一种多并发三角形2度循环的过程模型挖掘方法与流程
本发明涉及多并发三角形2度循环过程模型挖掘领域,具体涉及一种多并发三角形2度循环的过程模型挖掘方法。
背景技术
随着计算机、互联网的发展,越来越多的企业采用信息系统处理业务,这些信息系统会产生大量的日志文件。过程挖掘作为一门新兴学科,旨在从这些日志文件中提取有价值的过程相关信息。过程挖掘主要有过程发现(processdiscovery)、合规性检查(processconformance)和过程改进(processenhancement)三个方面的应用。过程发现是过程挖掘中最富有挑战性的任务之一。
通常,过程发现就是使用不包括任何先验信息的事件日志生成模型的过程。在得到模型后,一般采用拟合度、精确度、简化度和泛化度这四个标准评价过程模型。拟合度表示日志中的迹在模型中重演的能力;精确度表示模型重演日志的能力;简化度表示模型的复杂程度;泛化度表示模型允许未来行为的能力。拟合度和精确度是判断过程模型最重要的两个标准。
不同背景下,针对过程发现中出现的不同问题,国内外学者提出了诸多过程发现的算法。文献:wilvda,weijterst,marusterl.workflowmining:discoveringprocessmodelsfromeventlogs.ieeetransactionsonknowledge&dataengineering[j],2004,16(9):1128-1142,提出的alpha算法,该算法根据活动的次序判断活动之间的关系,但是该算法无法挖掘短循环(只含有一个活动或者两个活动组成的循环)。
文献:wenlijie,vanderaalstwmp,wangjianmin,etal.miningprocessmodelswithnon-free-choiceconstructs[j].datamingingandknowledgediscoverry,2007,15(2):145-180,提出alpha++算法,解决了非自由选择结构的问题。文献:weijtersajmm,dongenbfv,medeirosaka.processmining:extendingthe–algorithmtomineshortloops[c].springerberlinheidelberg,2004:151-165,提出alpha+算法来挖掘短循环(循环中活动少于三个),但是要求日志是完全完备的。然而,当日志只满足局部完备性,并且不含有明显的“aba”等循环显式行为时,alpha及其扩展算法均不能挖掘出正确的模型。文献:weijtersajmm,aalstwmp,medeirosaka.processmingingwiththeheuristicsmineralgorithm[j].eindhovenuniversityoftechnology,2006:1-34,提出启发式过程挖掘算法,该算法根据依赖关系重演日志,算法在不完备的、有噪声的日志处理上有很大优势,但是对于短循环处理能力一般。文献:medeirosakad,weijtersajmm,aalstwmpvd.geneticprocessmining:anexperimentalevaluation[m].datamining&knowledgediscovery,2007,14(2):245-304,将遗传算法思想用于过程挖掘,该方法有着良好的并行能力,日志处理速度快,但是当短循环隐藏在规模很大的模型中时,效率并不是很高。文献:j.m.e.m.vanderwerf,dongenbfv,hurkencaj,etal.processdiscoveryusingintegerlinearprogramming[j].fundamentainformaticae,2008,94(3):368-387,提出ilp算法(整数线性规划算法),该算法一定程度上能解决短循环挖掘问题,但是对日志完备性要求较高。文献:林雷蕾,周华,代飞,等.一种挖掘二度循环的扩展alpha算法[j].计算机集成制造系统,2018,24(03):591-601,创新性地将2度循环划分为三角形2度循环和菱形2度循环,并提出紧邻度模型解决无循环显式行为时的2度短循环挖掘。紧邻度模型在一定程度上能够解决该问题。但是紧邻度模型是依据相关性计算的概率模型,依赖于大量日志。当日志量比较少或者三角形2度循环中的活动紧邻行为较少时,识别三角形2度循环存在一定局限性,即对于多个三角形2度循环并发时,匹配三角形2度循环中的活动很容易出现偏差。
