一种面向裁判文书的文本信息抽取方法与流程
本发明涉及一种针对中文裁判文书的文本信息抽取技术,具体涉及一种面向裁判文书的文本信息抽取方法,属于自然语言处理技术领域。
背景技术
裁判文书是法官在案件审理终结后,依据案件事实和法律条款,对案件实体和程序问题所做出的具有法律约束力的书面结论。裁判文书忠实地记录了案件的裁判过程,因此包含了大量的有价值信息。对裁判文书的分析与研究对司法审判活动具有重要意义。但是,在法院实际工作中,裁判文书是由法官使用自然语言书写的文档,如果不做任何预处理,将难以高效地利用裁判文书中的信息。我国多地法院均已建立了法院裁判文书网上公开系统,但尚未开展对裁判文书的解析工作。因此,采用信息化的方式,对裁判文书进行信息抽取,将其转化为计算机可以理解的结构化数据,对于解决这个问题具有非常重要的意义。
针对中文裁判文书的结构化处理主要是以裁判文书书写规律与文书结构为基础,结合法律标准和法院实际业务需求,确定文书结构划分以及需要提取的信息项,设计文书信息项模型,研究法律领域自然语言处理技术,构建文书信息项模型,并将模型转化为xml结构化文档输出。
中文裁判文书具有规范的书写格式与文书结构,本专利利用裁判文书的这一特点设计并构造了文书分段模型,将裁判文书划分为七个逻辑段,以便于有针对性地对裁判文书进行结构化处理。不同案件类型的裁判文书在文书结构上是相同的,都可以分为“文首”、“当事人”、“诉讼记录”、“案件基本情况”、“裁判分析过程”、“判决结果”和“文尾”共7个逻辑段,但是不同案件类型的逻辑段落中所包含的信息项是不同的。针对这个问题,本专利为各类案件设计了对应的文书信息项模型,并构建了对应的文书解析器,分别对各类案件进行结构化处理。需要抽取的文书信息项类型有多种,无法使用统一的方法进行抽取,针对这个问题,本专利提出了多种抽取方法以满足各类信息项的抽取需求。为使文书结构化有效地应用于法律业务中,采用xml文档作为文书结构化的输出载体。xml技术已经非常成熟稳定,是一种可以让用户自己定义标记的语言。主要用于在网页上组织信息,同时也用来确保网络交互合作时,具有良好的可靠性和互操作性。本专利中选择使用xml输出结构化数据,使得xml文件的结构可以复杂到任意程度。xml内容与应用分开,具有良好的复用性,数据可以被不同的应用程序加以利用。由于法院业务需求,需要在不同部门、不同程序之间传递裁判文书信息,使用xml作为文书存储结构保证了结构化文书的普遍适用性,使法律文书中的信息可以按照法院业务需求在各种场景下适用。
技术实现要素:
本发明是一种面向裁判文书的文本信息抽取方法,主要针对民事一审、民事二审、刑事一审、刑事二审、行政一审、行政二审共六类案件的裁判文书,根据裁判文书的书写规律和文书结构,设计了一种文书分段模型和一种文书信息项模型,提出了一种构造文书分段模型的方法和一种构造文书信息项模型的方法。最终实现结构化中文裁判文书,输出xml结构化文档,使得中文裁判文书能够更有效地应用于针对中文裁判文书的研究中,并在裁判文书质量评查、裁判文书可视化、审判系统信息校对等领域中发挥作用。
