基于影响力与种子扩展的重叠社区发现方法与流程
本发明涉及大规模网络上的重叠社区发现技术领域,特别是一种基于影响力与种子扩展的重叠社区发现方法。
背景技术
随着社会信息网络的快速发展,出现了很多复杂的网络结构,例如社交网络、科学家合作网络、文献引用网络、蛋白质互相协作网等。在复杂网络中,节点代表网络中的个体,而边代表个体间的联系,有的边还带有属性值。复杂网络中的社区结构通常表现为社区内的点连接紧密,而社区间的点连接稀疏。社区发现是研究复杂网络结构的关键技术之一。目前,社区发现的研究成果可以被应用于网络舆情监控、个性化兴趣推荐、蛋白质功能预测等诸多领域。
为了高效准确的挖掘出复杂网络中重要的社区结构,近些年已经有很多研究人员对其展开深入研究。传统的社区发现算法包括层次聚类算法、谱方法、基于团的方法、边聚类、标签传播等。这些算法虽然可以较好的发现网络社区结构,但需要对整个网络结构信息进行整体认知,当在规模较大或者不完整的复杂网络中就受到了一些约束,所以就有研究员提出了大量基于种子扩展的局部社区发现算法。
目前已有很多学者对基于种子扩展的重叠社区发现进行研究,也取得了很多成果,但仍然存在以下几个问题:首先算法的时间与空间复杂度相对较高,在处理较大规模网络时存在不足;其次,算法在选择种子节点时未能充分考虑节点间的紧密度,从而影响了社区扩展挖掘的精确度;最后,在社区扩展阶段未能综合考虑节点与社区的紧密度,对于参数的选择也不是很合理,所以社区发现的精度不高。
技术实现要素:
本发明的目的在于提供一种基于影响力与种子扩展的重叠社区发现方法,该方法可以高效、准确地对复杂网络的重叠结构进行划分。
为实现上述目的,本发明的技术方案是:一种基于影响力与种子扩展的重叠社区发现方法,包括以下步骤:
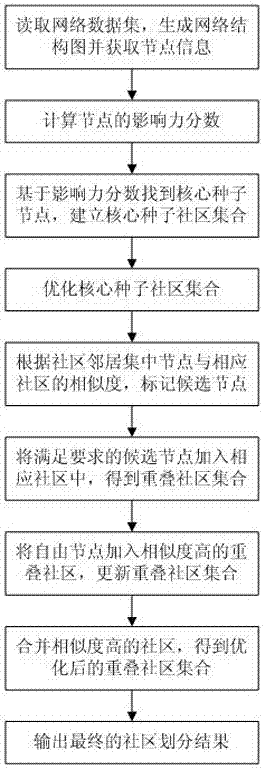
步骤1:读取网络数据集,生成网络结构图并获取网络中节点的邻域信息;
步骤2:结合网络中两两节点之间的jaccard系数和节点的邻域信息,计算网络中每个节点的影响力分数;
步骤3:基于节点的影响力分数,找到核心种子节点,进而建立核心种子社区集合coreseeds;
步骤4:计算核心种子社区之间的相似度,合并相似度高的社区,得到优化后的核心种子社区集合coreseeds’;
步骤5:根据各核心种子社区的社区邻居集中节点与相应核心种子社区的相似度,标记出候选节点;
步骤6:根据各候选节点的模块度,将满足模块度要求的候选节点加入相应核心种子社区中,得到重叠社区集合cset;
步骤7:根据未属于任何社区的自由节点与各重叠社区的相似度,将自由节点加入相似度高的重叠社区,更新重叠社区集合cset;
步骤8:根据重叠社区之间的相似度,合并相似度高的社区,得到优化后的重叠社区集合cset’;
步骤9:输出最终的社区划分结果。
进一步地,在步骤1中,读取网络数据集,生成用于社区结构划分的网络结构图g=(v,e),其中v表示节点集,e表示边集,并获取网络中节点的邻域信息:
其中,aij表示邻接矩阵,eij表示节点i和节点j之间的边。
进一步地,在步骤2中,计算网络中每个节点的影响力分数,包括以下步骤:
步骤2.1:统计每个节点的邻居集:
γ(v)={u:u∈v,(v,u)∈e}(2)
其中,γ(v)表示节点v的邻居集合,u表示节点v的邻居节点;
步骤2.2:计算任意两个节点之间的jaccard系数:
juv表示节点u与节点v的jaccard系数,juv用于衡量节点之间的亲密度,juv值越大表示两个节点之间越相似;
