案情数据的归并方法及装置与流程
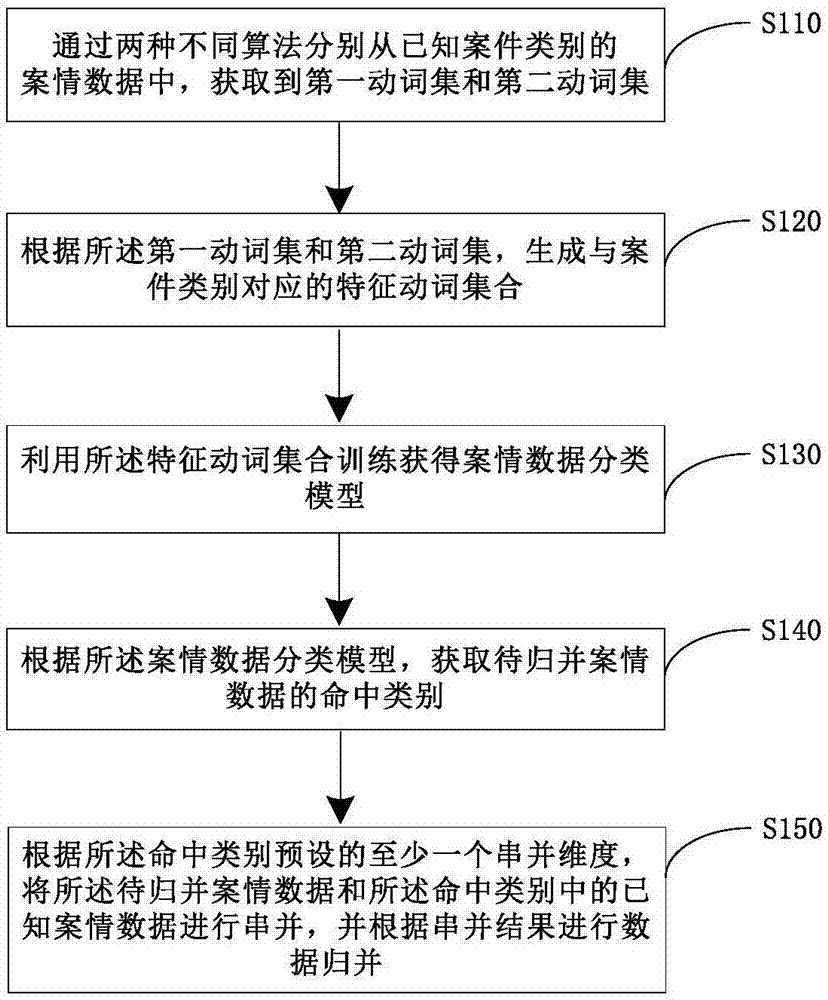
本申请涉及犯罪案情数据挖掘
技术领域:
,尤其涉及一种案情数据的归并方法及装置。
背景技术:
在刑事案件侦破
技术领域:
,案件串并是串联案件和并案侦查的简称,案件串并分析不仅有利于打击多发性、连续性、区域性犯罪活动,遏制案件的多发态势,还能使执法人员对可能发生的犯罪活动进行预测,从而及时打击预防。通常,案件串并首先要对案情数据进行分类,例如,盗窃类、抢劫类等,其次,再将同一案件类别的不同案情数据进行对比分析,执法人员凭借其办案经验来判断案件的相似程度,进而完成案件的串并侦查工作。然而,由于执法机构常年积累的犯罪案情数据量巨大,且其中不乏一大部分内容有缺失、特征要素不明确的数据,这就使得针对任意一组案情数据,尤其是不完整的案情数据的串并分析,都需要消耗大量的时间,加之这些分析均是基于执法人员的经验进行,因此串并的准确率也无法得到保证。由此,大量的案件之间潜在的关联,难以得到挖掘,从而导致数据利用率低且办案效率低下的问题。因此,如何提高对案情数据的串并精度和效率,尤其是对不完整的案情数据的串并,成为本领域技术人员亟待解决的技术问题。技术实现要素:本申请提供一种案情数据的归并方法及装置,以提高对案情数据的串并精度和效率。第一方面,本申请提供了一种案情数据的归并方法,该方法包括:通过两种不同算法分别从已知案件类别的案情数据中,获取到第一动词集和第二动词集;根据所述第一动词集和第二动词集,生成与案件类别对应的特征动词集合;利用所述特征动词集合训练获得案情数据分类模型;根据所述案情数据分类模型,获取待归并案情数据的命中类别;根据所述命中类别预设的至少一个串并维度,将所述待归并案情数据和所述命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并。第二方面,本申请提供一种案情数据的归并装置,包括:获取单元,用于通过两种不同算法分别从已知案件类别的案情数据中,获取到第一动词集和第二动词集;生成单元,用于根据所述第一动词集和第二动词集,生成与案件类别对应的特征动词集合;训练单元,用于利用所述特征动词集合训练获得案情数据分类模型;分类单元,用于根据所述案情数据分类模型,获取待归并案情数据的命中类别;归并单元,根据所述命中类别预设的至少一个串并维度,将所述待归并案情数据和所述命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并。本申请提供的案情数据的归并方法及装置,首先基于两种不同的算法,分别从已知案件类别的案情数据中获取第一动词集和第二动词集,并根据第一动词集和第二动词集生成与案件类别对应的特征动词集合,提高了获取特征动词的准确率;其次利用该特征动词集合训练获得案情数据分类模型,通过该案情数据分类模型确定待归并案情数据的命中类别,提高了模型对待归并案情数据的分类精度;最后根据命中类别预设的至少一个串并维度,将待归并案情数据和该命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并,提高了公安领域案件串并工作的精度和效率,同时提高了海量案情数据的利用率。附图说明为了更清楚地说明本申请的技术方案,下面将对实施例中所需要使用的附图作简单地介绍,显而易见地,对于本领域普通技术人员而言,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。图1为本申请根据一示例性实施例示出的一种案情数据的归并方法流程图;图2为本申请为图1所示方法中步骤s110的一种实现方法流程图;图3为本申请根据一示例性实施例示出的第一动词集、第二动词集以及特征动词集合的逻辑关系图;图4为图1所示方法中步骤s130的一种实现方法流程图;图5为图1所示方法中步骤s140的一种实现方法流程图;图6为图1所示方法中步骤s150的一种实现方法流程图;图7为图1所示方法中步骤s150的另一种实现方法流程图;图8为本申请根据一示例性实施例示出的一种从候选词集中获取第一动词集和第二动词集的方法流程图;图9为本申请根据一示例性实施例示出的一种案情数据的归并装置的框架示意图。具体实施方式为了使本
