一种大规模安卓恶意软件自动化检测系统及方法与流程
本发明涉及移动终端安全技术领域,特别涉及一种大规模恶意软件自动化检测系统及方法。
背景技术
随着智能手机的普及,恶意软件也在快速地增长。对于android操作系统的移动设备,其开源特性导致其成为了恶意软件开发者的主要目标。
随着各种系统漏洞的不断披露,现存的android智能手机就像一艘漏水的船,纵然手机安全软件能够缓解一些安全隐患,但系统中的漏洞仍未能有效修补,而android安全软件又无法被授予系统的最高权限,因而android系统安全问题一直非常棘手。传统的检测软件是不是恶意的主要靠人工来分析代码,但随着恶意软件的逐渐增多,这种方法在不可行。于是开始将机器学习的思想与恶意软件识别相结合。
综上所述,基于机器学习的恶意软件检测是解决android手机安全的重要方案之一,但是当前市场上的检测方案只是单纯的针对一个软件进行分析,然后根据分析结果进行判定是否为恶意软件。提出的解决方案大部分为基于权限特征来检测恶意软件的,然而随着反编译、代码篡改、反汇编等技术的出现,仅仅依靠权限特征并不能很好的识别恶意软件,另外少数人提出动静结合的方法虽然在以往的基础上增加了特征选取的方式,但依旧无法比较全面的选取特征。其次是机器学习的算法上面,普遍的都会只选取一种算法进行测试,无论是机器学习还是深度学习,都无法统筹兼顾的提升总体学习的准确率。本专利提出的解决方案不仅在动静结合的基础上能够比较完整的提取样本的属性,还首次使用集成学习的方案进行学习,实验结果也证明了集成学习的恶意软件识别的效果比较突出。
技术实现要素:
本发明主要解决的技术问题是:克服现有技术的不足,提出一种大规模安卓恶意软件自动化检测系统及方法,可以使得大规模恶意软件检测变得高效,且检测结果准确率高,其中所有检测方案的检测率均大于0.8419,大量模型集中在0.95附近,最高的集成学习模型准确率可达到0.9969。
本发明技术解决方案:一种大规模安卓恶意软件自动化检测系统,包括:样本处理模块、特征提取模块、预处理模块、机器学习模块和恶意软件检测模块;
样本处理模块:收录正常样本和恶意样本两种,其中正常样本2千余个,由googleplay商店获取,恶意样本2千余个,由网上已经公布出的恶意样本收集而来;利用文件哈希去除样本中的重复文件,并以哈希命名文件;前期对样本利用apktool工具进行反编译操作,获取样本的dex文件;再利用dex2jar工具获取到apk文件的源码;得到的文件包括安卓可执行文件、安卓配置文件和安卓源码文件;
特征提取模块:搭载五种分析工具的平台,五种工具分别为apktool、dex2jar、androguard、drozer和droidbox;对于用户提交的每一个待检测文件,利用上述五特困户工具进行检测得出对应的检测报告;其中apktool用来反编译安卓可执行文件得到安卓配置文件,在配置文件中提取到权限、意图调用、服务特征,利用dex2jar工具得到项目源码后对项目的api调用,activity数量、java调用特征进行提取;androguard检测报告提取安卓的四大组件,即activity,service,broadcastreceiver,contentprovider的使用情况、ndk反射信息和签名信息特征;drozer对apk存在的攻击面进行检测,检测报告中提取到攻击面特征;drozbox检测报告中提取一段时间(用户自定义,本发明规定为20s)内用户对手机文件的操作方式、操作次数特征,收集特征并按照文件名字分类形成特征矩阵;
预处理模块:对特征提取模块获取的特征矩阵进行处理,去除掉无影响特征,得到初步的最能体现软件恶意性的特征组;
