一种多特征类子字典学习的高光谱图像分类方法与流程
本发明属于图像处理技术领域,特别涉及了一种多特征类子字典学习的高光谱图像分类方法。
背景技术
高光谱图像数据维度高、训练样本少及光谱波段间相似度高等问题给它的分类任务带来了诸多挑战。仅利用单个像素点光谱特征的分类模型易受“同物异谱,同谱异物”等因素的影响,分类精度较低。随着研究的不断深入,研究人员发现高光谱图像中刻画近邻间关系的空间信息有助于进一步提高分类精度,进而提出了大量光谱信息与空间信息同时使用的分类模型。该分类模型底层特征的利用以光谱特征为主,综合考虑了图像的纹理、形状及像素邻域等空间信息。但这些简单人工特征的表达能力有限且易受高光谱图像中噪声点的干扰。从有噪声的图像中获得鲁棒特征表示的稀疏表示和字典学习模型在高光谱图像分类领域得到广泛关注。
但目前大多稀疏表示和字典学习方法在利用空间邻域信息的基础上仅考虑了高光谱图像的光谱特征。一种特征仅能从一个角度来刻画图像,而不同类型的特征具有不同的判别力,可提供互补且相关的信息辅助分类。因此,如何有效地利用多种特征信息以提高编码系数的可区分性在高光谱图像分类领域仍需要进一步探索。并且,高光谱图像中还存在特征编码具有相似性的问题,这给高光谱图像的分类带来了挑战。
技术实现要素:
为了解决上述背景技术提出的技术问题,本发明旨在提供一种多特征类子字典学习的高光谱图像分类方法,解决高光谱图像中存在的同物异谱、同谱异物等问题,提高高光谱图像分类精度。
为了实现上述技术目的,本发明的技术方案为:
一种多特征类子字典学习的高光谱图像分类方法,包括以下步骤:
(1)提取高光谱图像的多种互补特征数据;
(2)对每类训练样本利用mfkcsdl模型学习得到相应的类子字典;
(3)利用基于分水岭的图像分割方法将高光谱图像划分成若干空间组;
(4)将步骤(2)学习得到的类子字典组合应用到mfkjsr模型,获得每个空间组像素点的多特征表示系数;
(5)通过空间组中所有像素点的多特征重构误差最小,预测空间组中像素点的类别标签。
进一步地,在步骤(1)中,所述多种互补特征数据包括光谱、梯度、纹理和形状特征。
进一步地,在步骤(2)中,所述mfkcsdl模型通过以下步骤得到:
(a)设高光谱图像中第k类特征数据表示的第c类训练样本矩阵为
(b)同类训练样本数据属于相同的地物,能够由相同的字典原子来表示,因此,设同类训练样本数据得到的相应编码系数矩阵中非零元素所在的行是相同的,即相应的编码系数矩阵具有行稀疏性,而非零元素值的大小有所不同;由于
(c)结合步骤(a)和(b),得到mfkcsdl模型:
其中,
进一步地,在步骤(2)中,根据表示理论,字典
进一步地,步骤(2)的具体步骤如下:
(21)初始化图像矩阵y,矩阵
(22)固定每类样本数据上的矩阵vc,每类训练样本数据的稀疏表示系数矩阵ψc通过下式求解:
其中,
(23)固定第c类训练样本数据的多特征稀疏系数矩阵ψc,该类数据的每种特征相应的变换矩阵
令该目标函数的梯度等于零,则
(24)重复步骤(22)-(23),直至满足迭代终止条件,输出矩阵
进一步地,在步骤(3)中,首先获取高光谱图像的梯度图像,然后基于梯度图像利用分水岭分割算法进行高光谱图像分割,获得高光谱图像的分割图,将其划分成若干个空间组{g1,g2,…,gi,…gg},g表示空间组总数。
进一步地,在步骤(4)中,设高光谱图像中第k种特征数据表示的空间组gi中像素点集合表示为
其中,
进一步地,在步骤(5)中,步骤(4)求得的多特征稀疏表示系数包含了与未知样本类别相关的信息,利用残差将空间组gi中所有像素点划分到残差最小对应的类别当中,确定空间组中测试像素点的类别标签:
其中,
采用上述技术方案带来的有益效果:
首先,本发明通过对高光谱图像划分空间组,结合空间信息辅助分类,较好地利用了高光谱图像的空间信息,以此提高高光谱图像的分类效果。
其次,本发明通过融合多种特征信息,有效利用了多种特征信息的相关性和互补性,提升分类正确率,增强分类鲁棒性。
