一种宫颈细胞学图像特征的处理方法及其装置与流程
本发明属于医疗影像数据处理领域,具体一种宫颈细胞学图像特征的处理方法及其装置。
背景技术
在宫颈癌的临床诊断中,病理诊断结果被认为是最权威,最准确的判别结果,也是在临床中诊断是否患有癌症的最重要的指标。在宫颈癌病理细胞学影像中中,临床医师能够在显微镜下,由专业的病理医生通过切片的移动,进而肉眼扫描整个切片,发现切片下的无上皮内病变/恶性病变细胞(nilm)、低级别鳞状上皮内病变(lsil)、高级别鳞状上皮内病变(hsil)等非常规细胞,这种工作对于有经验的医生来说是繁重而耗时的,并且随着阅片时间的增长,漏诊率也随之提高。
深度学习方法在图像处理领域取得了巨大的成就,这也为应用深度学习技术识别医疗图像数据中的病发部位提供了可能。目前,以深度学习为基础的cad(computeraideddiagnosis)系统,在识别并分割ct图像中的器官、病变区域等方面,就有着广泛的应用。人体组织的三维重建、定量分析都需要事先对有关部位进行分割,此外,图像分割还有助于引导手术、肿瘤放射治疗以及进行治疗评价,应用广泛。
物体检测(objectdetection)是计算机视觉的一个重要研究方向,其任务是通过计算机算法在图像中使用方形框标注出图像中的物体所在位置,并进行物体类别预测。物体检测任务在人脸识别,监控安防,医疗,航空航天,自动驾驶,工业制造等场景中都有着重要应用。在医疗影像中,物体检测常被检测ct中的病灶,或超声,mri影像中的器官,检测病理图像中的细胞等。
在1998年lecun等人首次提出了卷积神经网络(convolutionalneuralnetwork,ncc)lenet模型被美国许多银行用来识别支票上的手写数字之后。各种不同架构的cnn模型如vgg,resnet等在imagenet竞赛中取得多次比赛的冠军,cnn在图像处理与目标识别领域被广泛应用,成为深度学习在图像处理领域的通用神经网络。cnn在物体检测中被广泛使用:2015年kaiminghe等人提出的fasterrcnn在fastrcnn的基础上不仅提高了速度,而且在精度上也有很好的表现,同时,2015年由weiliu团队提出的ssd算法在速度上相比于fasterrcnn更加高效,在精度上略逊于fasterrcnn,fasterrcnn与ssd成为了两步法物体检测与单步物体检测的两个典型代表。
然而,由于医疗影像的分割与自然图像的差异较大,直接将一般的物体检测方法运用在医疗影像上往往效果不好,使物体检测在医疗上还有很长的路要走。
技术实现要素:
本发明提供一种基于fasterrcnn算法的宫颈细胞学图像特征的处理方法,并相应提供宫颈细胞学图像中非常规细胞的检测方法。本发明所述的常规细胞为人体正常细胞,非常规细胞与人体正常细胞相对应,为人体非正常形态细胞。
一种宫颈细胞学图像特征的处理方法,包括:
(1)准备n倍放大的宫颈细胞学图像以及图像中非常规细胞的标注框作为训练数据;所述的n取值范围为10~40的整数;
本发明优选n=20或n=40,其原因在于,20倍放大与40倍放大为医生常用显微镜放大倍数,利于与医生经验保持一致;
(2)对步骤(1)得到的训练数据压缩至分辨率r,并将宫颈细胞学图像数据增强后输入区域提名网络,得到区域提名框与宫颈细胞学图像特征图,所述r为500~2500的整数,优选512,1024,2048;
(3)在步骤(2)所得的宫颈细胞学图像特征图中,选择区域提名框对应的特征作为输入,通过网格池化层获得池化特征图;
(4)将池化特征图输入分类网络得到该区域的分类概率和预测框与提名框的偏移;
(5)分别计算步骤(2)中区域提名网络的损失与步骤(4)中分类网络的损失,求和得到最终损失函数l;
