基于C6678平台的大数据转置方法与流程
本发明涉及雷达数据处理的技术领域,具体地说是一种基于c6678平台的大数据转置方法。
背景技术:
随着雷达技术的进步,大数据、快速存储、高速运算已经成为了雷达信号处理的主流,特别是海量数据的转置读写更是stap杂波抑制、sar成像等重要功能必不可少的环节。但是受限于大数据存储器件线性存储的限制条件,海量数据传统转置读写的性能会随着矩阵操作的增大,性能迅速下降,有时转置时间甚至占用了整个信号处理时间的70%,成为了制约雷达实时信号处理发展的致命短板。
为了解决传统矩阵转置操作单地址跳转读写效率异常低下的问题,本文结合ti公司最新信号处理芯片tms30c6678dsp处理芯片提出了一种高速转置方法。该方法基于ddr(doubledataratesdram)分块转置的原理,有效整合片外存储器ddr、片内存储共享、核内缓存空间三种存储器的优点,实现海量数据高速、无缝搬移,使得最终的转置效率提升4-5倍,有效缩短了数据搬移的时间,大幅提升了实时处理的性能,扩展了多种雷达算法的工程应用领域。
技术实现要素:
本发明的目的是克服上述现有技术的不足,提供一种整合多种存储器,利用合理的分块转置算法实现海量数据高速转置的基于c6678平台的大数据转置方法。
本发明采用的技术方案为:基于c6678平台的大数据转置方法,包括下述步骤:
1)系统初始化,设置分块转置的详细参数:分块的个数、分块矩阵的列大小、分块矩阵的行大小;
2)依据初始化后的分块转置参数,通过qdma通道ddr分块转置读取,完成分块矩阵由ddr到共享的数据搬移;
3)启动8核并行开展数据共享存储的分块读取,片内存储的跳转存储,数据按照列格式顺序存储;
4)在片内存储空间开展并行转置列的数据处理,完成矩阵转置信号处理;
5)转置并行列处理结果顺序写入ddr,片内存储器内的转置处理结果存储到ddr缓存区内,完成分块转置处理。
进一步的,矩阵转置时评估公式为:
其中为10gb/s为ddr顺序读写的速率,m为方位向点数,n为距离向点数,1/4为brust读取效率,1/4为ddr跨页读取效率。
进一步的,转置速率公式为:
其中m为分块转置所包含的列个数,其大小为:
其中2048*1024/8为2mb数据中缓存的复数的个数,实部虚部为32位浮点数,整个m*n矩阵需要分块的个数为:
count=n/m。
基于c6678平台的大数据转置方法与传统的转置相比,能取得如下有益效果:1、采用分块转置的方法提升外设存储其的数据搬移效率,避免ddr跳转单点读取效率低下的问题;2、采用边转置边处理的分块转置算法,每次转置大小都为二维列数的整数倍,能够在转置读取存储前开展信号处理,避免不必要的数据搬移;3、采用8核并行数据l2存储独立排序设计,既能够充分利用8核并行的运算优势,又能够充分利用片存储器的独立写通道的特性,充分提升传输效率;4、能够有机整合片dsp的多种存储器资源,大幅提升矩阵转置的效率。
附图说明
图1基于c6678平台的大数据转置方法的流程图。
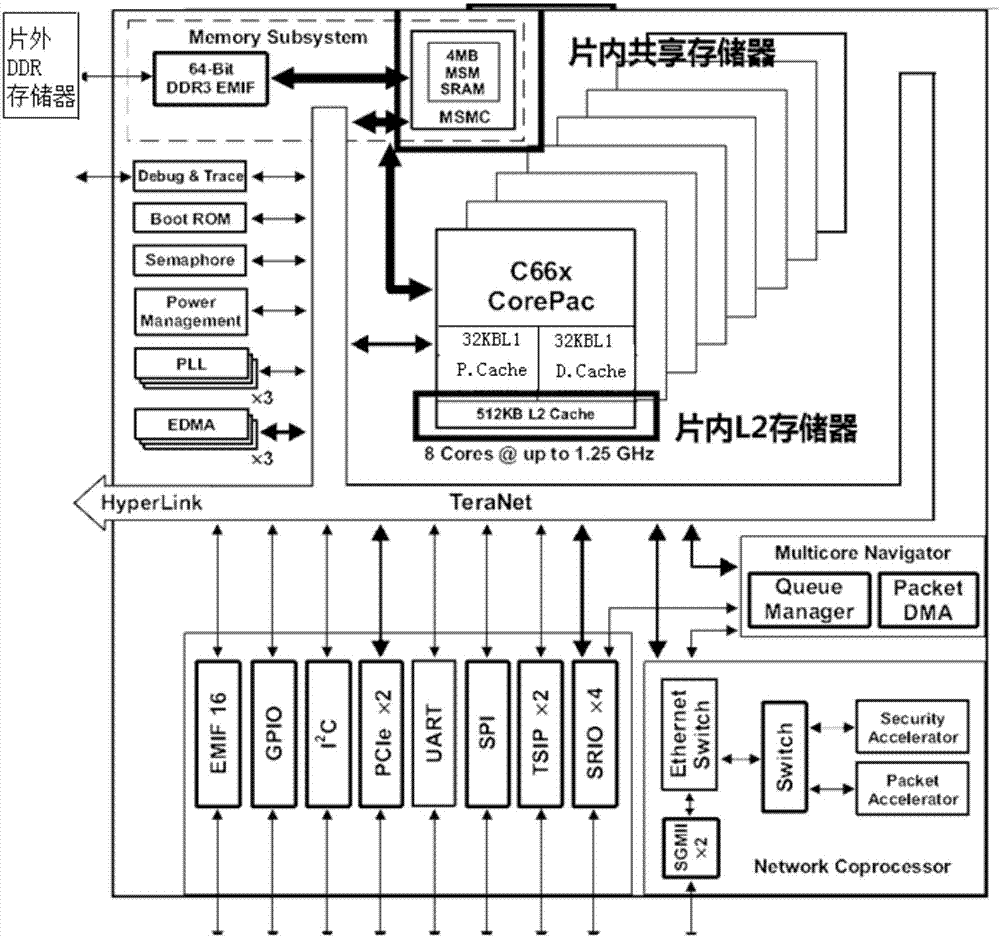
图2现有c6678平台组成示意图。
图3传统转置速率的测试结果。
图4ddr分块转置读取示意图。
图5ddr分块转置读取速率的测试结果。