技术实现要素:
针对现有的多并发三角形2度循环在挖掘时,存在挖掘的结果模型很容易与原模型出现偏差的问题,本发明的目的都是提供了一种多并发三角形2度循环的过程模型挖掘方法。
本发明采用以下的技术方案:
一种多并发三角形2度循环的过程模型挖掘方法,包括以下步骤:
步骤1:根据三角形2度循环的定义提出三角形2度循环并发块,依据数量特征将活动分为主体活动和回调活动;
定义三角形2度循环,用δ>l或<δl表示;
设n=(p,t;f,m)是一个petri网模型,a,b是n中的两个变迁,aδ>lb或b<δla当且仅当:
(1)
(2)假设m1∈r(m0),使得m1[a>m2,且不存在m1[σ>m2,其中σ为发生序列,则仅存在m2[b>m1,若m2非最终标识且存在m2[x>m3,其中x∈t,a≠x≠b;
设活动ai,bi构成三角形2度循环,满足aiδ>lbi或bi<δiai,ai为主体活动,bi为回调活动,称所有主体活动构成的集合和所有回调活动的集合分别为主体活动集合和回调活动集合,其形式化定义如下:
定义主体活动集合和回调活动集合
设bol为主体活动集合,cl为回调活动集合,其中:
(1)
(2)
定义三角形2度循环并发块
设二元组(a1,b1),(a2,b2),……,(an,bn)中的活动均满足aiδ>lbi,当n个三角形2度循环并发时,存在唯一的变迁x和y,满足:
(1)x=●(●a1)∩●(●a2)∩……∩●(●an);
(2)y=(a1●)●∩(●a2●)●∩……∩(an●)●;
称x,y与n个并发的三角形2度循环组成的结构为三角形2度循环并发块,其中hδ=x为块首活动,tδ=y为块尾活动;
迹中连续发生的两个活动构成直接跟随关系,利用直接跟随关系能判断并发关系、因果关系,直接跟随集合的定义如下:
定义直接跟随集合
直接跟随集合dl中的元素是迹中所有构成>l关系的活动组成的二元组,即
构成循环结构的活动会在日志中多次出现,活动的次数关系是判断循环的一个重要参考,下面给出活动出现次数的定义:
定义活动出现次数
设日志l,迹σ∈l,活动a∈σ,sum(a,σ)表示活动在迹中的出现次数,sum(a,l)表示活动在日志中出现的总次数;
算法1主体活动和回调活动的分类算法
输入:满足局部完备性的日志l;
输出:主体活动集合bol和回调活动集合cl;
步骤(1):创建来统计活动次数的一维数组ltm,创建直接跟随集合dl,主体活动集合bol,回调活动集合cl以及三角形2度循环并发块块首活动hδ并进行初始化;
步骤(2):遍历日志l,将起始活动放入开始活动集合ti,将结束活动放入结束活动集合to,将所有活动放入活动集合tl,并且将连续出现的活动组成二元组,将二元组放入直接跟随集合dl中;
步骤(3):遍历日志l,统计活动集合tl中活动出现的次数,将次数放入一维数组ltm对应的位置;
步骤(4):遍历一维数组ltm,如果数组中两元素之差大于0,并且两元素对应的活动在日志中处于并发关系,则遍历日志中的任意一条迹,将两活动中首先出现的活动之前的一个活动赋值为三角形2度循环并发块块首活动hδ;
步骤(5):遍历活动集合tl,将与块首活动hδ满足因果关系的活动放入主体活动集合bol,将与主体活动集合中活动满足并发关系和直接跟随关系的活动放入回调活动集合cl中;
步骤(6):返回主体活动集合bol和回调活动集合cl;
步骤2:定义活动首次在迹中出现的位置,采用剪枝的思想将不正确的活动匹配删除,从而得到正确的活动匹配;
