基于双分支网络的高光谱分类方法与流程
本发明属于图像处理技术领域,具体涉及基于双分支网络的高光谱分类方法。
背景技术
高分辨率的高光谱图像不仅可以显示地物的几何结构和空间信息,而且,还包含了丰富的光谱信息。因此,高光谱图像为广泛的应用提供了基础,如地面物体识别与分类,矿物勘探,精准农业等。对于这些应用而言,最基本任务就对是高光谱图像的分类。但是,在高光谱图像的分类中,还面临许多挑战,例如,类间相似性,训练数据有限,样本不平衡等等。
为了解决这些问题,许多研究者提出了不同的解决方案。起初,bigdeli等人应用支持向量机(svm)来解决这一问题。后来,随机森林和无监督的聚类方法(如k-均值,模糊聚类)也被应用来解决这个问题。现如今在目标检测、人脸图像识别、语音识别、图像配准等领域表现非凡的深度学习也逐步被应用于这一领域。
lietal.等人发表的论文“hyperspectralimageclassificationusingdeeppixel-pairfeatures”(ieeetransactionsongeoscienceremotesensing,55(2),pp.844-853,2016.)中提出了一种像素对的方法,该方法被用于缓解有限的训练样本的问题。对于测试像素,通过组合中心像素和每个周围像素构建像素对,再由训练的cnn分类,然后最终标签由投票策略确定。该方法利用cnn网络学习像素对的特征,具有较强的分类能力,但是对于空间特征和光谱特征融合后的特征分类能力较差。
xiaodongxu等人发表的论文“multisourceremotesensingdataclassificationbasedonconvolutionalneuralnetwork”(ieeetransactionsongeoscienceremotesensing(99),pp.1-13,2017)中提出了一个双分支网络(2d+1d),分别使用二维卷积网络和一维卷积网络提取空间特征和光谱特征,然后融合特征进行最终分类。然而,一维卷积网络的输入是仅由中心像素组成的矢量,当它们是噪声或混合像素时,这种网络的分类性能将会大幅度下降。
技术实现要素:
本发明的目的在于提供基于双分支网络的高光谱分类方法,解决了现有的对高光谱图像进行分类的方法分类能力差的问题。
为了达到上述目的,本发明采用的技术方案是:
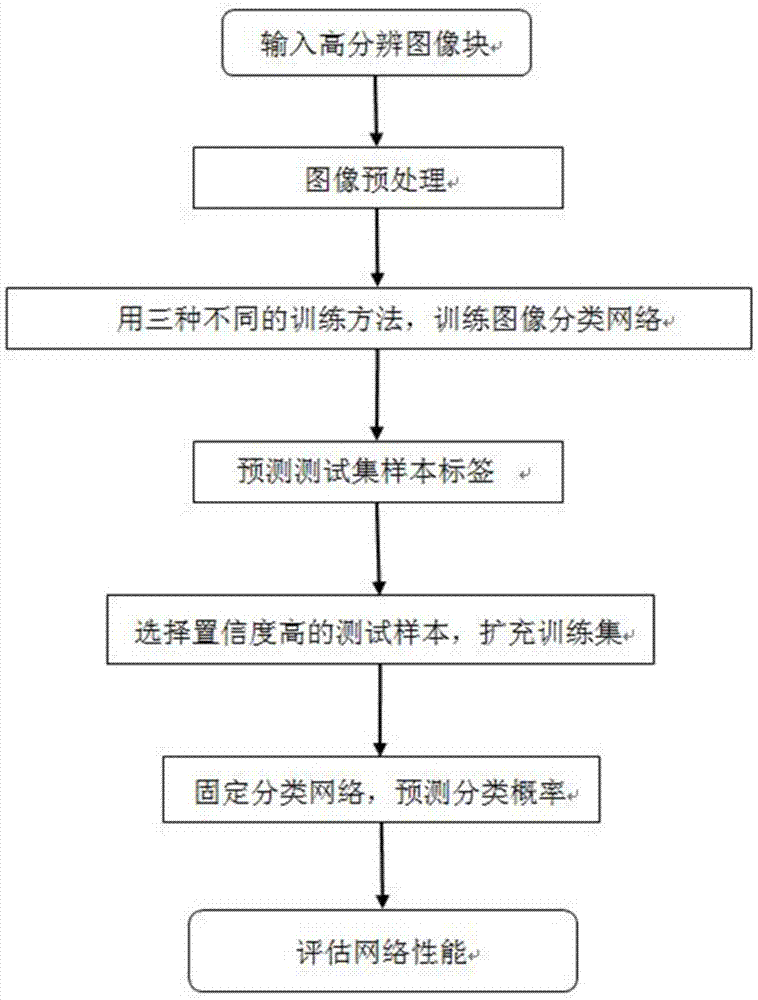
本发明提供的基于双分支网络的高光谱分类方法,包括以下步骤:
步骤1),将待处理的高光谱图像数据进行预处理,得到预处理后的高光谱图像;
步骤2),将步骤1)中所得的预处理高光谱图像进行制作并划分,得到训练样本和测试样本;
步骤3),将步骤2)中得到的训练样本进行数据重采样,得到一个批次的平衡样本;
步骤4),将步骤3)中得到的一个批次的平衡样本,输入到双分支网络结构中,分别得到特征向量f1和特征向量f2,并将特征向量f1和特征向量f2进行级联得到特征向量f;
步骤5),利用三种训练方式分别对步骤4)中的双分支网络结构进行训练,得到三种训练模型;