技术领域:
的人员更好地理解本发明中的技术方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。实施例一本实施例提供一种案情数据的归并方法,参阅图1,该方法包括下述步骤:在步骤s110中,通过两种不同算法分别从已知案件类别的案情数据中,获取到第一动词集和第二动词集;公安领域的案情数据是指包括案发时间、地点、涉案人员和/或违法行为描述等案情关键信息的数据,包括但不限于语音形式的案情数据和文本形式的案情数据。其中,文本形式的案情数据主要来自于现有犯罪数据库中的自有案情描述或者公安内部网络上的案情公告。本申请实施例以非结构化或半结构化的数字化案情文本为例,对本申请方法的具体实施方式进行说明,但该种形式的案情数据并不构成对申请保护范围的限定。对于某一特定的、完整的案情数据,可以明确其所属的案件类别,所述案件类别包括盗窃类、抢劫类、诈骗类以及拐卖人口类等等。示例性地,案件类别为盗窃类的一案情数据如下:(一)接警后,我所民警立即赶到现场,经初步了解,系报警人***(男,身份证号码******************,联系电话*********,户籍:重庆市潼南县古溪镇下炮村,现住址:贵阳市南明区花果园区10栋1单元503号)称其2017年10月11日10时30分,发现其位于花果园区5栋1楼1-7门面被盗,被盗现金3600元人民币,该事发地属于松山南路社区,我所受理为刑事案件。由于完整的案情数据中包括犯罪行为描述性的词汇,例如,抢劫类案件的案情数据中通常包括“抢劫”、“被抢”,盗窃类案件的案情数据中通常包括有“盗窃”、“被盗”等动词,可见动词对其所属的案情数据具有较强的类别区分能力。因此,在本实施例中,分别从每个已知案件类别下的多个案情数据中获取第一动词集和第二动词集,从而得到对应于每个案件类别的第一动词集和第二动词集。参阅图2,在本申请实施例中,步骤s110的一种实现方法为:在步骤s111中,对案情数据进行切词,并对切词得到的分词添加词性标签;可选的,使用基于机器学习的中文切词方式,例如ictclas分词法,对案情数据文本进行切词,同时,对切词得到的分词添加词性标签,以便根据词性标签从全部分词中抽取动词,以及在后续步骤中根据词性标签抽取案情数据的各个维度值。示例性地,对上述案件(一)切词的结果如下:[接警/v][后/f],[我/rr][所/usuo][民警/n][立即/d][赶到/v][现场/s],[经/p][初步/d][了解/v],[系/v][报警/vn][人/n]***([男/b],[身份证/n]******************,[联系/v][电话/n]*********,[户籍/n]:[重庆市/ns][潼南县/ns][古溪镇/ng][下/vf][炮/n][村/n],[现/tg][住址/n]:[贵阳市/ns][南明区/ns][花果/n][园/ng][区/n][10/m][栋/q][1/m][单元/n][503/m][号/q])[称/v][其/rz][2017年/t][10月/t][11日/t][10时/t][30分/t],[发现/v][其/rz][位于/v][花果/n][园/ng][区/n][5/m][栋/n][1/m][楼/n][1-7/m][门面/n][被盗/vn],[被盗/vn][现金/n][3600/m][元/q][人民币/n],[该/rz][事发/vi][地/ude2][属于/v][松山南/ns][路/n][社区/n],[我/rr][所/usuo][受理/v][为/p][刑事/b][案件/n]。