一种基于语义相似度的自动问答文本匹配方法、自动问答方法和系统与流程
本发明涉及一种基于语义相似度的自动问答文本匹配方法、自动问答方法和系统,涉及智能客服领域。
背景技术
现有技术中,对话系统大体上可以分为三大类:闲聊型对话系统(chitchat-bot)、检索型对话系统(ir-bot)、任务型对话系统(task-bot)。随着人工智能的发展,对话系统的研究也取得了不同程度的成果,有的已经成功运用于各行各业。然而,部分行业的咨询自动问答系统并不多见,大多效果不理想,常常出现“答非所问”的现象,无法知晓用户意图,难以很好地实现问答匹配,降低了系统的准确率和招回率,对用户体验造成了伤害。
有鉴于此,本发明人专门设计了一种基于语义相似度的自动问答文本匹配方法、自动问答方法和系统,本案由此产生。
技术实现要素:
本发明提供了一种基于语义相似度的自动问答文本匹配方法,具有能够更准确地实现问答匹配,便于更准确地识别用户意图,匹配相应回答模板的特点。
本发明还提供了一种基于语义相似度的自动问答方法及系统,具有能够更准确地识别用户意图,匹配相应回答模板的特点。
根据本发明提供的一种基于语义相似度的自动问答文本匹配方法,具体方法包括,
对文本进行分词操作,对文本中的语句进行分词;
对文本进行去停词操作,去除文本中的停用词,保留非停用词;
按照文本词性对每个词赋予权重,根据每个词的重要级别进行分类,级别越高权重越高,级别越低权重越低;
文本中每个词的加权词向量表示为:t=v*w;
文本相似度匹配,设文本a中每个词的加权词向量为a1,a2,...,an,文本b中每个词的加权词向量为b1,b2,...,bm,则文本a与b的相似度为:
其中,v为词向量,w为词向量权重,n与m分别代表文本a、b中词的个数,i与j分别表示文本a、b中的某个词的顺序下标。
所述重要级别由高到低包括核心、次核心、一般和不重要;其中,核心级别的字和/或词包括句子主干中的名词;次核心级别的字和/或词包括句子主干中的动词;一般级别的字和/或词包括代词、形容词和副词;不重要级别的字和/或词包括助词、标点、未知符号和语气词。
所述方法还包括,把未分类的其他词性的词设置为一般级别的字和/或词。
其中,核心级别的字和/或词权重为3;次核心级别的字和/或词权重为2;一般级别的字和/或词权重为1;不重要级别的字和/或词权重为0。
所述方法还包括,把未分类的其他词性的词设置权重为1。
根据本发明提供的一种基于语义相似度的自动问答文本匹配方法,采用上述自动问答文本匹配方法,应用于整形咨询自动问答匹配方法。
根据本发明提供的一种基于语义相似度的自动问答方法,具体方法包括,在基于上述自动问答文本匹配方法的基础上进行匹配模型训练,基于训练好的模型,对问答对进行整理,实现用户的意图识别,匹配模板,给出相应回答。
根据本发明提供的一种基于语义相似度的自动问答系统,其特征在于,包括客户端和服务端;其中服务端在基于上述自动问答文本匹配方法的基础上进行匹配模型训练,基于训练好的模型,对问答对进行整理,实现用户的意图识别,匹配模板,给出相应回答。
与现有技术相比,本发明能够更准确地实现问答匹配,可更加准确地识别用户意图,从而匹配相应的回答模板,避免出现“答非所问”的现象,令对话系统更加更加顺畅和智能化,满足人工智能的需求,大大提升了用户的体验。
附图说明
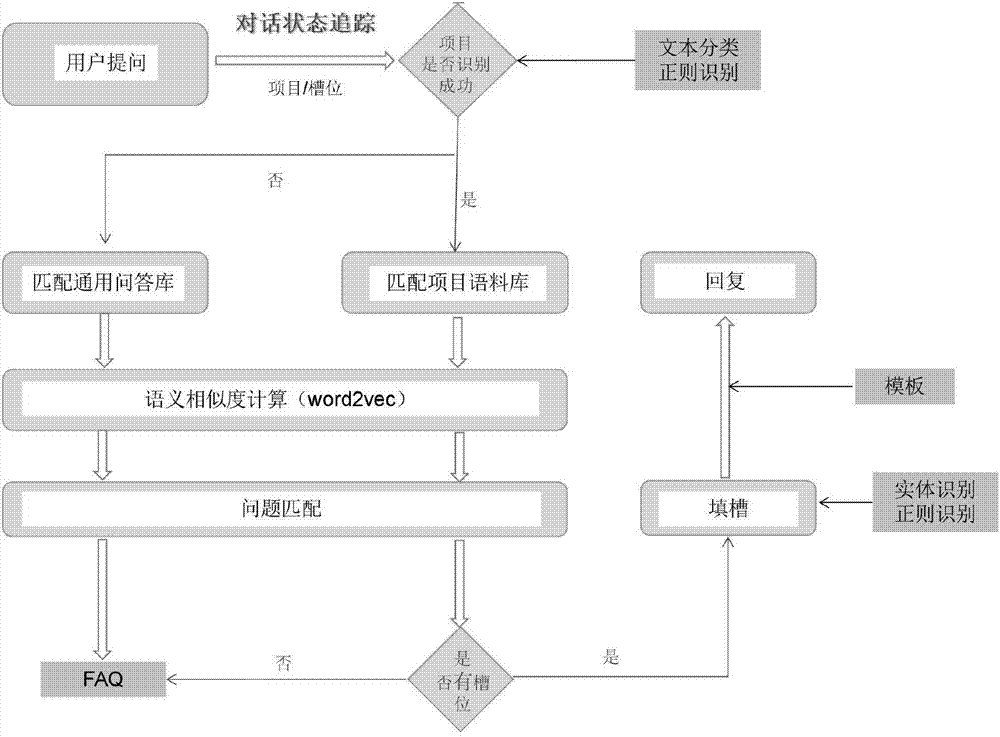
图1为本发明其中一实施例的自动问答方法实现示意图。
具体实施方式
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合实施例和附图,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
本说明书(包括摘要和附图)中公开的任一特征,除非特别叙述,均可被其他等效或者具有类似目的的替代特征加以替换。即,除非特别叙述,每个特征只是一系列等效或类似特征中的一个例子而已。
一种基于语义相似度的自动问答文本匹配方法,具体方法包括,
对文本进行分词操作,对文本中的语句进行分词;
对文本进行去停词操作,去除文本中的停用词,保留非停用词;
按照文本词性对每个词赋予权重,根据每个词的重要级别进行分类,级别越高权重越高,级别越低权重越低;
文本中每个词的加权词向量表示为:t=v*w;
