师、实时毕业概率、用户类别、情感倾向性、课程完成情况、考试成绩和毕业情况的状态评估可视化模块;所述的数据采集及数据库管理模块与数据预处理模块信号连接,所述的数据预处理模块分别与数据采集及数据库管理模块、用户分类模块、多极情感分析模块信号连接,所述的用户分类模块分别与数据预处理模块、状态评估可视化模块、多极情感分析模块信号连接,所述的多极情感分析模块分别与数据预处理模块、用户分类模块、用户行为实时预测模块信号连接,所述的用户行为实时预测模块分别与多极情感分析模块、状态评估可视化模块信号连接。所述的数据采集及数据库管理模块所采集的数据包括:文本数据与学习行为数据,其中文本数据包括:用户评论文本、用户发起话题文本、用户提问文本、用户回复话题文本、用户回复提问文本、私信教师文本、私信其他用户文本和用户基本信息;学习行为数据包括:参与观看情况、参与评论情况、参与问答情况、私信教师情况、考试成绩、毕业情况、作业完成情况和私信其他用户情况。所述的数据预处理模块的功能是,分别对文本数据与用户行为数据进行预处理,其中,需要经过数据的预处理学习行为数据包括:参与观看情况、参与评论情况、参与问答情况、私信教师情况和私信其他用户情况五项学习行为数据;首先,将所述的五项学习行为数据处理成包括时间属性与参与度属性的二维时间序列;其次,将所述的五项学习行为数据二维时间序列进行合并运算,得到参与度时间序列,文本数据预处理的功能在于,基于分词词典,以课时为时间节点,将每个时间节点的文本语段进行分词处理。所述的多极情感分析模块用于文本数据的情感量化处理,最终将文本数据表示为情感向量,首先,基于多种词性词典对分词处理后的语段进行词语匹配与位置标注;而后,对语句情感进行量化处理,实现语句的情感量化;最终,通过加权计算处理分析用户的阶段性情感倾向与情感倾向性,其中,用于词性分析的词典包括多极情感词典,程度副词词典,否定词词典,转折连词词典,情感标点符号和情感表情符号。所述的用户分类模块四种用户类型中,所述的活跃的积极用户为:课程学习参与度较高,而且情感倾向性表现为积极的用户;所述的活跃的消极用户为:课程学习参与度较高,而且情感倾向性表现为消极的用户;所述的游览学习的用户为:仅参与前期课程的学习,三节课时以后不再参与课程学习的用户;所述的抽样学习的用户为:不定时参与课程学习,旷课次数较多的用户。所述的用户行为预测模块的功能是实时预测用户的行为,主要通过分析用户的多极情感预测其毕业概率。所述的状态评估可视化模块的功能是,根据用户状态评估的可视化处理,展示相应的用户行为,包括:实时毕业概率、用户类别、情感倾向性、课程完成情况、考试成绩和毕业情况。实现本发明的目的之二采用的技术方案是:本发明的一种基于多极情感分析的用户行为预测方法,其特征是,它包括以下步骤:步骤1:针对网络教学网站,进入数据采集及数据库管理模块。利用网络爬虫采集网络教学网站数据,依据字段属性与数据结构,将网页数据保存到数据库中。步骤2:对所述网页数据进行数据预处理:(1)定义参与观看时间序列cvpts,cvpts是每个课时用户是否参与课程观看的时间序列,参与观看记为1,未参与观看记为0;(2)定义参与评论时间序列ccpts,ccpts是每个课时用户是否参与课程评论的时间序列,参与评论记为1,未参与评论记为0;(3)定义参与问答时间序列cqpts,cqpts是每个课时用户是否参与课程问答的时间序列,参与问答记为1,未参与问答记为0;(4)定义私信教师时间序列ctpts,ctpts是每个课时用户是否私信教师的时间序列,私信记为1,未私信记为0;(5)定义私信其他用户时间序列copts,copts是每个课时用户是否私信其他用户的时间序列,私信记为1,未私信记为0;(6)定义参与度时间序列acpts,判断在每个课时,用户是否参与课程观看,参与评论,参与问答,私信教师,私信其他用户五项用户行为中的任何一项行为活动,参与记为1,未参与记为0;(7)以课时为时间节点,合并每个时间节点的文本语段,文本语段包括:用户评论文本comment,用户发起话题文本topic-create,用户提问文本question-create,用户回复话题文本topic-reply,用户回复提问文本question-reply,私信教师文本to-teacher,私信其他用户文本to-other;(8)语段分词,利用分词词典对所述的各时间节点的合并文本语段,进行分词处理。