需要说明的是,上述词性标签如ns、m、q等对应的词性名称可参考《标准汉语词性对照表》。值得注意的是,v对应的词性为动词,vn对应的词性为名动词,vf对应的词性为趋向动词,vi对应的词性为不及物动词。在步骤s112中,根据词性标签,从所有所述分词中提取动词,以及,对提取到的动词进行去停用词处理,生成候选词集;示例性地,根据词性标签,从上述案件(一)切词得到的所有分词中提取到的动词如下:[接警/v][赶到/v][了解/v][系/v][报警/vn][联系/v][下/vf][称/v][发现/v][位于/v][被盗/vn][事发/vi][属于/v][受理/v]在信息检索领域中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉某些字或词,这些字或词即被称为停用词(或集外词)。任何一类的词语都可以被选作停用词。具体地,将哪些词作为停用词,需要根据给定的目的来确定。对于案情数据而言,除常规停用词外,还常常包括出现频率很高但对数据归并无用的词,例如,“犯罪嫌疑人”、“报案”、“出警”、“受理”等等。本申请实施例中,可以预先建立公安领域专门的停用词表,其中包括公安领域的专用动词停用词。根据该预设的专用停用词表,去除步骤s111提取到的动词中的停用词。示例性地,对从案件(一)的切词中提取的动词去除停用词,得到候选词集如下:[赶到/v][联系/v][发现/v][被盗/vn][事发/vi]在步骤s113中,从候选动词集中获取第一动词集和第二动词集。实际上,从候选词集中获取第一动词集或第二动词集的方法有很多,例如,文档频率方法(df)、互信息(mi)、信息增益(ig)、期望交叉熵(ece)、文本证据权(wet)等等。这些方法的基本思想是通过设定一个阈值,然后对候选词集中的每一个动词计算统计度量值,而后选取统计度量值大于所设阈值的动词形成第一动词集或第二动词集。本实施例中,通过两种不同的算法分别从候选词集中获取到第一动词集和第二动词集。由于获取方法不同,因而得到第一动词集所包括的动词词汇与第二动词集所包括的动词词汇可能不同。在步骤s120中,根据所述第一动词集和第二动词集,生成与案件类别对应的特征动词集合;在本申请实施例中,特征动词集合包括数个具有一定的类别区分能力的特征动词,这些特征动词用于在下述步骤s130中训练案情数据分类模型。本申请实施例根据第一动词集和第二动词集生成与案件类别对应的特征动词集合,而不是直接以第一动词集或者第二动词集中的词汇作为特征词训练案情数据分类模型,从而减小或消除了在选取特征词的环节产生的误差,提高了案情数据归并结果的准确度。本实施例中,步骤s120的一种实现方法为:在步骤s121中,根据预设规则,确定第一动词集的候选特征动词和第二动词集的候选特征动词;可选的,上述预设规则可以为,根据每个动词的统计度量值,对第一动词集中的动词按照倒序排列,按照预设的候选特征词数量,选取排名靠前的动词为候选特征动词。示例性地,本申请对盗窃类下的300条案情数据和诈骗类下的300条案情数据执行上述步骤s110和步骤s120,得到的第一动词集和第二动词集分别如下:盗窃类-第一动词集{发现入室撬翻破坏盗窃被盗联系发生}盗窃类-第二动词集{发现靠近公交乘坐划扯盗窃被盗发生}诈骗类-第一动词集{投资奖励冒充转账受骗骗取信任发现}诈骗类-第二动词集{中奖补助冒充汇款转账受骗骗取发现}根据各动词的统计度量值(未示出)对每个词集中的动词按照倒序排列,并取前5个(预设的候选特征动词数量)动词为候选特征动词,得到:盗窃类-第一动词集-候选特征词{被盗盗窃发现发生入室}盗窃类-第二动词集-候选特征词{被盗盗窃发生发现靠近}诈骗类-第一动词集-候选特征词{受骗骗取转账冒充发现}诈骗类-第二动词集-候选特征词{受骗骗取冒充转账汇款}在步骤s122中,选取第一动词集和第二动词集中相同的候选特征动词,形成与案件类别对应的特征动词集合。