基于深度神经网络的初撑力、末阻力识别方法、存储介质与流程
本发明涉及一种基于深度神经网络的液压支架初撑力点、末阻力点自动识别方法。
背景技术:
目前井下液压支架的顶板控制方法是以手动方法完成,操作工人根据经验设定固定的初撑力使液压柱上升。当出现片帮、顶煤下放不利等情况时,再手动操作液压支架的掩护梁、液压柱等做出相应的操作。人工操作不能从工作面顶板的整体动态状况综合考虑,无法有效兼顾工作面层级的性能,更无法实现液压支架群的自动控制,其根本原因是缺乏液压支架群系统层级的控制模型。
液压支架是煤矿综放工作面安全支护的核心设备,初撑力和末阻力是两个重要的技术指标。初撑力是液压支架初次加压的数值,是液压支架主动作用于顶板的数据依据,也是采场支护质量评价的重要依据;末阻力是液压支架泄压前的顶板压力值,是顶板压力的直接反应,并可据此分析得出上覆岩层的动态特性。
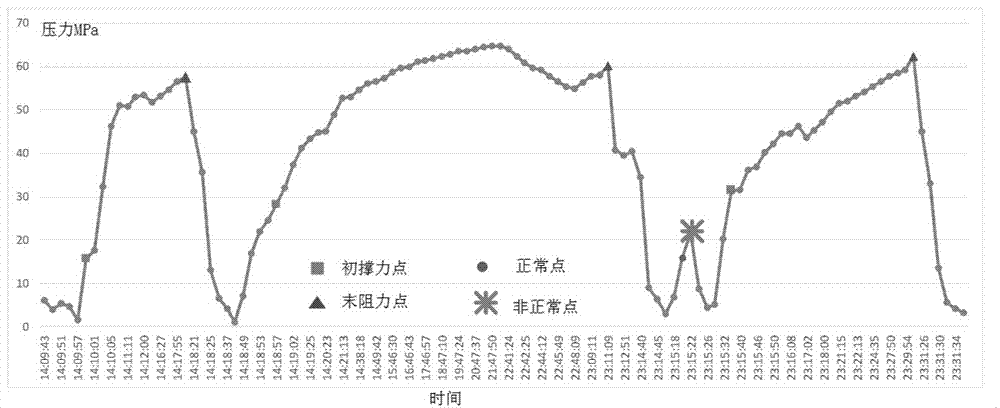
目前,井下液压支架上安装有压力检测设备,检测液压支架承受压力,其检测原理是:当压力有变化时,每2秒检测液压支架的压力数据;然后工作人员根据收集的压力数据,分析顶板的动态特性及液压支架的支撑力调整,如图1所示。
目前,初撑力和末阻力点的检测方法主要是人工标识法和梯度变化法(尚未见文献说明)。梯度变化法是通过检测两点间的变化率来确定初撑力和末阻力点。由于开采过程中液压支架收到顶板压力复杂,造成目前的梯度变化法错误率较高。
技术实现要素:
本发明的目的在于建立一种基于深度神经网络的液压支架初撑力、末阻力自动识别方法,实现采集数据的自动分类识别,并提高识别准确度。
本发明采用以下技术方案:
基于深度神经网络的初撑力、末阻力识别方法,包括以下步骤:
s1:采集液压支架不同时间的检测数据,所检测数据的每个数据点均包括时间数据和压力数据;
s2:为每个数据点设置具有四个属性的标注数据,所述标注数据的四个属性分别为:初撑力点、末阻力点、正常点、非正常点;
s3:采集的检测数据和对应的标注数据形成输入数据的训练样本,依据训练样本训练深度神经网络;
s4:建立基于深度神经网络的预测模型;
s5:现场采集液压支架的检测数据并送入到训练好的深度神经网络中,输出每个数据点的分类结果。
所述s3中,首先构造深度神经网络,然后通过训练样本训练深度神经网络,完成深度神经网络的预测模型的建立。
所述深度神经网络包括依次相连的包括:第一类卷积层、第一类池化层、第二类卷积层、第三类卷积层、第四类卷积层、第二类池化层、第一类全卷积层、第二类全卷积层、第一类反卷积层、第二类反卷积层、softmax层,其中第一类池化层的池化结构通过第二类卷积层后,与第一类反卷积层输出的结构相加后再依次进入到第二类反卷积层、softmax层。
第一类卷积层的卷积核为[13,1,64],步幅为[1,2];
第一类池化层的步幅为[2,1];
第二类卷积层包括串联的三个卷积层,每个卷积层的卷积核为[3,1,128],步幅为[1,1];
第三类卷积层包括串联的三个卷积层,每个卷积层的卷积核为[3,1,256],步幅为[1,1];
第四类卷积层包括串联的三个卷积层,每个卷积层的卷积核为[3,1,512],步幅为[1,1];
第二类池化层的步幅为[2,1];
第一类全卷积层的卷积核为[12,1,1024],步幅为[1,1];
第二类全卷积层的卷积核为[1,1,2048],步幅为[1,1];
第一类反卷积层的卷积核为[4,1,4],输出规格为[50,1,4];
第二类反卷积层的卷积核为[2,1,4],输出规格为[100,1,4];
第五类卷积层的卷积核为[1,1,4],步幅为[1,]。
所述s3中,通过训练样本训练深度神经网络的步骤包括:
s31:产生一个0到n-l之间的随机数,假设该随机数为m;所述n标识训练样本的数据长度,l表示每次处理的数据长度;