定义活动首次在迹中出现的位置
设迹σ∈l,活动a∈σ,first(a,σ)表示活动a在迹σ中第一次出现时的位置下标;
定义首次标记位置矩阵
设日志l,集合bol∪cl,则首次标记位置矩阵为fm[|l|][|bol∪cl|],满足
利用首次标记位置矩阵获得匹配结果,所有匹配结果构成的集合被称作匹配结果集合,匹配结果和匹配结果集合的定义如下:
定义匹配结果和匹配结果集合
匹配结果是一个二元组mtl=(a,b),其中a为主体活动,b为回调活动,二元组中的活动不能同时为主体活动或者回调活动,即
匹配结果集合mtl是由匹配结果mtl组成的集合,即mtl={(a,b)|(a∈bol∧b∈cl)∨(b∈bol∧a∈cl)};
算法2主体活动和回调活动匹配算法
输入:满足局部完备性的日志l,主体活动集合bol,回调活动集合cl;
输出:匹配结果集合mtl;
步骤(1):创建首次标记位置矩阵fm[|l|][|bol∪cl|],匹配结果集合mtl和匹配结果mtl1并进行初始化;
步骤(2):将主体活动集合bol和回调活动集合cl中的活动做笛卡尔积,将组成的二元组赋值给mtl1,并将所有的mtl1放入匹配结果集合mtl中;
步骤(3):遍历日志l,将l中属于集合bol∪cl的活动首次在迹中出现的位置记录下来并存储在二维数组fm[|l|][|bol∪cl|]中对应的位置;
步骤(4):遍历二维数组fm[|l|][|bol∪cl|],若回调活动集合cl中的活动位置小于主体活动集合bol中的位置,则将匹配结果集合mtl中这个活动的笛卡尔积删除;
步骤(5):返回匹配结果集合mtl;
步骤3:得出alphamatch算法,完成多并发三角形2度循环的过程模型挖掘;
定义alphamatch算法
设l为一个基于活动的日志,那么alphamatch(l)定义如下:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)pl={p(a,b)|(a,b)∈yl}∪{il,ol};
(10)fl={(a,p(a,b))|(a,b)∈yl∧a∈a}∪{(p(a,b),b)|(a,b)∈yl∧b∈b}∪{(il,t)|t∈ti}∪{(t,ol)|t∈to};
(11)alphamatch(pl,tl,fl);
alphamatch算法先将主体活动和回调活动进行分类,再对主体活动与回调活动匹配,最后返回正确匹配的结果集mtl,并获得结果集中活动间的关系。
本发明具有的有益效果是:
本发明提供的多并发三角形2度循环的过程模型挖掘方法,首先,根据三角形2度循环的定义提出三角形2度循环并发块的概念,并且依据数量特征将活动分为主体活动和回调活动,然后,依据活动首次在迹中首次出现的位置,采用剪枝的思想将不正确的活动匹配删除,从而得到正确的活动匹配。该方法实现简单,易于操作,对日志完备性依赖程度低,准确性高,不会挖掘出日志中不存在的关系。
最后,将算法以插件形式在prom平台实现,经过实验分析,验证了本文算法能够正确有效的挖掘多并发三角形2度循环,并且该方法得到的模型有着更高的精确度和拟合度。
附图说明
图1为塑料浇筑模具生产过程模型。
图2为alpha+算法挖掘l2日志结果图。
图3为三角形并发块的结构图。
图4为alphamatch算法挖掘结果图。
图5为滚珠轴承生产的原模型。
图6为实施例1的alpha+挖掘的模型。
图7为实施例1的ilp算法挖掘的模型。
图8为实施例1的inductiveminer-infrequent(imf)算法挖掘的模型。
图9为实施例1的alphamatch算法挖掘的模型。
图10为拟合度对比图。
图11为精确度对比图。
具体实施方式
下面结合附图和具体实施例对本发明的具体实施方式做进一步说明:
定义迹和事件日志
设a为活动的集合,迹σ∈a*是活动队列,事件日志l是迹的多集,即l∈b(a*)。
petri网是用于描述分布式系统的一种模型,它能描述系统的结构,又能模拟系统的运行。从形式上看petri网是一个没有孤立节点的有向二分图。