再者,本发明利用多种特征信息学习更有判别能力的类子字典,进而提升稀疏编码的判别能力,利用稀疏编码间接获得待分类样本的类别标签,提高了高光谱图像的分类精度。同时,通过核方法提高数据的线性可分性,有效解决了高光谱图像中存在的同物异谱、同谱异物问题,因此具有较高的使用价值。
附图说明
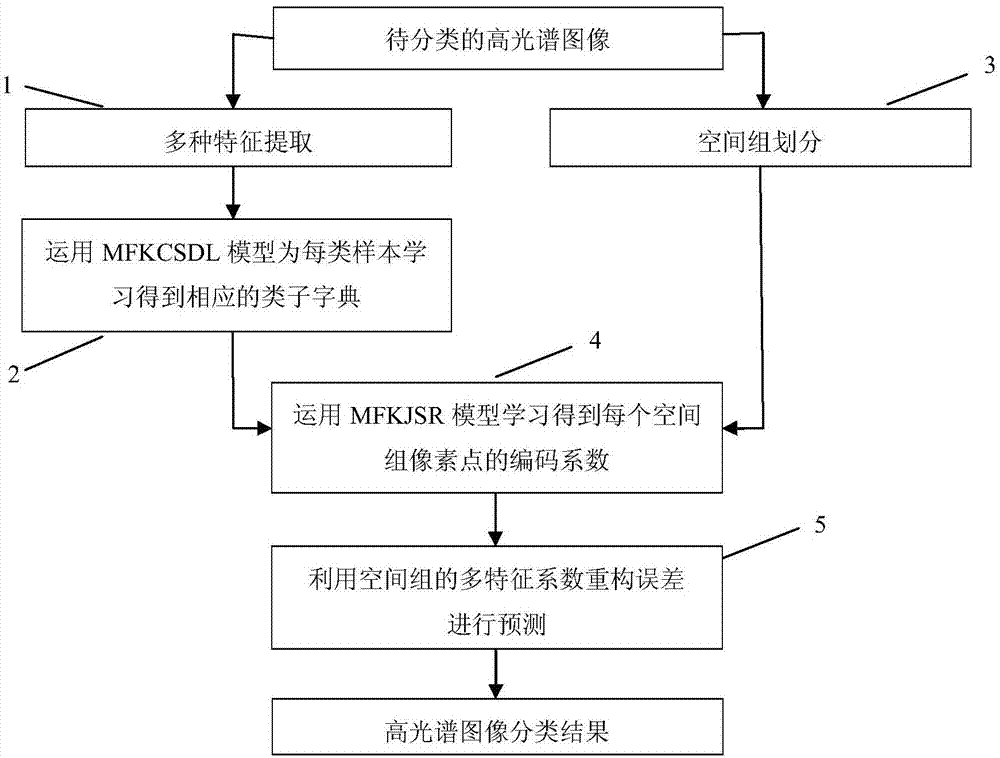
图1是本发明的整体流程图;
图2是本发明运用mfkcsdl学习得到字典和稀疏编码的流程图。
具体实施方式
以下将结合附图,对本发明的技术方案进行详细说明。
如图1所示,本发明提供一种多特征类子字典学习的高光谱图像分类方法,包括如下步骤:
步骤1,提取待分类高光谱图像的光谱、梯度、纹理、形状多种特征数据:利用现有技术提取高光谱的多种特征信息,得到不同特征空间的样本数据,为步骤3做铺垫。多种特征信息具有相关性和互补性,为高光谱图像的正确分类提供更多有效的信息,进一步提升分类精度。
步骤2,运用mfkcsdl(multifeaturekernelclasssub-dictionarylearning)模型为每类样本数据学习得到相应的类子字典:迭代更新字典和稀疏编码,直到满足迭代终止条件,输出学习得到具有判别能力的类子字典。
步骤3,利用分水岭分割方法对待分类高光谱图像进行分割,划分成若干个空间近邻组:首先利用现有技术提取高光谱图像的梯度图像,然后利用分水岭分割算法对梯度图像进行分割,获得高光谱图像的分割图,将其划分成若干个空间组。组内空间信息具有一致性,对分类帮助较大。
步骤4,将每学习得到的类子字典组合都成每种特征下的总字典,然后将总字典应用到mfkjsr(multifeaturekerneljointsparserepresentation)模型中,为每个空间组中所有像素点学习得到相应的多特征表示系数。
步骤5,利用空间组中所有像素点的多特征重构误差最小,预测每个空间组中所有测试像素点的类别标签。对所有空间组像素点按此方法进行分类,得到最终的高光谱图像分类结果。
需要说明的是,本发明的核心步骤在于运用mfkcsdl模型学习得到字典和稀疏编码,因此,具体实施方式的描述主要侧重于步骤2。
在步骤2中,mfkcsdl模型可通过如下步骤得到:
(a)设高光谱图像中第k类特征数据表示的第c类训练样本矩阵为
(b)同类训练样本数据属于相同的地物,能够由相同的字典原子来表示,因此,设同类训练样本数据得到的相应编码系数矩阵中非零元素所在的行是相同的,即相应的编码系数矩阵具有行稀疏性,而非零元素值的大小有所不同;由于
(c)结合步骤(a)和(b),得到mfkcsdl模型:
其中,
如图2所示,运用mfkcsdl模型学习得到类子字典的具体内容是:
根据表示理论,字典
这里,定义核函数
步骤21,初始化图像矩阵y,矩阵
步骤322,固定每类样本数据上的矩阵vc,每类训练样本数据的稀疏表示系数矩阵ψc可以通过下式求解:
步骤23,固定第c类训练样本数据的多特征稀疏系数矩阵ψc,该类数据的每种特征相应的矩阵
该公式是在
步骤24,重复步骤22-23,直至满足迭代终止条件,输出学习得到的矩阵
综合上述,本发明一种多特征类子字典学习的高光谱图像分类方法,采用mfkcsdl(multifeaturekernelclasssub-dictionarylearning)字典学习模型,通过对每类训练样本的多种特征施加联合稀疏约束lrow,0并嵌入多特征的系数重构误差来有效融合多种特征的互补相关信息,为每类样本的每种特征学习得到有较高判别力的字典,由此提出一种新的高光谱图像分类方法。该方法仅利用每类训练样本学习对应的子字典,训练阶段运行时间较短,并且在主观视觉以及客观评价指标上都达到了提升分类精度的目的。另外,利用核方法扩展线性模型,有效缓解高光谱图像中的同物异谱、同谱异物现象,因此具有较高的使用价值。
实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!