图6ddr分块转置数据存储结构。
图7片内l2存储器内顺序存储的数据结构。
图8基于c6678平台的大数据转置工程实现的数据格式图。
图9高速转置与传统转置的速率对比。
具体实施方式
下面结合附图对本发明做进一步阐述。
基于c6678平台的大数据转置方法充分利用c6678的片内、片外各种存储器,以及c6678高速信号处理功能才能够完成实现,充分体现c6678的高吞吐量性能。
依据图1的流程图可知,具体的实现步骤如下:
1.系统初始化,设置分块转置的详细参数:分块的个数、分块矩阵的列大小、分块矩阵的行大小;
2.系统同步,8核同步一次,8核处于就绪状态;
3.dsp芯片0核启动,通过qdma通道进行ddr分块转置读取,完成分块矩阵由ddr到共享的数据搬移;
4.系统同步,8核同步一次,8核处于就绪状态;
5.8核并行开展数据共享存储的分块读取、片内存储的跳转存储,数据按照列格式顺序存储;
6.8核并行开展信号处理,完成各个数据列的信号处理;
7.8核并行进行ddr数据顺序存储,片内存储器内的转置处理结果存储到ddr缓存区内,完成一次分块转置处理;
8.系统同步,8核同步一次,8核处于就绪状态;
9.分块转置计数器是否为0,计数器为0时矩阵转置处理完成,计数器不为0分块转置还需要继续,重新开始步骤3。
本发明采用下述方法来实现c6678平台的快速转置:
本文采用分块转置设计,充分利用c6678芯片8个高速处理内核,有效整合片外存储器、片内共享存储器、片内存储器三种存储器的优点,取长补短发挥各个单元的优势,最终完成海量数据的快速转置。其分析与实现步骤如下:
由图2可知,现有的c6678平台由通信接口、外扩存储空间、处理芯片三个部分组成。与数据转置有关的主要有存储空间、处理芯片两个部分。其性能描述如下:
处理芯片:主频1ghz,8核集成、每个核集成两组寄存器、16个功能单元,支持流水线数据操作。
片内l2存储空间:大小512kb,每个核都单独使用,读写主频1ghz,具备独立的写入通道,但数据读取时需要经过cache缓存;
片内共享空间:大小4mb,8核共同使用,读写主频500mhz,数据的读写都需要经过cache缓存;能够满足常规小块数据的输入与缓存,更能够应用于8个处理核之间的同步与数据交换。
片外ddr扩展存储空间:大小2gb,单独数据总线与dsp芯片通信,读写主频1.33ghz,64位位宽、单个brust通信读取数据大小32byte,ddr翻页跳转时钟间隔为4,刷页间隔74us,刷页时间0.1us。
片外ddr扩展存储空间作为大数据存储的唯一手段,为dsp实时处理提供了数据源与缓存空间,但是受限于ddr跳转读写翻页效率、与最小通信brust数据大小的限制条件,在进行大矩阵转置时,数据读写效率会直线降低,其评估公式为:
其中为10gb/s为ddr顺序读写的速率,m为方位向点数,n为距离向点数,1/4为brust读取效率,1/4为ddr跨页读取效率。理论速率在625mb/s左右。
图3是传统c6678平台实时测试了不同矩阵大小情况下,实时转置的速率。虽然ddr理论数据搬移速率可以达到10gb/s,但由于其线性数据读取的限制条件,其转置效率会随着矩阵的增大、迅速降低,转置速率下降到小于550mb/s,为数据顺序传输峰值速率的1/18,只使用了5.5%的搬移效率,高速带宽使用率低,已经无法满足实际应用中的需求。