示例性地,上述盗窃类和诈骗类对应的特征动词集合分别如下:盗窃类-特征动词集合{被盗盗窃发现发生}诈骗类-特征动词集合{受骗骗取转账冒充}其中,同一案件类别对应的第一动词集、第二动词集以及特征动词集合的关系如图3所示。本实施例中,选取第一动词集和第二动词集中共有的候选特征词,生成特征动词集合,消除了单一的选择特征动词的方法存在的误差,有利于提高案情数据归并结果的准确度。在步骤s130中,利用所述特征动词集合训练获得案情数据分类模型;本申请实施例所述的案情数据分类模型,是指在给定案件类别分类体系的前提下,能够实现根据案情数据的内容自动判别案件类别的功能模型。该案情数据分类模型基于机器学习技术,通过不同案件类别对应的特征动词集合训练获得。可选的,本申请实施例利用libsvm工具训练获得案情数据分类模型,参阅图4,可以包括下述步骤:步骤s131,将特征动词集合中的特征动词转换为特征向量;在本申请实施例中,需要将特征动词集合中的特征动词转换成libsvm可接受的数据格式,即将所述特征动词进行量化。具体的,实现从案件类别(名称)、特征动词集合中每个词元素及其统计度量值到数字编号的映射转换。可选的,采用tf-idf值作为特征动词集合中每个词元素的统计度量值。tf-idf(termfrequency–inversedocumentfrequency)是一种用于信息检索与数据挖掘的加权技术。tf意思是词频(termfrequency),idf意思是逆向文件频率(inversedocumentfrequency)。tf-idf是一种统计方法,用以评估一个字词对于一个语料库的重要程度。字词的权重随着它在语料中出现的次数成正比增加,但同时会随着它在其他语料库中出现的频率成反比下降。本申请中,tf表征某个动词在其自身所属的案情数据中出现的频率,idf表征包含某个动词的案情数据的频率的倒数。示例性地,假设盗窃类(预设编号为1)对应的特征动词集合中的每个动词的tf-idf值如下:特征动词tf-idf值(从高到底)(1)被盗0.13(2)盗窃0.12(3)发现0.0285(4)发生0.0195则根据步骤s131,将上述盗窃类对应的特征词集合映射转换为特征向量的结果为:特征动词特征向量(1)被盗1:1:0.13(2)盗窃1:2:0.12(3)发现1:3:0.0285(4)发生1:4:0.0195其中,通过冒号隔开的数字编号依次代表案件类别代号、特征动词编号以及特征动词的统计度量值即tf-idf值。步骤s132,根据预设缩放规则,对所述特征向量进行缩放处理,得到训练输入文件;本申请中,通过步骤s132将量化后的数据缩放到某一范围之内,所述缩放规则可以为一缩放后的数据区间,例如[0,1]。可选的,libsvm工具通过使用svm_scale命令实现缩放操作,得到训练输入文件。步骤s133,利用所述训练输入文件训练获得案情数据分类模型。在本申请实施例中,还包括测试案情数据分类模型的分类精度以及案情数据分类模型参数寻优,此处不再赘述。在步骤s140中,根据所述案情数据分类模型,获取待归并案情数据的命中类别;在本申请实施例中,待归并案情数据是指案件类别不明确和/或内容不完整的数据。参阅图5,上述步骤s140的一种实现方法是:在步骤s141中,对待归并案情数据进行切词,并对切词得到的分词添加词性标签;需要说明的是,步骤s141采用与步骤s111相同的分词器对案情数据进行切词。示例性地,一待归并案情数据如下:经出警民警***到达现场初步调查:系受害人***(女,58岁,户籍地:贵阳市云岩区浣沙巷19号2单元附32号,现住地:贵阳市花溪区康城花溪小区1栋3单元602号,身份证号:*********,电话:***********)称*************,购价7000元人民币),损失总价值11600元人民币,经技术科民警夏楚雄现场勘察系翻窗入室盗窃,贵筑派出所已受理为刑事案件侦查。