一种基于交叉存储的Cache实现方法与流程
本发明属于集成电路设计技术领域,具体涉及一种基于交叉存储的cache实现方法。
背景技术
高性能处理器通常采用层次化的多级cache来作为数据和指令的缓冲,以减小处理器和存储器之间的速率差异。其中,一级cache通常位于处理器核内部,与流水线紧密配合,具有很小的访问延迟,基本上与处理器的执行速率保持一致,为了获得指令和数据的并行访问,通常采用哈佛结构,即分成独立的指令cache和数据cache。一级cache始终都是影响处理器性能的重要因素。嵌入式高性能处理器的主存通常是具有猝发访问模式的快速存储器,配以高带宽的片上总线,满足处理器的高性能处理需求。设计与系统相匹配的cache对于处理器整体性能的提升有很大的帮助。
在cache的设计中,每个cache行中数据有效性的表示有两种方式:第一种是每个cache行中的每个字均用1bit的有效位进行表示,这种实现方式,主要应用于总线带宽不大,一般带宽只有1个字,而且流水线中每个周期需要的指令/数据量也只有1个字的系统中。每个字使用1bit的有效位可以实现一个cache行不必同时更新,每个字更新到cache中时只需将对应的有效位置位即可,由于cache缺失时的位置是随机的,对于每个字使用1bit的有效位的表示方式,可以只从缺失字开始取数据,而不必要将同个cache行中缺失字之前的字也取进cache中,可有效降低因不必要的访存引起的性能损失,文献“32位嵌入式处理器的cache设计”(西北工业大学硕士学位论文)采用了这种数据有效性的表示方式。第二种是每个cache行统一使用1bit的有效位进行表示,这种实现方式,需要使每个cache行的所有数据同时更新,valid位有效表示的是整个cache行的所有数据都是有效的,主要应用于总线带宽较大,可一次性填充整个cache行,满足处理器每个周期对多个指令/数据的需求,文献“x-dsp一级数据cache的设计与实现”采用的是第二种表示方法。
cache中的存储器可以分为tag存储器和data存储器,tag存储器中存储物理地址的高位,data存储器存储相应物理地址的数据。在cache的设计中,读data存储器的时机有两种:第一种是读tag存储器和data存储器同周期进行,下个周期同时将各路的tag和data读出,并进行命中判断,如果cache命中,则将命中路的data返回给处理器,文献“dsp处理器中数据cache的设计与验证”(西安电子科技大学硕士学位论文)采用了该种data存储器的读取时机。第二种是先读tag存储器,各路的tag读出后进行命中判断,如果cache命中,则再读对应路的data存储器,只读取出处理器需要的data,可有效降低功耗,但与第一种读方式相比,性能也降低了,文献“基于流水化和滑动窗口结构的低功耗指令cache设计”中采用了第二种data存储器的访问时机。实际设计中,具体选择哪种访问方案,需要根据流水线的时序要求进行选择。
针对每个cache行统一使用1bit的有效位进行表示,读tag存储器和data存储器同周期进行,下个周期就要将data返回流水线中。
针对该问题,可以想到两种方案:第一种是cache中的每路使用1个存储体,共有m路既用m个存储器,所有存储体的位宽为cache行的大小,既n个字,该方案最大的缺点是功耗太大,在读周期,需要将所有m路对应行的n个字全部读出(共m*n个字),之后再选择处理器需要的相应k个字,如果k比n小得多,则极大地浪费了无用数据读出的功耗,而且该方案的存储器不利于实现,因为既定容量的位宽很大的存储器在选定的工艺库中不一定存在。第二种方案是将第一种方案中的每1个存储体再进行细分,例如可分为n个存储器,每个存储器的深度不变,位宽为1个字,或者如果n是k的整数倍,可分为n/k个存储器,每个存储器的深度不变,位宽为k个字,该方案最大的缺点是分成的小块(存储体)个数太多,由此带来的面积开销太大。