定义petri网
petri网是一个四元组n=(p,t;f,m),其中p是库所的有限集合,t是变迁的有限集合。n满足:
(1)
(2)
(3)
(4)m:p→{1,2,3,...}称为n的一个标识,m0表示初始标识。
(5)dom(f)∪cod(f)=p∪t。
其中,
定义前集和后集
设n=(p,t;f,m)是一个petri网。对于x∈p∪t,记
●x={y|y∈p∪t∧(y,x)∈f}
x●={y|y∈p∪t∧(x,y)∈f}
称●x为x的前集,称x●为x的后集。
迹中任意两个活动构成不同的次序关系,四种常见的次序关系如下:
定义基于日志的次序关系
设l为一个基于活动的事件日志,σ为日志中的迹,a、b是日志l中出现的任意两个活动。那么:
(1)a>lb当且仅当存在一个迹σ=<t1,t2,t3,...tn>,i∈{1,2,3,4,...,n-1},使得σ∈l,ti=a并且ti+1=b;
(2)a→lb当且仅当a>lb并且不存在b>la。
(3)a#lb当且仅当不存在a>lb也不存在b>la。
(4)a||lb当且仅当a>lb并且b>la。
下面详细介绍一下多并发三角形2度循环的过程模型挖掘方法。
一种多并发三角形2度循环的过程模型挖掘方法,包括以下步骤:
步骤1:根据三角形2度循环的定义提出三角形2度循环并发块,依据数量特征将活动分为主体活动和回调活动;
定义三角形2度循环,用δ>l或<δl表示
设n=(p,t;f,m)是一个petri网模型,a,b是n中的两个变迁。aδ>lb或b<δla当且仅当:
(1)
(2)假设m1∈r(m0),使得m1[a>m2,且不存在m1[σ>m2,其中σ为发生序列,则仅存在m2[b>m1,若m2非最终标识且存在m2[x>m3,其中x∈t,a≠x≠b;
定义alpha算法
设l表示一个基于活动的事件日志,那么alpha(l)的定义如下:
(1)
(2)
(3)
(4)
(5)
(6)pl={p(a,b)|(a,b)∈yl}∪{il,ol};
(7)fl={(a,p(a,b))|(a,b)∈yl∧a∈a}∪{(p(a,b),b)|(a,b)∈yl∧b∈b}∪{(il,t)|t∈ti}∪{(t,ol)|t∈to};
(8)alpha(pl,tl,fl);
定义局部完备性日志
设a,b为日志中任意两个活动,并且b可以直接跟在a后发生,称满足a>lb的行为在迹中至少出现一次的日志为局部完备性日志。
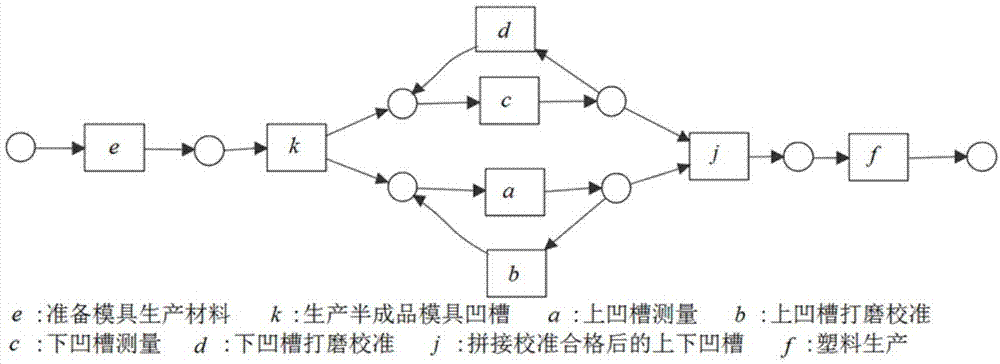
模具通常由多个零部件构成。塑料浇筑模具由上下两块特殊金属凹槽拼接成一个空腔,最后将液态塑料浇灌到空腔中,等待塑料冷却成型,再经过后续过程加工成塑料。塑料浇筑模具生产过程通常是先分别生产出半成品的上凹槽和下凹槽。由于模具需要很高的精度,绝大多数情况下半成品的上、下凹槽都不符合拼接标准,故要求对模具的上下两凹槽进行打磨校准。一方面使边缘处符合拼接要求,另一方面将腔体进行抛光。具体过程可抽象为以下几步:1)准备模具生产材料。2)生产半成品凹槽。3)对模具上凹槽进行测量。4)若上凹槽符合标准,则等待拼接;若不符合标准,则需要对上凹槽进行打磨校准,然后继续进行步骤3。5)对模具下凹槽进行测量。6)若下凹槽符合标准,则等待拼接;若不符合标准,则需要对下凹槽进行打磨校准,然后继续进行步骤5。7)模具上下凹槽都测量合格后,将两凹槽拼接成塑料浇筑模具。8)成品模具进入后续塑料生产流程。其中步骤3,步骤5是可以同时进行的,步骤4,步骤6也是可以同时进行的。上述模具加工的过程模型如图1所示:
如图1所示的模型,模型中两个三角形2度循环是并发的,a与b,c与d之间有明显的先后关系。必须先进行活动a,后进行活动b,并且活动b完成后,还要再进行一遍活动a,两次进行的活动a之间一定会进行活动b。活动c与d也遵循这样的关系。该模型可以产生两类日志,一类是含有“aba”,“cdc”等明显的三角形2度循环显式行为的完备日志[12]。如日志l1=<ekacjf,ekcajf,ekabacjf,ekacbajf,ekcdcaj,ekcdacjf,ekabacdcjf,ekcdcabajf,…>。另一类是不出现“aba”,“cdc”等三角形循环显式行为的局部完备日志。如日志l2=<ekacjf,ekcajf,ekabcajf,ekacbajf,ekcdacjf,ekcadcjf,ekacdbacjf,ekacbdacjf>。对于日志l2,现有技术中的算法均不能挖掘出正确的模型。以alpha+算法为例,alpha+算法对日志l2挖掘结果如图2所示。由于alpha+算法只挖掘出了a,b,c,d之间的并发关系,没有挖掘出三角形2度循环。所以,得到的模型存在两个独立变迁,显然不是正确的模型。
虽然日志中没有出现循环显式行为,但是日志依旧保持着该类循环的特征:(1)迹中活动a,b出现的顺序固定;(2)日志中活动a,b的数量关系不变。
在缺乏循环显式行为的局部完备性日志中,通过该结构的上述特征,挖掘含有多个并发的三角形2度循环的模型为研究重点。该问题核心在于如何正确匹配两个活动组成三角形2度循环。例如图2所示的模型,问题核心在于如何将活动b、d与活动a、c匹配成三角形2度循环。
以图1中的模型生成的一个日志为例,详细描述算法。
设活动ai,bi构成三角形2度循环,满足aiδ>lbi或bi<δiai,ai为主体活动,bi为回调活动。称所有主体活动构成的集合和所有回调活动的集合分别为主体活动集合和回调活动集合,其形式化定义如下:
定义主体活动集合和回调活动集合
设bol为主体活动集合,cl为回调活动集合,其中:
(1)
(2)
定义三角形2度循环并发块
设二元组(a1,b1),(a2,b2),……,(an,bn)中的活动均满足aiδ>lbi,当n个三角形2度循环并发时,存在唯一的变迁x和y,满足:
(1)x=●(●a1)∩●(●a2)∩……∩●(●an);
(2)y=(a1●)●∩(●a2●)●∩……∩(an●)●。
称x,y与n个并发的三角形2度循环组成的结构为三角形2度循环并发块,其中hδ=x为块首活动,tδ=y为块尾活动。
如图3所示,(c,d)和(a,b)两个二元组中的活动分别构成三角形2度循环,其中a和c为主体活动,b和d为回调活动。并且块首活动k、块尾活动j和两个并发的三角形2度循环构成三角形2度循环并发块。
迹中连续发生的两个活动构成直接跟随关系,利用直接跟随关系可以判断并发关系、因果关系等其他关系,直接跟随集合的定义如下:
定义直接跟随集合
直接跟随集合dl中的元素是迹中所有构成>l关系的活动组成的二元组,即
例如在σ3=<eacf>中,活动e>la,a>lc,c>lf,因此dl={(e,a),(a,c),(c,f)}。
构成循环结构的活动可能在日志中多次出现,活动的次数关系是判断循环的一个重要参考。下面给出活动出现次数的定义:
定义活动出现次数
设日志l,迹σ∈l,活动a∈σ。sum(a,σ)表示活动在迹中的出现次数,sum(a,l)表示活动在日志中出现的总次数。
例如迹σ1=<eacf>,sum(a,σ1)=1;l={<ecabaf>},sum(a,l)=2。
日志中活动的特征是模型结构的正确反映,将三角形2度循环结构的特征抽象为位置定理和数量定理,并给出证明。
定理1位置定理:若存在活动ai,bi∈σ,σ∈l,且aiδ>lbi,则first(ai,σ)<first(bi,σ)。
证明:活动ai,bi∈σ,σ∈l,满足aiδ>lbi,ai为主体活动,bi为回调活动。由定义可知该三角形2度循环一定产生的如σ=<aibiaibiaibi…biai>的序列,该序列第一个出现的活动是ai,随后才出现第一个bi。因此第一个bi在σ中的下标必然小于第一个ai在σ中的下标。证毕。
除了满足位置定理外,该循环结构活动数量同样有一定的规律。
定理2数量定理:若有活动ai和bi且aiδ>lbi,则含有ai,bi构成的三角形2度循环的模型产生的任意一条迹σ和任意日志l中:sum(bi,σ)-sum(ai,σ)=1和sum(ai,l)-sum(bi,l)=|l|。