步骤3:情感表达规则建立:(1)扩展多极情感词典:扩展现有多极情感词典:计算词语相似度similarity,在同义词词典中选择每个情感词词意相似度最高的五个词语,并添加到现有情感词典中;(2)定义多极情感词典影响强度w;(3)定义程度副词影响强度ε;(4)定义情感标点符号影响强度ω;(5)定义情感表情符号影响强度δ;(6)定义否定词影响强度μ;(7)定义转折连词对前向与后向子句的影响强度σ;步骤4:语句情感量化:(1)定义语段s,并对语段s进行分句处理;(2)定义语句si,si是语段s中的第i个语句;(3)定义语句的多极情感量化值p(si),采用公式得到语句的情感量化值,其中n*是语句si中情感词的总数,wj是语句si中第j个情感词的影响强度,m是修饰情感词wj的程度副词总数,εk是语句si中第k个程度副词的影响强度,ω是情感标点符号的影响强度,δ是情感表情符号的影响强度,μ是否定词的影响强度,σ是转折连词对前向与后向子句的影响强度;步骤5:语段情感向量化:(1)定义课时节点t;(2)定义语段情感向量vt,采用公式得到语段情感向量,n是语段s中语句的总数;步骤6:阶段性情感倾向分析:(1)定义阶段性单极情感量化值pst,其中,t是课时节点;(2)定义阶段性情感倾向maxpst,采用统计分析法计算每一课时t的情感量化值最高的单极情感量化值,得到阶段性情感倾向maxpst;步骤7:情感倾向性分析:(1)定义情感倾向性et,采用公式得到用户情感倾向性,其中,n’是课时的总数;(2)定义积极情感倾向性,积极情感倾向性包含:快乐,惊讶,傲慢,爱慕;(3)定义消极情感倾向性,消极情感倾向性包含:悲伤,愤怒,失望,傲慢,恐惧;步骤8:用户分类:(1)定义活跃的积极用户,判断参与度时间序列是否具有较高的完整度,并具有积极情感倾向性;(2)定义活跃的消极用户,判断参与度时间序列是否具有较高的完整度,并具有消极情感倾向性;(3)定义浏览学习的用户,通过公式判断用户是否属于浏览学习的用户;(4)定义抽样学习的用户,定义参与度时间序列acpts的旷课次数rv,通过公式判断用户是否属于抽样学习的用户;步骤9:学习行为实时预测:(1)实时统计用户每个课时的阶段性情感倾向maxpst;(2)实时计算每个课时的阶段性积极情感与消极情感比率r;(3)将每位用户的阶段性积极情感与消极情感比率r及相应的毕业情况输入毕业概率回归函数f(x)=p1×r3+p2×r2+p3×r+p4,其中,p1,p2,p3,p4是回归函数的回归系数,f(x)是预测的毕业概率;(4)将未处理用户的阶段性积极情感与消极情感比率r输入毕业概率回归函数f(x)实时预测毕业概率;步骤10:在状态评估可视化模块显示用户的行为与状态,包括:预测毕业概率,用户类别,情感倾向性,课程完成情况,考试成绩,毕业情况。本发明的基于多极情感分析的用户行为预测系统及其方法具有如下优点:(1)本发明的基于多极情感分析的用户行为预测系统,主要应用于分析用户的行为特征并总结规律,预测用户未来的行为;(2)本发明全面考虑了情感词典的适用性,提高了情感词典后期扩展能力,构建完备的多极情感词典,降低分析结果的模糊性,从而为准确预测用户的行为提供保障;(3)本发明的系统中,依据情感表达特点,建立了情感表达规则,从而提高情感量化准确性,从课程全周期的情感趋势分析用户情感倾向性,降低阶段性极端情绪对用户实际情感倾向性判别的影响;(4)其方法科学合理,适用性强。附图说明图1为本发明的一种基于多极情感分析的用户行为预测系统结构框图;图2为本发明的一种基于多极情感分析的用户行为预测系统流程图。具体实施方式为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图通过具体实施例对本发明进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。