一种联合文件系统中多副本同步方法及装置与流程
本公开涉及计算机领域,具体涉及一种联合文件系统中多副本同步方法及装置。
背景技术
联合文件系统是一种虚拟的文件系统,它并不具备真正的实体,而是通过将多个实体的文件系统聚合在一起,形成一个层级,构成的一个虚拟的文件系统,对这个文件系统的读写,将会映射到层级聚合的实体文件系统中。联合文件系统(unionfs)是一种轻量级的高性能分层文件系统,它支持将文件系统中的修改信息作为一次提交,并层层叠加,同时可以将不同目录挂载到同一个虚拟文件系统下,应用看到的是挂载的最终结果。联合文件系统是linux系统中常见的文件系统,这种文件系统的核心结构是将多个不同的目录挂载成一个独立的文件目录,在这个独立的文件目录中,文件分层级的存储在多个组成的目录中,上层的文件将遮盖下层的文件,当发生文件写入的时候,可以选择多种策略将文件分散在各个层级目录中从而实现分布式存储。各个层级目录中存储的副本是最简单的数据冗余策略,即统一存储系统中存储同一份数据的多个相同拷贝,只要这些拷贝中的一个有效,就能访问该数据。数据的副本越多、数据的可用性越高、可靠性越高,存储空间的利用率也就越低。联合文件系统被诟病的主要是文件更新写入的性能比较低下,文件的写入并没有进行冗余来对数据进行保护,由于文件之间缺乏联系,造成每个应用程序都有对应的文件,有可能同样的数据在在联合文件系统的多个层级目录之间重复存储。
技术实现要素:
本公开提供一种联合文件系统中多副本同步方法及装置,在联合文件系统的多个层级目录之间进行文件同步的方法,从而为联合文件系统提供了多副本冗余同步的功能。
为了实现上述目的,根据本公开的一方面,提供一种联合文件系统中多副本同步方法,所述方法包括以下步骤:
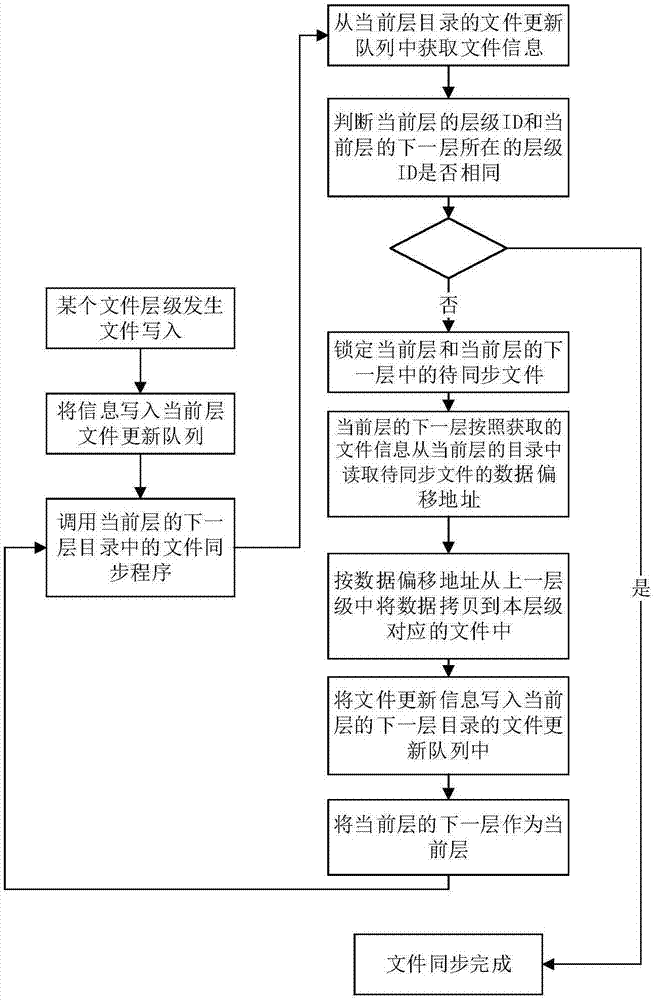
步骤1,当联合文件系统中的一个文件层级目录发生文件写入;
步骤2,将文件数据的文件信息写入到文件更新队列,将发生文件写入的文件层级目录作为当前层;
步骤3,调用当前层的下一层的目录中的文件同步程序;
步骤4,文件同步程序从当前层目录的文件更新队列中获取文件信息;
步骤5,判断当前层的层级id和当前层的下一层所在的层级id是否相同,如果相同则转到步骤11,不同则转到步骤6;
步骤6,锁定当前层和当前层的下一层中的待同步文件;
步骤7,当前层的下一层按照获取的文件信息从当前层的目录中读取待同步文件的数据偏移地址;
步骤8,按数据偏移地址从当前层中将数据拷贝到当前层的下一层对应的文件中;
步骤9,将文件更新信息写入当前层的下一层目录的文件更新队列中;
步骤10,将当前层的下一层作为当前层,转到步骤3;
步骤11,文件同步完成。
进一步地,在步骤1中,所述联合文件系统包括至少一个文件层级目录,每个文件层级目录都有唯一的层级id,所述层级目录包括文件更新队列、文件同步程序。
进一步地,在步骤2中,所述文件更新队列为文件信息的队列,文件信息排列顺序为更新时间的先后;所述当前层为待同步文件层级目录的上一层文件层级目录。
进一步地,在步骤3中,所述文件同步程序用于待同步文件层级目录从上一层的文件层级目录中同步文件及文件更新队列。
进一步地,在步骤4中,所述文件信息包括有文件名,数据偏移地址,发生更新的层级id。
进一步地,在步骤5中,所述锁定当前层和当前层的下一层中的待同步文件为不允许修改待同步文件。
进一步地,在步骤6中,所述数据偏移地址为数据在待同步文件层级目录的上一层文件层级目录中的地址。