使用ictclas分词器,该待归并案情数据进行切词,并对切词得到的分词添加词性标签,得到:[经/p][出警/vn][民警/n]***[到达/vt][现场/s][初步/d][调查/v]:[系/v][受害/vn][人/n]***([女/b],[58/m][岁/q],[户籍/n][地/ude2]:[贵阳市/ns][云岩区/ns][浣沙/n][巷/n][19/m][号/q][2/m][单元/n][附/v][32/m][号/q],[现/tg][住址/n]:[贵阳市/ns][花溪区/ns][康/a][城/n][花溪小区/n][1/m][栋/n][3/m][单元/n][602/m][号/q],[身份证/n]:*********,[电话/n]:***********)[称/v]*************,[购/v][价/n][7000/m][元/q][人民币/n]),[损失/v][总/p][价值/n][11600/m][元/q][人民币/n],[经/p][技术/n][科/n][民警/n]***[现场/s][勘察/v][系/v][翻/v][窗/n][入/v][室/n][盗窃/v],[贵筑/n][派出所/n][已/p][受理/v][为/p][刑事/b][案件/n][侦查/v]。在步骤s142中,根据词性标签,从所有所述分词中提取动词,以及,对提取到的动词进行去停用词处理,生成输入词集;示例性地,从上述待归并案情数据的所有分词中提取动词,并去除停用词,得到的输入词集为:{购损失翻入盗窃}需要说明的是,步骤s142使用与步骤s112相同的停用词表。在步骤s143中,将输入词集中的每个动词转换为输入词向量;在步骤s144中,根据所述预设缩放规则,对所述输入词向量进行缩放处理,得到输入序列;在步骤s145中,根据输入序列,从所述案情数据分类模型获取与输出序列对应的待归并案情数据的命中类别。在本实施例中,利用案情数据分类模型计算命中类别的准确率,如果准确率大于预设的阈值,确定待归并案情数据为该案件类别的数据。在步骤s150中,根据所述命中类别预设的至少一个串并维度,将所述待归并案情数据和所述命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并。本实施例基于每个案件类别,预设有数个串并维度,不同的案件类别预设的串并维度可能不同。例如,盗窃类案件预设的串并维度可以包括:作案时间、作案地点、涉案人员、作案工具、涉案金额(损失物品和损失金额)等,人口拐卖类案件预设的串并维度可以包括:作案时间、作案地点、涉案人员、被拐人特征等。在步骤s150中,将待归并案情数据与该待归并案情数据的命中类别下的其他已知的案情数据进行串并,参阅图6,一种可能的实现方法为:在步骤s151中,分别从待归并案情数据和所述已知案情数据中获取每个串并维度的维度值;本申请所述的维度值可以理解为,在一具体案情数据中,能够定义串并维度的特征或数值。例如,案发时间(串并维度)为2017年5月6日上午11时(维度值),案发地点(串并维度)为贵阳市花溪区康城花溪小区1栋3单元602号(维度值),作案工具为专用开锁工具(维度值)。在本申请实施例中,从案情数据中获取维度值的实现方式可分为两种,第一种是需要结合专门的关键词库的串并维度的维度值获取,例如,作案手段,作案工作,损失物品等。对于这种方法,首先对案情数据进行切词并标注词性信息,再结合专门的关键词库,从案情数据中抽取出各个串并维度的维度值信息。其中,专门的关键词库是指通过大量的分词训练,人工提取维度关键词建立的词典。第二种是不需要结合专门的关键词库的串并维度的维度值获取,例如,作案时间,涉案人员,作案地点,损失金额等。对于这种方法,首先根据各个分词的词性标签,判断每个分词是否为相应的词性,如果是,再做进一步抽取。