步骤6),将测试样本分别输入到步骤5)得到的三种训练模型中进行预测,得到三个测试样本中每类像素点对应的预测标签及该预测标签对应的置信度;
步骤7),若三种训练模型中有两个训练模型预测的测试样本中每类像素点对应的预测标签相同,且该预测标签对应的置信度至少为90%,则将该预测标签假定为真实标签,并将该真实标签对应的测试样本放入步骤2)中的训练样本中,反之,则执行步骤8);
步骤8),重复迭代步骤3)至步骤7),直至三种训练模型输出的预测结果趋于稳定为止,得到最终的预测结果。
优选地,步骤1)中,将训练数据进行预处理的具体方法是:
第一步,使用立方插值法将高光谱图像的分辨率调整为与地面真实的分辨率一致;
第二步,将高光谱图像的所有光谱信息用z-score标准化,使其分布的均值和方差分别为0和1。
优选地,步骤2)中,对预处理高光谱图像进行制作并划分的具体方法是:
首先,在该高光谱图像上以每个像素点为中心,剪切边长为a的正方形图像块,同时将该正方形图像块的所属类别记为其中心像素点的所属类别;
然后,从该高光谱图像的左上角开始,将每类像素按出现的先后顺序进行排序,并将该类像素的前30%作为训练样本,剩余为测试样本。
优选地,步骤3)中,数据重采样的具体方法是:
第一步,从步骤2)中得到的训练样本中,有放回的随机采样相同数量的每类样本,并放入临时数据池中;
第二步,在临时数据池中随机选取一部分数据作为双分支网络结构的输入。
优选地,步骤4)中,双分支网络结构包括上分支网络和下分支网络,其中,上分支网络包括三层网络结构,第一层上分支网络结构和第二层上分支网络结构相同,均包括卷积层,卷积层连接有一个激活函数和一个池化层;第三层上分支网络结构包括卷积层,卷积层连接有一个激活函数;
下分支网络包括三层网络结构,第一层下分支网络结构包括卷积层,卷积层连接有一个激活函数和一个池化层;第二层下分支网络结构包括卷积层,卷积层连接有一个激活函数;第三层下分支网络结构包括双线性插值,双线性插值连接有池化层。
优选地,双分支网络结构构建的具体方法是:
将数据重采样之后得到的一个批次的平衡样本作为数据源输入到双分支网络结构中的上分支网络中,经过卷积、池化及全连接操作后得到对应的特征向量f1;
同时,在该批次的平衡样本上,以每个样本的中心点为中心,随机剪切边长为b的正方形图像块,并将该正方形图像块输入到下分支网络中,经过卷积、池化、双线性插值及全连接操作后得到特征向量f2;
最后,将特征向量f1和特征向量f2进行级联得到新的特征向量f。
优选地,步骤5)中,三种训练方式分别对步骤4)中的双分支网络结构进行训练的具体方法是:
第一种训练方式的具体方法是:将步骤4)中所得的新的特征向量f经过全连接层产生交叉熵,之后将所得到的交叉熵进行优化级联,得到第一种训练模型;
第二种训练方式的具体方法是:首先,将步骤4)中所得的新的特征向量f经过全连接层后产生交叉熵,然后优化此交叉熵;其次,分别将特征向量f1和特征向量f2经过全连接层产生两个交叉熵,分别对该两个交叉熵进行优化;最后得到第二种训练模型;
