一种智能交互自动问答系统以及自我学习方法与流程
本发明涉及领域智能交互自动问答技术领域,尤其涉及一种智能交互自动问答系统以及自我学习方法。
背景技术
对用户来说,自然语言是最佳的人机交互方式,智能交互自动问答系统用自然语言回答用户的问题,比搜索引擎更友好,更能满足用户操作简单化和知识精准化的需求。随着大数据知识管理、智能化深度分析、个人携带智能设备、移动互联网等相关技术与应用的突飞猛进,自动问答的形态和应用场景正在经历深刻变化,也使得用户的行为与需求模式发生了极大的变化。将智能交互问答系统从基于文本关键词的层面,提升到基于知识的层面,实现智能化的知识机器人,已成为交互自动问答系统未来的发展趋势与目标。
技术实现要素:
本发明的目的在于提供一种智能交互自动问答系统及其自我学习方法,从基于关键词的层面提升至基于知识的层面,实现个性化、智能化的知识机器人。
为实现上述目的,本发明的技术方案如下:
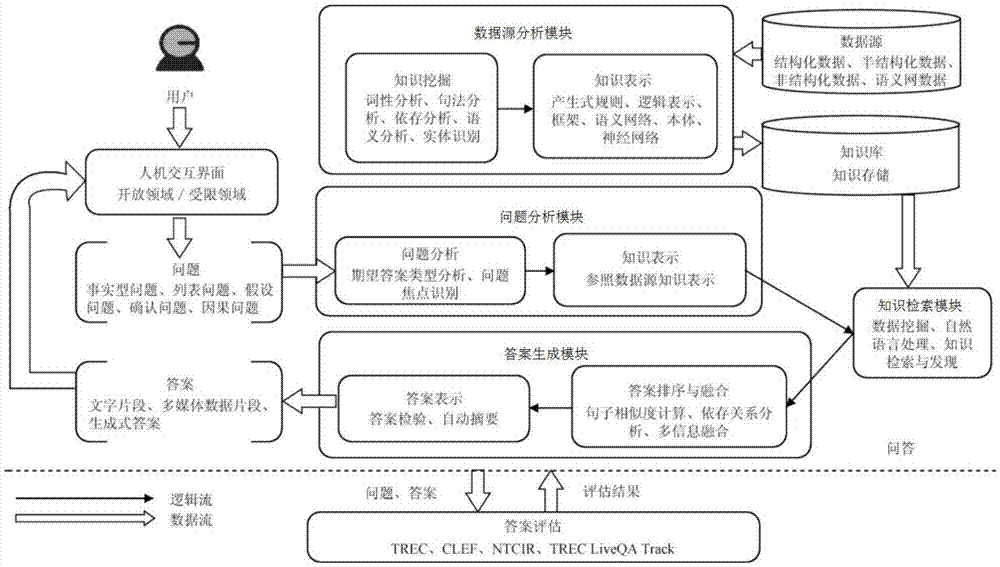
一种智能交互自动问答系统,包括数据源分析模块、问题分析模块、知识检索模块、答案生成模块;
所述问题分析模块基于数据源分析模块对问题分析后表示成与数据源相匹配的问题知识表示;
所述知识检索模块基于问题知识表示,在知识库中检索相关知识子集;
所述答案生成模块对知识子集进行相似度计算、依存关系分析、多源数据融合、知识排序与融合后进行答案检验和评估后,生成答案。
进一步的,所述数据源分析模块采用词性分析、句法分析、语义分析、依存分析和实体识别的多种方式,从结构化、半结构化或非结构化数据中,提取有用的信息与知识,并表示成知识表示形式。
进一步的,所述问题分析模块采用自然语言处理技术对问题进行语义理解和分析,通过对问题进行类型分类确定期望答案类型。
一种智能交互自动问答系统的自我学习方法,包括如下步骤:
知识识别,通过知识库内封装好的知识,对问题进行分析检索,确认是否存在相关知识;
知识创建,当检索不到相关知识或相关知识不全面时,智能交互自动问答系统触发获取新知识的需求,对数据源进行分析和知识提取;
知识存储,对提取的新知识存入知识库,用于知识识别阶段的分析检索;
知识共享,智能交互自动问答系统生成答案并共享给用户;
知识使用,用户根据获得的答案解决问题、作出决策、提高效率、促进创新思维;
知识学习,通过用户使用知识的反馈,并基于自动问答评估方法,作为智能交互自动问答系统创建新知识或改进现有知识的基础,如果知识被评估为有价值,则将进入知识存储阶段,如果知识被评估为不完整,则返回到知识识别或知识创建阶段。
本发明的智能交互自动问答系统及其自我学习方法,从基于文本关键词的层面,提升至基于知识的层面,对用户来说,自然语言是最佳的人机交互方式,自动问答系统用自然语言来回答用户的问题,比搜索引擎更友好,更能满足用户操作简单化和知识精准化的需求,实现智能化交互问答的知识机器人。
附图说明
图1是本发明一个实施例的智能交互自动问答系统的结构框图;
图2是本发明一个实施例的智能交互自动问答系统的递归神经网络模型图;
图3是本发明一个实施例的智能交互自动问答系统的注意力模型图。
具体实施方式
下面结合附图和实施例对本发明的技术方案做进一步的详细说明。
如图1所示,本发明的一种智能交互自动问答系统,包括数据源分析模块、问题分析模块、知识检索模块和答案生成模块。