例如,作案时间的维度值的抽取:以ictclas分词器为例,其通常倾向于将一个完成的时间短语进行细分,例如[2017年/t][10月/t][11日/t][10时/t][30分/t],因此,需要将连续的词性为时间的词进行合并。本申请实施例中,分别从待归并案情数据中以及所述命中类别下的每条已知案情数据中获取每个串并维度的维度值,并将待归并案情数据的维度值逐一与每一条已知案情数据的维度值进行对比,确定待归并案情数据与各条已知案情数据的匹配维度。沿用上述实施例(步骤s140),该待归并案情数据的命中类别为盗窃类,如果假设盗窃类预设的串并维度包括作案地点、作案工具、涉案金额,从上述待归并案情数据中获取每个串并维度的维度值,以及从盗窃类案件中的两条已知案情数据中获取每个串并维度的维度值的一种示例性结果为:案情数据作案地点作案工具涉案金额待归并案情数据…花溪小区…-11600元案件(二)…花溪小区…木棍3500元案件(三)…花果园区…铁棒8600元在步骤s152中,匹配两条案情数据的各个串并维度的维度值,确定维度值一致的串并维度为匹配维度;在本实施例中,通过维度值对比,确定维度值完全相同的串并维度为匹配维度,例如在上述示例中,待归并案情数据与案件(二)的作案地点相同,确定“作案地点”这一串并维度为待归并案情数据与案件(二)的匹配维度。在步骤s153中,根据匹配维度的数量和匹配维度的预设优先级,确定所述两条案情数据的相似度;由于案情数据与一般的数据文本不同,案情数据中包含大量的维度信息,如作案地点、作案时间等,各个维度对于串并的重要程度不一样,因此,本申请实施例对每个串并维度预设优先级,所述优先级对应一个权值,用于表示该维度的重要性程度。例如,将各个串并维度按照优先级降序排列,其对应的权值如下:优先级序列j串并维度权值ci1作案地点0.52作案工具0.33作案手段0.1………………实际上,计算两条案情数据相似度的方法有很多。在本申请实施例中,可选采用下式计算相似度:相似度=∑cj其中,cj表示匹配维度的预设优先级对应的权值。在步骤s154中,将相似度满足预设阈值的案情数据进行归并。在本实施例中,预先设置一个阈值,当两条案情数据的相似度计算结果满足大于或等于该阈值时,将这两条案情数据归并到一起,即完成了案件的串并。作为上述步骤s151至步骤s154的替代方案,本申请图7所示实施例包括下述步骤:步骤s1511,分别从待归并案情数据和所述已知案情数据中获取每个串并维度的维度值;步骤s1522,匹配两条案情数据的各个串并维度的维度值,确定两条案情数据同一串并维度的维度值的匹配度;在本申请实施例中,基于同义词的语义分析,确定两条案情数据同一串并维度的维度值的匹配度。语义分析是自然语言处理领域的一个概念,主要是对单词、词组、句子、句群所包含的意义和在语言使用过程中所产生的意义进行分析,它包含词与词之前的同义和蕴含关系。例如,“偷窃”的同义词有“扒窃”、“窃取”等。基于此,在步骤s1522中,可以预先建立公安领域专用的同/近义词词典,在对比两条案情数据同一串并维度的维度值,通过判断两个维度值是否在所述同/近义词词典中,来确定该两个维度值的匹配度。例如,如果该两个维度值属同义词,确定其匹配度为60%-90%(根据需要设定),如果该两个维度值属近义词,确定其匹配度为30%-60%(根据需要设定)。步骤s1533,如果两条案情数据同一串并维度的维度值的匹配度在预设的匹配区间内,确定所述串并维度为匹配维度;在步骤s1533中,预先设置一个匹配区间,如果两个维度值的匹配度计算结果落在该匹配区间内,该两个维度值对应的串并维度为匹配维度。步骤s1544,根据匹配维度的数量和匹配维度的预设优先级,确定所述两条案情数据的相似度;步骤s1555,将相似度满足预设阈值的案情数据进行归并。本实施例步骤s1511、步骤s1544及步骤s1555的具体实现方式可参见上述实施例,此处不再赘述。