第三种训练方式的具体方式是:首先,训练双分支网络结构中的上分支网络并使其达到最优;其次,分别将步骤4)中所得的新的特征向量f和特征向量f2经过全连接层产生两个交叉熵,分别对该两个交叉熵进行优化;最后得到第三种训练模型。
优选地,所述的交叉熵损失的计算方法,按如下步骤进行:
第一步,将特征向量经过全连接层和softmax函数后,得到模型预测的输入样本类别的概率分布
第二步,对于单个样本交叉熵损失为:
其中,{y1,y2,...,yi,...,yc}为输入数据的真实标签分布,
与现有技术相比,本发明的有益效果是:
本发明提供的基于双分支网络的高光谱分类方法,首先,通过数据重采样的方法,既保证训练过程中的每次迭代时输入数据各类别样本数量不是恒定相等的,又能保证在统计学上参与训练的每类样本是均衡的。这样不仅有效缓解了网络学习中的样本不平衡问题,同时保持了数据的多样性;为了提取数据多尺度特征,本发明使用了双分支的网络结构,通过三种训练策略,进行半监督学习,这样不仅扩充了训练集,而且通过集成学习策略,相比于其他分类方法,极大程度的提高了分类精度。本发明提出的基于双分支网络的高光谱分类方法不仅在性能上优于其他方法,而且在训练效率上也优于其他方法。
附图说明
图1是本发明的流程示意图;
图2是本发明使用的整体网络结构图;
图3是本发明使用的高光谱数据集对应的光学图像;
图4是本发明使用的高光谱数据对应的真实标签的伪彩图;
图5是本发明使用的高光谱数据每类样本数量的分布及每类标注颜色;
图6是本发明使用的本方法产生的预测结果伪彩图。
具体实施方式
下面结合附图,对本发明进一步详细说明。
如图1、图2所示,本发明提供的基于双分支网络的高光谱分类方法,包括以下步骤:
步骤1),将待处理的高光谱图像数据进行预处理,得到预处理后的高光谱图像;预处理的方法具体包括有如下步骤:
第一步,由于待处理的高光谱数据和地面真实的分辨率不同,利用立方差值将训练数据的高光谱图像的分辨率调整为与地面真实的分辨率一致;
第二步,为了利用光谱信息,将高光谱图像的所有光谱信息用z-score标准化,使其分布的均值和方差分别为0和1。
步骤2),将步骤1)中所得的预处理高光谱图像进行制作并划分,得到训练样本和测试样本,具体地:
首先,在该高光谱图像上以每个像素点为中心,剪切边长为a的正方形图像块,同时将该正方形图像块的所属类别记为其中心像素点的所属类别;
然后,从该高光谱图像的左上角开始,将每类像素按出现的先后顺序进行排序,并将该类像素的前30%作为训练样本,剩余为测试样本;
步骤3),将步骤2)中得到的训练样本进行数据重采样,得到一个批次的平衡样本,用于缓解样本不平衡产生的网络倾斜问题;数据重采样的方法具体包括有如下步骤:
第一步,从训练样本数据池中有放回的随机采样相同数量的每类样本,并放入临时数据池中;
第二步,随机选取临时数据池中的一部分数据作为双分支网络结构的输入。
步骤4),将步骤3)中得到的一个批次的平衡样本,输入到双分支网络结构中,分别得到特征向量f1和特征向量f2,并将特征向量f1和特征向量f2进行级联得到特征向量f;
其中,双分支网络结构包括上分支网络和下分支网络,其中,上分支网络包括三层网络结构,第一层上分支网络结构和第二层上分支网络结构相同,均包括卷积层,卷积层连接有一个激活函数和一个池化层;第三层上分支网络结构包括卷积层,卷积层连接有一个激活函数;