优选地,如果发生文件更新的是最后一层目录,最后一层目录作为当前层,则将第一层目录作为当前层目录的下一层,所有的层级目录构造组织成一个环型结构,实现循环同步。
优选地,当联合文件系统中的某一个层级目录发生文件写入的时候,则将发生文件写入的目录作为当前层,将写入文件数据的文件名、写入文件数据的偏移地址、发生更新的层级id,记录到该层级目录的文件更新队列中,然后调度下一层目录的文件同步程序进行文件的同步。
本发明还提供了一种联合文件系统中多副本同步装置,所述装置包括:存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序运行在以下装置的单元中:
写入监测单元,用于监测当联合文件系统中的一个文件层级发生文件写入;
队列更新单元,用于将文件数据的文件信息写入到文件更新队列,将发生文件写入的文件层级作为当前层;
同步调用单元,用于调用当前层的下一层目录中的文件同步程序;
文件信息获取单元,用于文件同步程序从当前层目录的文件更新队列中获取文件信息;
层级判断单元,用于判断当前层的层级id和当前层的下一层所在的层级id是否相同,如果相同则转到同步完成单元,不同则转到文件锁定单元;
文件锁定单元,用于锁定当前层和当前层的下一层中的待同步文件;
偏移地址读取单元,用于在当前层的下一层按照获取的文件信息从当前层的目录中读取待同步文件的偏移地址的数据;
数据拷贝单元,用于按偏移地址的数据从当前层中将数据拷贝到当前层的下一层对应的文件中;
队列同步单元,用于将文件更新信息写入当前层的下一层目录的文件更新队列中;
当前层重置单元,用于将当前层的下一层作为当前层,转到同步调用单元;
同步完成单元,用于文件同步完成操作。
本公开的有益效果为:本发明提供一种联合文件系统中多副本同步方法及装置,加入了副本同步的方法,保证整个文件系统层级中文件的一致性,这个特性是主流的联合文件系统所不具备的,可以提升联合文件系统整体的健壮性,在联合文件系统中某一个,甚至几个层级的文件系统崩溃损坏的时候,也能最大限度的保证文件数据的完整性。
附图说明
通过对结合附图所示出的实施方式进行详细说明,本公开的上述以及其他特征将更加明显,本公开附图中相同的参考标号表示相同或相似的元素,显而易见地,下面描述中的附图仅仅是本公开的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图,在附图中:
图1所示为一种联合文件系统中多副本同步方法的流程图;
图2所示为一种联合文件系统中多副本同步装置图。
具体实施方式
以下将结合实施例和附图对本公开的构思、具体结构及产生的技术效果进行清楚、完整的描述,以充分地理解本公开的目的、方案和效果。需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。
如图1所示为根据本公开的一种联合文件系统中多副本同步方法的流程图,下面结合图1来阐述根据本公开的实施方式的一种联合文件系统中多副本同步方法。
本公开提出一种联合文件系统中多副本同步方法,具体包括以下步骤:
步骤1,当联合文件系统中的一个文件层级目录发生文件写入;
步骤2,将文件数据的文件信息写入到文件更新队列,将发生文件写入的文件层级目录作为当前层;
步骤3,调用当前层的下一层的目录中的文件同步程序;
步骤4,文件同步程序从当前层目录的文件更新队列中获取文件信息;
步骤5,判断当前层的层级id和当前层的下一层所在的层级id是否相同,如果相同则转到步骤11,不同则转到步骤6;
步骤6,锁定当前层和当前层的下一层中的待同步文件;