s32:选取从m开始到m+l的范围内的l个数据,作为训练样本;
s33:将训练样本的数据送入到深度神经网络中,得到一个预测输出;
s34:将该预测输出与训练样本的标注数据对比,求取交叉熵后,采用随机梯度下降法更新深度神经网络的权重,并使交叉熵降低;
s35:重复s31~s34的步骤,直至交叉熵小于预设熵值,或者循环次数大于预设次数值,完成深度神经网络训练。
存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1~5任一项所述方法的步骤。
本发明的有益效果:本发明能通过深度神经网络对液压支架的数据自动提取特征,并通过大量样本训练得到精确的预测结果。
附图说明
图1为液压支架的时间与压力数据示意图。
图2为深度神经网络组成结构示意图。
具体实施方式
下面结合附图和具体实施方式对本发明作进一步详细说明。
本发明提供的基于深度神经网络的液压支架初撑力点、末阻力点自动识别方法,主要包括以下步骤:
s1:通过设置在液压支架上的压力检测装置获取液压支架的检测数据,该检测数据包括多个数据点,每个数据点均包括时间数据和压力数据;
s2:标签数据处理:为每个数据点设置具有四个属性的标注数据,该标注数据用于标识压力数据的属性,因此该四个属性分别为:初撑力点、末阻力点、正常点、非正常点;非正常点是小于一个采煤循环周期而出现的峰值点,而正常点是除了初撑力点、末阻力点和非正常点之外的所有数据点;
s3:构造深度神经网络;
s4:将采集的检测数据和对应的标注数据形成输入数据的训练样本,依据训练样本训练深度神经网络;
s5:建立基于深度神经网络的预测模型;
s6:现场采集液压支架的检测数据并送入到训练好的深度神经网络中,输出每个数据点的分类结果;该分类结果是指数据点属于初撑力点、末阻力点、正常点、非正常点的哪一个属性。
由上述可知,本发明需要建立深度神经网络的预测模型,然后通过深度神经网络的预测模型对现场采集的数据点的属性进行识别。
本发明中,深度神经网络的预测模型的建立可采用下述实施方式的方法:
一:样本数据的规范化处理
为了便于数据进行处理,需要对采集的检测数据进行规范化处理。规范化处理的方法可采用现有任何可行的方法,本发明中,给出下述一种规范化处理的具体实施例:
(1)检测数据的处理。检测数据即输入数据,包括两类:时间信息和压力信息。将时间信息规范化为yyyymmddhhmmss形式,其中yyyy表示年,mm表示月,dd表示天,hh表示小时,mm表示分钟,ss表示秒,并存储为float格式。压力信息保持不变,存储为float格式。
(2)标签数据的处理。与检测数据对应,引入一个标注数据。将数据点的种类分为4类:初撑力点、末阻力点、正常点、非正常点,该标注数据可依次对应设为1000、0100、0010、0001。其中非正常点是小于一个采煤循环周期而出现的峰值点,正常点是除了初撑力点、末阻力点和非正常点之外的所有数据点。
(3)数据长度的规范化。此时实例中规定每次处理的数据长度为100点,则一个样本数据有时间数据100个、压力数据100个、标定数据400个。每次处理的数据长度也可选择其他数值,例如每次处理的数据长度为200或者300或者350等。
(4)训练样本制作。从现场采集的数据中,选取10000个连续的数据点,并按照前述的处理方式进行规范化处理,并对样本的数据点进行标注,形成样本数据,标注过程如下:根据时间和阻力变化情况,对每一个数据点标注为:初撑力点、末阻力点、正常点、非正常点,并分别用0,1,2,3表示。
二:深度神经网络的建立
本发明的初撑力、末阻力点自动识别方法通过深度神经网络自动提取特征,在此基础上通过2次反卷积实现每个数据点的分类。
(1)深度神经网络的组成