证明:
1)若不进入三角形2度循环,则迹中ai的总数是1,bi的总数是0,此时定理成立。
2)若进入三角形2度循环,由上文知ai,bi构成的三角形2度循环一定产生如σ=<aibiaibiaibi….biai>的序列。第一个出现的活动是ai,随后出现成对的<biai>,所以σ中ai的总数一定比bi多1,此时定理也成立。
每条迹都满足上述数量关系,此时日志中ai的总数一定比bi的总数多1×|l|=|l|个。证毕。
算法1是主体活动和回调活动的分类算法。算法1主要根据三角形2度循环并发块的定义以及定理2中的数量关系把日志中的主体活动和回调活动进行分类,并分别放入bol和cl中。
算法1主体活动和回调活动的分类算法
输入:满足局部完备性的日志l;
输出:主体活动集合bol和回调活动集合cl;
步骤(1):创建来统计活动次数的一维数组ltm,创建直接跟随集合dl,主体活动集合bol,回调活动集合cl以及三角形2度循环并发块块首活动hδ并进行初始化。
步骤(2):遍历日志l,将起始活动放入开始活动集合ti,将结束活动放入结束活动集合to,将所有活动放入活动集合tl,并且将连续出现的活动组成二元组,将二元组放入直接跟随集合dl中。
步骤(3):遍历日志l,统计活动集合tl中活动出现的次数,将次数放入一维数组ltm对应的位置。
步骤(4):遍历一维数组ltm,如果数组中两元素之差大于0,并且两元素对应的活动在日志中处于并发关系,则遍历日志中的任意一条迹,将两活动中首先出现的活动之前的一个活动赋值为三角形2度循环并发块块首活动hδ。
步骤(5):遍历活动集合tl。将与块首活动hδ满足因果关系的活动放入主体活动集合bol,将与主体活动集合中活动满足并发关系和直接跟随关系的活动放入回调活动集合cl中。
步骤(6):返回主体活动集合bol和回调活动集合cl。
以日志l3:[<ekabcajf>,<ekacbajf>,<ekcdacjf>,<ekcadcjf>,<ekacdbacjf>,<ekacbdacjf>,<ekacjf>,<ekcajf>]为例。步骤(1)时ltm数组中的元素均为0;步骤(2)得到dl={e>lk,a>lc,c>lb,c>ld,b>lc,b>la,k>lc,b>ld,d>lc,d>lb,c>lj,a>ld,k>la,d>la,a>lj,c>la,a>lb,j>lf};步骤(3)获取ltm矩阵,矩阵统计结果如表1所示。步骤(4)获取块首活动hδ=k;步骤(5)中活动a,c出现次数均为12;活动b,d出现次数均为4,满足定理2。此时得到bol={c,a},cl={d,b}。步骤(6)返回bol和cl。
表1算法得到l3的ltm
步骤2:定义活动首次在迹中出现的位置,采用剪枝的思想将不正确的活动匹配删除,从而得到正确的活动匹配;
定义活动首次在迹中出现的位置
设迹σ∈l,活动a∈σ。first(a,σ)表示活动a在迹σ中第一次出现时的位置下标。
例如迹σ1=<eacf>,first(a,σ1)=2;迹σ2=<ecabaf>,first(a,σ2)=3。
定义首次标记位置矩阵
设日志l,集合bol∪cl,则首次标记位置矩阵为fm[|l|][|bol∪cl|],满足
利用首次标记位置矩阵可以获得匹配结果,所有匹配结果构成的集合被称作匹配结果集合,匹配结果和匹配结果集合的定义如下:
定义匹配结果和匹配结果集合
匹配结果是一个二元组mtl=(a,b),其中a为主体活动,b为回调活动。二元组中的活动不能同时为主体活动或者回调活动,即
匹配结果集合mtl是由匹配结果mtl组成的集合,即mtl={(a,b)|(a∈bol∧b∈cl)∨(b∈bol∧a∈cl)}。
算法2是主体活动和回调活动匹配算法。算法2先将匹配结果放入匹配结果集合,再使用活动被首次标记时的位置根据定理1进行活动匹配。匹配过程采用了剪枝的思想,若匹配结果mtl中的两个活动不满足定理1,则删除该匹配结果。
算法2主体活动和回调活动匹配算法