在本发明的一个实施例中,提供了一种基于多极情感分析的用户行为预测系统,用来预测至少未来某一时间点的用户行为,而时间范围可以为至少两个课时的时间节点。如图1所示,本发明的一种基于多极情感分析的用户行为预测系统,用于采集网络数据并进行分类管理,进而构建系统数据库的数据采集及数据库管理模块;基于分词词典将每个课时的文本语段进行分词处理,并将参与观看情况、参与评论情况、参与问答情况、私信教师情况和私信其他用户情况五项用户行为表示为时间序列,从而合并运算构建用户参与度时间序列的数据预处理模块;基于多种词性词典对分词处理后的语段进行词语匹配与位置标注,而后对语句情感进行量化处理,实现语句的情感量化,最终通过加权计算处理分析用户的阶段性情感倾向与情感倾向性的多极情感分析模块;通过分析网络学习用户的情感倾向性与用户行为将用户分为活跃的积极用户、活跃的消极用户、游览学习的用户和抽样学习的用户四类的用户分类模块;用于实时预测用户行为的用户行为实时预测模块;用于展示用户id、课程信息、课程教师、实时毕业概率、用户类别、情感倾向性、课程完成情况、考试成绩和毕业情况的状态评估可视化模块;所述的数据采集及数据库管理模块与数据预处理模块信号连接,所述的数据预处理模块分别与数据采集及数据库管理模块、用户分类模块、多极情感分析模块信号连接,所述的用户分类模块分别与数据预处理模块、状态评估可视化模块、多极情感分析模块信号连接,所述的多极情感分析模块分别与数据预处理模块、用户分类模块、用户行为实时预测模块信号连接,所述的用户行为实时预测模块分别与多极情感分析模块、状态评估可视化模块信号连接。所述的数据采集及数据库管理模块所采集的数据包括:文本数据与学习行为数据,其中文本数据包括:用户评论文本、用户发起话题文本、用户提问文本、用户回复话题文本、用户回复提问文本、私信教师文本、私信其他用户文本和用户基本信息;学习行为数据包括:参与观看情况、参与评论情况、参与问答情况、私信教师情况、考试成绩、毕业情况、作业完成情况和私信其他用户情况。所述的数据预处理模块的功能是,分别对文本数据与用户行为数据进行预处理,其中,需要经过数据的预处理学习行为数据包括:参与观看情况、参与评论情况、参与问答情况、私信教师情况和私信其他用户情况五项学习行为数据;首先,将所述的五项学习行为数据处理成包括时间属性与参与度属性的二维时间序列;其次,将所述的五项学习行为数据二维时间序列进行合并运算,得到参与度时间序列,文本数据预处理的功能在于,基于分词词典以课时为时间节点,将每个时间节点的文本语段进行分词处理。所述的多极情感分析模块用于文本数据的情感量化处理,最终将文本数据表示为情感向量,首先,基于多种词性词典对分词处理后的语段进行词语匹配与位置标注;而后,对语句情感进行量化处理,实现语句的情感量化;最终,通过加权计算处理分析用户的阶段性情感倾向与情感倾向性,其中,用于词性分析的词典包括多极情感词典,程度副词词典,否定词词典,转折连词词典,情感标点符号和情感表情符号。所述的用户分类模块四种用户类型中,所述的活跃的积极用户为:课程学习参与度较高,而且情感倾向性表现为积极的用户;所述的活跃的消极用户为:课程学习参与度较高,而且情感倾向性表现为消极的用户;所述的游览学习的用户为:仅参与前期课程的学习,三节课时以后不再参与课程学习的用户;所述的抽样学习的用户为:不定时参与课程学习,旷课次数较多的用户。所述的用户行为预测模块的功能是实时预测用户的行为,主要通过分析用户的多极情感预测其毕业概率。所述的状态评估可视化模块的功能是,根据状态评估可视化处理,展示相应的用户行为,包括:实时毕业概率、用户类别、情感倾向性、课程完成情况、考试成绩和毕业情况。