步骤7,当前层的下一层按照获取的文件信息从当前层的目录中读取待同步文件的数据偏移地址;
步骤8,按数据偏移地址从当前层中将数据拷贝到当前层的下一层对应的文件中;
步骤9,将文件更新信息写入当前层的下一层目录的文件更新队列中;
步骤10,将当前层的下一层作为当前层,转到步骤3;
步骤11,文件同步完成。
进一步地,在步骤1中,所述联合文件系统包括至少一个文件层级目录,每个文件层级目录都有唯一的层级id,所述层级目录包括文件更新队列、文件同步程序。
进一步地,在步骤2中,所述文件更新队列为文件信息的队列,文件信息排列顺序为更新时间的先后;所述当前层为待同步文件层级目录的上一层文件层级目录。
进一步地,在步骤3中,所述文件同步程序用于待同步文件层级目录从上一层的文件层级目录中同步文件及文件更新队列。
进一步地,在步骤4中,所述文件信息包括有文件名,数据偏移地址,发生更新的层级id。
进一步地,在步骤5中,所述锁定当前层和当前层的下一层中的待同步文件为不允许修改待同步文件。
进一步地,在步骤6中,所述数据偏移地址为数据在待同步文件层级目录的上一层文件层级目录中的地址。
优选地,如果发生文件更新的是最后一层目录,最后一层目录作为当前层,则将第一层目录作为当前层目录的下一层,所有的层级目录构造组织成一个环型结构,实现循环同步。
优选地,当联合文件系统中的某一个层级目录发生文件写入的时候,则将发生文件写入的目录作为当前层,将写入文件数据的文件名、写入文件数据的偏移地址、发生更新的层级id,记录到该层级目录的文件更新队列中,然后调度下一层目录的文件同步程序进行文件的同步。
一个优选的实施例的主要实现的方法为:
1.为每一个层级目录设立一个文件更新队列;
2.为每一个层级目录设立一个文件同步程序;
3.当联合文件系统中的某一个层级目录发生文件写入的时候,将发生写入的文件名,写入的数据的偏移地址,发生更新的层级id,记录到该层级目录的文件更新队列中,然后调度下一层目录的文件同步程序,进行文件的同步;
4.相同的如果发生文件更新的是最后一层目录,则将第一层目录作为该层目录的下一层,如此将所有的层级目录,组织成一个环以实现循环同步。
其中文件同步程序的实现方法;
1.读取上一层目录的文件更新队列,并从中获取文件更新的信息(文件名,数据偏移地址,发生更新的层级id);
2.判断发生更新的层级id和自身所在的层级id是否相同,如果相同则终止往下执行,否则继续往下执行;
3.锁定上层目录中的该文件,和本层目录中的该文件;
4.按照获取的文件更新信息,从上一层的目录中读取对应文件的对应偏移地址的数据;
5.将读取的数据写入到本地该文件对应的偏移位置中;
6.将从上一层目录文件更新队列获取的信息写入本层目录的文件更新队列中;
7.调度下一层目录的文件同步程序,进行文件同步。
本公开的实施例提供的一种联合文件系统中多副本同步装置,如图2所示为本公开的一种联合文件系统中多副本同步装置图,该实施例的一种联合文件系统中多副本同步装置包括:处理器、存储器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现上述一种联合文件系统中多副本同步装置实施例中的步骤。
所述装置包括:存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序运行在以下装置的单元中:
写入监测单元,用于监测当联合文件系统中的一个文件层级发生文件写入;
队列更新单元,用于将文件数据的文件信息写入到文件更新队列,将发生文件写入的文件层级作为当前层;