机器学习模块:通过机器学习分类算法进行准确率检测,得出在训练样本分别占总样本95%、85%、75%、65%、55%、45%等6种不同比例下的准确率,选取准确率最高的模型为后期调整参数的模型;通过实验结果显示集成学习为最优模型,在集成学习模型中,通过对四种参数进行调节,优化前期得出的模型;所述四种参数包括,通过减少权重提高准确率eta、树的最大深度max_depth、随机采样的比例subsample、随机采样列数的占比colsample_bytree;在max_path属性上,实验从3取到10,每次增长为1。eta属性上,从0.01取到0.2每次增长为0.01。subsample属性上从0.75到1每次增长为0.05;colsample_bytree属性上从0.5到1,每次增长为0.1;因属性较多,图4中只列举出不同max_depth下的最高准确率,即每种max_depth下其他参数进行调整后的最优结果;因参数较多,图4中只列举出不同max_depth下的最高准确率,即每种max_depth下其它参数进行调整后的最优结果;图4中max_depth从3到9,每行列举出eta、colsample_bytree和subsample经过调整后得到的最大准确率,包含此准确率下eta、colsample_bytree和subsample的具体数值。
恶意软件检测模块:此模块用户通过web访问,提交自己待检测的软件集合或者可下载此软件的网络连接,由服务器执行下载操作。服务端加载机器学习模块得到的准确率最高的,并且经过参数调优后的模型,通过模型检测后返回给用户检测结果;
在本发明中,首先通过样本处理模块获取到可以提取特征的文件;然后通过特征提取模块获取所有实验样本的特征;经过预处理模块对实验数据的处理,得出适合在机器学习模块检测的特征表;在机器学习模块检测其准确率,选取准确率高的模型,进行参数调优,得出最佳模型;最后在恶意软件检测模块实现用户提交检测数据,服务端返回检测结果。
所述预处理模块的处理方式采用移除无关属性、处理缺失值、处理密集特征和相关系性检查;其中:
所述移除无关属性为从特征提取模块获取的特征矩阵里面会有对模型检测无关的特征,在检测过程中,首先移除此部分特征,包括软件名即哈希,此特征用来唯一标识一个样本的特征组,但在实际检测中没有影响;
所述处理缺失值,特征提取模块获取的特征矩阵中会有数据处于无值状态,考虑到提取过程中会对软件拥有的特征进行分类赋值,所以缺失值代表此软件无此项特征,实验中统一赋值为零,例如特征模块在提取如权限类特征时,由于有些软件没有用到此特征,故在进行存储时便没有对此特征进行处理,这里对其进行填零操作,使其组成一张完整的特征表;
所述处理密集特征,在特征表中,会有部分属性所有样本均拥有或者均不拥有,称之为密集特征,对于这种特征,本发明设定阈值为95%,假如此项特征95%以上样本的值相同,那么移除此项特征;
所述相关系性检查,考虑到某些特征之间存在相关性,这样的特征会对实验结构产生影响,所以本系统利用皮尔森相关系数求出它们之间的相关性,当大于规定的阈值时,依旧移除此项特征,本实验规定阈值为0.75;
上述四种处理方式为本实验的数据处理阶段,通过上述四种方式处理,移除掉对实验结果无影响或影响较小的特征,得到初步的机器学习模块需要使用的特征矩阵。
所述机器学习模块中的机器学习分类算法选用k近邻算法、朴素贝叶斯、决策树、逻辑回归、神经网络、支持向量机和集成学习。
本发明一种大规模安卓恶意软件自动化检测方法,包括以下步骤:
第一步,收集安全软件和恶意软件库作为初始样本集;
第二步,从动态和静态两个角度收集初始样本集的特征,形成安卓软件特征表格;
第三步,对所述安卓软件特征表格进行数据预处理;
第四步,利用机器学习算法对第三步预处理后的特征表格进行检测,选取准缺率最高的模型并对其进行参数调节,选取准确率最高的模型作为本发明的检测模型;
第五步,对于待检测的软件,利用最终检测模型对所选软件检测后返回结果。
第一步中,所述初始样本集包括恶意软件数据集和从googleplay上爬取的正常软件数据集。其中正常样本2千余个,由googleplay商店获取,恶意样本2千余个,由网上已经公布出的恶意样本收集而来;利用文件哈希来去去除样本中的重复文件,并以哈希命名文件。
