一种中文长文本情感分析方法与流程
本发明涉及自然语言处理领域,具体地,涉及一种中文长文本情感分析方法。
背景技术:
在过去的几十年中,人们的生活越来越离不开互联网,随着“互联网+”的发展,许多传统行业和互联网相结合,互联网也在逐渐改变人民的生活方式,现在的用户已经从以前单纯的从网络获取信息的索取者变为了网络信息的创造者,人们通过微博、朋友圈和论坛等发表着自己的想法观点。近几年互联网的信息也呈现指数性的增长。
这些信息往往存在巨大的社会和经济效益,对于个人来说,了解他人的观点可以帮助他们在购物上作出选择或者学习自己未了解的知识;对于商家或者组织来说,可以帮助他们了解市场形势来及时调整战略。但是这些海量信息同时也会造成互联网舆情问题。社会各类信息通过互联网的传播,和以往相比传播的途径更加丰富、传播的效率更加高、覆盖的范围也更加全面了,如果不进行合理的监控与管理,极易在社会上造成不良的影响。而舆情分析的核心同样是情感分析。
文本情感分析的结果通常分为三种,即积极、中性和消极,也可以看成一个三分类问题。为了实现海量互联网文本的情感分析,研究者们通过统计的方法、机器学习以及神经网络等方法来自动化分析文本的情感倾向性。目前文本情感分析对于微博等短文本的研究较多,而长文本的研究相对匮乏,而且中文不同于英文有许多复杂的句式,所以在长文本的情感分析上难度更大。
目前情感分析的研究主要分为两个方向,一个是基于情感词典的情感分析算法,一个是基于机器学习的情感分析算法。在情感词典的情感分析中,情感词典的质量直接影响到最终的情感分析结果,所以设计一个高质量的情感词典至关重要。在机器学习的情感分析主要是基于文本分类,选取词特征、词性特征和语义特征为特征向量,使用支持向量机等算法来进行情感分析。长文本的情感分析技术的核心是过滤掉没有情感表达的客观陈述句,只对文中表达情感的语句来进行情感分析,从而提高情感分析的准确性和效率。
技术实现要素:
本发明的目的在克服现有长文本情感分析算法准确率不高的问题,提供一种基于机器学习的长文本情感分析方法,采用条件随机场抽取核心句,引入句子情感极性权值来分析整篇文章,提高中文长文本情感分析的准确率。
为实现上述发明目的,本申请提供了本发明基于机器学习的情感分析方法,包括以下步骤:
(1)、文本预处理
将待情感分析的文章根据标点好进行断句,然后对每一句话进行分词、过滤停用词操作;
(2)、条件随机场抽取核心句
使用条件随机场得到整篇文章的评价对象,包含该评价对象的句子为该篇文章的核心句。
(3)、对核心句进行情感分析
采用基于情感词典的情感分析算法,遍历文本预处理后的句中所有词语,如果存在于情感词典中,则记录下相应的情感极性分数,最后把所有记录下的分数累加求和,根据最终的分数来判断每句话的情感极性,如果最终分数大于零则表达了积极的情感,如果小于零则表达了消极的情感,如果等于零则没有明显的情感表达,然后根据判断结果定义初始情感分数为+1、-1和0。
(4)、定义核心句的情感极性权值
采用情感极性权值来区分不同句子情感极性的强弱,根据最终的情感权值分数分析整篇文章情感极性。
(5)、扩展当前情感分析所使用的情感词典