深度神经网络组成结构如图2所示,设定卷积核规格[h,w,c],其中h表示卷积核高、w表示卷积核宽,c表示卷积核个数;步幅规格[hb,wb],其中hb表示高度方向的步幅,wb表示宽度方向的步幅;反卷积输出规格[hf,wf,cf],其中hf表示输出数据的高、wf表示输出数据的宽,cf表示输出数据的通道。
本发明采用的深度神经网络由5类卷积层、2个池化层、2个全卷积层、2个范卷积层,以及一个softmax层组成。其中第一类卷积层卷积核为[13,1,64],步幅为[1,2],直接将样本数据的时间和压力融合成为一个特征输出;随后,进行第一次平均池化操作,特征值进行下采样,池化操作的步幅为[2,1];池化的输出结果进入第二类卷积层,该类卷积层卷积核为[3,1,128],步幅为[1,1],第二类卷积层由3个卷积层串联组成;接着第三类卷积层的卷积核为[3,1,256],步幅为[1,1,],共有3个相同卷积层串联;第四类卷积层的卷积核为[3,1,512],步幅为[1,1],也有3个相同的卷积层串联组成;数据经过上述卷积操作后,进入到第二次平均池化操作,步幅为[2,1];第二次池化操作的结果送入到第一个全卷积层,卷积核为[12,1,1024],步幅为[1,1];其输出结果进入第二个全卷积层,卷积核为[1,1,2048],步幅为[1,1]。第二个全卷积层的输出送入到第一个反卷积层,该层的卷积核为[4,1,4],输出的规格为[50,1,4]。第一次反卷积层的结果需要与第一次池化操作的结果相融合,因此在采用第五类卷积层对第一次池化操作的结果进行出来,第五类卷积层的卷积核为[1,1,4],步幅为[1,1],该操作的输出结果与第一次反卷积的输出结果的规格相同。将第一次反卷积输出结果与第五类卷积层输出相加,送入到第二次反卷积层,该层的卷积核为[2,1,4],输出的规格为[100,1,4],最后将该输出结果送到softmax层中,换算成每个数据点属于初撑力点、末阻力点、正常点、非正常点的概率值。
上述的深度神经网络的组成方式仅仅是本发明所采用的一种实施方式,也可采用其它现有的组成方式活着对现有的组成方式进行改进的组成方式。
(2)神经网络的训练
由(1)可知,经过规范化处理的训练样本包括数据和标签两个部分,其长度设为n,则数据的规格为[n,2],n表示数据长度,2表示数据中有时间和压力两种数据;标签的规格为[n,4],n表示标签长度,4表示数据可分为4类。规定每次处理数据长度为100个。
神经网络训练过程:
<1>首先产生一个0到n-100之间的随机数,假设为m;
<2>选取从m开始到m+100的范围内的100个数据,作为训练样本;
<3>将训练样本的数据送入到神经网络中,并得到一个预测输出;
<4>将该预测输出与样本的标签对比,求取交叉熵后,采用随机梯度下降法,更新神经网络的权重,并使交叉熵降低;
<5>重复<1>~<4>直至交叉熵小于预选设定的一个较小的值,或者循环次数大于预设值,则完成神经网络训练。
(3)神经网络的预测
上述的深度神经网络训练完成以后,即建立了基于深度神经网络的预测模型,可用于现场采集信号的预测。首先将现场采集的时间和压力信号按照规范化处理,然后,每设定个数据为一组,例如一组100个数据,送入到训练好的神经网络,得到的输出结果,即为每个数据点的分类结果。
本发明还包括一种存储介质,该存储介质存储有计算机程序,计算机程序被处理器执行时实现上述方法的步骤。
上述的存储介质可以包括能够携带所述计算机程序的任何实体或装置、记录介质、u盘、移动硬盘、光盘、磁盘、计算机存储器等。
以上所述的仅是本发明的优选实施方式,应当指出,对于本领域的技术人员来说,在不脱离本发明整体构思前提下,还可以作出若干改变和改进,这些也应该视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!