第二步中,所述静态角度为:收集涵盖安卓activity、service、broadcastreceiver、contentprovider组件、权限、意图和ndk反射的数据;所述动态角度为收集软件在规定时间内对安卓手机文件的读写操作、读写次数以及攻击面检测的使用情况。
第三步中,所述预处理为去除掉每一列数据量相似度小于5%或者大于95%的特征,用皮尔森相关系数去除掉相关性大于0.75的特征。
第四步中,所述机器学习算法为选用k近邻算法、朴素贝叶斯、决策树、逻辑回归、神经网络、支持向量机和集成学习,每一种算法分别划分95%、85%、75%、65%、55%、45%的测试集和训练集分别进行测试。
本发明与现有技术相比的优点在于:
(1)在特征选取上,采用动静结合的方法从四种工具上获得了较比其他解决方案更多,更能体现软件恶意性的特征,在特征选取方面更为全面。
(2)使用多种算法进行对比,不同的训练集占总样本比例划分,能更加准确的说明各个算法在恶意软件识别方面的适应性。
(3)首次提出将集成学习的方法引进到恶意软件识别当中,能够更加准确的对恶意软件进行识别。
现有的解决方案存在特征提取少,算法选择单一的问题,特征提取的合适度是影响检测结果一个很重要因素。而在机器学习的算法选取上,并不是越好的算法在所有检测结果上都很好,本发明在体征选取和算法选择上很好的解决了这些问题。本发明在动静结合的方法上,结合四种分析工具,获取到更多能够影响软件恶意性的特征,而动静结合、多种工具搭配使用、特征分析使得能够更全面更准确的提取到体现软件恶意性的特征。在学习算法选择上面,本方案选取了七种当前比较流行的学习算法,每种算法再细分为六种不同的分配比,使得更直观的分析每种算法的每个分配比的检测结果,这样就能保证本方案选取的算法是最贴合本实验数据的。本发明检测结果如图3所示,从图3中可以看出集成学习的准确率明显高于其他模型。在图3中可以看出,所有模型不同分配比例下的准确率均高于84%。并且每种分配比例下集成学习的准确率都是最高的,集成学习最差为97.93%,最高为99.69%。
附图说明
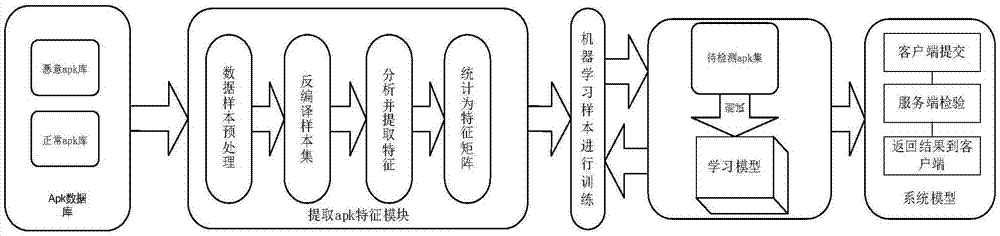
图1为本发明检测系统框图;
图2为本发明软件特征提取图;
图3为本发明实验检测结果;
图4为本发明参数调优结果图。
具体实施方式
本发明解决方案通过以下方案实现:使用者通过本地提交待检测的安卓可执行文件,服务端负责对提交上来的样本进行分析,然后在系统已经学习好的模型上面检测,得出结果,并返回给用户分析结果,对提交的软件集合自动的分类其是否为恶意软件。
1.本发明的实现过程为:
(1)收集安全软件和恶意软件库,恶意软件从googleplay上获取固定数量的样本数量,加上已知恶意软件数据集,一同组成该方案的初始样本集。
(2)利用androguard、droidbox等软件分析工具,从动态和静态两个角度分别收集每一个软件的特征,形成一个安卓软件特征表格。
(3)对表格的收据进行处理,规定一个阈值,当某个特征所有样本的值的个数都大于阈值时,删除此特征。利用皮尔森相关系数进行判定两列的的相关系数,相关系数小于该方案规定的值的时候,同样删除此特征,这样就初步的把相关度小的系数去掉,增加了后期数据的准确性。
(4)用机器学习的七种算法(k近邻算法、朴素贝叶斯、决策树、逻辑回归、神经网络、支持向量机和集成学习)对获取到的数据进行处理,并调节训练集和测试集比例得出准确率最高的模型。
(5)存储识别率较高的模型,用于后期的检测。
(6)搭建检测平台,用户提交单个或大量符合要求的文件后,加载系统提前选择好的模型,然后经过模型检测生成检测报告。
2.在步骤(1)中恶意软件从googleplay上获取固定数量的样本数量,加上已知恶意软件数据集,一同组成该方案的初始样本集。
在步骤(2)中从静态分析中获取涵盖安卓四大组件、权限、意图和ndk反射的相关数据,从动态分析中收集软件在一定时间内对安卓收集文件系统的使用情况,包括操作方式和操作次数。