(6)使用反向传播方法优化l,使最终损失函数达到最小,得到收敛的fasterrcnn模型。
(7)改变步骤(2)中的压缩分辨率r,重复步骤(2)至步骤(6),得到多个收敛的fasterrcnn模型,使用非极大值抑制的方法对多个fasterrcnn的预测框进行筛选,保留置信度高的预测框;
本发明的处理方法还可以进一步包括步骤(8),(8)将未标注的图像压缩至步骤(2)所述分辨率r输入区域提名网络,输出可能含有非常规细胞的提名区域和该区域对应的特征图,将特征图输入网格池化层后再输入分类网络得到每种类别的概率与最终预测框与提名框的偏移,将最大预测概率的类别作为最终预测类别,并使用提名框与最终预测框偏移计算最终预测框的位置,使用非极大值抑制筛选多个模型预测框,得到最终预测结果;
步骤(2)中,每个标注框包括方框的左上角横坐标、纵坐标,方框的宽、高以及该方框对应的类别;方框对应的分类类别包括高级别鳞状上皮病变,低级别鳞状上皮病变,非典型鳞状细胞以及鳞状上皮癌等;
步骤(2)所述数据增强方法具体步骤为:
(2-1)对图像和标注框进行左右翻转
(2-2)对图像和标注框进行上下翻转
(2-3)对图像进行随机亮度改变
步骤(3)中的网格池化层的计算方式为:
(3-1)把输入的特征图分为k×k的网格
(3-2)将每个网格中的特征值求平均值
(3-3)得到k×k的池化特征图;其中k选自5-50的整数,优选6、7、8、9、10、11、12、13,更优选7。
步骤(2)中所述的区域提名网络与步骤(4)中的分类网络,其基础网络为经典分类网络,如vgg,resnet,inception等;
本发明优选使用resnet作为分类网络与区域提名网络的基础网络,原因在于,resnet中的残差模块有利于训练时的梯度回传,训练时更加容易收敛。在训练过程中,分类网络与区域提名网络的基础网络结构相同,因此共享参数;
步骤(5)中的区域提名网络损失的具体方法为:
(5-1)计算基础网络全连接层特征的centerloss;
所述centerloss的具体计算公式为:
其中,lc为计算得到的centerloss,m代表全连接层的特征总数,xi表示位置i所对应的特征值,
(5-2)计算区域提名网络输出的分类损失crossentropy;
(5-3)计算区域提名与标注框的距离损失,smoothl1loss;
(5-4)将以上三步的值相加,得到区域提名网络损失;
图像特征处理模块的分类网络损失的具体方法为:
(5-5)计算分类网络输出的分类损失crossentropy;
(5-6)计算分类网络预测的偏移与标注框的距离损失,smoothl1loss;
(5-7)将以上两部所得的值相加得到分类网络损失;
步骤(5-2)与(5-5)所述crossentropy的具体计算公式为:
其中y为类别的类别独热编码,
步骤(5-3)与(5-6)所述smoothl1loss的计算方法为:
其中,x是网络输出偏移与目标偏移的差值;
步骤(7)的具体步骤为:
(7-1)结果集合s初始置为空,所有预测框的集合设为s’;
(7-2)将所有预测框按置信度从高至低排序;
(7-3)选定当前置信度最高的预测框b,从s’移入s;
(7-4)在s’中选择面积重合超过th的预测框,并从s’中删除;所述th为0.5~0.8的小数,本发明优选0.5;
(7-5)重复(7-1)至(7-4)直至s’中没有剩余预测框,此时s即为保留的预测框;