本发明所属的一种面向裁判文书的文本信息抽取方法,包括以下步骤:
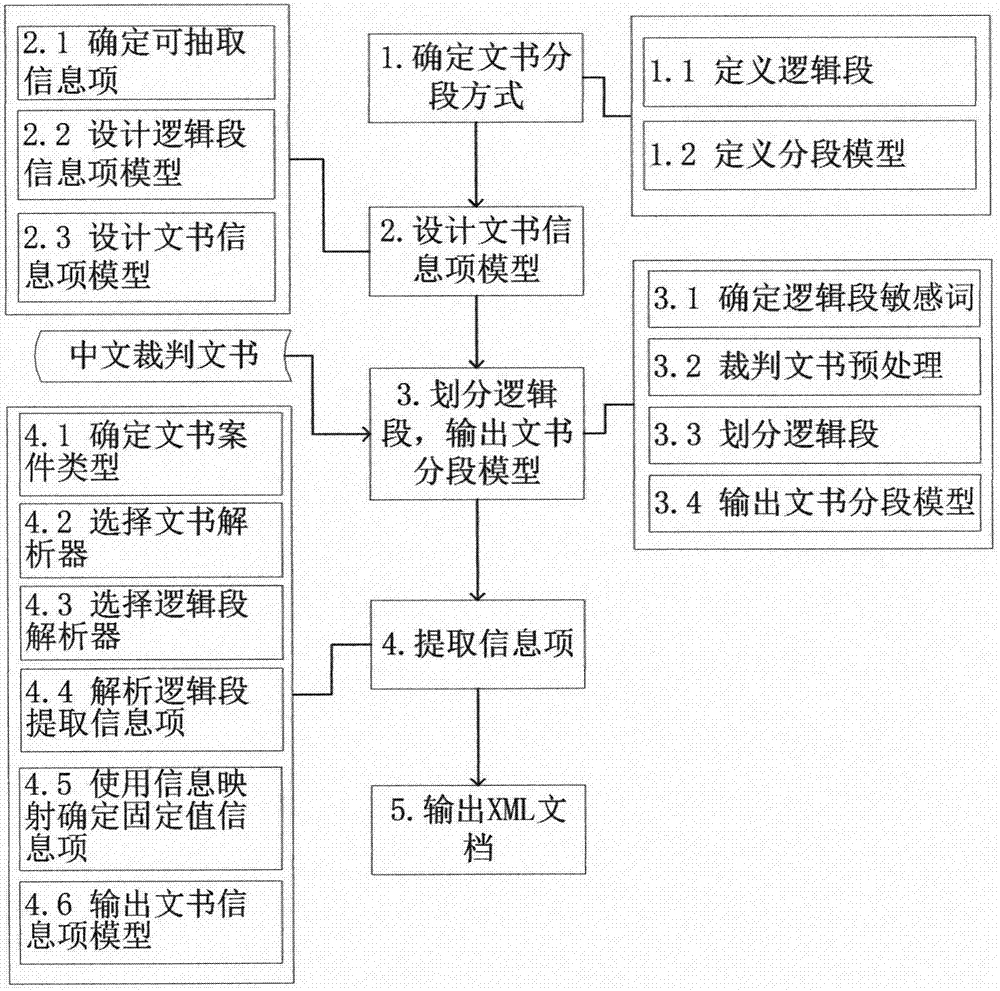
步骤(1)根据中文裁判文书的书写规律与文书结构,将文书划分为七个逻辑段,设计文书分段模型存储逻辑段;
步骤(2)分析各逻辑段的内容,结合法律标准和法院业务需求,确定每个逻辑段包含的信息项,设计文书信息项模型;
步骤(3)以中文裁判文书为输入,以逻辑段的特征为依据,划分逻辑段,输出文书分段模型;
步骤(4)以文书分段模型为输入,以信息项特征为依据,提取信息项内容,构建文书信息项模型;
步骤(5)将文书信息项模型转化为xml结构化文档。
具体而言,步骤(1)根据中文裁判文书的书写规律与文书结构,将文书划分为七个逻辑段,设计文书分段模型存储逻辑段,具体包括以下步骤:
步骤(1.1)总结中文裁判文书书写规律和文书结构,将文书各段落按照逻辑关系划分为七个逻辑段落,包括“文首”、“当事人”、“诉讼记录”、“案件基本情况”、“裁判分析过程”、“判决结果”和“文尾”;
步骤(1.2)设计文书分段模型用以存储文书各逻辑段,每个逻辑段包含若干个自然段。
步骤(2)中分析各逻辑段的内容,结合法律标准和法院业务需求,确定每个逻辑段包含的信息项,设计文书信息项模型,具体包括以下步骤:
步骤(2.1)分别针对民事一审、民事二审、刑事一审、刑事二审、行政一审、行政二审共六种案件类型,结合法律标准和法院业务需求,分析该案件类型的裁判文书,确定各逻辑段中可以提取的信息项;
步骤(2.2)分别针对(2.1)中的六种案件类型,结合文书分段模型,按照信息项之间的层级关系,为各逻辑段设计逻辑段信息项模型,存储信息项信息;
步骤(2.3)将逻辑段信息项模型组织为文书信息项模型,包含了裁判文书全文的所有信息。共设计民事一审、民事二审、刑事一审、刑事二审、行政一审、行政二审六类文书信息项模型。
步骤(3)以中文裁判文书为输入,逻辑段特征为依据,输出文书分段模型,具体包括以下步骤:
步骤(3.1)针对各逻辑段,确定可以标志该逻辑段落的敏感词,为各逻辑段构建敏感词库。
步骤(3.2)对中文裁判文书内容进行预处理,清除干扰项,包括:换行符、全半角空格、空白行、提前换行;
步骤(3.3)按照从头至尾的顺序,以自然段为单位,扫描预处理后的文书内容。每扫描一个自然段,根据逻辑段的敏感词库,以及敏感词出现位置,判断该自然段所属的逻辑段,将该自然段加入文书分段模型的所属逻辑段内;
步骤(3.4)扫描结束后,完成了全文逻辑段划分,输出文书分段模型。
步骤(4)根据权利要求1所述的一种面向裁判文书的文本信息抽取方法,其特征在于步骤(4)以文书分段模型为输入,信息项特征为依据,提取信息项内容,构建文书信息项模型,具体包括以下步骤:
步骤(4.1)以文书分段模型为输入,使用正则表达式从“文首”逻辑段内提取出案件性质、审判程序,根据案件性质、审判程序确定该文书所属的案件类型;
步骤(4.2)根据案件类型,将文书分段模型发送给该案件类型的文书解析器;