在步骤(3)中对获取的样本特征集数据进行处理,首先去除掉每一列数据量小于5%或者大于95%的特征组,保留其数据量在5%至%95之间的数据,减小这种所有样本类似的的属性对检测结果的干扰。最后借用皮尔森相关系数,去除掉相关系数不符合标准的属性,得出最终结果集。
在步骤(4)中选用当前比较流行的七种算法,k近邻算法、朴素贝叶斯、决策树、逻辑回归、神经网络、支持向量机和集成学习。然后每一种算法分别划分六种不同比例(六种训练集比例分别为95%、85%、75%、65%、55%、45%)的测试集和训练集,分别测试,单个分析用于后期检测。
在步骤(5)中挑选其中准确率最高的模型,进行参数调优后存储其模型,方便下次直接加载使用。
在步骤(6)中建立检测平台,对于用户提交上来的待测数据集,先在平台上进行分析,提取特征后自动进行分类,将待测数据集分为恶意和正常两类。
下面进行详细说明。
如图1所示,使用者通过本地提交待检测的安卓安装文件,通过服务端分析后返回给用户分析结果,是否为恶意软件。服务端负责对提交上来的样本进行分析,然后在预先选择的模型上面检测,得出返回结果。
1.该方案的实现过程为:
(1)收集安全软件和恶意软件库,恶意软件从googleplay上获取固定数量的样本数量,加上已知恶意软件数据集,一同组成该方案的初始样本集。
(2)系统实现了搭载四种分析工具的平台,四种工具分别为apktool、androguard、drozer和droidbox。其中apktool用来反编译安卓安装文件获得权限、意图调用等信息。androguard用来对安卓的四大组件(activity,service,broadcastreceiver,contentprovider)的使用情况、ndk反射信息和签名信息等信息。drozer可以对apk存在的攻击面等信息进行收集。drozbox可以获取一段时间(用户自定义,本实验规定为20s)内用户对手机文件的操作方式、操作次数等信息。利用软件分析工具,从动态和静态两个角度分别收集每一个软件的特征,形成一个安卓软件特征表格,提取框架如图2.
(3)对表格的收据进行处理,规定一个阈值,当某个特征所有样本的值的个数都大于阈值时,删除此特征。利用皮尔森相关系数进行判定两列的的相关系数,相关系数小于该方案规定的值的时候,同样删除此特征,这样就初步的把相关度小的系数去掉,增加了后期数据的准确性。
(4)用机器学习的支持向量机、神经网络等算法对获取到的数据进行处理,并调节多个参数的出准确率最高的模型。
(5)存储识别率最高模型,进行参数调优后,储存其模型,用于后期的检测。
(6)用户提交符合要求的文件后,加载提前选择好的模型,然后经过模型检测生成检测报告并返回给用户。
2.在步骤(1)中恶意软件从googleplay上爬取选取数量的样本数量,加上已知恶意软件数据集,一同组成该方案的初始样本集。
在步骤(2)中从静态分析中获取涵盖安卓四大组件(activity,service,broadcastreceiver,contentprovider)、权限、意图和ndk反射等特征,从动态分析中收集软件在一定时间内对安卓手机文件系统的使用情况,包括操作方式和操作次数等特征。
在步骤(3)中对获取的样本特征集数据进行处理,首先去除掉每一列数据量小于5%或者大于95%的特征组,减小这种所有样本类似的的特征对检测结果的干扰。最后借用皮尔森相关系数,去除掉相关性大于0.75的特征,得出最终结果集。
在步骤(4)中选用当前比较流行的七种算法,k近邻算法、朴素贝叶斯、决策树、逻辑回归、神经网络、支持向量机和集成学习。然后每一种算法分别划分六种训练集比例分别为95%、85%、75%、65%、55%、45%的测试集和训练集,分别测试,单个分析用于后期检测。
在步骤(5)中挑选其中准确率最高的模型,进行参数调优后存储下模型,方便下次直接加载使用。
在步骤(6)中建立检测平台,用户通过web访问,提交自己待检测的软件集合或者可提交此软件的网络下载链接,由服务器执行下载操作。服务端加载以前储存的模型,通过模型将检测返回给用户检测集合的检测结果。
- 还没有人留言评论。精彩留言会获得点赞!