步骤2.3:根据jaccard系数和节点的邻域信息,计算每个节点的影响力分数iscore(v):
其中,kv为节点v的度;iscore(v)越大,表示节点v在网络中所具有的影响力越大,更有可能作为整个网络的核心种子节点。
进一步地,在步骤3中,基于节点的影响力分数,找到核心种子节点,进而建立核心种子社区集合coreseeds,包括以下步骤:
步骤3.1:统计每个节点v的影响力分数大于其邻居节点影响力分数的个数lnum,若lnum与节点v邻居节点个数nnum的比值大于阈值ρ,则将节点v定义为核心种子节点,并把节点v作为初始种子社区;
步骤3.2:遍历节点v的邻居节点集γ(v),计算邻居节点u与初始种子社区的相似度snc(u,c),找出相似度snc(u,c)大于设定阈值ε的邻居节点,加入到初始种子社区中得到核心种子社区s,从而得到核心种子社区集合coreseeds:
ns(c)=∪v∈cγ(v)-c(6)
其中,c表示初始种子社区,|ns(c)∩γ(v)|为社区邻居集ns(c)与节点v的邻居节点集的交集拥有的节点数,|ns(c)∪γ(v)|为社区邻居集ns(c)与节点v的邻居节点集的并集拥有的节点数;snc(u,c)表示节点u与社区c的相似度,snc(u,c)越大,表明节点u属于社区c的概率越大;∪v∈cγ(v)表示对属于社区c的所有节点的邻居集合进行合并操作,ns(c)表示与社区c有直接连边的节点集合。
进一步地,在步骤4中,计算核心种子社区之间的相似度,合并相似度高的社区,包括以下步骤:
步骤4.1:计算核心种子社区集合coreseeds中两两核心种子社区之间的社区相似度scc(ci,cj):
其中,|ci∩cj|为社区ci与社区cj的交集拥有的节点数,|ci|为社区ci的节点数,|cj|为社区cj的节点数,min(|ci|,|cj|)返回的是两个社区中节点数的最小值;scc(ci,cj)越大,表明社区ci与社区cj的结构越相近;
步骤4.2:将社区相似度scc(ci,cj)大于设定阈值ε的社区两两合并,得到优化后的核心种子社区集合coreseeds’。
进一步地,在步骤5中,根据各核心种子社区的社区邻居集中节点与相应核心种子社区的相似度,标记出候选节点,包括以下步骤:
步骤5.1:遍历步骤4得到的核心种子社区集合coreseeds’,对于其中的每一个核心种子社区cs,生成其社区邻居集ns(cs);
步骤5.2:遍历ns(cs),计算其中每个节点u与核心种子社区cs的相似度snc(u,cs);
步骤5.3:将相似度snc(u,cs)大于设定阈值ε的节点标记为候选节点。
进一步地,在步骤6中,根据各候选节点的模块度,将满足模块度要求的候选节点加入相应核心种子社区中,包括以下步骤:
步骤6.1:分别计算各候选节点加入社区前、后的模块度q,如果加入社区后q值较原先q值变大,则将节点加入社区,否则置其为自由节点;模块度q的计算公式如下:
其中,m是网络中边的总数,nc是社区数目,lc是社区c中边的总数,dc是社区c中所有节点的度总和;
步骤6.2:更新ns(cs),重复步骤5到步骤6,直到ns(cs)为空时停止;
步骤6.3:得到网络结构的初始社区划分,记为重叠社区集合cset。
进一步地,在步骤7中,根据未属于任何社区的自由节点与各重叠社区的相似度,将自由节点加入相似度高的重叠社区,包括以下步骤:
步骤7.1:找到网络中未属于任何社区的自由节点,形成自由节点集vfree;
