一种子宫颈癌细胞再识别诊断方法与流程
本发明属于图像识别、生物医学领域,特别涉及一种子宫颈癌细胞再识别诊断方法。
背景技术
目前全世界癌症发病率正逐年上升,其中,子宫颈癌是严重危害女性健康的恶性疾病。子宫颈癌的早期诊断是其治愈关键。一般来说,子宫颈癌的诊断方法包括子宫颈脱落细胞学检查、人乳头瘤病毒病原学诊断、子宫颈组织病理学检查等,其中,子宫颈涂片筛查是至关重要的措施,即通过对子宫颈细胞进行取样得到细胞涂片或组织涂片,在显微镜下进行观察,发现形态异常的细胞或细胞群,根据其变异数量、变异程度等分析得出诊断结果。目前,显微镜下的病理分析通常由经验丰富的医生完成。在临床诊断中,由于经验丰富的医师人数有限,且人工诊断受人的主观性、劳累、经验等因素影响,对得到可靠的病理诊断有一定的制约性。
随着图像处理和模式识别技术的迅速发展,计算机辅助识别可以大大提高诊断效率。但目前为止,计算机辅助子宫颈细胞图像自动筛查的诊断方法还少有涉及。如能普及子宫颈涂片的识别诊断自动化,在实现准确筛查的同时,降低医师工作量,消除人工检测弊端引起的误诊和漏诊,可以在一定程度上降低假阴性率。
技术实现要素:
本发明的目的,在于提供一种子宫颈癌细胞再识别诊断方法,其有效地将病理诊断与计算机技术进行结合,实现较高的总体识别率和较低的虚警率。
为了达成上述目的,本发明的解决方案是:
一种子宫颈癌细胞再识别诊断方法,包括如下步骤:
步骤1,对采集到的子宫颈细胞图像进行预处理,提取细胞形态和色度特征,并表示为向量;
步骤2,获取训练样本,训练识别机制m1和m2,构成平衡邻域分类器m,其中,m1用于判别是否为癌变细胞,m2用于确定癌变种类;
步骤3,对待识别的子宫颈细胞图像进行预处理,提取细胞形态和色度特征,并表示为向量;
步骤4,将其向量参数输入平衡邻域分类器m中进行判别,首先利用m1判别是否为癌变细胞,对癌变细胞再利用m2确定癌变种类。
采用上述方案后,本发明首先对采集到的子宫颈涂片进行处理,提取出细胞形态、色度、纹理等特征,利用数字图像处理技术对其进行参数化分析,将其表示为特征向量。然后通过一种特定的子宫颈细胞图像识别方法,对可能癌变细胞进行分类和再识别,从而得出可靠的诊断结果。本发明在进行特定的子宫颈细胞图像识别时,首先提出了一种平衡邻域分类器,解决数据集分类的类不平衡问题,对细胞数据集进行分类,找出可能癌变的细胞数据集;然后对可能癌变的细胞图像进行再识别,得到最终诊断结果。应用效果表明,该方法有效地将病理诊断与计算机技术进行结合,实现较高的总体识别率和较低的虚警率。
附图说明
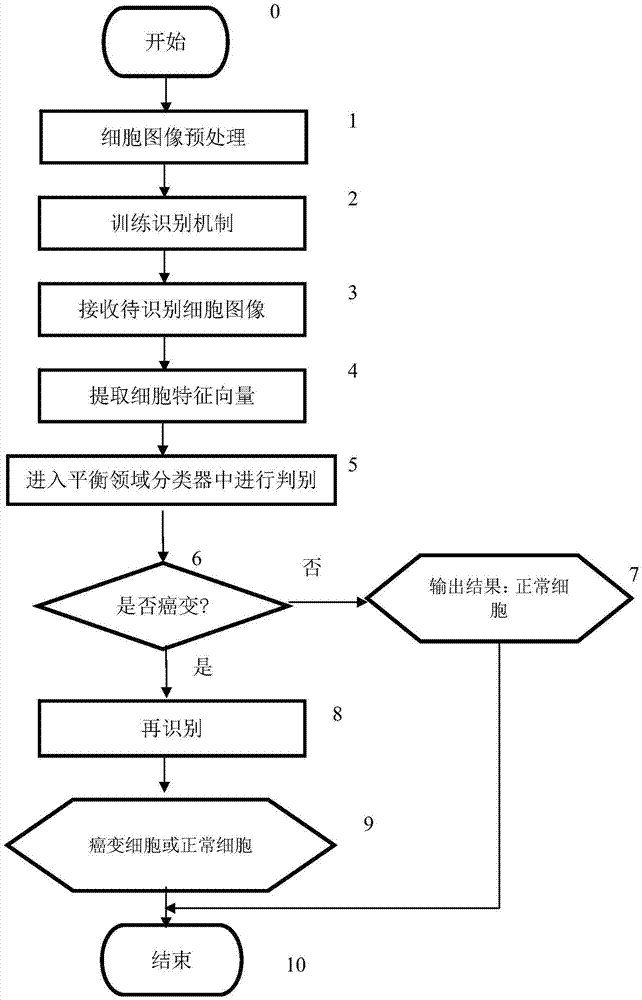
图1是本发明的流程图;
图2是细胞图像处理流程图;
图3是训练识别机制流程图;
图4是平衡邻域分类器利用识别机制m1处理过程流程图;
图5是利用识别机制m2进行细胞图像再识别流程图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
本发明提供的方法流程如图1所示,步骤0是初始动作;步骤1对图像进行预处理,用于训练过程,该步骤将在后面部分结合图2进行具体介绍;步骤2获取训练样本,并训练识别机制;步骤5进入平衡邻域分类器中,利用识别机制m1对细胞图像进行分类,筛选出癌变的细胞图像;步骤8利用识别机制m2进行再识别过程,确定癌变种类。步骤5与步骤8将在后面的部分结合图4和图5进行具体介绍。