下分支网络包括三层网络结构,第一层下分支网络结构包括卷积层,卷积层连接有一个激活函数和一个池化层;第二层下分支网络结构包括卷积层,卷积层连接有一个激活函数;第三层下分支网络结构包括双线性插值,双线性插值连接有池化层,通过双线性插值操作将变化的输入尺寸统一调整到固定的尺寸。
将一个批次的平衡样本输入到双分支网络结构中的具体方法是:
将一个批次的平衡样本作为数据源输入到双分支网络结构中的上分支网络中,经过卷积、池化及全连接操作后得到对应的特征向量f1;
同时,在该批次的平衡样本上,以该平衡样本的中心点为中心,随机剪切边长为b的正方形图像块,并将该正方形图像块输入到下分支网络中,经过卷积、池化、双线性插值及全连接操作后得到特征向量f2;
最后,将特征向量f1和特征向量f2进行级联得到新的特征向量f。
步骤5),利用三种训练方式分别对步骤4)中的双分支网络结构进行训练,得到三种训练模型;
其中,三种训练方式分别对步骤4)中的双分支网络结构进行训练的具体方法是:
第一种训练方式的具体方法是:将步骤4)中所得的新的特征向量f经过全连接层产生交叉熵,之后将所得到的交叉熵进行优化级联,得到第一种训练模型;
第二种训练方式的具体方法是:首先,将步骤4)中所得的新的特征向量f经过全连接层后产生交叉熵,然后优化此交叉熵;其次,分别将特征向量f1和特征向量f2经过全连接层产生两个交叉熵,分别对该两个交叉熵进行优化;最后得到第二种训练模型;
第三种训练方式的具体方式是:首先,训练双分支网络结构中的上分支网络并使其达到最优;其次,分别将步骤4)中所得的新的特征向量f和特征向量f2经过全连接层产生两个交叉熵,分别对该两个交叉熵进行优化;最后得到第三种训练模型;
其中,交叉熵损失的计算方法,按如下步骤进行:
第一步,将特征向量经过全连接层和softmax函数后,得到模型预测的输入样本类别的概率分布
第二步,对于单个样本交叉熵损失为:
其中,{y1,y2,...,yi,...,yc}为输入数据的真实标签分布,
步骤6),将测试样本分别输入到步骤5)得到的三种训练模型中进行预测,得到三个测试样本中每类像素点对应的预测标签及该预测标签对应的置信度;
步骤7),若三种训练模型中有两个训练模型预测的测试样本中每类像素点对应的预测标签相同,且该预测标签对应的置信度至少为90%,则将该预测标签假定为真实标签,并将该真实标签对应的测试样本放入步骤2)中的训练样本中;反之,则执行步骤8);
步骤8),重复迭代步骤3)至步骤7),直至测试集上得到的准确率不再提升为止。
基于双分支网络的高光谱分类方法是图像理解与分类领域里一项最基本的任务之一。高光谱图像为广泛的应用提供了基础,如地面物体识别与分类,矿物勘探,精准农业等。因此高光谱分类方法越来越受到人们的关注。目前针对基于卷积神经网络的图像分类技术一般采用多分支网络结构,用来提取数据多尺度特征,再用全连接层对数据多尺度信息进行分类。然而,本发明通过增加三种不同的训练方式,得到分类结果,使用半监督的学习策略,较好的解决了样本不平衡和小样本学习问题,大幅度提高了分类的准确度。