步骤7.2:遍历自由节点集vfree,计算其中各自由节点vf与重叠社区集合cset中每个社区ci的相似度snc(vf,ci),把自由节点vf加入到相似度最高的社区中;如果相似度相同,则该自由节点同时属于多个社区,并对重叠社区集合cset进行更新。
进一步地,在步骤8中,计算重叠社区集合cset中两两社区之间的社区相似度scc(ci,cj),如果相似度大于设定阈值ε时,则将社区进行合并,从而得到优化后的重叠社区集合cset’。
进一步地,在步骤9中,输出最终的社区划分结果的方法如下:
步骤9.1:将重叠社区集合cset’中每个社区ci’中的节点vi,j写成行向量形式ri=(vi,j);
步骤9.3:输出向量集{ri},0<i<p,p为社区个数,每行代表一个社区;社区重叠由行向量中包含的重复节点表示。
本发明的有益效果是将影响力策略、相似度计算以及优化自适应函数fitness相结合,应用于较大规模网络的社区发现,从而能够有效地得到网络中重叠社区结构划分,并为网络聚类在重叠社区发现方向的发展提供有益补充。
附图说明
图1是本发明实施例的实现流程图。
具体实施方式
下面结合附图及具体实施例对本发明作进一步的详细说明。
本发明基于影响力与种子扩展的重叠社区发现方法,如图1所示,包括以下步骤:
步骤1:读取网络数据集,生成网络结构图并获取网络中节点的邻域信息。具体方法为:
读取网络数据集,生成用于社区结构划分的网络结构图g=(v,e),其中v表示节点集,e表示边集,并获取网络中节点的邻域信息:
其中,aij表示邻接矩阵,eij表示节点i和节点j之间的边。
步骤2:结合网络中两两节点之间的jaccard系数和节点的邻域信息,计算网络中每个节点的影响力分数。具体包括以下步骤:
步骤2.1:统计每个节点的邻居集:
γ(v)={u:u∈v,(v,u)∈e}(2)
其中,γ(v)表示节点v的邻居集合,u表示节点v的邻居节点;
步骤2.2:计算任意两个节点之间的jaccard系数:
juv表示节点u与节点v的jaccard系数,juv用于衡量节点之间的亲密度,juv值越大表示两个节点之间越相似;
步骤2.3:根据jaccard系数和节点的邻域信息,计算每个节点的影响力分数iscore(v):
其中,kv为节点v的度;iscore(v)越大,表示节点v在网络中所具有的影响力越大,更有可能作为整个网络的核心种子节点。
步骤3:基于节点的影响力分数,找到核心种子节点,进而建立核心种子社区集合coreseeds。具体包括以下步骤:
步骤3.1:统计每个节点v的影响力分数大于其邻居节点影响力分数的个数lnum,若lnum与节点v邻居节点个数nnum的比值大于阈值ρ,则将节点v定义为核心种子节点,并把节点v作为初始种子社区;
步骤3.2:遍历节点v的邻居节点集γ(v),计算邻居节点u与初始种子社区的相似度snc(u,c),找出相似度snc(u,c)大于设定阈值ε的邻居节点,加入到初始种子社区中得到核心种子社区s,从而得到核心种子社区集合coreseeds:
ns(c)=∪v∈cγ(v)-c(6)
其中,c表示由多个节点组成的一个初始种子社区,|ns(c)∩γ(v)|为社区邻居集ns(c)与节点v的邻居节点集的交集拥有的节点数,|ns(c)∪γ(v)|为社区邻居集ns(c)与节点v的邻居节点集的并集拥有的节点数;snc(u,c)表示节点u与社区c的相似度,snc(u,c)越大,表明节点u属于社区c的概率越大;∪v∈cγ(v)表示对属于社区c的所有节点的邻居集合进行合并操作,ns(c)表示与社区c有直接连边的节点集合。