cache存储器采用什么样的组织结构,如何保证一个周期能将同一路的某个cache行同时更新,保证与有效位的一致性,又要保证同个周期取出所有路的对应低位地址的k个字的数据,并且功耗以及硬件面积开销相比上述两种方案更小,经检索相关文献和专利,尚未发现有解决该问题的方法。
技术实现要素:
本发明所要解决的技术问题在于针对上述现有技术中的不足,提供一种基于交叉存储的cache实现方法,保证了可同时写入同一路一个cache行的所有数据,又可同时读出不同路的相同地址的数据,充分利用了高性能片上总线的数据带宽,又满足了处理器流水线对cache时序的要求。
本发明采用以下技术方案:
一种基于交叉存储的cache实现方法,在满足
具体的,包括以下步骤:
s1、根据cache的路数、cache行的大小、流水线与cache之间的数据带宽以及cache的容量,确定data存储器与tag存储器的组织结构;
s2、根据步骤s1确定的cache的组织结构,设计cache的更新与访问方式,保证一个周期能将一路的一个cache行同时更新,且同一周期取出所有路相同地址的数据;
s3、通过同周期将所有路的对应相同地址的tagv取出完成对tag存储器的读操作;
s4、基于cache的组织结构、cache存储器的读写访问方式,流水线在第一个周期发出访问所有m路的tag存储器和所有m路的对应k个字data的相关信号和有效时序;
s5、在第二个周期,读出所有m路的对应地址的tagv,进行命中判断,如果命中,在该周期将命中路的所有k个字返回给处理器,完成处理器对cache存储器的本次访问。
进一步的,data存储器的最小存储体的数据位宽为k个字,共有m个这样的存储体,存储体的深度根据cache的容量确定,tag存储器也包括m个小的存储体,每个存储体的深度是data最小存储块的k/n倍,每个存储体的宽度与cache的容量、存储的是物理地址还是虚拟地址的高位相关,tag每个存储块的每行中均增加一位有效位,用于表示对应data的整个cache行的有效性。
进一步的,在cache更新周期,将tag存储器中对应路、对应行的物理地址高位标志tag和有效位valid简称tagv、以及data存储器中对应路、对应cache行的n个字,同时进行更新。
更进一步的,对于data存储器的更新,更新cache行的地址是更新tagv对应行地址addr再拼接上
进一步的,根据处理器发出的读地址addr,实现同周期读出所有路的对应地址的tagv;使用相同的读地址对data存储器进行读操作,同周期将所有路的对应地址的第j组k个字取出,j=0,1,…,n/k-1,根据读地址的低
进一步的,设流水线访问tag存储器的地址为addr_tag,访问data存储的地址为addr_tag拼接上流水线访问地址的低
进一步的,步骤s5中,命中判断具体为:如果第i路命中,i=0,1,…,m-1,在这个周期需要给流水线返回第i路的第j组k个字,j=0,1,…,n/k-1,根据读地址的低
与现有技术相比,本发明至少具有以下有益效果:
本发明一种基于交叉存储的cache实现方法,在cache的功耗以及硬件开销较小的情况下,通过采用交叉存储的cache更新方式,保证了可同时写入同一路的一个cache行的数据,又可同时读出不同路的相同地址的数据,充分利用了高性能片上总线的数据带宽,又满足了处理器流水线第一个周期读tag和data存储器,第二个周期将命中路的对应数据返回流水线的要求,所取得的效果如下:
tag存储器只采用m(m为cache的路数)个位宽为tagv长度的存储体,data存储器只采用m个位宽为k(k为处理器与cache之间的数据位宽)个字长度的存储体,相比data存储器采用m个位宽为一个cache行大小的存储体方案,降低了无用数据的读功耗;相比data存储器每路采用n/k(n为一个cache行的大小,即n个字)个位宽为k个字的存储体,共需要m*n/k个存储体的方案,面积更小。
cache的data存储器采用交叉存储的方式,在m≥n/k的情况下,保证了一个cache行的所有n/k组的k个字分别位于不同的存储体中,可实现同周期更新整个cache行的时序需求;也保证了不同路的相同cache行中的第j组k个字,j=0,1,…,n/k-1,分别位于m个不同存储体的相同地址中,地址低