本发明的方法与传统单模型fasterrcnn的区别在于:本发明在多种分辨率上训练多个fasterrcnn,并使用了非极大值抑制的方法筛选最终预测框,使模型对不同大小的非常规细胞预测结果更加稳定,因此提高了传统fasterrcnn的准确率,为了验证本发明提出的融合方法的有效性,设计实验:使用相同的7000张有病变标记的训练宫颈细胞学图像数据按照本发明描述的faster-rcnn模型训练方法,训练每个单模型至模型收敛,分别计算每个单模型的敏感度与特异性,再使用本发明提出的多分辨率预测框筛选方法对多个模型的结果进行融合后,再次计算融合模型的敏感度与特异性,两者进行比较。经过实验,本发明提出的多分辨率预测框筛选方法,相比于每个单模型fasterrcnn均有提升,敏感性平均提升10.5%,特异性提高5.6%。
本发明还提供一种宫颈细胞学图像特征的处理装置,包括图像输入模块、图像预处理模块、图像特征提取模块和图像特征处理模块;
其中图像输入模块,准备n倍放大的宫颈细胞学图像以及图像中非常规细胞的标注框作为训练数据;所述的n取值范围为10~40的整数;
图像预处理模块,对图像输入模块得到的训练数据,将宫颈细胞学图像数据增强后输入区域提名网络,得到区域提名框与宫颈细胞学图像特征图;
图像特征提取模块,在图像预处理模块所得的宫颈细胞学图像特征图中,选择区域提名框对应的特征作为输入,通过网格池化层获得池化特征图;
再将池化特征图输入分类网络得到该区域的分类概率和预测框与提名框的偏移;
图像特征处理模块,分别计算图像预处理模块中区域提名网络的损失与图像特征提取模块中分类网络的损失,求和得到最终损失函数l;
并使用反向传播方法优化l,使最终损失函数达到最小,得到收敛的fasterrcnn模型;
以及改变压缩分辨率r,得到多个收敛的fasterrcnn模型,使用非极大值抑制的方法对多个fasterrcnn的预测框进行筛选。
其中,图像输入模块中,每个标注框包括方框的左上角横坐标、纵坐标,方框的宽、高以及该方框对应的类别;方框对应的分类类别包括高级别鳞状上皮病变,低级别鳞状上皮病变,非典型鳞状细胞以及鳞状上皮癌等;
图像预处理模块中所述数据增强方法具体步骤为:
1、对图像和标注框进行左右翻转
2、对图像和标注框进行上下翻转
3、对图像进行随机亮度改变
图像特征提取模块中的网格池化层的计算方式为:
1、把输入的特征图分为k×k的网格
2、将每个网格中的特征值求平均值
3、得到k×k的池化特征图;其中k选自5-50的整数,优选6、7、8、9、10、11、12、13,更优选7。
图像预处理模块所述的区域提名网络与图像特征提取模块中的分类网络,其基础网络为经典分类网络,如vgg,resnet,inception等;
本发明优选使用resnet作为分类网络与区域提名网络的基础网络。在训练过程中,分类网络与区域提名网络的基础网络结构相同,因此共享参数;
图像特征处理模块的区域提名网络损失的具体方法为:
(5-1)计算基础网络全连接层特征的centerloss;
所述centerloss的具体计算公式为:
其中,lc为计算得到的centerloss,m代表全连接层的特征总数,xi表示位置i所对应的特征值,
(5-2)计算区域提名网络输出的分类损失crossentropy;
其中y为类别的类别独热编码,
(5-3)计算区域提名与标注框的距离损失,smoothl1loss;
(5-4)将以上三步的值相加,得到区域提名网络损失;
图像特征处理模块的分类网络损失的具体方法为:
(5-5)计算分类网络输出的分类损失crossentropy;
(5-6)计算分类网络预测的偏移与标注框的距离损失,smoothl1loss;
(5-7)将以上两部所得的值相加得到分类网络损失;
步骤(5-2)与(5-5)所述crossentropy的具体计算公式为:
其中y为类别的类别独热编码,
步骤(5-3)与(5-6)所述smoothl1loss的计算方法为:
其中,x是网络输出偏移与目标偏移的差值;
附图说明
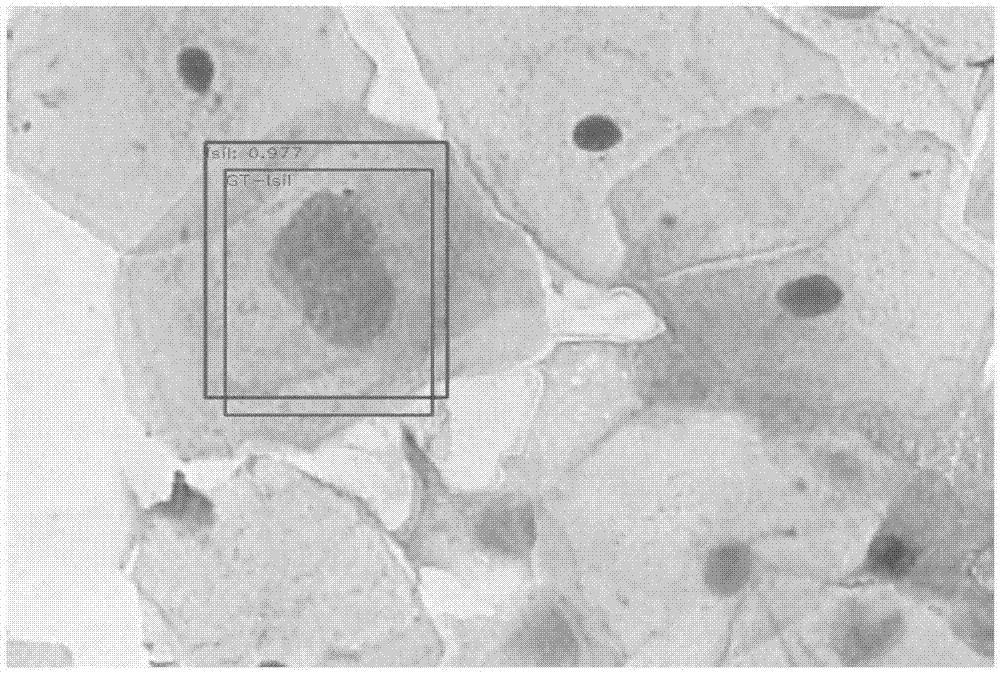
