一种网站相似度检测方法与流程
本发明信息安全检测技术领域,尤其涉及一种网站相似度检测方法。
背景技术
现有技术中,常常会出现与正规网站相同页面内容的钓鱼网站,而这些网站仿冒正规网站的域名(url)地址以及页面内容,或者利用真实网站服务器程序上的漏洞在站点的某些网页中插入危险的javascript代码,以此来骗取用户银行或信用卡账号、密码等私人资料,使用户受到经济上的损失。目前钓鱼网站的检测识别成为web安全领域重要研究内容。判断一个网站是否是钓鱼网站,一个重要的途径是验证该网站是否跟某个真实网站在视觉效果或内容上具有相似性。但是如果若通过人工进行鉴别,则效率低,无法基于海量网站中快速查找出钓鱼网站。
因此,现有技术有待于进一步的改进。
技术实现要素:
鉴于上述现有技术中的不足之处,本发明的目的在于为用户提供一种网站相似度检测方法,克服现有技术中基于人工进行钓鱼网站的查找和识别的缺陷。
本发明公开了一种网站相似度检测方法,其中,所述方法包括:
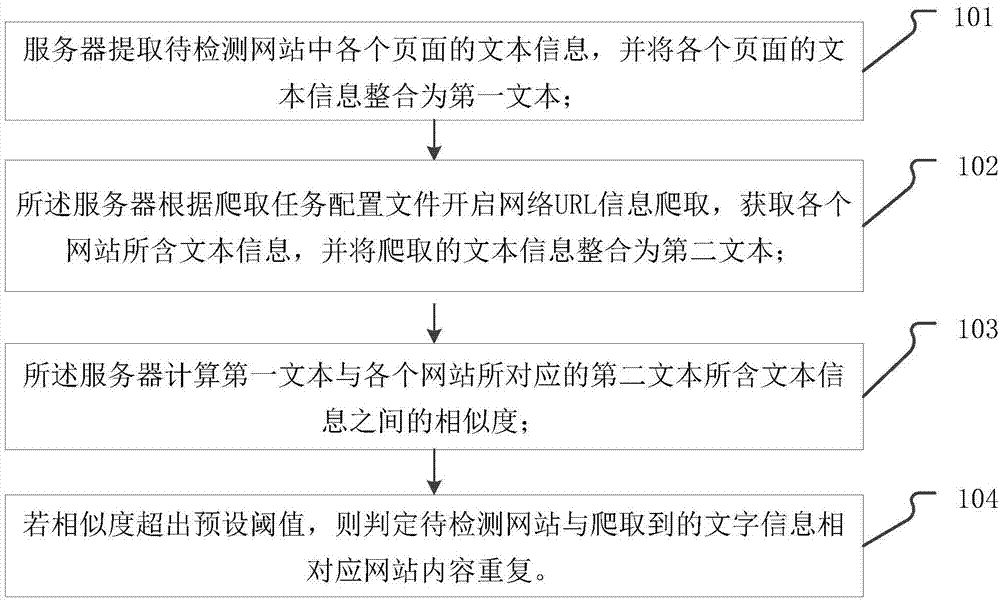
服务器提取待检测网站中各个页面的文本信息,并将各个页面的文本信息整合为第一文本;
所述服务器根据爬取任务配置文件开启网络url信息爬取,获取各个网站所含文本信息,并将爬取的文本信息整合为第二文本;
所述服务器计算第一文本与各个网站所对应的第二文本所含文本信息之间的相似度;
若相似度超出预设阈值,则判定待检测网站与爬取到的文字信息相对应网站内容重复。
可选的,将第一文本中各个网页所含文本块与第二文本中各个网页所含文本块之间相似度的权值作为所述第一文本与第二文本之间的相似度。
可选的,服务器计算第一文本中各个文本块与第二文本中相对应文本块之间的相似度的权值步骤包括:
所述服务器对所述第一文本中的文本块进行拆解得到若干候选句子;
所述服务器确定各候选句子的重要性分数;
所述服务器提取重要性分数大于预设值的目标句子作为所述第一文本的关键信息;
所述服务器将所述第一文本的关键信息与各个第二文本中相对应文本块的关键信息进行对比得出各个文本块之间相似度;
将各个文本块之间的相似度进行加权得到文本块之间相似度的权值。
可选的,所述服务器对所述第一文本进行拆解得到若干候选句子的步骤中,对第一文本中的文本块进行拆分的方法为:
按照标点符号进行拆解;其中,所述标点符号为分号、逗号、句号时,进行拆解,当标点符号为顿号、冒号、引号时,不进行拆解。
可选的,所述服务器确定各候选句子的重要性分数的步骤包括:
判断所述候选句子中是否包含中文句子和/或网页链接地址;
若仅仅含有中文句子,则将中文句子中各词组的权值之和作为所述候选句子的重要性分数;
若仅仅含有网页链接地址,则将所述网页链接地址对应网页中所含页面元素的权值之和作为所述候选句子的重要性分数;
若同时含有中文句子和网页链接地址,则将中文句子中各词组的权值之和和网页链接地址所对应网页中所含页面元素的权值之和的加权平均值作为所述候选句子的重要性分数。
可选的,所述将中文句子中各词组的权值之和作为所述候选句子的重要性分数的步骤包括:
按照语义分析的方式再将每个候选句子拆分为若干个词组;
进行全文检索,计算各词组出现的次数;
按照出现次数由高到低的顺序对各词组进行排序,每个词组按照出现次数赋予相应的权值,出现次数越高,权值越高;
根据各词组的权值,计算各候选句子的重要性分数,该重要性分数即为该候选句子中各词组的权值之和。
