一种基于自适应预测模式的LSTM网络行人重识别方法与流程
本发明属于图像识别技术领域,涉及一种基于自适应预测模式的lstm网络行人重识别方法。
背景技术:
随着摄像头安装数量、智慧城市和公共安全需求的日益增长,传统的摄像头监控系统仅能做到对单个摄像头中的运动目标进行自动化检测和跟踪。因此研究和实现一个基于多摄像头的运动目标跨区域跟踪系统就变的非常迫切。行人重识别技术作为“跨摄像头追踪系统”中的关键技术之一,主要是指在非重叠视角域多摄像头网络下进行的行人图像匹配,即确定不同位置的摄像头在不同时刻拍摄到的行人是否为同一人。
行人重识别技术目前存在的难点有:①由于视频光照、角度、尺度等变化导致行人的外貌特征发生变化;②由于摄像机视角和行人姿态的变化导致行人外貌特征存在遮挡;③不同摄像头或不同行人的外貌特征可能比同一个人的外貌特征更相似。
[1]yichaoyan,bingbingni,zhichaosong,chaoma,yanyan,andxiaokangyang.personre-identificationviarecurrentfeatureaggregation[m].workshoponstatisticallearningincomputervision(eccv),2016:701-716.
[2]liaos,huy,zhux,etal.personre-identificationbylocalmaximaloccurrencerepresentationandmetriclearning[c].computervisionandpatternrecognition(cvpr).ieee,2015:2197-2206.
技术实现要素:
本发明的目的是提供一种基于自适应预测模式的lstm网络行人重识别方法,解决了现有的lstm网络由于遮挡因素导致的行人重识别性能偏低的问题。
本发明所采用的技术方案是,一种基于自适应预测模式的lstm网络行人重识别方法,具体包括如下步骤:
步骤1,获取行人重识别数据集,该行人重识别数据集包括两个摄像头所拍摄的n个不同行人的2×n个视频序列,从2×n个视频序列中随机抽取j个不同行人的2×j个视频序列作为训练样本集vtrain,其中
步骤2,对步骤1所得的训练样本集vtrain中的所有视频帧图像
步骤3,制作标签文件,设置lstm网络参数,把标签文件、训练特征集flbpc中特征的正向排列作为前向lstm网络flstm的输入,得到flstm网络模型mflstm;把标签文件、训练特征集flbpc中特征的反向排列作为后向lstm网络blstm的输入,得到blstm网络模型mblstm;
步骤4,制作自适应预测模式选择网络apm-net的训练样本集apm_vtrain,通过mflstm对apm_vtrain提取flstm特征,得到flstm特征集atr_fflstm;通过mblst对apm_vtrain提取blstm特征,得到特征集atr_fblstm;
步骤5,设计自适应预测模式选择网络apm-net,通过apm-net网络对训练样本集apm_vtrain中的三类样本进行预测,三类样本分别为前向样本、后向样本及双向样本;
步骤6,制作标签文件,把标签文件、前向lstm特征集atr_fflstm和后向lstm特征集atr_fblstm作为apm-net网络的输入,训练自适应预测模式选择网络apm-net,得到网络模型mapm。
步骤7,把步骤1数据集中除去训练样本集vtrain之外的的剩余数据作为测试样本集vtest,其中
步骤8,对vtest提取apm特征,得到apm特征集afv;
步骤9,对测试数据集vtest提取的apm特征集afv进行均值化预处理,得到特征均值集av_afv;
步骤10,将摄像机1中的行人特征均值作为目标行人特征集obj,摄像机2中的行人特征均值作为待识别行人特征集gal,其中obj={objtrain,objtest},gal={galtrain,galtest},
本发明的特点还在于,
步骤2中
步骤2.1,对输入的行人图像
步骤2.2,将图像imgw×h划分为m=m1×m2个图像块blkm,其中1≤m≤m;
步骤2.3,对每个图像块blkm提取lbp和颜色融合特征fblkm;
步骤2.4,将图像imgw×h中m个图像块所提取的lbp和颜色融合特征fblkm进行串联融合,就可得到图像imgw×h对应的lbp和颜色融合特征
步骤2.3的具体如下:
步骤2.3.1,将图像块blkm转换为灰度图像块gblkm,对gblkm提取lbp特征lblkm;