在对cache进行更新时,同一个cache对应的tagv和所有的n/k组的k个字的数据同时写入,保证了数据有效位的正确指示。
流水线对cache访问的时序要求是第一个周期cache根据流水线发出的访问地址对tag存储器和data存储器并行访问,第二个周期将流水线发出的物理地址高位与从tag存储器中读出的各路的tag比较,进行命中判断,如果命中,该周期将命中路的对应k个字返回给流水线,这要求该周期读出所有路的对应k个字,这对于采用交叉存储方式的data存储器是满足的。
下面通过附图和实施例,对本发明的技术方案做进一步的详细描述。
附图说明
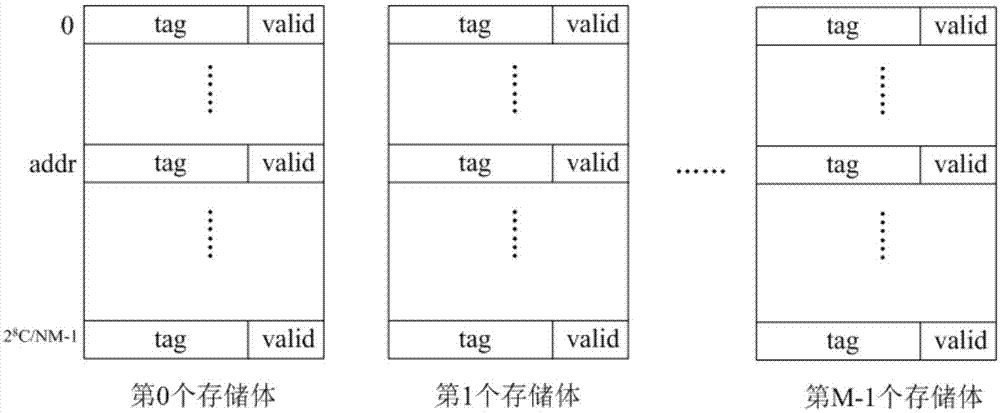
图1为tag存储器的组织结构示意图;
图2为data存储器的组织结构示意图;
图3为data存储器的交叉存储控制示意图。
具体实施方式
本发明提供了一种基于交叉存储的cache实现方法,在满足
本发明一种基于交叉存储的cache实现方法,包括以下步骤:
s1、根据设计中确定的cache的路数、每个cache行的大小、流水线与cache之间的数据带宽以及cache的容量,确定data存储器与tag存储器的组织结构;
例如,cache采用m路组相联、每个cache行的大小是n个字、流水线与cache之间的数据带宽是k个字。为了避免不必要的cache跨行访问引起的性能损失,cache行大小n是流水线与cache间数据带宽k的整数倍。于是,确定的data存储器的最小存储体的数据位宽为k个字,共有m个这样的存储体,存储体的深度根据cache的容量确定。
tag存储器也包括m个小的存储体,每个存储体的深度是data最小存储块的k/n倍,每个存储体的宽度与cache的容量、存储的是物理地址还是虚拟地址的高位等有关,并且tag每个存储块的每行中均增加了一位有效位,用于表示对应data的整个cache行的有效性。
s2、根据上述的cache的组织结构,设计cache的更新方式,保证一个周期能将一路的某个cache行同时更新,保持与有效位的一致性,又要保证同个周期能取出所有路相同地址的数据;
在cache更新周期,将tag存储器中对应路、对应行的物理地址高位标志tag和有效位valid简称tagv、以及data存储器中对应路、对应cache行的n个字,同时进行更新。tag存储器的更新相对简单,只需要将拼接好的tagv写入对应路、对应行中即可。
对于data存储器的更新,更新cache行的地址是更新tagv对应行地址addr再拼接上
按照上述方式进行更新,保证了不同路的相同cache行中的第j组k个字,j=0,1,…,n/k-1,分别位于m个不同的存储体中,并且位于相同的地址中,地址低
s3、对tag存储器读操作的要求是同周期将所有路的对应相同地址的tagv取出;
由于tag存储器由m个小的存储体组成,每个存储体对应1路,存储体的位宽为tagv的长度,所以根据处理器发出的读地址addr,可实现同周期读出所有路的对应地址的tagv;对data存储器读操作的要求是使用相同的读地址,同周期将所有路的对应地址的第j组k个字取出,j=0,1,…,n/k-1,j是根据读地址的低
s4、基于上述cache的组织结构、cache存储器的读写访问方式,流水线在第一个周期发出访问所有m路的tag存储器和所有m路的对应k个字data的相关信号和有效时序,不妨设流水线访问tag存储器的地址为addr_tag,则访问data存储的地址为addr_tag拼接上流水线访问地址的低
s5、在第二个周期,读出所有m路的对应地址的tagv,进行命中判断:如果第i路命中,i=0,1,…,m-1,则在这个周期需要给流水线返回第i路的第j组k个字,j=0,1,…,n/k-1,j是根据读地址的低
实际上,这个周期已经将所有路的第j组k个字读出了,只需要从中选取第i路的第j组k个字返回流水线即可。