采用pmi互信息率和斯坦福语义树把情感词典中未包含的情感词加入进去,扩展情感词典的使用范围。
(6)、得到最终情感分析结果
其中所述步骤(1)中文本预处理的具体步骤为:
(1.1)对输入的非结构化文本进行统一格式处理:去除非结构化文本的首尾非文本部分,获取纯文本部分,若为空文本则跳过;
(1.2)对待分析的纯文本根据句号、惊叹号、省略号、问号、分号来断句;
将纯文本部分进行词语词性的分词处理,针对词语词性,去除分词结果中的标点符号、拟声词、叹词、助词、连词、介词、副词、数词、量词;
其中,条件随机场抽取核心句的具体方法为:
(2.1)、由ramshaw和marcus提出评价对象标记模式为抽取评价对象过程中的自定义标记标签。对分词过后的词语进行iob标签标记,使用stanfordparser分析上面分词过后的句子,得到每个词语相应的语义树标签。
(2.2)根据分词结果、词性、语义结构设计了条件随机场的特征函数模板。
(2.3)统计整篇文章的评价对象词语,出现频率最高的那个词语就为整篇文章的评价对象,包含该词语的句子则为核心句。如果多个评价对象出现次数最高时,那么这些词均为该篇文章的评价对象。
其中对核心句进行情感分析的具体方法为:
(3.1)对核心句使用基于情感词典的情感分析算法,根据情感分析结果的积极、消极和无明显情感定义该句子的初始情感分数为+1、-1和0。
其中定义核心句情感极性权值的具体方法为:
(4.1)根据每句话情感表达强度的不同,给每句话定义不同情感极性权值,然后给每句话的初始情感分数乘以一个相应的权值。
(4.2.1)程度副词会加强或减弱情感词的情感强度,本专利设计了一个程度副词表,根据不同的程度副词给该核心句的情感极性分数乘以一个权值。
(4.2.2)感叹句和疑问句会加强句子的情感表达,本专利设计了相应的语气助词表,给相应的核心句乘以一个权值。
(4.2.3)总结句是作者总结前文表达自己观点的句子,本专利设计了一个程度副词表,给相应的核心句乘以一个权值。
其中扩展当前的情感词典具体的方法为:
(5.1)将分词和去掉停用词的词语组合输入到斯坦福解析器中进行语法解析,得到每个词语相应的语法标签。选取语法标签为副词短语advp、形容词短语adjp、动词短语vp并且不包含在情感词典的词语作为候选情感词。
(5.3)构建一个基础情感词典,计算候选情感词与基础情感词典的互信息率,满足一定的阈值则加入到情感词典当中。
(5.3.2)计算每个候选情感词和基础情感词典的互信息率,计算公式为
其中ci为候选情感词,n为基础情感词典,ri为基础情感词典中的情感词,count(ci,ri)为资料库中的数量,本专利中选取互联网为资料库,通过一个爬虫来爬取该组合在互联网上的信息条目数。计算该词的互信息率,最终符合条件加入到情感词典中。
本发明的发明目的是这样实现的:
本发明提出一种中文长文本的情感分析方法,使用机器学习条件随机场得到每句话的评价对象,根据评价对象得到整篇文章的核心句,然对核心句进行情感分析,又根据每句话情感极性强度的不同赋予了不同权值,最终分析得到整篇文章的情感极性。通过提取核心句过滤掉没有情感表达的陈述语句,对核心句表达的情感强度做了进一步的划分,提高了长文本情感分析的准确率。