步骤2.3.2,将图像块blkm转换到hsv颜色空间,得到转换之后的图像hblkm,计算图像hblkm在h、s、v各个通道上的均值,组成三维hsv颜色特征chblkm;将图像块blkm转换到lab颜色空间,得到转换之后的图像labblkm,计算图像labblkm在l、a、b各个通道上的均值,组成三维lab颜色特征clblkm;
步骤2.3.3,将步骤2.3.1中图像块blkm所提取的lbp特征lblkm、步骤c2中图像块blkm所提取得hsv颜色特征chblkm以及lab颜色特征labblkm进行串联融合,从而得到图像块blkm所对应的lbp和颜色融合特征fbikm。
步骤3的具体过程如下:
步骤3.1,准备样本标签文件,将训练特征集flbpc中c摄像机下id号为j的行人所对应的视频特征集
步骤3.2,设置网络训练参数,并写入配置文件solver.prototxt;
步骤3.3,训练flstm网络模型mflstm,该网络flstm特征输出的维数为512维,该网络的输入数据为从lstm_train.txt训练文件中随机抽取的样本
步骤3.4,训练blstm网络模型mblstm,该网络blstm特征输出的维数为512维,该网络的输入数据为从lstm_train.txt训练文件中随机抽取的样本
步骤4的具体过程如下:
步骤4.1,制apm-net的训练样本集apm_vtrain,其中apm_vtrain={apm_vtrainp|1≤p≤a_tn},apm_vtrainp表示第p个训练样本,它是从
步骤4.2,提取训练样本集apm_vtrain对应的lbp和颜色融合特征集apm_flbpc={apm_flbpcp|1≤p≤a_tn};
步骤4.3,把apm_flbpc中每一个样本apm_vtrainp对应的特征集apm_flbpcp中的第(i-n+1)~i帧特征
步骤5中的网络apm-net结构包括输入层、reshape层、第一个全连接+drop层、第二全连接层和softmax层;
输入层:输入层的输入为样本apm_vtrainp对应的前向lstm特征atr_fflstmp和后向lstm特征atr_fblstmp。
reshape层:reshape层的输入为atr_fflstmp和atr_fblstmp,输出为特征维数为10240(10240=1024*n)的数据feaf_b,该层的作用为对输入的前向lstm特征和后向lstm特征进行串联操作;
第一全连接加drop层:第一个全连接+drop层:全连接层的输入为feaf_b,作用是将10240维数据feaf_b降成800维数据inner1;drop层的输入是inner1,操作是对inner1数据按一定的概率随机置0,作用是在一定程度上防止过拟合现象,输出数据为800维数据drop1;
第二全连接层:输入是drop1,输出为3维数据inner2=(x0,x1,x2)′,分别对应三种预测模式;
softmax层:对网络进行训练时需要通过softmax层的loss值对网络进行反馈修订,具体操作为:计算inner2中的最大值xmax=max(x0,x1,x2);根据xmax值对inner2中的数据进行归一化处理得到ykk,
其中kk=0,1,2;根据样本标签alable对应的yalable计算loss值,loss=-log(yalable)。
步骤6的具体过程为:
步骤6.1,制作样本标签文件,以步骤4.1设定的样本alable值来对训练样本集apm_vtrain中的数据进行标记,并将标记结果存入训练标签文件apm_train.txt中;以第p个样本对应的连续2n-1帧视频apm_vtrainp为例,标签格式为apm_vtrainpath/apm_vtrainp.avialable,apm_vtrainpath/apm_vtrainp.avi为apm_vtrain中各样本对应的视频路径apm_vtrainpath/下的视频文件名apm_vtrainp.avi;
步骤6.2,训练自适应预测模式选择网络apm-net,以自适应预测模式选择网络apm-net的训练样本集apm_vtrain所对应的前向lstm特征集atr_fflstm和后向lstm特征集atr_fblstm作为训练apm-net网络的输入,进行apm-net网络训练,得到自适应预测模式选择网络模型mapm。
步骤8中apm特征的提取过程如下:
步骤8.1,对测试样本集vtest中的所有视频帧图像
步骤8.2,对行人测试样本集vtest提取apm特征集