输入:满足局部完备性的日志l,主体活动集合bol,回调活动集合cl;
输出:匹配结果集合mtl;
步骤(1):创建首次标记位置矩阵fm[|l|][|bol∪cl|],匹配结果集合mtl和匹配结果mtl1并进行初始化。
步骤(2):将主体活动集合bol和回调活动集合cl中的活动做笛卡尔积,将组成的二元组赋值给mtl1,并将所有的mtl1放入匹配结果集合mtl中。
步骤(3):遍历日志l,将l中属于集合bol∪cl的活动首次在迹中出现的位置记录下来并存储在二维数组fm[|l|][|bol∪cl|]中对应的位置。
步骤(4):遍历二维数组fm[|l|][|bol∪cl|],若回调活动集合cl中的活动位置小于主体活动集合bol中的位置,则将匹配结果集合mtl中这个活动的笛卡尔积删除。
步骤(5):返回匹配结果集合mtl。
以l3为例,步骤(1)时fm矩阵中的元素均为0。步骤(2)将cl与bol的笛卡尔积放入mtl。此时得到的mtl={(a,b),(a,d),(b,a),(d,a),(c,b),(c,d),(b,c),(d,c)}。步骤(3)获取cl∪bol中活动在每条迹中首次出现的位置。得到的fm[|l|][|bol∪cl|]如表2所示。步骤(4)检索cl中的活动的位置下标小于bol中哪些活动的位置下标,以σ1为例,first(b,σ1)=2<first(c,σ1)=3。根据定理1,证明主体活动c和回调活动b不能匹配,则对应删除mtl中(b,c)和(c,b)两个二元组。在σ3中first(d,σ3)=2<first(a,σ3)=3。同理,删除mtl中的(a,d)和(d,a)两个二元组。当遍历完fm后,mtl中剩下(a,b)、(b,a)、(c,d)、(d,c)四个二元组,匹配结果集合中二元组中活动即能构成三角形2度循环。
表2l3的首次标记位置矩阵fm
步骤3:得出alphamatch算法,完成多并发三角形2度循环的过程模型挖掘;
定义alphamatch算法
设l为一个基于活动的日志,那么alphamatch(l)定义如下:
(1)
(2)
(3)
(4)
(5)
(6)
(7)
(8)
(9)pl={p(a,b)|(a,b)∈yl}∪{il,ol};
(10)fl={(a,p(a,b))|(a,b)∈yl∧a∈a}∪{(p(a,b),b)|(a,b)∈yl∧b∈b}∪{(il,t)|t∈ti}∪{(t,ol)|t∈to};
(11)alphamatch(pl,tl,fl)。
与经典的alpha算法相比,alphamatch算法先将主体活动和回调活动进行分类;再对主体活动与回调活动匹配;最后返回正确匹配的结果集mtl,并获得结果集中活动间的关系。以l3为例,经过alphamatch算法挖掘并分析得到活动间的关系如表3所示。
由表3可知,活动a与b,c与d均被匹配在一起,最后得出l3对应的的模型如图4所示,该模型与案例中的原模型一致。
表3l3的足迹
实施例1
三角形2度循环的并发结构广泛出现在模具生产、零件加工、柔性制造、精密仪器生产、医疗器械生产、传感器生产等诸多领域。
本发明以滚珠轴承的生产过程模型为例,通过以下步骤获取不含有“aba”等循环显式行为的局部完备日志:
1)输入如图5所示含有三个并发的三角形2度循环的滚珠轴承生产的过程模型;
2)运行prom中的performasimplesimulationofa(stochastic)petrinet插件得到原模型的日志;
3)人工筛选符合要求的局部完备日志。进行试验的日志属性如表4所示:
实验比较了alphamatch算法、alpha+算法、ilp算法和inductiveminer-infrequent(imf)算法挖掘的结果。
表4日志属性
导入日志l4,该日志是由图5所示的原模型得到。对比alpha+算法,ilp算法,inductiveminer-infrequent(imf)算法以及alphamatch算法的挖掘结果。alpha+算法结果如图6所示。由于日志不是完全完备的,所以alpha+算法只挖掘出活动a,b,c,d,g,h之间的并发关系和活动的因果关系。此时alpha+算法并没有挖掘出三个回调活动与其他活动之间的关系,所以图6的模型中存在三个独立变迁,与原模型有很大差别。因此,该模型是不合理的。
