一种基于双变加权核FCM算法的数据聚类方法与流程
本发明涉及数据聚类
技术领域:
,具体地说是一种基于双变加权核fcm算法的数据聚类方法。
背景技术:
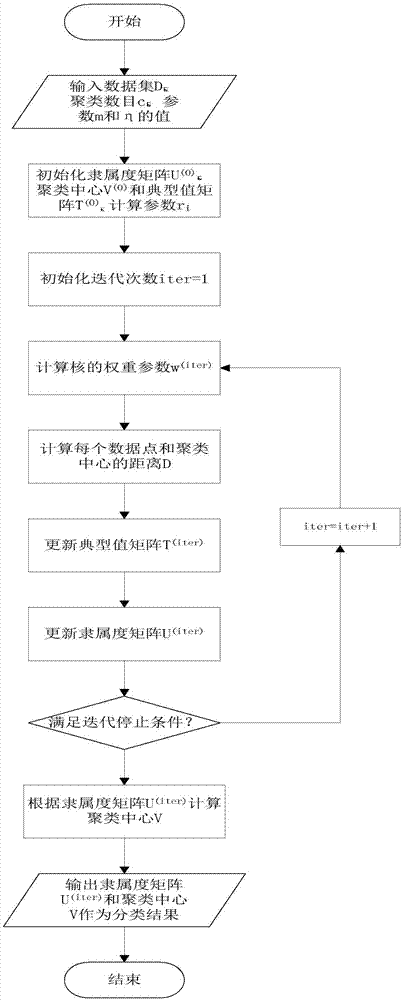
聚类是数据挖掘和人工智能领域重要的研究内容,在大数据、模式识别、图像分割、机器学习等诸多领域发挥了很大的作用。聚类就是根据数据的相似性规则对数据进行划分的过程,划分结果由规则决定,划分后的组或者集合,也常常称之为簇。模糊c均值聚类算法(fcm)是模糊聚类的一个最基本方法,为基于目标函数的聚类算法奠定了基础,但这个方法不仅对聚类中心初始化敏感,而且易受噪声点的影响。为了提高算法的抗噪性,krishnapuram和keller提出了pcm算法。pcm算法采用了可能性划分矩阵,可能性隶属度反映了数据点对某一聚类中心的典型度。另外,它放松了fcm算法中划分矩阵和为1的限制条件,相较fcm算法,pcm能更好地处理噪声点。然而pcm算法容易得到比预先设定的类别数还少的聚类中心或是相互重叠的类。基于以上原因zhang在文献中提出一种改进的可能性聚类算法聚类方式,增加一种新的参数ηi来减少算法的误差,虽然可能性的聚类算法能够克服一致性聚类的问题,然而对于原来的mp参数的选择异常敏感,不同的mp值即使相差很小,最后得到的聚类中心也会是两个截然不同的数值。nikhil提出的一种改进的可能性模糊c均值聚类算法pfcm,pfcm算法具有很好的噪声鲁棒性,也不会产生重合的聚类,然而pfcm算法对参数a和b的选择通常需要人为的指定而缺乏理论上的依据,具有较强的依赖性。以上算法对于线性数据具有很好的聚类效果,但是对于非线性数据的聚类往往效果不是很理想,通过引入核函数,将原始数据通过mercer核条件将样本数据x={x1,…,xn}映射到高维特征空间f中,映射数据为{φ(x1),...,φ(xn)},其中φ就是映射函数,并在空间f中对样本进行聚类,形成基于核的模糊聚类算法。yang提出了基于核的模糊聚类算法kfcm,genton也从统计学的角度展示了一种核的机器学习方式,这些算法使数据点映射到一个高维特征空间,通过使用内核函数和优化的聚类错误使其对于噪声和野值点具有很好的鲁棒性,克服了pfcm算法对参数设置敏感的问题,然而基于核的模糊聚类算法对于球形数据效果比较好,但是对于非球状数据往往得不到理想的效果。zhaoetal.先前在文献中提出多核的最大核的分割聚类算法多关注于监督以及半监督的聚类学习,这是基于最大限度的边际聚类,然而很明显的一个缺点是其聚类算法多用于硬聚类。hsin-chien提出的多核的核方法对基础内核的选择和组合提供了很大的灵活性,这也从不同的角度增加了信息源,另外这也提高了领域知识的编码能力,但这些多核聚类算法的一个缺点是,内核的权重的指数通常难以确定,很难实现良好的内核权重分配。技术实现要素:本发明为了克服上述现有技术存在的不足之处,提供一种基于双变加权核fcm算法的数据聚类方法,以期能准确地规避fcm对噪声点比较敏感,以及pcm容易产生一致性聚类的问题,增加算法的准确性,更准确地挖掘数据集中存在的数据结构信息。同时能自动发现最适合权重值以及当前隶属度值的大小,进而提高算法的可靠性和收敛性。为了实现上述发明目的,本发明采用如下技术方案:本发明基于双变加权核fcm算法的数据聚类方法,用于对客户信息进行聚类,根据聚类结果对客户进行产品推荐,其按如下步骤进行:步骤1、数据集合x为客户信息,x={x1,x2,…,xn},xj为第j个数据点;j=1,2,…,n,n是数据的总个数;对数据集合x进行最优划分,使得式(1)中的目标函数j值为最小:式(1)中,i表示第i类,c表示划分的类别数,且1≤i≤c,2≤c≤n;uij表示第j个数据点xj隶属于第i类的隶属度值;为uij的m次幂,m是表示聚类模糊程度的加权指数,tij表示第j个数据点xj隶属于第i类的可能性典型值,为tij的η次幂,η为加权指数,用于控制隶属度和典型值的比例实现双变;dij表示多核高维度特征空间的第j个数据点xj和多核高维度特征空间的第i类的聚类中心vi之间的距离,并有:式(2)中,wl是核的权重参数,m是核的总个数,αijk