实施例1
本发明步骤(3)中的数据重采样的方法,由于给定的高光谱数据严重不平衡,例如建筑和道路有足够的训练样本,然而,水,未铺成的停车场和人造草坪不到三千。因此,样本不平衡会造成网络性能底下,为了解决这个问题,本发明提出了重采样的方法,具体包括有如下步骤:
(3a)从每类数据中随机采样相同数量的样本,并放入临时数据池中;
(3b)随机选取临时数据池中的一部分数据作为网络的输入。
通过重采样的方法,即能保证训练过程中的每次迭代的输入数据各类别数量不是恒定相等的,又能保证在统计学上参与训练的每类样本是均衡的,这样就有效缓解了网络学习中的样本不平衡问题。
实施例2
本发明步骤(4)中提取数据多尺度特征的方法见双分支网络结构示意图,通过分析表明,在该问题的解决中多尺度特征起到了重要作用,因此,本发明设计了一个双分支网络结构,整个网络的输入尺寸为17×17的图像块,其标签由图像块的中心点的类别决定。该网络主要由两部分构成,具体包括有如下部分:
(4a)在上分支网络中,进一步将图像块裁剪为16×16,通过卷积层,归一化层,激活函数层和池化层的处理,最终特征通过扁平操作,形成特征向量f1;
(4b)下分支网络相比于上分支网络更加注重多尺度信息,所以,在不改变其中心点位置的条件下,随机裁剪它的输入,其裁剪范围为[8×8~12×12]。并且为了保持下分支网络输出大小固定,本发明在第二分支的最后一层,使用双线性差值操作统一特征大小。
这两个分支架构使本发明能够从多尺度的视图学习特征,并且使网络专注图像块的中心而不是边缘。
仿真实验条件:
本发明仿真实验的硬件平台是:戴尔计算机intel(r)core5处理器,主频3.20ghz,内存64gb;仿真软件平台是:spyder软件(python3.5)版。
仿真实验内容与结果分析:
本发明的仿真实验具体分为两个仿真实验,所使用的高光谱图像和其标签,如图3至图5所示。每种颜色代表每种像素点所属类别,且伪彩图每个颜色所属的类别与图5对应。每一组的标签在图像块的中心点处,通过网络不断迭代训练,分类结果趋于稳点,保存网络权重。然后,固定网络分支二,在测试集上进行标签预测。
仿真实验1:本发明与现有技术的对比。采用本发明与现有技术中基于双分支网络的高分辨分类方法,先进行半监督的学习策略,然后,载入预先训练好的权重,进行预测。评价结果如表1所示,通过对比三种不同训练方式,2d+1d方式,和本发明提出的重采样多尺度学习方法,在三种衡量指标(平均准确度(aa),总体准确度(oa)和卡伯系数)下的表现,对比来衡量分类网络的精度。
表1
如上表1、及如图6通过本发明预测的测试样本的伪彩图,可以得到:本发明提出的三种训练模型,在aa评价指标和卡波尔系数评价指标上均优于2d+1d方法,在oa评价指标上与2d+1d方法精度持平,这个结果表明本发明的数据重采样和多尺度特征学习方法,整体性能优于2d+1d方法。在最后一个方法中本发明进一步整合了三个模型,并使用了半监督的学习策略,毫无意外,本发明分类方法整体性能比2d+1d方法有了大幅度的提高。
- 还没有人留言评论。精彩留言会获得点赞!