基于交叉存储的cache实现方式,保证了可同时写入同一路一个cache行的数据,又可同时读出不同路相同地址的数据,充分利用了高性能片上总线的数据带宽,又可以完全满足流水线在第一个周期发出读tag和data存储器的时序,第二个周期读出tagv进行命中判断以及将命中路的对应数据返回流水线的要求。并且tag存储器只使用m个位宽为tagv长度的存储体(存储体容量与配置的cache的容量相关),data存储器只使用m个位宽为k个字的存储体(存储体容量与配置的cache的容量相关),功耗以及硬件开销更小。
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。通常在此处附图中的描述和所示的本发明实施例的组件可以通过各种不同的配置来布置和设计。因此,以下对在附图中提供的本发明的实施例的详细描述并非旨在限制要求保护的本发明的范围,而是仅仅表示本发明的选定实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
请参阅图1,图1中tag存储器分为m个存储体,分别对应m路,存储体的每行存储的是物理地址的高位标志tag和表示对应cache行是否有效的valid位。假设cache的容量为ckb,每个字的大小为4个字节,则每个存储体的深度为210c/4nm=28c/nm行。
请参阅图2,图2中data存储器也分为m个存储体,每个存储体的位宽为k个字的长度,每个存储体的深度为
请参阅图3,以一个具体的例子,说明data存储器的交叉存储控制,具体如下:
cache的路数为m=6,一个cache行n=8个字,流水线与cache之间的数据位宽k=2个字,cache的容量c=24kb,当对第0路,第0个cache行进行更新时,cache行的第0组的2个字对应图3中的“0路_0”写入第0个存储体的0地址,第1组的2个字对应图3中的“0路_1”写入第1个存储体的1地址,依次类推,第3组的2个字对应图3中的“0路_3”写入第3个存储体的3地址;
当对第1路,第0个cache行进行更新时,cache行的第0组的2个字对应图3中的“1路_0”写入第1个存储体的0地址,第1组的2个字对应图3中的“1路_1”写入第2个存储体的1地址,依次类推,第3组的2个字对应图3中的“1路_3”写入第0个存储体的3地址;
于是可以归纳为,当对第i路,i=0,1,2,…,5,第0个cache行进行更新时,cache行的第0组的2个字对应图3中的“i路_0”写入第i个存储体的0地址,第1组的2个字对应图3中的“i路_1”写入第(i+1)mod6个存储体的1地址,依次类推,第3组的2个字对应图3中的“i路_3”写入第(i+3)mod6个存储体的3地址;对其他cache行的更新操作是类似的。
对data存储器进行读操作时,根据读地址的低位,确定从不同存储体中取出的是对应哪一路的数据,如果读地址的低位为j,
本发明已经应用于一款兼容sparcv8结构的高性能soc中,该soc具有高带宽的片上总线,并且其支持的主存储器为具有猝发访问模式的快速存储器,可快速实现cache行的同时更新,于是采用每个cache行使用1位有效位的实现方式,充分利用了片上总线的高带宽优势;并且处理器中的流水线对时序的要求是第一个周期发送访问cache的地址,第二个周期将命中的数据返回流水线中,一级的指令cache和数据cache通过分别采用交叉存储的cache实现结构,满足了流水线对时序的要求。
本发明中的cache实现方法对一级指令和数据cache均适用,甚至是二级/三级cache中,只要涉及需要保证一个周期能同时将一路的某个cache行同时更新,又要保证同个周期能同时取出所有路对应地址的数据的情况,本发明均是有效的。
以上内容仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明权利要求书的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!