本实施例中,所述的数据采集及数据库管理模块由爬虫框架与数据库所组成,所采集的数据包括:文本数据text与学习行为数据behavior,其中文本数据包括:用户评论文本comment,用户发起话题文本topic-create,用户提问文本question-create,用户回复话题文本topic-reply,用户回复提问文本question-reply,私信教师文本to-teacher,私信其他用户文本to-other,用户基本信息info。学习行为数据包括:参与观看情况v,参与评论情况c,参与问答情况q,私信教师情况t,考试成绩e,毕业情况g,作业完成情况h,私信其他用户情况o;所述的数据预处理模块的功能是,分别对文本数据与用户行为数据进行预处理,其中,需要经过数据的预处理学习行为数据包括:参与观看情况v,参与评论情况c,参与问答情况q,私信教师情况t,私信其他用户情况o。首先,将五种学习行为数据处理成含有参与度属性与时间属性的二维时间序列,分别为:观看时间序列cvpts,参与评论时间序列ccpts,参与问答时间序列cqpts,私信教师时间序列ctpts,私信其他用户时间序列copts。其中,文本数据预处理的功能在于,基于分词词典将每个课时的文本语段进行分词处理,得到已分词语段。属性列表一:用户评论文本comment参与观看情况v用户发起话题文本topic-create参与评论情况c用户提问文本question-create参与问答情况q用户回复话题文本topic-reply私信教师情况t用户回复提问文本question-reply考试成绩e私信教师文本to-teacher毕业情况g私信其他用户文本to-other作业完成情况h用户基本信息info私信其他用户情况o所述的多极情感分析模块的用于文本数据的情感量化处理,最终将文本数据表示为情感向量vt。首先,基于多种词性词典对分词处理后的语段进行词语匹配与位置标注;而后,对语句情感进行量化处理,实现语句的情感向量表示vt;最终,通过加权计算处理分析用户的阶段性情感倾向与情感倾向性et。其中,用于词性分析的词典包括多极情感词典、程度副词词典、否定词词典、转折连词词典、情感标点符号和情感表情符号;所述的用户分类模块,依据用户行为与情感特征将用户分为四种类型,包括:(1)活跃的积极用户:课程学习参与度较高,而且情感倾向性表现为积极的用户;(2)活跃的消极用户:课程学习参与度较高,而且情感倾向性表现为消极的用户;(3)游览学习的用户:仅参与前期课程的学习,三节课时以后不再跟随课程学习的用户;(4)抽样学习的用户:不定时参与课程学习,旷课次数较多的用户;所述的用户行为预测模块主要用于实时预测用户的行为;所述的状态评估可视化模块的功能是,根据状态评估可视化处理,用户可以查询相应的用户行为,包括:实时毕业概率gp,用户类别category,情感倾向性et,课程完成情况comp,考试成绩e,毕业情况g。在本实施例中,提供了的具体步骤为:步骤1:针对网络教学网站,进入数据采集及数据库管理模块。利用网络爬虫采集网络教学网站数据,依据字段属性与数据结构,将网页数据保存到数据库中。步骤2:对所述网页数据进行数据预处理:(1)定义参与观看时间序列cvpts,cvpts是每个课时用户是否参与课程观看的时间序列,参与观看记为1,未参与观看记为0;(2)定义参与评论时间序列ccpts,ccpts是每个课时用户是否参与课程评论的时间序列,参与评论记为1,未参与评论记为0;(3)定义参与问答时间序列cqpts,cqpts是每个课时用户是否参与课程问答的时间序列,参与问答记为1,未参与问答记为0;(4)定义私信教师时间序列ctpts,ctpts是每个课时用户是否私信教师的时间序列,私信记为1,未私信记为0;(5)定义私信其他用户时间序列copts,copts是每个课时用户是否私信其他用户的时间序列,私信记为1,未私信记为0;(6)定义参与度时间序列acpts,判断在每个课时,用户是否参与课程观看,参与评论,参与问答,私信教师,私信其他用户五项用户行为中的任何一项行为活动,参与记为1,未参与记为0;(7)以课时为时间节点,合并每个时间节点的文本语段,文本语段包括:用户评论文本comment,用户发起话题文本topic-create,用户提问文本question-create,用户回复话题文本topic-reply,用户回复提问文本question-reply,私信教师文本to-teacher,私信其他用户文本to-other;(8)语段分词,利用分词词典对所述的各时间节点的合并文本语段,进行分词处理。