步骤8.2的特征集提取过程如下:
步骤8.2.1,对摄像机c下id号为j的行人视频
步骤8.2.2,获取单帧图像
步骤10的具体过程如下:
步骤10.1,把objtrain和galtrain作为交叉视角二次判别分析(cross-viewquadraticdiscriminantanalysis,xqda)的训练特征集,训练得到映射矩阵w和度量核矩阵m;
步骤10.2,距离计算;
把步骤10.1中训练得到的度量核矩阵m,测试特征集galtest和w的乘积galtest×w,objtest和w的乘积objtest×w作为输入送入距离度量函数mahdistm(m,galtest×w,objtest×w)中,输出得到一个r/2×r/2的二维距离矩阵
步骤10.3,对矩阵d按行进行升序排列得到矩阵d′,d′中第i行中的第一列元素d′i0在d中的对应元素记为dij,dij的下标i和j为识别到的两个摄像机下的同一个行人。
本发明的有益效果是,本发明提出的一种基于自适应预测模式的lstm网络行人重识别方法,根据所提出的apm-net网络对半进入遮挡物和走出遮挡物时的lstm特征进行选择,从而提高了行人在遮挡情况下的识别性能。
附图说明
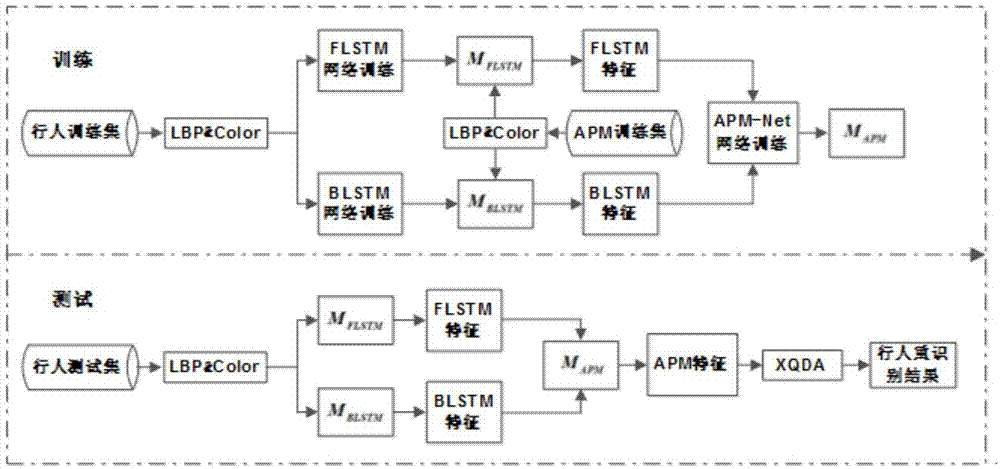
图1是本发明的一种基于自适应预测模式的lstm网络行人重识别方法的流程示意图;
图2是本发明一种基于自适应预测模式的lstm网络行人重识别方法中
图3是本发明一种基于自适应预测模式的lstm网络行人重识别方法中前向flstm网络结构图;
图4是本发明一种基于自适应预测模式的lstm网络行人重识别方法中后向flstm网络结构图;
图5是本发明一种基于自适应预测模式的lstm网络行人重识别方法中自适应预测模式网络的结构图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明一种基于自适应预测模式的lstm网络行人重识别方法,如图1所示,主要由行人重识别网络训练、行人特征提取和距离度量三个部分组成。
首先进行行人重识别网络训练过程,具体按照以下步骤实施:
训练部分主要包括flstm、blstm和apm-net三个网络的训练,其具体实施步骤如下:
步骤1,通过网络下载,获取行人重识别数据集(如ilids-vid、prid数据集等)。该行人重识别数据集包括两个摄像头所拍摄的n个不同行人的2×n个视频序列。从中随机抽取j个不同行人的2×j个视频序列作为训练样本集vtrain,其中
步骤2,对训练样本集vtrain中的所有视频帧图像
步骤2.1,对输入的行人图像
步骤2.2,将图像imgw×h划分为m=m1×m2个图像块blkm,其中1≤m≤m,图像块的大小为16×8,相邻图像块在水平方向上相差4个像素在垂直方向相差8个像素。本实施方案中的m1=(w-8)/4+1=15,m2=(h-16)/8+1=15,m=225。
步骤2.3,对每个图像块blkm提取lbp和颜色的融合特征fblkm,具体过程如下:
步骤2.3.1,将图像块blkm转换为灰度图像块gblkm,对gblkm提取lbp特征lblkm,特征lblkm的维数为256维;
步骤2.3.2,将图像块blkm转换到hsv颜色空间,得到转换之后的图像hblkm,计算图像hblkm在h、s、v各个通道上的均值,组成三维的hsv颜色特征chblkm;将图像块blkm转换到lab颜色空间,得到转换之后的图像labblkm,计算图像labblkm在l、a、b各个通道上的均值,组成三维的lab颜色特征clblkm;
步骤2.3.3,将步骤2.3.1中图像块blkm所提取的lbp特征lblkm和步骤2.3.2中图像块blkm所提取得hsv颜色特征chblkm以及lab颜色特征labblkm进行串联融合,就可得到图像块blkm所对应的262(256+3+3)维的lbp和颜色融合特征fblkm;
步骤2.4,将图像imgw×h中m个图像块所提取的lbp和颜色融合特征fblkm进行串联融合,得到图像imgw×h对应的lbp和颜色融合特征
步骤3,制作标签文件,设置lstm网络参数,然后把标签文件、训练特征集flbpc中特征的正向排列作为前向lstm网络flstm的输入,得到flstm网络模型mflstm;把标签文件、训练特征集flbpc中特征的反向排列作为后向lstm网络blstm的输入,得到blstm网络模型mblstm;步骤3的具体过程如下:
步骤3.1,准备样本标签文件,将训练特征集flbpc中c摄像机下id号为j的行人所对应的视频特征集