可选的,所述将所述网页链接地址对应网页中所含页面元素的权值之和作为所述候选句子的重要性分数步骤包括:
服务器后台开启该网页链接地址对应的目标网页;
服务器根据该目标网页中所含页面元素确定所述目标网页的重要性分数。
可选的,所述服务器根据该目标网页中所含页面元素确定所述目标网页的重要性分数的步骤包括:
使用下面的公式确定目标网页的重要性分数;
其中,s(vi)是目标网页的重要性分数,d是阻尼系数,一般设置为0.85,in(vi)是存在指向目标网页的链接的网页集合。out(vj)是网页j中的链接存在的链接指向的网页集合,out(vj)取绝对值是用以表示该网页集合中元素的个数,s(vj)是网页j的重要性分数。
可选的,所述服务器将所述第一文本的关键信息与第二文本的关键信息进行相似度对比的步骤包括:
计算第一文本的关键信息中的第一句子与第二文本的关键信息中的第二句子的余弦相似度;
若余弦相似度高于预设值,则确定第一文本与第二文本近似。
可选的,所述余弦相似度的计算方法为:
将第一句子拆分为若干个词组;
将第二句子拆分为若干个词组;
将两组词组进行逐一对比,若存在,则记录为1,若不存在,则记录为0,得到第一序列和第二序列;
计算第一序列和第二序列之间的余弦相似度,并作为第一句子和第二句子之间的余弦相似度。
有益效果,本发明提供了一种网站相似度检测方法,通过服务器提取待检测网站中各个页面的文本信息,并将各个页面的文本信息整合为第一文本;所述服务器根据爬取任务配置文件开启网络url信息爬取,获取各个网站所含文本信息,并将爬取的文本信息整合为第二文本;所述服务器计算第一文本与各个网站所对应的第二文本所含文本信息之间的相似度;若相似度超出预设阈值,则判定待检测网站与爬取到的文字信息相对应网站内容重复。对判定出的相同内容网站进行辨别,确认出是否为钓鱼网站。本发明公开的网站相似度检测方法,在现有技术的基础上,增加了网站信息智能爬取和爬取信息的相似度匹配的步骤,提高了钓鱼网站的快速识别。
附图说明
图1为本发明所公开的一种网站相似度检测方法的具体实施例步骤流程图。
具体实施方式
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明公开了一种网站相似度检测方法,如图1所示,所述方法包括:
步骤s101、服务器提取待检测网站中各个页面的文本信息,并将各个页面的文本信息整合为第一文本。
针对可能会被信息抄袭,导致用户信息丢失的网站,本步骤中通过输入网站网址信息的方式,向服务器发出检测互联网内是否存在与该网址所对应网站内容相雷同的网站,因此到服务器接收到检测申请后,首先根据用户输入的网站网址获取该网站各个页面的文本信息,并将获取到的文本信息整合为第一文本。
步骤s102、所述服务器根据爬取任务配置文件开启网络url信息爬取,获取各个网站所含文本信息,并将爬取的文本信息整合为第二文本。、
根据上述步骤中获取的第一文本,设置爬取任务配置文件,该任务配置文件中含有爬取与第一文本相似内容的任务,则服务器根据所述配置文件,获取与第一文本内容相似的网站中含有的页面信息,并将页面信息整合为第二文本。
步骤s103、所述服务器计算第一文本与各个网站所对应的第二文本所含文本信息之间的相似度。