图7为ilp算法挖掘的模型,与alpha+算法相比,ilp算法得到的模型中主体活动和回调活动匹配是正确的,但是该模型出现了很多日志和原模型中不存在的次序关系。例如e→lb、e→ld。因此ilp算法得到的模型是不合理的。
图8为inductiveminer-infrequent(imf)算法挖掘的模型,该算法没有进行活动的匹配,而是将回调活动和主体活动分成两个部分,并且加入了大量不可见变迁,这导致模型结构相对比较复杂。除此之外,若先发生主体活动a,另外两个主体活动还没发生的情况下,三个回调活动中的任意一个都可以紧跟活动a发生。这种情况下产生的序列可能是原模型无法产生的,例如序列“aha”。因此,图8中的模型是不合理的。
图9为本发明方法挖掘的模型,与alpha+算法挖掘的模型相比,图9所示的模型正确的把活动匹配在一起,并且没有独立变迁的存在;与ilp算法挖掘的模型相比,图9所示的模型没有活动间的错误关系。与inductiveminer-infrequent(imf)算法挖掘的模型相比,图9的模型不会产生原模型无法得到的序列,并且该模型与原模型一致。
综上所述,从算法挖掘模型上看,本文挖掘的模型与原模型一致,与其他算法相比,有着较大优势。
从拟合度的角度分析四种结果模型。导入由原模型生成的不同规模,不同完备性的日志l4,l5,l6,l7。四个日志中l7含有迹的数量最多,完备性最强。通过prom平台的replayalogonpetrinetforconformanceanalysis插件,输入模型和日志,得出四种算法所挖掘模型的拟合度,统计结果如图10所示。其中alphamatch算法和inductiveminer-infrequent(imf)算法得到的拟合度一直都是1,拟合度要高于其他两种算法。但是由于inductiveminer-infrequent(imf)算法将主体活动和回调活动分成两块挖掘,导致模型还可能产生类似于“ada”“aha”等原模型不能产生的序列。因此,该模型是一种不合理的模型。ilp算法在挖掘日志l4,l5,l6时,得到模型的拟合度较低,但是在挖掘日志l7时拟合度也达到1,这是由于日志完备性增强,此时ilp也得出了正确的模型。相比而言,在弱完备性下本文算法也一直保持较高的拟合度。因此,在日志的完备性需求方面,本文算法比ilp算法有优势。由于上文中四个的日志都不是alpha+算法所要求的完全完备日志,alpha+算法无法得到回调活动间的关系。因此alpha+算法得到模型的拟合度相对较低。
综上所述,本文算法在所得到模型的拟合度上有一定优势。
分析四种算法得到模型的精确度。利用prom中的checkprecisionbasedonalign-etconformance插件得到四种算法的精确度,统计结果如图11所示。由于alpha+算法挖掘的模型中出现三个独立变迁,所以得到模型的精确度最低。由于inductiveminer-infrequent(imf)算法挖掘的模型能产生大量原模型无法产生的活动序列,所以该算法得到模型的精确度也不高。由于日志l4,l5,l6完备性较弱,ilp算法挖掘出的模型与原模型有一定差别,所以精确度略低于本文算法的精确度。但ilp算法挖掘l7时,由于日志完备性较强,也得到了与原模型一致的正确模型,此时ilp算法得到模型的精确度等于本文算法得到模型的精确度。相比之下,本文算法对日志的完备性要求更低,精确度更高。
综上所述,本文算法得到的模型在精确度方面也有着较大优势。
当然,上述说明并非是对本发明的限制,本发明也并不仅限于上述举例,本技术领域的技术人员在本发明的实质范围内所做出的变化、改型、添加或替换,也应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!