步骤3.2,设置网络训练参数,并写入配置文件solver.prototxt,其中对网络训练影响较大的训练参数的具体设置如表1所示:
表1
步骤3.3,训练flstm网络模型mflstm,其中flstm的网络结构如图3所示,该网络结构采用的是文献[1]中的lstm网络结构,该网络flstm特征输出的维数为512维,该网络的输入数据为从lstm_train.txt训练文件中随机抽取的样本
步骤3.4,训练blstm网络模型mblstm,其中blstm的网络结构如图4所示,该网络结构采用的是文献[1]中的lstm网络结构,该网络blstm特征输出的维数为512维,该网络的输入数据为从lstm_train.txt训练文件中随机抽取的样本
步骤4,制作自适应预测模式选择网络apm-net的训练样本集apm_vtrain,通过mflstm对apm_vtrain提取flstm特征,得到flstm特征集atr_fflstm;通过mblstm对apm_vtrain提取blstm特征,得到特征集atr_fblstm,其中apm_vtrain中的样本数目为a_tn,本实施方案中a_tn=542,步骤4的具体过程如下:
步骤4.1,制作apm-net的训练样本集apm_vtrain,其中apm_vtrain={apm_vtrainp|1≤p≤a_tn},apm_vtrainp表示第p个训练样本,它是从
在准备apm-net的训练样本集apm_vtrain时,训练样本集apm_vtrain中的样本类别数设为三,这三种样本类别分别为双向、前向和后向预测模式。当样本
步骤4.2,提取训练样本集apm_vtrain对应的lbp和颜色融合特征集apm_flbpc={apm_flbpcp|1≤p≤a_tn}。由步骤2对
步骤4.3,把apm_flbpc中每一个样本apm_vtrainp对应的特征集apm_flbpcp中的第(i-n+1)~i帧特征
步骤4.3.1,提取样本apm_vtrainp的前向lstm特征atr_fflstmp。将训练好的前向lstm网络模型mflstm看作函数get_fflstm(·),以样本apm_vtrainp所对应的特征集apm_flbpcp中的第(i-n+1)~i帧特征
步骤4.3.2,提取样本apm_vtrainp的后向lstm特征atr_fblstmp。将训练好的后向lstm网络模型mblstm看作函数get_fblstm(·),以样本apm_vtrainp所对应的特征集apm_flbpcp中的第(i+n-1)~i帧特征
步骤5,设计自适应预测模式选择网络apm-net,apm-net网络的功能为对样本的三种模式进行预测,其网络结构图如图5所示,由输入层、reshape层、第一个全连接+drop层、第二全连接层和一个softmax层组成;
(1)输入层:输入层的输入为样本apm_vtrainp对应的前向lstm特征atr_fflstmp和后向lstm特征atr_fblstmp。本实施方案中atr_fflstmp和atr_fblstmp的特征维数均为n×512,n=10;
(2)reshape层:reshape层的输入为atr_fflstmp和atr_fblstmp,输出为特征维数为10240(10240=1024*n)的数据feaf_b,该层的作用为对输入的前向lstm特征和后向lstm特征进行串联操作;
(3)第一个全连接+drop层:全连接层的输入为feaf_b,作用是将10240维数据feaf_b降成800维数据inner1;drop层的输入是inner1,操作是对inner1数据按一定的概率随机置0,作用是在一定程度上防止过拟合现象,输出数据为800维数据drop1;本实施案例中概率值为0.3;
(4)第二个全连接层:输入是drop1,输出为3维数据inner2=(x0,x1,x2)′,分别对应三种预测模式;
(5)softmax层:对网络进行训练时需要通过softmax层的loss值对网络进行反馈修订,具体操作为:计算inner2中的最大值xmax=max(x0,x1,x2);根据xmax值对inner2中的数据进行归一化处理得到ykk,
其中kk=0,1,2;根据样本标签alable对应的yalable计算loss值,loss=-log(yalable);根据loss值采用文献[1]中的网络反馈机制在网络训练过程中对网络参数进行修订。