其中,问题分析模块基于数据源分析模块对问题分析后表示成与数据源相匹配的问题知识表示,数据源分析模块采用词性分析、句法分析、语义分析、依存分析和实体识别的多种方式,从结构化、半结构化或非结构化数据中,提取有用的信息与知识,并表示成知识表示形式,问题分析模块主要是采用包括而不限于词性分析、问题焦点识别等自然语言处理方法,对问题进行语义理解和分析,通常,问题可分为事实性问题、列表问题、假设问题、确认问题和因果问题等,问题类型将影响对期望答案类型的判断,同时,将问题的预期答案类型分为如:人、机构、地点、数量、时间等基本类型,期望答案类型可以为知识检索和答案抽取提供参考依据。
知识检索模块基于问题知识表示,在知识库中检索相关知识子集,涉及数据挖掘、信息检索、知识检索与发现等多种方法与技术。
答案生成模块对知识子集进行相似度计算、依存关系分析、多源数据融合、知识排序与融合后进行答案检验和评估后,生成答案,答案可能是抽取文字或多媒体数据片段。
一种智能交互自动问答系统的自我学习方法,包括如下步骤:
知识识别,通过知识库内封装好的知识,对问题进行分析检索,确认是否存在相关知识;
知识创建,当检索不到相关知识或相关知识不全面时,智能交互自动问答系统触发获取新知识的需求,对数据源进行分析和知识提取;
知识存储,对提取的新知识存入知识库,用于知识识别阶段的分析检索;
知识共享,智能交互自动问答系统生成答案并共享给用户;
知识使用,用户根据获得的答案解决问题、作出决策、提高效率、促进创新思维;
知识学习,通过用户使用知识的反馈,并基于自动问答评估方法,作为智能交互自动问答系统创建新知识或改进现有知识的基础,如果知识被评估为有价值,则将进入知识存储阶段,如果知识被评估为不完整,则返回到知识识别或知识创建阶段。
本发明的智能交互自动问答系统,基于递归神经网络,利用问题句子的依存解析树,从词和短语层面对问题句子进行表示,其主要是利用语义相似度建立实体题集与实体关系的匹配关系,用于对单关系问题的自动问答。该模型由词散列层、一个三层的神经网络和语义层构成,如图2所示,在散列层中,为每个词(如“cat”),添加首尾分隔符(如“#cat#”),然后根据词中字母三元组(如“#ca,cat,at#”),将词散列化为词向量作为神经网络的输入。神经网络由卷积层、maxpooling层和前馈层构成。首先,利用词在句子中的局部上下文信息,通过卷积层的处理得到一组局部上下文特征向量,在局部上下文特征空间中,语义相似的n元词组(word-n-grams)将被映射为相似的向量。考虑到句子的含义往往取决于少数几个关键词,采用maxpooling层抽取最显著的局部特征向量,从而得到固定长度的全局特征向量。最后,通过前馈神经网络层,从全局特征向量中抽取非线性语义特征。语义层实际上也是一个神经网络,其激活函数为softmax,计算语义特征相似度,从而得到问题实体指代(entitymentions)和知识库实体相似度,以及关系模式和知识库关系的相似度。
在大部分基于神经网络的智能交互问答系统中,对于与不同答案的相似度计算,问题都被表示为相同的向量。然而,应该根据候选答案的焦点,基于注意力模型动态计算问题的向量表示,如图3所示,系统将问题中的每个词表示为词向量(wordembedding),并经过长短时记忆模型(longshort-termmemory,lstm)获得问题的句向量;将答案从答案实体ae、答案关系ar、答案类型at、答案上下文ac等方面基于知识库分别表示为答案向量ee、er、et、ec;最后以句向量和答案向量为输入,经过注意力模型获得。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!