服务器计算第一文本与第二文本之间的相似度,根据相似度的结果判断内容是否相同,具体的,在本步骤中将第一文本中各个网页所含文本块与第二文本中各个网页所含文本块之间相似度的权值作为所述第一文本与第二文本之间的相似度。
步骤s104、若相似度超出预设阈值,则判定待检测网站与爬取到的文字信息相对应网站内容重复。
若第一文本中所含的文本块内容与第二文本中所含文本块的内容相同,则判断为内容相同的网站,则该查找出的网站疑似为钓鱼网站,将其输出,用户对其进行进一步确认,最终确定是否为钓鱼网站。
进一步的,服务器计算第一文本中各个文本块与第二文本中相对应文本块之间的相似度的权值步骤包括:
所述服务器对所述第一文本中的文本块进行拆解得到若干候选句子;
所述服务器确定各候选句子的重要性分数;
所述服务器提取重要性分数大于预设值的目标句子作为所述第一文本的关键信息;
所述服务器将所述第一文本的关键信息与各个第二文本中相对应文本块的关键信息进行对比得出各个文本块之间相似度;
将各个文本块之间的相似度进行加权得到文本块之间相似度的权值。
在具体实施例中,所述服务器对所述第一文本进行拆解得到若干候选句子的步骤中,对第一文本进行拆分的方法为:
按照标点符号进行拆解;其中,所述标点符号为分号、逗号、句号时,进行拆解,当标点符号为顿号、冒号、引号时,不进行拆解。
所述服务器确定各候选句子的重要性分数;
所述服务器提取重要性分数大于预设值的目标句子作为所述第一文本的关键信息;
所述服务器将所述第一文本的关键信息与第二文本的关键信息进行相似度对比,并将比对出的相似度值判定为所述第一文本与第二文本之间的相似度值。
进一步的,由于各个候选句子中可能包含不同属性的信息,也即是候选句子可能含有中文句子或者网页链接地址,所以在进行重要性分数的计算之前,所述服务器确定各候选句子的重要性分数的步骤包括:
判断所述候选句子中是否包含中文句子和/或网页链接地址;
若仅仅含有中文句子,则将中文句子中各词组的权值之和作为所述候选句子的重要性分数;
若仅仅含有网页链接地址,则将所述网页链接地址对应网页中所含页面元素的权值之和作为所述候选句子的重要性分数;
若同时含有中文句子和网页链接地址,则将中文句子中各词组的权值之和和网页链接地址所对应网页中所含页面元素的权值之和的加权平均值作为所述候选句子的重要性分数。
所述将中文句子中各词组的权值之和作为所述候选句子的重要性分数的步骤包括:
按照语义分析的方式再将每个候选句子拆分为若干个词组;
进行全文检索,计算各词组出现的次数;
按照出现次数由高到低的顺序对各词组进行排序,每个词组按照出现次数赋予相应的权值,出现次数越高,权值越高;
根据各词组的权值,计算各候选句子的重要性分数,该重要性分数即为该候选句子中各词组的权值之和。
例如,有一篇论文中含有以下内容:
今天xx协会在北京召开了工作会议,天气不错,大概有30摄氏度,没有下雨,交通情况也良好,在工作会议上,张会长对xx协会去年的工作进行了总结,还表彰了xx协会的优秀员工。
候选句子包括:
a、今天xx协会在北京召开了工作会议;
b、天气不错;
c、大概有30摄氏度;
d、没有下雨;
e、交通情况也良好;
f、在工作会议上;
g、张会长对xx协会去年的工作进行了总结;
h、还表彰了xx协会的优秀员工。
拆解得到的词组包括:
今天:出现1次,权值为1
xx协会:出现3次,权值为3
北京:1次,权值为1
召开:1次,权值为1
工作会议:2次,权值为2
天气:1次,权值为1
30摄氏度:1次,权值为1