图1为本发明具体实施方法中输入宫颈细胞学图像、标注框与预测框。
图2为本发明训练单个fasterrcnn具体实施方法结构图。
图3为本发明筛选多模型预测框的示意图。
具体实施方式
为了进一步理解本发明,下面结合具体实施方法对本发明提供的具体一种宫颈细胞学图像中非常规细胞的检测方法进行具体描述,但本发明并不限于此,该领域技术人员在本发明核心指导思想下做出的非本质改进和调整,仍然属于本发明的保护范围。
实施例1、一种宫颈细胞学图像特征处理的方法,包括:
(1)准备40倍放大的宫颈细胞学图像以及图像中非常规细胞的标注框作为训练数据;每个标注框包括方框的左上角横坐标、纵坐标,方框的宽、高以及该方框对应的类别;方框对应的分类类别包括高级别鳞状上皮病变,低级别鳞状上皮病变,非典型鳞状细胞以及鳞状上皮癌等;
(2)对步骤(1)得到的训练数据压缩至分辨率r,并将宫颈细胞学图像数据增强后输入以resnet为基础网络的区域提名网络,得到区域提名框与宫颈细胞学图像特征图;
数据增强方法具体步骤为:
(2-1)对图像和标注框进行左右翻转
(2-2)对图像和标注框进行上下翻转
(2-3)对图像进行随机亮度改变
(3)在步骤(2)所得的宫颈细胞学图像特征图中,选择区域提名框对应的特征作为输入,通过网格池化层获得池化特征图。网格池化层的计算方式为:
(3-1)把输入的特征图分为7×7的网格
(3-2)将每个网格中的特征值求平均值
(3-3)得到7×7的池化特征图
(4)将池化特征图输入分类网络得到该区域的分类概率和预测框与提名框的偏移;
(5)分别计算步骤(2)中区域提名网络的损失与步骤(4)中分类网络的损失,求和得到最终损失函数l,区域提名网络损失的具体方法为:
(5-1)使用以下公式计算基础网络全连接层特征的centerloss:
其中,lc为计算得到的centerloss,m代表全连接层的特征总数,xi表示位置i所对应的特征值,
(5-2)使用crossentropy公式计算区域提名网络输出的分类损失;
(5-3)使用smoothl1公式计算区域提名与标注框的距离损失;
(5-4)将以上三步的值相加,得到区域提名网络损失;
分类网络损失的具体计算方法为:
(5-5)计算分类网络输出的分类损失crossentropy;
(5-6)计算分类网络预测的偏移与标注框的距离损失,smoothl1loss;
(5-7)将以上两部所得的值相加得到分类网络损失;
步骤(5-2)与(5-5)所述crossentropy的具体计算公式为:
其中y为类别的类别独热编码,
步骤(5-3)与(5-6)所述smoothl1loss的计算方法为:
其中,x是网络输出偏移与目标偏移的差值;
(6)使用反向传播方法优化l,使最终损失函数达到最小,得到收敛的fasterrcnn模型;
(7)改变步骤(2)中的压缩分辨率r,令r分别为512、1024、2048,重复步骤(2)至步骤(6),得到多个收敛的fasterrcnn模型,使用非极大值抑制的方法对多个fasterrcnn的预测框进行筛选,保留置信度高的预测框:
(7-1)结果集合s初始置为空,所有预测框的集合设为s’;
(7-2)将所有预测框按置信度从高至低排序;
(7-3)选定当前置信度最高的预测框b,从s’移入s;
(7-4)在s’中选择面积重合超过0.6的预测框,并从s’中删除;
(7-5)重复(7-1)至(7-4)直至s’中没有剩余预测框,此时s即为保留的预测框;
(8)将未标注的图像压缩至步骤(2)所述分辨率r输入区域提名网络,输出可能含有非常规细胞的提名区域和该区域对应的特征图,将特征图输入网格池化层后再输入分类网络得到每种类别的概率与最终预测框与提名框的偏移,将最大预测概率的类别作为最终预测类别,并使用提名框与最终预测框偏移计算最终预测框的位置,使用非极大值抑制筛选多个模型预测框,得到最终预测结果。
