基于FPGA的决策树模型中的浮点数离散化方法与流程
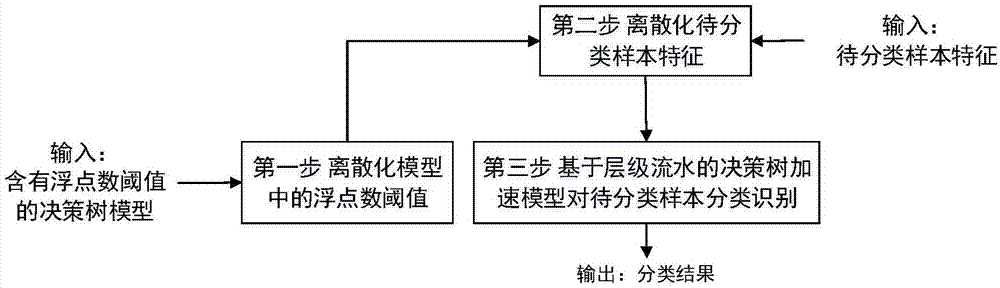
本发明属于机器学习领域,涉及一种基于硬件的决策树分类加速优化方法,具体涉及基于fpga的决策树模型中的浮点数阈值离散化方法。
背景技术:
决策树是机器学习中一种常用的算法,也是多种集成分类器的基分类器,如随机森林,bagging算法等。它在多个领域都表现出优秀的分类能力,如物体检测,网络流量分类等。由于待检测样本数目的急剧增长及众多应用要求实时性分类,决策树模型除了需要保证准确率外,还需具有极快的分类速度。轴平行决策树模型包括中间节点与叶子节点。中间节点包括一个特征和对应的阈值。当特征为离散特征时,其阈值是该特征的可能取值之一,从而产生多个分支(每个取值为一个分支)或两个分支(等于与不等于某一可能取值)。当属性为连续属性时,阈值通常为浮点数,并产生两个分支。叶子节点只包含类别信息。决策树分类时,每个样本从根节点开始比较,直至到达一个叶子节点获得分类结果。已有的决策树分类的软件实现,如在cpu平台上的分类器,已不能满足实时分类应用的速度需求,如网络流量识别。因此,众多工作利用硬件加速决策树分类过程。fpga由于其可编程,配置灵活备受青睐。目前基于fpga的决策树硬件实现方法主要包括两类。一类是将决策树与阈值网络相结合,第一层网络将每个节点作为单独的处理单元对输入进行计算,第二层网络接受第一层的节点输出并利用定义好的分类逻辑给出结果。这种方法只包含两个步骤,因此分类速度快,但是需要大量的计算资源,并且也会引入大量的路由逻辑。第二类方法将树的每层作为独立的处理单元,实现层级流水,在完全流水化时也可实现每时钟周期一个输出,相对第一种方法对资源需求较少。以上两种方案的重点都在于如何并行化或流水化分类过程从而提高分类速度。当分类任务具有连续属性时,分类模型就可能存在浮点数阈值。而浮点数相比整数需要更多的存储资源,也需要更复杂的计算单元。这两种方法均没有涉及决策树中浮点数值在硬件实现中的存储与计算的优化,没有考虑如何优化模型中存在的浮点数。hiroki等人在fpga上实现随机森林模型(hirokinakahara等,arandomforestusingamulti-valueddecisiondiagramonanfpga(fpga平台上基于多值决策图的随机森林模型),ieee47thinternationalsymposiumonmultiple-valuedlogic(第47届多值逻辑国际会议),2017,266-271)。对于模型中的32位浮点数值,采用14位的定点数表示,这种方法虽然减少所需的存储资源,但是会影响模型的分类精度。akira提出使用k-means方法对决策树中的特征阈值进行聚类,从而合并相近的阈值,减少阈值的个数,从而降低所需的存储资源,但最终的阈值依然为浮点数,并且也会影响模型的精度(akirajinguji等.anfpgarealizationofarandomforestwithk-meansclusteringusingahigh-levelsynthesisdesign(使用高级分析设计及k-means聚类实现fpga平台的随机森林模型).ieicetransactionsoninformationandsystems(ieice信息与系统),2018,101(2):354-362)。综上所述,现有基于fpga的决策树硬件实现方法重点在于设计流水化方案以提高分类速度,很少有工作关注硬件实现时如何处理决策树模型存在的浮点数,而浮点数对硬件实现中的存储与计算有极大的影响,现有针对浮点数进行优化的方法虽然减少所需的存储资源,但是会影响模型的分类精度,进而导致现有方法无法在硬件实现的存储和计算资源过大和分类精度之间获得很好的折中。技术实现要素:本发明针对现有基于fpga的包含浮点阈值的决策树模型的硬件实现方法无法在降低硬件巨大存储和计算资源的同时保持模型的分类性能的问题,提供一种基于fpga的决策树模型中的浮点数离散化方法,离散化轴平行二叉决策树模型中的浮点数阈值,将模型中的浮点数转换为整数,在不改变模型的分类性能的前提下减少硬件实现需要的存储和计算资源,优化硬件实现方案。技术方案如下:第一步,离散化决策树模型中的浮点数阈值。记输入为含有浮点数阈值的决策树模型t;样本的连续属性集为f,属性集f大小为m,m为自然数;fi表示第i个属性,fi对应的阈值列表为li,i∈{0,...,m}。