由式(3)所表达:式(3)中,kl(xj,xq)是由式(4)所表达的第l个高斯核函数:式(4)中的是函数的宽度参数,xjl,xql分别表示第j个数据点和第q个数据点的第l维特征值;式(1)中,表示第j个数据点xj的权重系数,并有:式(5)中,表示常数;xz表示第z个数据点,1≤z≤n;||xj-xz||表示第j个数据点xj和第z个数据点xz之间的欧式距离;式(1)中,ri表示惩罚因子,并有:式(6)中||xj-vi||表示第j个数据点和第i个聚类中心的欧式距离;步骤2、利用模糊c均值聚类算法fcm对所述数据集合x进行处理,获得隶属度矩阵u和聚类中心v分别为:由式(6)计算获得参数惩罚因子ri,并以利用模糊c均值聚类算法fcm获得的隶属度矩阵u作为双变加权核fcm算法的初始隶属度矩阵u(0);步骤3、随机初始化第j个数据点xj隶属于第i类的典型值定义迭代次数为iter,最大迭代次数为itermax;并初始化iter=1;则第iter次迭代的隶属度矩阵为u(iter),第iter次迭代的典型值矩阵为t(iter);步骤4、由式(3)得到参数步骤5、由式(7)得到参数βl:步骤6、由式(8)得到第iter次迭代的核的权重参数步骤7、由式(2)获得多核高维度特征空间的第j个数据点xj和多核高维度特征空间的第i类的聚类中心vi之间的距离dij的平方;步骤8、由式(9)获得第iter次迭代的第j个数据点xj隶属于第i类的典型值步骤9、由式(10)获得第iter次迭代的第j个数据点xj隶属于第i类的隶属度值步骤10、设定阈值ε,判断算法停止条件或iter>itermax是否成立,若成立,则为最优隶属度值,对于第j个数据点xj,取其最大值所对应的i值得到数据点xj属于第i类,根据得到的隶属度矩阵u(iter),得到所有属于第i类的数据点集合y,计算yj是第i类的数据点集合y中第j个数据,式是集合y的平均值,n′是属于第i类的数据点总个数,则第i类的聚类中心同样的方法获得其它类的聚类中心;根据聚类中心矩阵对新的客户进行产品推荐;若停止条件不成立,则将iter的值增加1,重复执行步骤4到步骤10直到满足条件为止。与已有技术相比,本发明的有益效果体现在:1、本发明双变加权核fcm聚类算法dwkfcm(weightedkernelfuzzyc-meanswithdoublevariables)采用多核的方法,集中了模糊聚类方法fcm的优点以及可能性聚类算法pcm的优点同时,减少了核函数的选择对于实验结果的影响,多核的聚类算法对于核函数的选择比较敏感,在多核的基础上面加入可能性的概念,使算法抗噪性更强,得到的聚类结果更准确。2、本发明dwkfcm采用的是基于核的算法能够进行非线性的数据运算,将普通数据过非线性运算映射到高维数据空间,增加了算法的鲁棒性,在本发明中核空间中数据点隶属于每一个聚类中心的比重是不同的。3、本发明dwkfcm将其延伸到软聚类方面去,将数据点的归属模糊化,同时考虑数据点的空间分布特征,通过计算数据点之间的距离来判断数据点对聚类中心的影响力,距离聚类中心越远影响力越小,因此,本方法灵活性更强。4、如今数据信息呈爆炸式增长,对数据进行聚类是进一步数据分析和知识挖掘的关键,因此,本发明具有良好的应用价值。附图说明图1为基于双变加权核fcm算法的数据聚类算法流程图;图2为鸢尾花数据集的sammon映射图。具体实施方式参见图1,本实施例中基于双变加权核fcm算法的数据聚类方法用于对客户信息进行聚类,根据聚类结果对客户进行产品推荐,按如下步骤进行:步骤1、数据集合x为客户信息,x={x1,x2,…,xn},xj为第j个数据点;j=1,2,…,n,n是数据的总个数,比如:采取10000个客户信息,即n=10000;对数据集合x进行最优划分,使得式(1)中的目标函数j值为最小:式(1)中,i表示第i类,c表示划分的类别数,即产品的种类,比如:c=10,1≤i≤c,2≤c≤n;uij表示第j个数据点xj隶属于第i类的隶属度值;为uij的m次幂,m是表示聚类模糊程度的加权指数,m可以取值为2,tij表示第j个数据点xj隶属于第i类的可能性典型值,为tij的η次幂,η为加权指数,用于控制隶属度和典型值的比例实现双变,η可以