下雨:1次,权值为1
交通情况:1次,权值为1
张会长:1次,权值为1
去年的工作:1次,权值为1
总结:1次,权值为1
表彰:1次,权值为1
优秀员工:1次,权值为1
则上面的候选句子的重要性分数分别为:a号8分,b号1分,c号1分,d号1分,e号1分,f号2分,g号6分,h号5分。
假设预设值为2分,则目标句子为a号,f号,g号和h号,最后的关键信息为:今天xx协会在北京召开了工作会议;在工作会议上;张会长对xx协会去年的工作进行了总结;还表彰了xx协会的优秀员工。
进一步的,所述将所述网页链接地址对应网页中所含页面元素的权值之和作为所述候选句子的重要性分数步骤包括:
服务器后台开启该网页链接地址对应的目标网页;
服务器根据该目标网页中所含页面元素确定所述目标网页的重要性分数。
所述服务器根据该目标网页中所含页面元素确定所述目标网页的重要性分数的步骤包括:
使用下面的公式确定目标网页的重要性分数;
其中,s(vi)是目标网页的重要性分数,d是阻尼系数,一般设置为0.85,in(vi)是存在指向目标网页的链接的网页集合。out(vj)是网页j中的链接存在的链接指向的网页集合,out(vj)取绝对值是用以表示该网页集合中元素的个数,s(vj)是网页j的重要性分数。
具体的,所述服务器将所述第一文本的关键信息与第二文本的关键信息进行相似度对比的步骤包括:
计算第一文本的关键信息中的第一句子与第二文本的关键信息中的第二句子的余弦相似度;
若余弦相似度高于预设值,则确定第一文本与第二文本近似。
具体的,所述余弦相似度的计算方法为:
将第一句子拆分为若干个词组;
将第二句子拆分为若干个词组;
将两组词组进行逐一对比,若存在,则记录为1,若不存在,则记录为0,得到第一序列和第二序列;
计算第一序列和第二序列之间的余弦相似度,并作为第一句子和第二句子之间的余弦相似度。
例如:
第一句子为:今天协会在北京召开会议。
第二句子为:协会在北京召开了普法会议。
则第一序列a为(1,1,1,1,0,1),第二序列b为(0,1,1,1,1,1)。
较佳的,本方法步骤中使用以下公式所述计算第一序列和第二序列之间的余弦相似度的计算:
其中,ab表示a序列的中元素与b序列中相应的元素相乘后整体相加,分母表示a序列中所有元素的平方和开根号后乘以a序列中所有元素的平方和开根号。
例如,上述两个句子计算的结果为:
最终的计算结果为:0.8。
本发明提供了一种网站相似度检测方法,通过服务器提取待检测网站中各个页面的文本信息,并将各个页面的文本信息整合为第一文本;所述服务器根据爬取任务配置文件开启网络url信息爬取,获取各个网站所含文本信息,并将爬取的文本信息整合为第二文本;所述服务器计算第一文本与各个网站所对应的第二文本所含文本信息之间的相似度;若相似度超出预设阈值,则判定待检测网站与爬取到的文字信息相对应网站内容重复。对判定出的相同内容网站进行辨别,确认出是否为钓鱼网站。本发明公开的网站相似度检测方法,在现有技术的基础上,增加了网站信息智能爬取和爬取信息的相似度匹配的步骤,提高了钓鱼网站的快速识别。
可以理解的是,对本领域普通技术人员来说,可以根据本发明的技术方案及其发明构思加以等同替换或改变,而所有这些改变或替换都应属于本发明所附的权利要求的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!