步骤(4.3)针对每种案件类型,文书解析器由该案件类型的逻辑段解析器组成,包括文首解析器、当事人解析器、诉讼记录解析器、案件基本情况解析器、裁判分析过程解析器、判决结果解析器和文尾解析器。
步骤(4.4)各逻辑段解析器从文书分段模型中获取对应逻辑段,使用正则表达式、分析工具、语义分析的方法,抽取原文内容作为信息项取值,逐个提取逻辑段内的信息项,构造逻辑段信息项模型;
步骤(4.5)对于法律标准中有明确定义,但原文中只给出描述,没有直接给出取值的信息项,需要对其进行特征映射,根据原文描述确定该信息项取值。进行特征映射,需要根据该信息项的所有固定取值,建立对应的敏感词特征库,敏感词特征包含若干敏感词以及敏感词之间的顺序关系。根据信息项的原文描述,逐个判断原文描述是否满足固定取值的敏感词特征,当满足敏感词特征时,将对应的固定取值赋予该信息项;
步骤(4.6)文书解析器将各逻辑段解析器构造的逻辑段信息项模型组织为文书信息项模型。
步骤(5)将文书信息项模型转化为xml结构化文档。
本发明与现有技术相比,其显著优点是:严格按照法律标准,深度结合法院实际业务需求,设计文书信息项模型,各类信息项均能够直接对应法院实际业务中产生的法律数据,可直接应用于法院审判业务;最大限度地提取裁判文书信息,文书信息模型基本可以覆盖文书中包含所有的法律信息;采用分而治之的策略,以逻辑段为单位解析并提取信息项,只需关注各逻辑段的处理,降低了解析的复杂度,有效提高提取正确率;使用xml结构化文档作为输出形式,具有良好的复用性,数据可以被不同的应用程序加以利用,保证了结构化文书的普遍适用性,使裁判文书中的信息可以按照法院业务需求在各种场景下适用。
附图说明
图1结构化中文裁判文书流程
图2文书模型的代码实现
图3民事一审案件结案文书的判决结果段
图4民事一审判决结果段的信息项模型
图5xml文档中七个主要逻辑段节点
图6民事一审裁判结果逻辑段对应xml结构
具体实施方式
为更加清晰地阐明本发明的目的、技术方案和优点,下面将结合附图及具体实施例子对本发明进行详细描述。
本发明的目的在于针对中文裁判文书,提出一种自动化方法将裁判文书结构化,且保证结构化的裁判文书可普遍适用于各类法律业务需求与裁判文书研究。该方法以中文裁判文书的书写规律和文书结构为基础,首先对裁判文书进行分段处理,将文书划分为七个逻辑段,构建文书分段模型。再以文书分段模型为输入,根据案件类型选择对应文书解析器,分别对不同逻辑段进行解析,使用正则表达式、分词工具、语义分析、敏感特征匹配的方法抽取信息项,构造文书信息项模型,最终输出xml结构化文档。发明概括来说主要包括以下步骤:
步骤(1)根据中文裁判文书的书写规律与文书结构,将文书划分为七个逻辑段,设计文书分段模型存储逻辑段;
步骤(2)分析各逻辑段的内容,结合法律标准和法院业务需求,确定每个逻辑段包含的信息项,设计文书信息项模型;
步骤(3)以中文裁判文书为输入,以逻辑段的特征为依据,划分逻辑段,输出文书分段模型;
步骤(4)以文书分段模型为输入,以信息项特征为依据,提取信息项内容,构建文书信息项模型;
步骤(5)将文书信息项模型转化为xml结构化文档。