本发明采用分块转置的方法,提升ddr转置数据搬移的效率,分块转置时为了提升信号处理的效率需要采用边搬移边处理的方法进行分块转置。该方法每次都是以转置列长度m的整数倍进行分块,这样每次转置缓存后的结果就可以进行完整的列处理,处理后的结果再缓存到ddr,这样转置搬移的一次数据搬移过程中就可以实现转置列的信号处理,无需为了列数据处理进行二次数据搬移,提升信号处理的效率。结合c6678硬件平台,为避免数据溢出,每次分块转置的大小为2mb,即片内共享空间存储空间的一半。此时分块转置速率推导公式为:
其中m为分块转置所包含的列个数,其大小为:
其中2048*1024/8为2mb数据中缓存的复数(实部虚部为32位浮点数)的个数。整个m*n矩阵需要分块的个数为:
count=n/m
图4显示了分块矩阵读取前后的关系。
其中aij表示了第i列第j行存储的原始点数。为验证分块矩阵搬移的效率,结合实时处理平台实测了各种点数下ddr数据分块读取的速率,如图5。
由图5可知,合理的分块转置可以大幅提升ddr数据读取的效率,分块矩阵一次搬移的点数越多,ddr数据读取的速率越高。当矩阵列点数小于时32k,分块读取的速率3.8gb/s,为常规转置的速率的0.55gb/s的7.5倍,效率提升了650%。但是受限于共享存储空间大小的限制,转置矩阵不能无限大,矩阵列大于32k会影响转置效率,不过大多数情况下32k点的列长度已经满足要求。
数据进入片内共享空间后,数据是按照分块格式存储,如图6所示。分块存储的结果无法直接用于转置列数据存储,两个列数据的间隔为m点,即ddr分块顺序读取的块点数大小。
本发明考虑到片内l2存储空间独立写通道的特性,利用共享空间分块读取、片内l2跳转存储,最终实现整列数据顺序存储,如图7。
其中m0为c6678单核内缓存行(ddr原始数据列)的个数,其计算公式为:
m0=m/8
8个核并行完成整列数据跳转片内l2存储之后,就可以开展相应的列信号的处理。处理后进行一次同步后就可以准备后续的转置结果储存。
处理后的结果就可以由片内l2存储器顺序搬移存储到ddr。完成转置结果存储的闭环。
下文列表显示了不同矩阵大小下实测的转置速率,以及各个步骤的时间开销:
表1高速转置设计下的实测结果
由上表可知,转置的的速率可以提升到2.6gb/s。步骤1的ddr数据源读取、步骤3的数据结果存储中ddr都是在高速工作,而且ddr搬移时间只占用了83%,其余时间ddr带宽都是释放状态,这就为后续ddr后台其他操作奠定了基础,具有更好的应用空间。步骤2为片内共享到片内l2的数据搬移,由于有效利用了c6678高速芯片8核并行的优势,核内搬移时间只占用了17%,能够以很小的核内处理时间开销获得转置的斜率的大幅提升。
不同存储器下数据存放的数据格式如图8所示。
本发明可以有效整合各种存储器的优点,大幅提升数据吞吐率。结合c6678信号处理平台,后续测试了不同转置列大小情况下转置的速率,并与传统转置的速率结果对比如图9所示。
当转置矩阵列大小m>2k时,本发明的转置速率为>2.5gb/s,为传统转置速率的5倍,能够明显改善转置效率。
以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!