同时本发明提出的一种中文长文本的情感分析方法还具有以下有益效果:
(1)、采用条件随机场抽取核心句,降低了需要情感分析语句的数量,提高了情感分析的效率。
(2)、使用pmi互信息率和斯坦福语义树来扩展情感词典,增加了情感词典的情感词数量,提高情感分析的召回率。
附图说明
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本申请的一部分,并不构成对本发明实施例的限定;
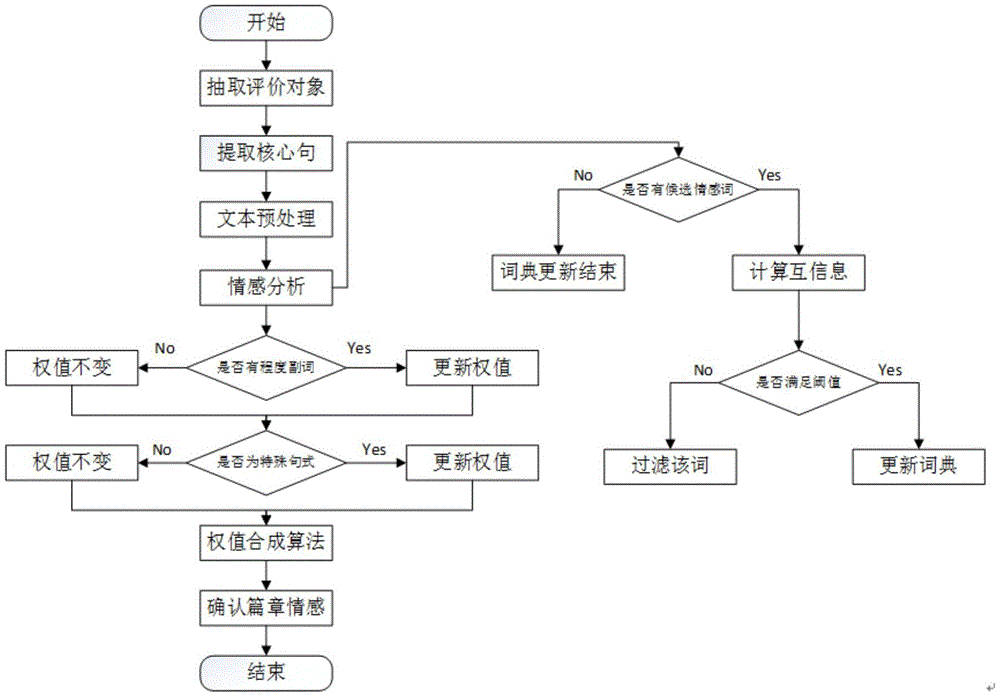
图1是中文长文本情感分析方法流程图;
图2是条件随机场提取核心句流程图;
图3是对句子定义情感权值合成流程示意图;
图4是情感词典扩展流程示意图。
具体实施方式
为了能够更清楚地理解本发明的上述目的、特征和优点,下面结合附图和具体实施方式对本发明进行进一步的详细描述。需要说明的是,在相互不冲突的情况下,本申请的实施例及实施例中的特征可以相互组合。
在下面的描述中阐述了很多具体细节以便于充分理解本发明,但是,本发明还可以采用其他不同于在此描述范围内的其他方式来实施,因此,本发明的保护范围并不受下面公开的具体实施例的限制。
实施例一:
图1是本发明一种中文长文本情感分析方法的流程图。
在本实施例中,如图1所示,本发明一种中文长文本情感分析方法,包括以下步骤:
s1、条件随机场提取核心句
对输入的每句话进行条件随机场模型标记评价对象,统计整篇文章出现次数最多的词为整篇文章的评价对象,提取包含该评价对象的句子为核心句。对核心句进行分词与去掉停用词处理,针对不同的语言可以采取不同的分词方法,本实施例中,针对汉语采用jieba汉语分词系统进行分词操作。获得词性之后,去除分词结果中的标点符号、拟声词、叹词、助词、连词、介词、副词、数词、量词。
下面结合图2对条件随机场提取核心句的具体流程进行详细说明,具体如下:
s1.1、对输入的每句话进行条件随机场抽取评价对象;
s1.1.1、首先对句子进行分词处理,本实施例中使用jieba分词进行分词操作,然后对分词结果使用iob标记为条件随机场抽取评价对象的标记模式,其中(1)b-eva,评价对象修饰短语开始词语;(2)i-eva,评价对象修饰短语内部词语;(3)b-pro,评价对象开始词语;(4)i-pro,评价对象内部词语;(5)b-att,评价对象相关属性开始词语;(6)i-att,评价对象相关属性内部词语;(7)o,其他;
s1.1.2将分词结果进行语义分析,本实施例中使用斯坦福解析器进行语法解析,得到相应的语义树标签。根据分词结果、词性和语义树标签设计相应的条件随机场特征模板。
在标记结果中b-pro和i-pro为该句话的评价对象。
s1.2、统计整篇文章中所有的评价对象以及出现的次数,出现次数最高的词语为整篇文章的评价对象,包含该词语的句子为该篇文章的核心句;
s1.3、然后对核心句进行基于情感词典的情感分析。