上述一种面向裁判文书的文本信息抽取方法的详细工作流程如图1所示。这里以一篇民事一审交通事故案件的结案文书作为例子,对上述步骤分别进行实例描述。
1.裁判文书通常是用doc或rtf格式进行存储,且文书分段清晰,书写规范,具有明显的文书结构。通过大量阅读裁判文书并总结其书写规律,本专利提出一种粗粒度结构化中文裁判文书的方法,将文书划分为七个逻辑段落,并设计出文书分段模型,用以存储各个的逻辑段落。具体步骤如下:
步骤(1.1)总结中文裁判文书书写规律和文书结构,将文书各段落按照逻辑关系划分为七个逻辑段落,包括“文首”、“当事人”、“诉讼记录”、“案件基本情况”、“裁判分析过程”、“判决结果”和“文尾”。
“文首”包括文书制作单位、文书类型、案号,该段落的特征是没有标点符号;
“当事人”段包含多个自然段,每个自然段描述一位当事人,每个自然段以该当事人的诉讼地位开头;
“诉讼记录”段简要总结了案件的诉讼过程,描述当事人、案由、案件审理过程以及案件审结情况;
“案件基本情况”段主要描述案情事实;
“裁判分析过程”段对案件事实进行分析论证,结合法律法条陈述判决理由;
“判决结果”段是对案件判决结果的陈述。本段的特征是承接上一段落,即裁判分析过程以固定的特征敏感词结尾,表明开始陈述判决结果;
“文尾”段列举了参与案件的审判人员,以及判决日期。该段落在文章中表现为落款。
步骤(1.2)设计文书分段模型用以存储文书各逻辑段,每个逻辑段包含若干个自然段。根据每个段落所包含的自然段数量,设计文书分段模型,如图2所示,每个自然段用字符串类型存储,由若干自然段组成的逻辑段用字符串数组存储,对于只有一个自然段的逻辑段使用字符串存储,如“诉讼记录段”。
2.结合法律和法院业务需求,以逻辑段为单位,确定每个逻辑段所包含的信息项。本专利提取了民事一审、民事二审、刑事一审、刑事二审、行政一审、行政二审六类案件共597个信息项。这里以民事一审交通事故案件的判决结果段为例说明本步骤,判决结果段内容如图3所示,具体步骤包括:
步骤(2.1)结合逻辑段的内容与法院业务需求,确定可以在逻辑段中抽取的所有信息项;
步骤(2.2)信息项具有一定的组织关系和层级结构,按照信息项的层级结构,构造逻辑段信息项模型,如图4,表示民事一审判决段的信息项模型;
步骤(2.3)按照步骤(2.2)对所有逻辑段设计信息项模型,各逻辑段的信息项模型组织为文书信息项模型。
步骤(2.4)对民事一审、民事二审、刑事一审、刑事二审、行政一审、行政二审共六类案件,分别进行(2.1)、(2.2)、(2.3)步骤,每个案件类型都有一个相应的文书信息项模型。
3.以中文裁判文书为输入,以逻辑段特征为依据,将裁判文书划分为七个逻辑段,输出文书分段模型。具体步骤包括:
步骤(3.1)分析各逻辑段可以用于区分其他逻辑段的特征,并根据其特征确定具体分段方法。
“文首”:由于文首内容固定,直接使用正则表达式匹配,匹配该正则表达式的自然段属于当前逻辑段;
“诉讼参与人”:使用非诉讼参与人判断方法,即不包含当事人诉讼地位敏感词,或者出现案情相关敏感词,例如“案情”、“纠纷”、“本院认定”、“诉称”等,则认为该自然段是非诉讼参与人段。若当前自然段是非诉讼参与人段落,立即停止诉讼参与人逻辑段分段;若当前自然段是诉讼参与人段,则进行对下一自然段的判断,直到出现非诉讼参与人自然段;