实施例2、一种宫颈细胞学图像特征处理的方法,包括:
(1)准备20倍放大的宫颈细胞学图像以及图像中非常规细胞的标注框作为训练数据;每个标注框包括方框的左上角横坐标、纵坐标,方框的宽、高以及该方框对应的类别;方框对应的分类类别包括高级别鳞状上皮病变,低级别鳞状上皮病变,非典型鳞状细胞以及鳞状上皮癌;
(2)对步骤(1)得到的训练数据压缩至分辨率r,并将宫颈细胞学图像数据增强后输入以resnet为基础网络的区域提名网络,得到区域提名框与宫颈细胞学图像特征图;
数据增强方法具体步骤为:
(2-1)对图像和标注框进行左右翻转
(2-2)对图像和标注框进行上下翻转
(2-3)对图像进行随机亮度改变
(3)在步骤(2)所得的宫颈细胞学图像特征图中,选择区域提名框对应的特征作为输入,通过网格池化层获得池化特征图。网格池化层的计算方式为:
(3-1)把输入的特征图分为10×10的网格
(3-2)将每个网格中的特征值求平均值
(3-3)得到10×10的池化特征图
(4)将池化特征图输入分类网络得到该区域的分类概率和预测框与提名框的偏移;
(5)分别计算步骤(2)中区域提名网络的损失与步骤(4)中分类网络的损失,求和得到最终损失函数l,区域提名网络损失的具体方法为:
(5-1)使用以下公式计算基础网络全连接层特征的centerloss:
其中,lc为计算得到的centerloss,m代表全连接层的特征总数,xi表示位置i所对应的特征值,
(5-2)使用crossentropy公式计算区域提名网络输出的分类损失;
(5-3)使用smoothl1公式计算区域提名与标注框的距离损失;
其中,x是网络输出偏移与目标偏移的差值;
(5-4)将以上三步的值相加,得到区域提名网络损失;
分类网络损失的具体计算方法为:
(5-5)计算分类网络输出的分类损失crossentropy;
(5-6)计算分类网络预测的偏移与标注框的距离损失,smoothl1loss;
(5-7)将以上两部所得的值相加得到分类网络损失;
所述的crossentropy与smoothl1loss计算方式与(5-2)、(5-3)相同;
步骤(5-2)与(5-5)所述crossentropy的具体计算公式为:
其中y为类别的类别独热编码,
步骤(5-3)与(5-6)所述smoothl1loss的计算方法为:
其中,x是网络输出偏移与目标偏移的差值;
(6)使用反向传播方法优化l,使最终损失函数达到最小,得到收敛的fasterrcnn模型;
(7)改变步骤(2)中的压缩分辨率r,令r分别为500、1000、2000,重复步骤(2)至步骤(6),得到多个收敛的fasterrcnn模型,使用非极大值抑制的方法对多个fasterrcnn的预测框进行筛选,保留置信度高的预测框:
(7-1)结果集合s初始置为空,所有预测框的集合设为s’;
(7-2)将所有预测框按置信度从高至低排序;
(7-3)选定当前置信度最高的预测框b,从s’移入s;
(7-4)在s’中选择面积重合超过0.5的预测框,并从s’中删除;;
(7-5)重复(7-1)至(7-4)直至s’中没有剩余预测框,此时s即为保留的预测框;
(8)将未标注的图像压缩至步骤(2)所述分辨率r输入区域提名网络,输出可能含有非常规细胞的提名区域和该区域对应的特征图,将特征图输入网格池化层后再输入分类网络得到每种类别的概率与最终预测框与提名框的偏移,将最大预测概率的类别作为最终预测类别,并使用提名框与最终预测框偏移计算最终预测框的位置,使用非极大值抑制筛选多个模型预测框,得到最终预测结果。
- 还没有人留言评论。精彩留言会获得点赞!