文本相似度匹配,设文本a中每个词的加权词向量为a1,a2,...,an,文本b中每个词的加权词向量为b1,b2,...,bm,则文本a与b的相似度为:
其中,v为词向量,w为词向量权重,n与m分别表示文本a、b中词的个数,i与j分别表示文本a、b中的某个词的顺序下标。
停词,即停用词,是指在信息检索中,为节省存储孔家和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为stopwords(停用词)。
作为本发明的一种具体实施方式,所述重要级别由高到低包括核心、次核心、一般和不重要;其中,核心级别的字和/或词包括句子主干中的名词;次核心级别的字和/或词包括句子主干中的动词;一般级别的字和/或词包括代词、形容词和副词;不重要级别的字和/或词包括助词、标点、未知符号和语气词。
作为本发明的一种具体实施方式,所述方法还包括,把未分类的其他词性的词设置为一般级别的字和/或词。
其中,核心级别的字和/或词权重为3;次核心级别的字和/或词权重为2;一般级别的字和/或词权重为1;不重要级别的字和/或词权重为0。
所述方法还包括,把未分类的其他词性的词设置权重为1。
一种基于语义相似度的自动问答文本匹配方法,采用上述自动问答文本匹配方法,应用于整形咨询自动问答匹配方法。
作为本发明的一个具体实施方式,假设文本a:你们医院地址在哪?文本b:请问医院的地址是?
分词后结果:
a:你们医院地址在哪
b:请问医院地址是
去停用词结果:
a:你们医院地址
b:请问医院地址
按照词性赋予每个词权重:
假设每个词的词向量已经训练出来,每个词的加权词向量为:
则文本a中词的加权词向量为v你们,3v医院,3v地址,b中词的加权词向量为2v请问,3v医院,3v地址。
文本a、b的相似度:
sim(a,b)=0.5*(max{v你们*2v请问,v你们*3v医院,v你们*3v地址}
+max{3v医院*2v请问,3v医院*3v医院,3v医院*3v地址}
+max{3v地址*2v请问,3v地址*3v医院,3v地址*3v地址})
+0.5*(max{2v请问*v你们,2v请问*3v医院,2v请问*3v地址}
+max{3v医院*v你们,3v医院*3v医院,3v医院*3v地址}
+max{3v地址*v你们,3v地址*3v医院,3v地址*3v地址})
在本具体实施例中,n表示名词,r表示代词,v表示动词。
本发明还提供了一种基于语义相似度的自动问答方法,具体方法包括,在基于上述自动问答文本匹配方法的基础上进行匹配模型训练,基于训练好的模型,对问答对进行整理,实现用户的意图识别,匹配模板,给出相应回答。
问题可答题归为两类,通用问题与专业问题。通用问题如询问医院地址、医院上班时间等,此类问题可以直接进行faq匹配,给出统一的回答;专业问题如割双眼皮多少钱、手术要多久、是永久的吗?此类问题需要先明确整形项目、整形方式等信息后才能给出回答。这些待明确的信息称为槽位,也就是说在回答相关问题时需要先填充槽位,即填槽。
如图1所示,无论是回答通用问题还是专业问题,都需要有相关的真实语料作为支撑,不能凭空制造答案。因此,有一份高质量的问答对语料显得尤其重要。首先按照问题类别对问题归类,然后分别整理问答对。通用问题的答案可以唯一,但是为了答案的丰富性,可以对统一答案作多种形式的表达,然后随机给出;专业问题需要根据当前槽位的填充情况给出相应回答,需要结合问答对匹配与模板匹配。
问题归类实际上是意图识别的过程,即对用户的问题进行意图识别,根据识别的结果确定问题的类别。
填槽实际上是实体识别的过程,即对用户的问题进行实体识别,根据识别的结果将相应的槽位填上。(识别的是整形的部位,整形的项目、整形的方式,采用的是crf+双向lstm算法)
在给出通用问题和专业问题的回答时都涉及到问答对匹配,这是给出准确答案的关键步骤。本发明所采用基于语义相似度的自动问答对匹配方法,能够更准确地实现问答匹配,便于更准确地识别用户意图,匹配相应回答模板。
本发明还提供了一种基于语义相似度的自动问答系统,包括客户端和服务端;其中服务端在基于上述自动问答文本匹配方法的基础上进行匹配模型训练,基于训练好的模型,对问答对进行整理,实现用户的意图识别,匹配模板,给出相应回答。
- 还没有人留言评论。精彩留言会获得点赞!