步骤6,制作标签文件,把标签文件、前向lstm特征集atr_fflstm和后向lstm特征集atr_fblstm作为apm-net网络的输入,训练自适应预测模式选择网络apm-net,得到网络模型mapm。具体步骤如下:
步骤6.1,制作样本标签文件,以步骤4.1设定的样本alable值来对训练样本集apm_vtrain中的数据进行标记,并将标记结果存入训练标签文件apm_train.txt中。以第p个样本对应的连续2n-1帧视频apm_vtrainp为例,标签格式为(apm_vtrainpath/apm_vtrainp.avialable),apm_vtrainpath/apm_vtrainp.avi为apm_vtrain中各样本对应的视频路径apm_vtrainpath/下的视频文件名apm_vtrainp.avi。
步骤6.2,训练自适应预测模式选择网络apm-net,得到apm-net的网络模型mapm。
把训练样本集apm_vtrain对应的特征集atr_fflstm、atr_fblstm和标签文件中对应的样本标签作为网络的输入,进行apm-net网络训练,得到自适应预测模式选择网络模型mapm。
此时网络的训练已经完成,接下来的步骤为行人重识别,其具体实施步骤如下:
步骤7,把步骤1数据集中除去行人重识别训练样本集vtrain之外的剩余数据作为测试样本集vtest,其中
步骤8,对vtest提取apm特征,得到apm特征集
步骤8.1,对测试样本集vtest中的所有视频帧图像
步骤8.1.1,对输入的行人图像
步骤8.1.2,将图像imgw×h划分为m=m1×m2个图像块blkm,其中1≤m≤m,图像块的大小为16×8,相邻图像块在水平方向上相差4个像素在垂直方向上相差8个像素。本实施方案中的m1=(w-8)/4+1=15,m2=(h-16)/8+1=15,m=225;
步骤8.1.3,对每个图像块blkm提取lbp和颜色融合特征fblkm,其具体步骤和步骤2.3中的具体步骤相同;
步骤8.1.4,将图像imgw×h中m个图像块所提取的lbp和颜色融合特征fblkm进行串联融合,就可得到图像imgw×h所对应的lbp和颜色融合特征
步骤8.2,对行人测试样本集vtest提取apm特征集
步骤8.2.1,对摄像机c下id号为j的行人视频
步骤8.2.2,获取单帧图像
步骤8.2.2.1,将视频
步骤8.2.2.2,将特征集
步骤9,对测试数据集vtest提取的apm特征集afv进行均值化预处理,得到特征均值集av_afv,其中
步骤10,将摄像机1中的行人特征均值作为目标行人特征集obj,摄像机2中的行人特征均值作为待识别行人特征集gal,其中obj={objtrain,objtest},gal={galtrain,galtest},
步骤10.1,把objtrain和galtrain作为交叉视角二次判别分析(cross-viewquadraticdiscriminantanalysis,xqda)的训练特征集,训练得到映射矩阵w和度量核矩阵m。具体方法参考文献[2]。
步骤10.2,距离计算。把步骤10.1中训练得到的度量核矩阵m,galtest和w的乘积galtest×w,测试特征集objtest和w的乘积objtest×w作为参考文献[2]中距离度量函数mahdist(m,galtest×w,objtest×w)的输入,输出得到一个r/2×r/2的二维距离矩阵
步骤10.3,对矩阵d按行进行升序排列得到矩阵d′,d′中第i行中的第一列元素d′i0在d中的对应元素记为dij,dij的下标i和j为识别到的两个摄像机下的同一个行人。
行人重识别性能的评价指标是行人重识别结果排名第一的正确率rank1,rank1的取值越高,行人重识别性能越好。rank1的计算方法为:①对矩阵d按行进行升序排列得到矩阵d′;②对d′中第i行中的第一列元素d′i0在d中找到对应元素,记为dij;③对各行中i和j相等的个数进行累加求和,得到numrank1;④
本实施方案中选用了ilids-vid标准数据集中的75对行人来进行识别,识别结果如表2所示。其中rfa-net重识别方法中的rank1、rank5、rank10和rank20取值分别为50.40%、79.20%、87.47%和94.80%,本文所提重识别方法中rank1、rank5、rank10和rank20取值分别为54.93%、79.07%、88.67%和94.80,实验结果表明,本发明的一种基于自适应预测模式的lstm网络行人重识别方法针对于遮挡情况能够在很大程度上提高行人重识别的性能。
表2
- 还没有人留言评论。精彩留言会获得点赞!