一种基于PSoC的卷积神经网络加速器的制作方法
本发明涉及卷积神经网络结构技术,特别涉及一种基于psoc的卷积神经网络加速器。
背景技术
卷积神经网络以局部权重共享在图像处理具有独特的优越性,其布局更接近实际的生物神经网络、共享权重降低了神经网络的复杂度,降低了神经网络的计算量。目前卷积神经网络在视频监控、机器视觉、模式识别、图像搜索等领域广泛应用。
但是卷积网络硬件实现需要大量硬件资源,带宽利用率低及数据复用低等问题。卷积神经网络中需要支持不同大小的卷积操作,池化操作及全连接操作,同时许多卷积神经网络应用中,通常包含图片处理部分,因此fpga(现场可编程门阵列,fieldprogrammablegatearray)纯粹的硬件逻辑实现限制了扩展性。对于卷积神经网络的实现来说,硬件实现的网络是固定的,带宽利用率低,无法扩展支持其他结构的卷积神经网络。psoc器件具有硬件可编程部分以及软件编程的特性,被认为是实现卷积神经网络合适的平台。
技术实现要素:
本发明的目的在于克服现有技术的缺点与不足,提供一种基于psoc的卷积神经网络加速器,将整个神经网络加速器硬件可编程部分可简化为乘加计算模块、激活函数模块、最大值池化模块和平均值池化模块。所有的乘加计算模块中的乘加运算都是并行计算的,支持不同卷积核大小的卷积计算,解决卷进神经网络计算量大,带宽要求大的问题。软件部分解决硬件逻辑无法实现的softmax分类器和非极大值抑制算法以及图像处理算法,以及解决不同网络结构的卷积神经网络的配置。
本发明的目的通过下述技术方案实现:一种基于psoc的卷积神经网络加速器,其特征在于,包括:片外存储器、cpu、特征图输入存储器、特征图输出存储器、偏置存储器、权重存储器、直接内存存取dma和与神经元数目相同的计算单元,
所述直接内存存储dma在cpu的控制下从片外存储器读取传输到特征图输入存储器、偏置存储器和权重存储器,或将特征图数据存储器的数据写回到片外存储器,cpu需要控制输入特征图、偏置、权重、输出特征图在片外存储器的存储位置,以及多层的卷积神经网络的参数传输,以适应多种架构的神经网络。
进一步地,所述计算单元包括先入先出队列、状态机、第一数据选择器、第二数据选择器、平均值池化模块、最大值池化模块、乘加计算模块和激活函数模块,
其中所述第一数据选择器与特征图输入存储器通信,输入特征图输入数据经过第一数据选择器输入到平均值池化模块、最大值池化模块、乘加计算模块和激活函数模块,
所述第二数据选择器与特征图输出存储器通信,平均值池化模块、最大值池化模块和乘加计算模块的输出结果经过所述第二数据选择器选择输出到特征图输出存储器。
进一步地,所述乘加计算模块为基于乘法加法树和乘加寄存器结合的结构,包括输入特征图矩阵、权重输入矩阵和偏置矩阵。
进一步地,所述激活函数模块包括第一配置寄存器、第一选择器、第一乘法器和第一加法器,用于实现正切函数,sigmoid函数和relu函数,cpu配置所述激活函数模块的第一配置寄存器,通过硬件逻辑实现激活函数。
进一步地,所述平均值池化模块包括第二配置寄存器、第二乘法器和第二加法器,通过cpu配置所述平均值池化模块,实现矩阵平均值池化,得到矩阵平均值。
进一步地,所述最大值池化模块包括第三配置寄存器、比较器和第二选择器,通过cpu配置所述最大值池化模块,实现矩阵最大值池化,比较矩阵中的每一个数据以得出最大值。
本发明相对于现有技术具有如下的优点及效果:通过将整个卷积神经网络在cpu的控制下进行数据的存储分配和数据传输,状态机控制下数据选择器进行数据分配,传输至乘加计算模块、激活函数计算模块、最大值池化模块和平均值池化模块,同时cpu进行图像处理、softmax分类器和非极大值抑制算法等算法,所述乘加计算模块内的计算是并行的,完成卷积操作,非线性函数操作,最大值池化以及平均值池化,解决卷积神经网络计算量大的问题,提高并行处理效率,减少带宽需求,实现可配置支持不同结构的卷积神经网络算法。
附图说明
图1是本发明的一种基于psoc的卷积神经网络加速器结构图;
图2是本发明的乘加计算模块结构图;
图3是本发明的激活函数模块结构图;
图4是本发明的平均值池化模块结构图;
图5是本发明的最大值池化模块结构图;
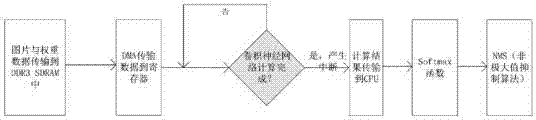
图6是本发明的cpu软件流程图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例一