同步调用单元,用于调用当前层的下一层目录中的文件同步程序;
文件信息获取单元,用于文件同步程序从当前层目录的文件更新队列中获取文件信息;
层级判断单元,用于判断当前层的层级id和当前层的下一层所在的层级id是否相同,如果相同则转到同步完成单元,不同则转到文件锁定单元;
文件锁定单元,用于锁定当前层和当前层的下一层中的待同步文件;
偏移地址读取单元,用于在当前层的下一层按照获取的文件信息从当前层的目录中读取待同步文件的偏移地址的数据;
数据拷贝单元,用于按偏移地址的数据从当前层中将数据拷贝到当前层的下一层对应的文件中;
队列同步单元,用于将文件更新信息写入当前层的下一层目录的文件更新队列中;
当前层重置单元,用于将当前层的下一层作为当前层,转到同步调用单元;
同步完成单元,用于文件同步完成操作。
所述一种联合文件系统中多副本同步装置可以运行于桌上型计算机、笔记本、掌上电脑及云端服务器等计算设备中。所述一种联合文件系统中多副本同步装置,可运行的装置可包括,但不仅限于,处理器、存储器。本领域技术人员可以理解,所述例子仅仅是一种联合文件系统中多副本同步装置的示例,并不构成对一种联合文件系统中多副本同步装置的限定,可以包括比例子更多或更少的部件,或者组合某些部件,或者不同的部件,例如所述一种联合文件系统中多副本同步装置还可以包括输入输出设备、网络接入设备、总线等。
所称处理器可以是中央处理单元(centralprocessingunit,cpu),还可以是其他通用处理器、数字信号处理器(digitalsignalprocessor,dsp)、专用集成电路(applicationspecificintegratedcircuit,asic)、现成可编程门阵列(field-programmablegatearray,fpga)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等。通用处理器可以是微处理器或者该处理器也可以是任何常规的处理器等,所述处理器是所述一种联合文件系统中多副本同步装置运行装置的控制中心,利用各种接口和线路连接整个一种联合文件系统中多副本同步装置可运行装置的各个部分。
所述存储器可用于存储所述计算机程序和/或模块,所述处理器通过运行或执行存储在所述存储器内的计算机程序和/或模块,以及调用存储在存储器内的数据,实现所述一种联合文件系统中多副本同步装置的各种功能。所述存储器可主要包括存储程序区和存储数据区,其中,存储程序区可存储操作系统、至少一个功能所需的应用程序(比如声音播放功能、图像播放功能等)等;存储数据区可存储根据手机的使用所创建的数据(比如音频数据、电话本等)等。此外,存储器可以包括高速随机存取存储器,还可以包括非易失性存储器,例如硬盘、内存、插接式硬盘,智能存储卡(smartmediacard,smc),安全数字(securedigital,sd)卡,闪存卡(flashcard)、至少一个磁盘存储器件、闪存器件、或其他易失性固态存储器件。
尽管本公开的描述已经相当详尽且特别对几个所述实施例进行了描述,但其并非旨在局限于任何这些细节或实施例或任何特殊实施例,而是应当将其视作是通过参考所附权利要求考虑到现有技术为这些权利要求提供广义的可能性解释,从而有效地涵盖本公开的预定范围。此外,上文以发明人可预见的实施例对本公开进行描述,其目的是为了提供有用的描述,而那些目前尚未预见的对本公开的非实质性改动仍可代表本公开的等效改动。
- 还没有人留言评论。精彩留言会获得点赞!