“诉讼记录”:由于诉讼记录段落只有一段,因此直接选择诉讼参与人之后的一个自然段;
“案件基本情况”:案件基本情况段没有明显特征,需要通过下一个逻辑段落,即裁判分析过程段进行分析,找到案件基本情况与裁判分析过程的临界点,诉讼记录段之后、临界点之前的自然段属于案件基本情况段;
“诉讼记录”:以诉讼记录段头部特征敏感词作为段落语句开头的自然段,是与案件基本情况段落的临界点,以诉讼记录段结尾特征敏感词作为该逻辑段结束标志;
“判决结果”:以诉讼记录段的结束标志为开始,当出现文尾特征敏感词时,即结束,进入到下一逻辑段;
“文尾段”:使用文尾特征敏感词判断是否是文尾段落。
步骤(3.2)根据步骤(3.1)中的各逻辑段特征以及分段方法,按照逻辑段的先后顺序,以自然段为单位,从头至尾依次判断该自然段所属的当前逻辑段,若该自然段属于当前逻辑段的下一逻辑段,将当前逻辑段指向下一逻辑段,将该自然段加入文书分段模型中所属逻辑段中。
4.以文书分段模型为输入,信息项特征为依据,提取信息项内容,构建文书信息项模型,具体步骤如下:
步骤(4.1)文书分段模型中包含“文首”逻辑段,这一逻辑段说明了办案法院、案号、裁判文书类型,其中根据案号可以得知案件性质、案件审判程序。首先以“文首”逻辑段为输入,文首解析器构建出文首信息项模型,根据文首信息项模型中的案件性质、案件审判程序两项确定案件类型;
步骤(4.2)获得案件类型后,解析控制器将文书分段模型发送给对应案件类型的文书解析器;
步骤(4.3)文书解析器由该案件类型的逻辑段解析器组成,包括文首解析器、当事人解析器、诉讼记录解析器、案件基本情况解析器、裁判分析过程解析器、判决结果解析器和文尾解析器。每个逻辑段的文书解析器从文书分段模型中获取对应逻辑段内容,解析器负责从对应逻辑段中抽取信息项,构建逻辑段信息项模型;
(4.4)不同种类的信息项需要采用不同的抽取方法,本专利根据每种信息项的特点提出了对应的抽取方法:
步骤(4.4.1)子段落。每个逻辑段下的语句是按照逻辑关系组织的,按照文书的语言逻辑将逻辑段拆分为若干子段落。针对这种信息项,本专利提出了一种抽取方法:确定逻辑段落所包含的子段落信息项,每个子段落的特征关键词,按照语句是否包含子段落特征关键词,确定该语句所属子段落。
步骤(4.4.2)取值固定,但原文中没有直接写出的信息项。针对这种信息项,本专利提出了一种抽取方法:进行特征映射,需要根据该信息项的所有固定取值,建立对应的敏感词特征库,敏感词特征包含若干敏感词以及敏感词之间的顺序关系。根据信息项的原文描述,逐个判断原文描述是否满足固定取值的敏感词特征,当满足敏感词特征时,将对应的固定取值赋予该信息项;
步骤(4.4.3)取值固定,且可以从原文中直接提取的信息项。针对此类信息项,本专利提出了一种抽取方法,在原文中进行匹配取值来提取这种信息项。