步骤3:情感表达规则建立:(1)扩展多极情感词典:计算词语相似度similarity,在同义词词典中选择对每个情感词词意相似度最高的五个词语,并添加到情感词典中;(2)定义多极情感词典影响强度w,w的影响强度从大到小设置在0至1区间内;(3)定义程度副词影响强度ε,ε的影响强度从大到小设置在0至2区间内;(4)定义情感标点符号影响强度ω,ω的影响强度从大到小设置在0至0.5区间内;(5)定义情感表情符号影响强度δ,δ的影响强度从大到小设置在0至0.5区间内;(6)定义否定词影响强度μ,μ的影响强度设置为-1;(7)定义转折连词对前向与后向子句的影响强度σ,σ设置情感重心所在语句的权值为1.5;步骤4:语句情感量化:(1)定义语段s,并对语段s进行分句处理;(2)定义语句si,si是语段s中的第i个语句(3)定义语句的多极情感量化值p(si),采用公式得到语句的情感量化值,其中n*是语句si中情感词的总数,wj是语句si中第j个情感词的影响强度,m是修饰情感词wj的程度副词总数,εk是语句si中第k个程度副词的影响强度,ω是情感标点符号的影响强度,δ是情感表情符号的影响强度,μ是否定词的影响强度,σ是转折连词对前向与后向子句的影响强度;步骤5:语段情感向量化:(1)定义课时节点t;(2)定义语段情感向量vt,采用公式得到语段情感向量vt,n是语段s中语句的总数;步骤6:阶段性情感倾向分析:(1)定义阶段性单极情感量化值pst,其中,t是课时节点;(2)定义阶段性情感倾向maxpst,采用统计分析法计算每一课时t的情感量化值最高的单极情感量化值,得到阶段性情感倾向maxpst;步骤7:情感倾向性分析:(1)定义情感倾向性et,采用公式得到用户情感倾向性,其中,n’是课时的总数;(2)定义积极情感倾向性,积极情感倾向性包含:快乐,惊讶,傲慢,爱慕;(3)定义消极情感倾向性,消极情感倾向性包含:悲伤,愤怒,失望,傲慢,恐惧;步骤8:用户分类:(1)定义活跃的积极用户,判断参与度时间序列是否具有较高的完整度,并判断用户是否具有积极情感倾向性,包括:快乐,惊讶,傲慢,爱慕;(2)定义活跃的消极用户,判断参与度时间序列是否具有较高的完整度,并判断用户是否具有消极情感倾向性,包括:悲伤,愤怒,失望,傲慢,恐惧;(3)定义浏览学习的用户,通过公式判断用户是否属于浏览学习的用户;(4)定义抽样学习的用户,定义参与度时间序列acpts的旷课次数rv,通过公式判断用户是否属于抽样学习的用户。步骤9:学习行为实时预测:(1)实时统计用户每个课时的阶段性情感倾向maxpst;(2)实时计算每个课时的阶段性积极情感与消极情感比率r;(3)将每位用户的阶段性积极情感与消极情感比率r及相应的毕业情况输入毕业概率回归函数f(x)=p1×r3+p2×r2+p3×r+p4,其中,p1,p2,p3,p4是回归函数的回归系数,f(x)是预测的毕业概率;(4)将未处理用户的阶段性积极情感与消极情感比率r输入毕业概率回归函数f(x)实时预测毕业概率;步骤10:在状态评估可视化模块显示用户的行为与状态,包括:实时毕业概率gp,用户类别category,情感倾向性et,课程完成情况comp,考试成绩e,毕业情况g。本发明所涉及的软件程序,依据互联网和自然语言处理技术编制,是本领域人员所熟悉的技术。显然,上述实施例仅仅是为了清楚地说明所作的举例,而并非对实施方式的限定。对于所述领域的普通技术人员来说,在上述说明的基础上还可以做出其他不同形式的变化或变动。这里无需也无法对所有实施方式予以穷举。而由此引申出的显而易见的变化或变动都应涵盖在本发明的保护范围之内,因此,本发明的保护范围都应以权利要求的保护范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1