取值为2;dij表示多核高维度特征空间的第j个数据点xj和多核高维度特征空间的第i类的聚类中心vi之间的距离,并有:式(2)中,wl是核的权重参数,m是核的总个数,m的取值为客户信息的属性个数,比如:m=6,αijk由式(3)所表达:式(3)中,kl(xj,xq)是由式(4)所表达的第l个高斯核函数:式(4)中的是函数的宽度参数,是利用公式:得计算得到的值,xjl,xql分别表示第j个数据点和第q个数据点的第l维特征值;式(1)中,表示第j个数据点xj的权重系数,并有:式(5)中,表示常数,可以取值为2;xz表示第z个数据点,1≤z≤n;||xj-xz||表示第j个数据点xj和第z个数据点xz之间的欧式距离;式(1)中,ri表示惩罚因子,并有:式(6)中||xj-vi||表示第j个数据点和第i个聚类中心的欧式距离。步骤2、利用模糊c均值聚类算法fcm对数据集合x进行处理,获得隶属度矩阵u和聚类中心v分别为:由式(6)计算获得参数惩罚因子ri,并以利用模糊c均值聚类算法fcm获得的隶属度矩阵u作为双变加权核fcm算法的初始隶属度矩阵u(0)。步骤3、随机初始化第j个数据点xj隶属于第i类的典型值定义迭代次数为iter,最大迭代次数为itermax,可以设置最大迭代次数itermax为100;并初始化iter=1;则第iter次迭代的隶属度矩阵为u(iter),第iter次迭代的典型值矩阵为t(iter)。步骤4、由式(3)得到参数步骤5、由式(7)得到参数βl:步骤6、由式(8)得到第iter次迭代的核的权重参数步骤7、由式(2)获得多核高维度特征空间的第j个数据点xj和多核高维度特征空间的第i类的聚类中心vi之间的距离dij的平方。步骤8、由式(9)获得第iter次迭代的第j个数据点xj隶属于第i类的典型值步骤9、由式(10)获得第iter次迭代的第j个数据点xj隶属于第i类的隶属度值步骤10、设定阈值ε=0.00001,判断算法停止条件或iter>itermax是否成立,若成立,则为最优隶属度值,对于第j个数据点xj,取其最大值所对应的i值得到数据点xj属于第i类,根据得到的隶属度矩阵u(iter),得到所有属于第i类的数据点集合y,计算yj是第i类的数据点集合y中第j个数据,式是集合y的平均值,n′是属于第i类的数据点总个数,可以由所得集合y中的元素个数得到。则第i类的聚类中心同样的方法获得其它类的聚类中心;根据聚类中心矩阵对新的客户进行产品推荐;若停止条件不成立,则将iter的值增加1,重复执行步骤4到步骤10直到满足条件为止。本实施例以市场营销的“catalogmarketing”(目录市场)为研究对象,需要进行聚类的数据为客户信息,即以所有客户信息组成的集合作为待聚类的数据集,每一条客户信息包括年龄、收入、上网时长、性别、星座、消费品种等数值化的属性信息。采用本实施例中数据聚类方法对所有客户信息进行聚类,然后根据聚类结果对不同的客户进行特定产品推荐、定期发布同类人员购买物品等市场营销策略。本实施例中聚类方法基于如下实验平台完成:操作系统为windows7的pc机,集成开发环境为matlabr2015b。硬件条件为:cpu为intelcore3.20ghz,内存为8gb。算法中的参数m和η都设为2.0,最大迭代次数itermax=100。为了验证基于双变加权核fcm算法的数据聚类方法dwkfcm的性能,使用四个真实数据集:鸢尾花数据集、葡萄酒数据集、玻璃数据集和皮马印第安人的糖尿病数据集。这四个数据集的具体信息如表1所示。表1实验中用到的真实数据集信息总结分别利用本实施例聚类方法dwkfcm、模糊c-均值聚类算法fcm,可能性聚类算法pcm、可能性模糊聚类算法pfcm,基于核的模糊聚类算法kfcm和多核模糊聚类算法mkfc对以上各个数据集进行聚类。以聚类准确率cr作为聚类效果的评价标准,定义聚类准确率cr为:其中ai表示最终被正确分类的样本数目,c表示聚类数目,n表示数据集中的样本个数。聚类准确率越高,聚类方法的聚类效果越好。当cr的值为1时,说明算法在数据集上的聚类结果是完全正确的。