第二步,离散化待分类样本的浮点数特征,即对输入的待分类样本的浮点数特征,根据离散化后的阈值列表进行转换,得到样本离散化后的整数特征向量。第三步,基于层级流水的决策树加速模型对待分类样本分类识别。作为本发明技术方案的进一步改进,所述第一步离散化决策树模型中的浮点数阈值具体步骤为:步骤1.1构建阈值列表。方法为:对每个连续属性fi,遍历决策树模型t中使用连续属性fi的所有中间节点,并将对应的阈值添加至fi的阈值列表li中,阈值列表中的阈值从小到大排列。步骤1.2离散化阈值。方法为:对于每个阈值列表li中的阈值,按照其在列表中的下标转换为对应的奇数;即当阈值下标为j时,对应的奇数为1+2*j,j为大于等于0的整数。步骤1.3决策树模型转换,即将决策树模型t中的浮点数阈值按照步骤1.2离散化后的阈值转换为对应的整数值,生成不包含浮点数阈值的决策树模型。作为本发明技术方案的进一步改进,所述第二步离散化待分类样本的浮点数特征,具体方法为:对于浮点数类型属性fi,设其值为x,在浮点数阈值列表li中查找其值x所在的下标k,并使得x小于等于k位置的阈值,大于k-1位置的阈值,则x对应的整数值为2*k。作为本发明技术方案的进一步改进,所述第二步中,对于浮点数类型属性fi,在浮点数阈值列表li中使用二分查找获得其值x所在的下标k。作为本发明技术方案的进一步改进,所述第三步基于层级流水的决策树加速模型对待分类样本分类识别,步骤如下:步骤3.1构建基于层级流水的决策树分类加速模型,基于层级流水的决策树分类加速模型中,决策树的每层是一个独立的处理单元,具有独立的存储与计算资源。每层包含节点存储和输入/输出缓冲存储两种存储;步骤3.2将第二步得到的离散化后的整数特征向量送入在fpga平台上实现的基于层级流水的决策树分类加速模型,得到待分类样本的分类结果。作为本发明技术方案的进一步改进,所述步骤3.1中,节点存储用来存储该层的中间节点信息,叶子节点的类别信息直接保存在其分支节点地址域中,并设置对应的标记位。节点存储包含特征号(featureid),阈值(threshold),左分支地址或标签(leftbranchaddr/label),右分支地址或标签(rightbranchaddr/label),左叶子节点标记位(leftleafflag),右叶子节点标记位(rightleafflag);输入/输出缓冲存储用来保存该层样本的输入与输出,从而保证每层可以同时处理不同的样本。输入/输出缓冲保存待检测样本的节点地址(nodeaddr)及待检测样本的特征向量(featurevector)及标签域(label)。作为本发明技术方案的进一步改进,所述步骤3.1中,特征号featureid域所需的位数与特征个数相关,若特征个数为n,则该域需log2n位。threshold与阈值范围及类型有关,若需表示浮点数,一般需32位。分支地址域则与下一层节点个数及类别个数有关。若下层节点个数为m,类别个数为k,则每层分支地址域最小为max(log2m,log2k),max()为取大函数,即从log2m和log2k中取大者。与现有技术相比,本发明的有益效果是:●本发明通过第一步离散化决策树模型中的浮点数阈值,得到不包含浮点数阈值的决策树模型,第二步离散化待分类样本的浮点数特征,对输入的待分类样本的浮点数特征,根据离散化后的阈值列表进行转换,得到样本离散化后的整数特征向量;进而既保证不改变分类器的分类性能,又有效的消除了模型中的浮点阈值;●本发明可移植性好,易于移植到其他基于决策树的模型,如随机森林算法。与单一的决策树不同,随机森林在生成阈值列表时,应生成全局的阈值列表,即对于某一属性,列表应包含所有树中该属性的阈值,才能保证模型的一致性。附图说明图1是本发明总体流程图;图2是本发明包含连续属性的决策树模型示意图;图3是本发明实施例对图1模型阈值整数化示例;图4是本发明实施例对决策树模型转换得到的基于层级流水的决策树加速模型;图5是本发明存储对象结构示意图;图6是本发明实施例模型分类结果比较图;图7是本发明实施例浮点数值类型特征使用次数图;图8是本发明实施例模型a浮点数特征阈值列表长度分布图。具体实施方式下面结合实施例对本发明的实施方式进行进一步详细说明。如图1所示,本发明基于fpga的决策树模型中的浮点数离散化方法包括以下步骤:第一步,离散化图2所示决策树模型中的浮点数阈值,图2给出一个包含连续属性及浮点数阈值的决策树模型示例。其中,f1,f2为两个连续属性,a,b为分类标签,模型含有7个中间节点。步骤1.1构建阈值列表。