步骤(4.4.4)取值不固定,可以从原文中直接提取的信息项。例如,诉讼金额、法律依据等等。这类信息项占所有信息项的比例最大,且种类较多,因此必须针对每个信息项具体分析。本专利提出了几种抽取方法:正则表达式匹配,例如金额、日期类的细腻项;分词器分词,使用anjs中文分词器对原文进行分词并对每个词标注词性,结合语意分析与信息项类型,得到信息项取值。例如,文尾逻辑段中,获取审判人员姓名可以在对文尾分词后将词性为人名的词赋值给审判人员姓名信息项;
步骤(4.5)各逻辑段完成各自对应逻辑段信息项模型构建后,文书解析器将各逻辑段信息项模型组装成文书信息项模型,将文书信息项模型转发给xml文档构造器。
5.将文书信息项模型转化为xml结构化文档。由于文书信息项模型以数据结构的方式存储在系统中,不便于阅读、存储,而且文书信息项模型作为其他关于裁判文书的基础信息来源,必须满足普遍适用性,因此,需要将文书信息项模型存储为易于阅读、理解、传输的格式,本发明中采用xml文档格式,将文书信息项模型转化为xml结构化文档。
步骤(5.1)本发明设计了一种xml节点规范,用以表示文书信息项模型。每个信息项对应一个xml节点,节点名称为信息项中文拼音首字母大写,节点属性“namecn”取值为信息项中文名称,节点属性“value”取值为信息项内容;
步骤(5.2)按照信息项模型的层级结构创建xml结构化文档,首先创建逻辑段节点,逻辑段节点的父节点为全文节点,如图5所示,全文节点下有七个子节点,分别对应七个逻辑段;
步骤(5.3)依次创建逻辑节点的子节点,如图6所示,以判决结果为父节点,按照本发明提出的xml节点规范创建其子节点;
步骤(5.4)当步骤(5.3)中新创建的子节点所对应的信息项有下级信息项时,需要继续以该信息项节点为父节点,创建下级信息项所对应的子节点。
步骤(5.5)重复步骤(5.4),直到为所有的信息项创建了xml节点,即完成了该逻辑段的xml文档创建,当所有逻辑段都完成对应xml文档创建时,就标志文书信息项模型已转化为xml结构化文档。
上面已经参考附图对根据本发明实施的一种面向裁判文书的文本信息抽取方法进行了详细描述。本发明具有如下优点:严格按照法律标准,深度并紧密结合法院实际业务需求,设计文书信息项模型,各类信息项均能够直接对应法院实际业务中产生的法律数据,可直接应用于法院审判业务;最大限度地提取裁判文书信息,文书信息模型基本可以覆盖文书中包含所有的法律信息;采用分而治之的策略,以逻辑段为单位解析并提取信息项,只需关注各逻辑段的处理,降低了解析的复杂度,有效提高了提取正确率;使用xml结构化文档作为输出形式,具有良好的复用性,数据可以被不同的应用程序加以利用,保证了结构化文书的普遍适用性,使裁判文书中的信息可以按照法律业务需求在各种场景下适用。
需要明确,本发明并不局限于上文所描述并在图中示出的特定配置和处理。并且,为了简明起见,这里省略对已知方法技术的详细描述。当前的实施例在所有方面都被看作是示例性的而非限定性的,本发明的范围由所附权利要求而非上述描述定义,并且落入权利要求的含义和等同物的范围内的全部改变从而都被包括在本发明的范围之中。
- 还没有人留言评论。精彩留言会获得点赞!