子宫颈涂片样本处理过程如图2所示。首先,通过细胞取样得到子宫颈细胞涂片,利用计算机图像采集软件,实时获取患者子宫颈癌细胞涂片上的视频信号,进行图像采集和处理后转化为红(r)、绿(g)、蓝(b)真彩色图像;然后将原始rgb彩色图像从三维色彩空间投影到一维线性空间,对其灰度图像进行分割、去噪、平滑、锐化和形态滤波等一系列处理,得到效果较好的二值图像;最后运用形态学和色度学对细胞图像的目标区域进行形态特征和色度特征的提取。通过特征提取模块将提取到的图像特征表示为向量,作为训练样本,进入平衡邻域分类器中进行训练。
图3详细说明了训练识别机制的过程,具体步骤如下:
(1)设正常细胞向量集为l1,可能癌变细胞向量集为l2,初始设
(2)获取带标记的细胞图像,进行特征提取并将其表示为向量;
(3)检查当前细胞图像已知的结果,当图像为正常细胞图像,将当前细胞图像所对应的特征向量加入l1;当图像为可能癌变细胞图像,将当前细胞图像所对应的特征向量加入l2,l2=l21∪l22∪…∪l2c,c为子宫颈癌症细胞种类数;
(4)判断是否还有其他图像,如果是则执行步骤(2);否则执行步骤(5);
(5)将l1中的向量标记为0,l2中的向量标记为1;
(6)使用l1、l2训练识别机制m1;
(7)将l2i中的向量标记为第i类,训练识别机制m2;
(8)结束。
图4详细说明了在平衡邻域分类器中采用识别机制m1进行判别的过程。在获得的细胞图像数据集中,一般来说,人体内正常细胞的占比多,癌症细胞的占比少,这便造成了数据集分类的类不平衡问题。为解决该类问题,提出一种平衡邻域分类器的识别机制m1、m2,对其进行识别诊断,具体步骤如下:
(1)对细胞图像中提取到细胞特征的部分样本集进行标记,记为标记样本集l;未标记的样本集记为未标记样本集u;
(2)使用选定的距离度量函数,计算待测样本x∈u到所有训练样本xj∈l的距离。一般使用三个度量函数d1,d2,d∞:
其中,ai表示第i个特征,m表示总特征数,f(x,a)表示x样本中特征a的值;
(3)计算类ci的最大距离
(4)计算平衡邻域分类器中类ci的阈值δi;
其中,ω为邻域半径与最大半径自设比例。
(5)收集类ci中待测样本x邻域的样本集xi:
xi={xj|xj∈li,d(x,xj)≤δi}
其中,
(6)计算待测样本x到每类样本集xi中心的局部距离;式中,|xi|是xi中的样本数:
(7)将待测样本x归于局部距离最小值对应的类:
c(x)=argmindi
(8)当此类为l1,则给出待测样本x的诊断结果为正常细胞,结束识别;
(9)当此类为l2,则给出待测样本x的诊断结果为癌变细胞,进入再识别阶段。
图5详细说明了采用识别机制m2再识别过程。再识别过程具体步骤如下:
(1)输入获得的癌变细胞的样本集l2;
(2)对l2进行n次重复抽样获得d1,d2,…,dn训练集;
(3)在di上训练决策树得到基分类器mi,其中,i=1,2,…,n;
(4)检测分类器mi的错误率ei;
(5)搜索错误率小于自定阈值的分类器m*,添加到集合m2中,直到搜索完所有基分类器:
(6)对分类器m采用投票原则f集成:
(7)输入待测样本,使用分类器m2对其识别诊断,得到癌变种类。
从以上具体实施方式可看出,本发明提供的一种子宫颈癌细胞再识别诊断方法,首先对采集到的子宫颈涂片进行处理,利用数字图像处理技术对其特征进行参数化分析并表示为特征向量。然后通过一种特定的子宫颈细胞图像自动筛查方法,对病变细胞进行分类和再识别。应用效果表明,本方法实现了较高的总体识别率和较低的虚警率。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!