步骤4:计算核心种子社区之间的相似度,合并相似度高的社区,得到优化后的核心种子社区集合coreseeds’。具体包括以下步骤:
步骤4.1:计算核心种子社区集合coreseeds中两两核心种子社区之间的社区相似度scc(ci,cj):
其中,|ci∩cj|为社区ci与社区cj的交集拥有的节点数,|ci|为社区ci的节点数,|cj|为社区cj的节点数,min(|ci|,|cj|)返回的是两个社区中节点数的最小值;scc(ci,cj)越大,表明社区ci与社区cj的结构越相近;
步骤4.2:将社区相似度scc(ci,cj)大于设定阈值ε的社区两两合并,得到优化后的核心种子社区集合coreseeds’。
步骤5:根据各核心种子社区的社区邻居集中节点与相应核心种子社区的相似度,标记出候选节点。具体包括以下步骤:
步骤5.1:遍历步骤4得到的核心种子社区集合coreseeds’,对于其中的每一个核心种子社区cs,生成其社区邻居集ns(cs);
步骤5.2:遍历ns(cs),计算其中每个节点u与核心种子社区cs的相似度snc(u,cs);
步骤5.3:将相似度snc(u,cs)大于设定阈值ε的节点标记为候选节点。
步骤6:根据各候选节点的模块度,将满足模块度要求的候选节点加入相应核心种子社区中,得到重叠社区集合cset。具体包括以下步骤:
步骤6.1:分别计算各候选节点加入社区前、后的模块度q,如果加入社区后q值较原先q值变大,则将节点加入社区,否则置其为自由节点;模块度q的计算公式如下:
其中,m是网络中边的总数,nc是社区数目,lc是社区c中边的总数,dc是社区c中所有节点的度总和;
步骤6.2:更新ns(cs),重复步骤5到步骤6,直到ns(cs)为空时停止;由于ns(cs)是一直更新的,当扩展到最后,最终社区的邻居集会出现为空集的情况,这也是迭代停止的条件;
步骤6.3:得到网络结构的初始社区划分,记为重叠社区集合cset;因为每个核心种子社区的扩展都不互相影响,则一个节点在每次扩展的过程可能会同时被归属到不同的核心种子社区中,从而得到网络结构的重叠社区划分。
步骤7:根据未属于任何社区的自由节点与各重叠社区的相似度,将自由节点加入相似度高的重叠社区,更新重叠社区集合cset。具体包括以下步骤:
步骤7.1:找到网络中未属于任何社区的自由节点,形成自由节点集vfree;
步骤7.2:遍历自由节点集vfree,计算其中各自由节点vf与重叠社区集合cset中每个社区ci的相似度snc(vf,ci),把自由节点vf加入到相似度最高的社区中;如果相似度相同,则该自由节点同时属于多个社区,并对重叠社区集合cset进行更新。
步骤8:根据重叠社区之间的相似度,合并相似度高的社区,得到优化后的重叠社区集合cset’。具体方法为:计算重叠社区集合cset中两两社区之间的社区相似度scc(ci,cj),如果相似度大于设定阈值ε时,则将社区进行合并,从而得到优化后的重叠社区集合cset’。
步骤9:输出最终的社区划分结果。具体方法如下:
步骤9.1:将重叠社区集合cset’中每个社区ci’中的节点vi,j写成行向量形式ri=(vi,j);
步骤9.3:输出向量集{ri},0<i<p,p为社区个数,每行代表一个社区;社区重叠由行向量中包含的重复节点表示。
以上是本发明的较佳实施例,凡依本发明技术方案所作的改变,所产生的功能作用未超出本发明技术方案的范围时,均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!