鸢尾花数据集包含150个数据对象,每个数据对象由4个属性描述:花萼长度,花萼宽度,花瓣长度,花瓣宽度,算法要根据这4个属性预测鸢尾花卉属于(setosa,versicolour,virginica)三个种类中的哪一类。从图2的鸢尾花数据集的sammon映射图可以看出,该数据集有两类数据互相重叠了,不易划分,图中由“△”和“○”标示,这给聚类方法带来了很大的挑战。采用dwkfcm算法、fcm算法、pcm算法、pfcm算法、kfcm算法和mkfcm算法对鸢尾花数据集进行得到的聚类结果的准确率如表2所示。表2各算法在鸢尾花数据集上的聚类准确率算法聚类准确率(cr)fcm0.877pcm0.668pfcm0.808kfcm0.914mkfcm0.932dwkfcm0.959从表2中可以看出dwkfcm算法的准确率比fcm、pcm、pfcm、kfcm和mkfcm分别提高了8.2%、29.1%、15.1%、4.5%和2.7%。因此dwkfcm算法的性能是最好的。玻璃数据集是以玻璃材质为特征的数据集,包含214个数据对象,每个对象由9个属性表示,共可分为数量不等的6类。采用dwkfcm算法、fcm算法、pcm算法、pfcm算法、kfcm算法和mkfcm算法对玻璃数据集进行得到的聚类结果的准确率如表3所示。表3各算法在玻璃数据集上的聚类准确率算法聚类准确率(cr)fcm0.813pcm0.739pfcm0.846kfcm0.888mkfcm0.901dwkfcm0.953表3的聚类结果表明,dwkfcm算法的聚类准确率比fcm、pcm、pfcm、kfcm和mkfcm分别提高了14%、21.4%、10.7%、6.5%和5.2%。因此dwkfcm算法的性能更好。葡萄酒数据集是以葡萄酒的成分分析为特征的数据集,包含178个数据,每个数据包含13个属性,分为3类,相比鸢尾花和玻璃数据集其属性的个数是最多的。采用dwkfcm算法、fcm算法、pcm算法、pfcm算法、kfcm算法和mkfcm算法对葡萄酒数据集进行得到的聚类结果的准确率如表4所示。表4各算法在葡萄酒数据集上的聚类准确率算法聚类准确率(cr)fcm0.708pcm0.409pfcm0.688kfcm0.777mkfcm0.841dwkfcm0.925表4的聚类结果表明,dwkfcm算法的聚类准确率比fcm、pcm、pfcm、kfcm和mkfcm分别提高了21.7%、51.6%、23.7%、14.8%和8.4%。因此dwkfcm算法的性能更好。糖尿病数据集是一种糖尿病诊断数据集,属于医学领域。该数据集包含768个实例,每个实例含有8个属性:孕次(pregnanttimes)、餐后2h内血浆葡萄糖浓度(plasmaglucoseconcentration)、舒张期血压mmhg(diastolicbloodpressure)、皮肤皱裂厚度mm(tricepsskinfoldthickness)、血清胰岛素muu/ml(seruminsulin)、体重指数(bodymassindex)、家族病史(pedigreefunction)、年龄(age)。算法根据这8个属性判断看病者是否患有糖尿病。该数据集共500组没有患病的数据组和268组患病者数据统计。采用dwkfcm算法、fcm算法、pcm算法、pfcm算法、kfcm算法和mkfcm算法对糖尿病数据集进行得到的聚类结果的准确率如表5所示。表5各算法在糖尿病数据集上的聚类准确率算法聚类准确率(cr)fcm0.582pcm0.355pfcm0.754kfcm0.773mkfcm0.831dwkfcm0.934从表5中可以看出,本发明dwkfcm对糖尿病数据集中糖尿病的诊断可以达到93.4%的准确率,而其它算法的准确率都低于90%,pcm算法甚至只有35.5%的聚类准确率。表5的聚类结果表明,dwkfcm算法的聚类准确率比fcm、pcm、pfcm、kfcm和mkfcm分别提高了35.2%、57.9%、18%、16.1%和10.3%。因此dwkfcm算法的性能更好。本发明双变加权核模糊c均值聚类算法dwkfcm可以很好地应用于市场营销、花卉、葡糖酒、玻璃的分类以及糖尿病的诊断等领域,可靠挖掘数据中存在的信息,具有很高的实用性。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1