对连续属性fi,遍历决策树模型t中使用连续属性fi的所有中间节点,并将对应的阈值添加至fi的阈值列表li中,阈值列表中的阈值从小到大排列,i=1,2。得到图3中步骤1.1所示的阈值列表l1={-50,3.25,100.6,501.25},l2={-50.15,206.3,1000.57}。步骤1.2离散化阈值。对于每个阈值列表li中的阈值,按照其在列表中的下标转换为对应的奇数;即当阈值下标为j时,对应的奇数为1+2*j,j为大于等于0的整数,从而将li中的所有阈值转换为对应的奇数。得到如图3中步骤1.2所示的离散化阈值。步骤1.3决策树模型转换,即将决策树模型t中的浮点数阈值按照步骤1.2离散化后的阈值转换为对应的整数值,生成如图3所示的不包含浮点数阈值的决策树模型。第二步,离散化待分类样本的浮点数特征,即对输入的待分类样本的浮点数特征,根据离散化后的阈值列表进行转换,得到样本离散化后的整数特征向量。如图3中第二步所示,对于原数据{40.5,20.02},根据离散化后的阈值列表进行转换,得到样本离散化后的整数特征向量{4,0}。第三步,基于层级流水的决策树加速模型对待分类样本分类识别。步骤3.1构建基于层级流水的决策树分类加速模型,基于层级流水的决策树分类加速模型中,决策树的每层是一个独立的处理单元,具有独立的存储与计算资源。每层包含节点存储和输入/输出缓冲存储两种存储;节点存储用来存储该层的中间节点信息,叶子节点的类别信息直接保存在其分支节点地址域中,并设置对应的标记位,进而将图4(a)所示的决策树模型构建成图4(b)所示的基于层级流水的决策树分类加速模型。如图5(a)所示,节点存储包含特征号(featureid),阈值(threshold),左分支地址或标签(leftbranchaddr/label),右分支地址或标签(rightbranchaddr/label),左叶子节点标记位(leftleafflag),右叶子节点标记位(rightleafflag);输入/输出缓冲存储用来保存该层样本的输入与输出,从而保证每层可以同时处理不同的样本。如图5(b)所示,输入/输出缓冲保存待检测样本的节点地址(nodeaddr)及待检测样本的特征向量(featurevector)及标签域(label)。其中,特征号featureid域所需的位数与特征个数相关,若特征个数为n,则该域需log2n位。threshold与阈值范围及类型有关,若需表示浮点数,一般需32位。分支地址域则与下一层节点个数及类别个数有关。若下层节点个数为m,类别个数为k,则每层分支地址域最小为max(log2m,log2k),max()为取大函数,即从log2m和log2k中取大者。步骤3.2将第二步得到的离散化后的整数特征向量送入在fpga平台上实现的基于层级流水的决策树分类加速模型,得到待分类样本的分类结果。本发明采用真实网络流量进行了测试,并对本发明的有效性进行评估。1)数据集测试数据集采用vpn-nonvpn公开数据集(lashkari等,characterizationofencryptedandvpntrafficusingtime-relatedfeatures(基于时间相关特征分类加密与虚拟专用网络流量).proceedingsofthe2ndinternationalconferenceoninformationsystemssecurityandprivacy(第二届信息系统安全与隐私国际会议论文集),2016,407-414)。该数据集中的流量包含14种类别,即:即时通讯(chat),邮件(email),端到端传输(p2p),文件传输(filetransfer),流媒体(streaming),网页浏览(browsing),语音通信(voip)及各类对应的虚拟专用网络(vpn)下的流量。但在该数据集的分类下,不同的类别有具有交叉的情况,例如使用浏览器的youtube和vimeo流量既属于streaming,又属于browsing,将这类流量看作streaming,并舍去类别browsing。剩下的12种类别存在样本不均衡的情况,例如vpn-email只有640条流数据,而voip数据有14万余条流,只保留数据样本在1000-10000间的类别。最终数据集的组成如表1所示。表1.