s1.3.1、遍历句中的情感词,并根据情感词典记录相应的情感极性分数累加求和,最终结果如果大于0,该句则表达了积极的情感,如果结果小于0则表达了消极的情感,如果结果为0,则该句没有明显的情感表达。
下面结合图3对句子进行定义情感权值流程进行详细说明,具体如下:
s2.1、根据核心句情感分析的结果,如果表达了积极的情感,则定义初始情感分数为+1,如果表达了消极的情感,则定义初始情感分数为-1,如果没有明显的情感表达,则初始情感分数为0;
s2.2、根据是否存在程度副词和句式给相应的初始情感分数乘以一个权值;
s2.2.1、根据本专利设计情感词程度副词表给句子乘以一个相应的权值;
本专利将程度副词分为most、more和less三级,相应的权值为1.5、1.25和0.75。遍历核心句,如果存在程度副词则在该句子的初始分数上乘以相应的权值。
s2.3、根据是否为特殊句式给相应的初始情感分数乘以一个权值。
s2.3.1、根据本专利设计感叹词表给句子乘以一个相应的权值。
本专利统计了中文中常见的感叹词并定义相应的情感极性权值,设计了一个感叹词表,遍历核心句,如果存在感叹词则该句子的初始分数上乘以相应的权值。
s2.3.2、根据本专利设计总结词表给句子乘以一个相应的权值。
本专利统计了中文中常见的总结词并定义相应的情感极性权值,设计了一个总结词表,遍历核心句,如果存在总结词则该句子的初始分数上乘以相应的权值。
s3、对赋予了情感极性权值的情感极性分数极性累加求和分析最终结果。
累加求和所有核心句的情感极性分数,最终结果如果大于0,该篇文章则表达了积极的情感,如果结果小于0则表达了消极的情感,如果结果为0,则该文章没有明显的情感表达。
下面结合图4对扩展情感词典的具体流程进行详细说明,具体如下:
s3.1、对本文预处理后的结果进行语义分析,本实施例中使用斯坦福解析器进行语义分析,根据语义标签选取候选情感词;
使用斯坦福解析器对核心句进行语义解析,根据语义标签,本实施例选取语义标签为动词短语vp,形容词短语adjp和副词短语advp并且不存在于情感词典的词语为候选情感词。
s3.2、根据本专利的基础情感词典计算该词与基础情感词典的互信息率;
s3.2.1、本实施例设计了一个代表积极和消极情感的基础情感词典,然后计算每个候选情感词和基础情感词典的互信息率,消极互信息率计算公式为
s3.2.2、本实施例中通过一个爬虫来爬虫相应词语组合在互联网中的条目数,并设计当该词语与基础情感词典的条目数大于1500万条时计算该词与基础情感词典的积极互信息率和消极互信息率。
s3.2.3、计算积极互信息和消极互信息之差,如果结果为正则为积极情感词,不然则为消极情感词,根据结果将情感词加入情感词典。
尽管已描述了本发明的优选实施例,但本领域内的技术人员一旦得知了基本创造性概念,则可对这些实施例作出另外的变更和修改。所以,所附权利要求意欲解释为包括优选实施例以及落入本发明范围的所有变更和修改。
显然,本领域的技术人员可以对本发明进行各种改动和变型而不脱离本发明的精神和范围。这样,倘若本发明的这些修改和变型属于本发明权利要求及其等同技术的范围之内,则本发明也意图包含这些改动和变型在内。
- 还没有人留言评论。精彩留言会获得点赞!