为提高卷积神经网络计算量大,提高并行处理效率,降低带宽需求,本发明提供如图1所示的一种基于psoc的卷积神经网络加速器100,包括:片外存储器101、cpu102、特征图输入存储器103、特征图输出存储器104、偏置存储器105、权重存储器106、直接内存存取dma107和与神经元数目相同的计算单元108。
直接内存存储dma107在cpu102的控制下从片外存储器101读取传输到特征图输入存储器103、偏置存储器105和权重存储器106,或将特征图输出存储器104的数据写回到片外存储器101。cpu102需要控制输入特征图、偏置、权重、输出特征图在片外存储器的存储位置,以及多层的卷积神经网络的参数传输,以适应多种架构的神经网络。
与神经元数目相同的计算单元108包括先入先出队列、状态机109、第一数据选择器110、第二数据选择器111、平均值池化模块112、最大值池化模块113、乘加计算模块114和激活函数模块115,其中所述第一数据选择器110与特征图输入存储器103通信,输入特征图输入数据经过第一数据选择器110输入到平均值池化模块112、最大值池化模块113、乘加计算模块114和激活函数模块115,所述第二数据选择器111与特征图输出存储器104通信,平均值池化模块112、最大值池化模块113和乘加计算模块114的输出结果经过所述第二数据选择器111选择输出到特征图输出存储器104。
如图2所示,乘加计算模块为基于乘法加法树和乘加寄存器结合的结构,包括输入特征图矩阵、权重输入矩阵和偏置矩阵。这种结构可实现卷积操作并行高效完成,且实现不同大小卷积核时不会降低乘法器利用率。
如图3所示,激活函数模块包括第一配置寄存器、第一选择器、第一乘法器和第一加法器,用于实现正切函数,sigmoid函数和relu函数,cpu配置所述激活函数模块的第一配置寄存器,通过硬件逻辑实现激活函数。
如图4所示,平均值池化模块包括第二配置寄存器、第二乘法器和第二加法器。通过cpu配置平均值池化模块,m值可配置,实现m*m平均值池化,得到m*m矩阵平均值。
如图5所示,最大值池化模块包括第三配置寄存器、比较器和第二选择器。通过cpu配置最大值池化模块,k值可配置,实现k*k最大值池化,比较k*k矩阵中的每一个数据,得出最大值。
实施例二
相应地,本发明还结合图6进一步描述了基于psoc的卷积神经网络加速器进行卷积神经网络计算的方法流程。
cpu可在嵌入式软件中进行编程,在软件编程中实现深度卷积神经网络的构建,输入相关处理器通过总线配置传输命令值控制寄存器。
配置命令实例如下表所示:
第一层输入为有x1个输入特征图数据,x3个权重数据数据,经过计算结果输入到最大值池化模块和激活函数模块,得到x2个输出特征图数据。
卷积层输出特征图在片外存储器的存储形式具有m层,m取值为1,3,5,7……。第m层的输出特征图为第m+1层的输入特征图,第m层输出特征图存储在以地址a1为起始地址的地址空间,第m+1层输出特征图存储位置在以地址a2位起始地址的地址空间。
在具体应用中,卷积神经网络层内的计算是并行执行的。整个网络执行过程如下:
(1)处理器102软件控制图像处理,样本数据存放到片外存储器101;
(2)处理器102控制dma107读取片外存储数据到第一数据选择器110,同时通过处理器102配置乘加计算单元114,平均值池化模块112,最大值池化模块113,激活函数模块115和状态机109。配置信息包括但不仅是卷积计算步长,卷积核大小,激活函数类型,平均值池化的大小,最大值池化模块大小。
(3)通过状态机109的控制下,数据从dma传输数据到特征图输入存储器103,偏置存储器105,权重存储器106。
(4)数据输入到乘加计算单元114,激活函数模块115,平均值池化模块112或最大值池化模块113,得到计算结果。
(5)在状态机控制下,数据从乘加计算单元114,激活函数115,平均值池化模块112或最大值池化模块113传输到数据选择器中,并传输到片外存储器101。
至此,整个网络计算完成一层的结果,网络循环完成多层的计算结果。
总之,本发明通过将整个卷积神经网络加速器硬件可编程部分可简化为乘加计算模块、激活函数模块、最大值池化模块和平均值池化模块,所有的乘加计算模块中的乘加运算都是并行计算的,支持不同卷积核大小的卷积计算,支持配置不同大小的池化计算,卷积神经网络加速器的cpu软件设计实现硬件逻辑无法实现的softmax分类器和非极大值抑制算法以及配置支持不同网络结构的卷积神经网络,完成卷积神经网络计算,解决卷进神经网络计算量大,带宽要求大的问题,实现可配置支持不同结构的卷积神经网络算法。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!