数据集组成类别流个数即时通讯8470邮件6595端到端传输1180流媒体5078虚拟专用网络下的即时通讯5155虚拟专用网络下的文件传输2825虚拟专用网络下的流媒体2623虚拟专用网络下的语音通信5265总计37191本实施例采用lashkari(lashkari等.characterizationofencryptedandvpntrafficusingtime-relatedfeatures(基于时间相关特征分类加密与虚拟专用网络流量).proceedingsofthe2ndinternationalconferenceoninformationsystemssecurityandprivacy(第二届信息系统安全与隐私国际会议论文集).2016,407-414)给出的23种时间相关统计特征,并使用其提供的iscxflowmeter工具提取特征。根据其实验结果,超时时间设置为30s。23种时间相关的统计特征如表2,其中含有12种浮点数类型统计特征。表2.特征子集2)决策树模型基于上述数据集采用weka提供的c4.5决策树训练分类模型,并采用10折交叉验证方法。其中,模型a直接使用连续属性训练决策树模型。模型b采用entropy-mdl方法对连续属性离散化,并训练二叉决策树模型。模型c采用entropy-mdl方法对连续属性离散化,但不限制模型为二叉树。三种模型的性能比较如表3,得到图6(a)每类分类精度详细和图6(b)每类分类召回率详细。表3.模型比较模型连续属性离散化二叉树总节点个数叶子节点数深度训练时间平均准确率模型a否是27091355342.45s77.51%模型b是是30971549239583.81s75.51%模型c是否524935188770.47s74.20%从表3看出,离散化连续属性会极大的增加模型深度或叶子节点个数,并且不一定会带来分类性能的提升。因此通过离散化连续属性消除模型中的浮点数未必是一种有效的手段。接下来基于模型a对本发明方法进行评估。3)硬件评估假设fpga的硬件资源足够实现每层流水化,采用基于层级流水的决策树加速模型,对模型浮点数阈值整数化前后的资源消耗进行评估。对于整数类型特征的资源占用不做讨论。(1)存储资源根据第三步描述的流水化方案可知,只有中间节点的“阈值”域及输入输出缓冲区的“特征向量”域的大小受浮点数类型数值影响。因此接下来仅对整数化前后这两个域所需的存储资源进行比较。未整数化前,浮点数采用32位表示。则采用浮点数值特征的中间节点的“阈值”域需要32位,输入与输出缓冲区的“特征向量域”保存12个浮点数值类型的特征需384位。考虑到使用浮点阈值的中间节点共599个,如图7所示的本发明实施例浮点数值类型特征使用次数,深度为34,则存储资源需45280bits,即:32*599+(384+384)*34bits。对模型中的浮点阈值进行整数化处理后,得到如图8所示的本发明实施例模型a浮点数特征阈值列表长度分布图。根据阈值列表长度分布,10位足以表示整数化后的阈值,即采用浮点数类型特征的中间节点的阈值位只需10位。对于输入输出缓冲区,样本的特征向量中离散化后的12种特征最少需使用63位。阈值列表中的浮点数仍用32位表示。若输入样本的转换也在硬件中实现,那么最终模型需要的存储大小约29154bits。即:(590*32+599*10+34*(63+63))。相比未整数化前,存储资源节约35.61%。若输入样本的转换过程在硬件外实现,如在提取样本特征时就进行转换,那么最终模型需要的存储大小约10274bits。即:(599*10+34*(63+63)),存储资源节约77.31%。值得注意的是,所有不同的浮点数阈值总个数为590,而使用浮点数类型特征的中间节点个数为599。这说明在整棵树中使用同一个特征的节点可能具有相同的阈值。本发明可以避免相同特征阈值的重复存储。同时,可以推断,当浮点属性个数增多时,会节省更多的资源。(2)计算资源未整数化阈值前,每层需要进行浮点数比较。在整数化后,每层需要进行的是整数化的比较。若输入样本的连续特征离散化在硬件中实现,那么本发明依然需要使用浮点数比较单元。但若连续特征少于决策树的深度或者在硬件外实现整数转换,那么将会减少或避免浮点数比较运算。这一优点在使用决策树作为基分类器的集成模型中更为明显。由此可见,本发明提供一种基于fpga的决策树模型中的浮点数离散化方法。通过离散化浮点数阈值,将其转换为整数,从而消除决策树模型中的浮点数。这种方法不改变分类器的分类结果,并且可以有效的减少在fpga上实现时所需的存储空间与计算资源。最后所应说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1