实施例二本实施例基于tf-idf算法的原理,从候选词集中获取第一动词集,或者说,本实施例是上述步骤s111的进一步细化步骤。参阅图8,在步骤s1131中,统计候选词集中每个动词的正向词频和反向词频;在本申请实施例中,根据每个动词在其自身所属的案情数据中的词频获得每个动词的正向词频,具体可以按照下式计算:其中,fi表示一案情数据中词序为i的分词出现的次数,n为该案情数据中的分词总数。以及,根据某动词所属的案件类别下的案情数据总条数和其中包含该动词的案情数据条数,获得该动词的反向词频,具体可按照下式计算:其中,d表示某动词所属的案件类别下的案情数据总条数,d(wordi)包含该动词的案情数据条数。示例性地,假设:盗窃类包含300条案情数据,“被盗”、“乘坐”、“发现”、“联系”的反向词频计算结果如下:包含该词的案情数据条数该词的反向词频联系1200.39乘坐200.15发现800.57被盗2301.3在步骤s1132中,根据所述的正向词频和反向词频,获取候选词集中每个动词相对于自身所属案件类别的第一分类权重;具体的,可按照下式计算第一分类权重:第一分类权重=正向词频×反向词频需要说明的是,由于候选词集中的一些动词,会同时出现在多个案情数据中,且需要根据各动词相对于其所属的案情数据的正向词频,来计算该词的第一分类权重,因此,计算过程中可能会出现同一动词对应多个第一分类权重的情况。针对这种情况,需在下述步骤s1133中做出去重处理。例如,“被盗”一词同时出现在案件(四)和案件(五)中,计算“被盗”一词相对于案件(四)及相对于案件(五)的第一分类权重结果如下:“被盗”出现次数词汇总数正向词频第一分类权重案情数据(五)51000.050.0238案情数据(六)2800.0250.0196…………………………在步骤s1133中,将所述第一分类权重满足第一预设条件的动词添加至第一动词集中;可以理解的是,某一动词的第一分类权重(或下述第二分类权重)表征该词对其所属的案件类别的类别区分能力。在本申请实施例中,预先设置一个用于判断各个动词的类别区分能力是否足够的条件,即第一预设条件(或第二预设条件)。可选的,第一预设条件可以为大于一设定的阈值,如果某一动词的第一分类权重满足该阈值,即为满足第一预设条件。另一可选的,在第一分类权重倒排表中位列前5(包括第5名)的动词,即为满足第一预设条件。需要说明的是,对上述倒排表中出现的重复的动词(同一动词对应至少两个第一分类权重)做去重处理,从而使形成的第一动词集中包含的动词互为不同。实施例三本实施例基于卡方检验的原理,从候选词集中获取第二动词集。具体的,在步骤s1134中,获取候选词集中每个动词相对于自身所属案件类别的第二分类权重,具体可按下式进行计算:其中,a表示与目标动词类别相同,且包含目标动词的案情数据量;b表示与目标动词类别不同,且包含目标动词的案情数据量;c表示与目标动词类别相同,且不包含目标动词的案情数据量;d表示与目标动词类别不同,且不包含目标动词的案情数据量。示例性地,计算目标动词“被盗”的第二分类权重的结果如下:目标动词abcd第二分类权重“被盗”230070300555945.9549在步骤s1135中,将所述第二分类权重满足第二预设条件的动词添加至第二动词集中;可选的,该第二预设条件可以为大于一设定的阈值,如果某一动词的第二分类权重满足该阈值,即为满足第二预设条件。另一可选的,在第二分类权重倒排表中位列前5(包括第5名)的动词,即为满足第二预设条件。由以上实施例可知,本申请提供的案情数据的归并方法,首先基于两种不同的算法,分别从已知案件类别的案情数据中获取第一动词集和第二动词集,并根据第一动词集和第二动词集生成与案件类别对应的特征动词集合,提高了获取特征动词的准确率;其次利用该特征动词集合训练获得案情数据分类模型,通过该案情数据分类模型确定待归并案情数据的命中类别,提高了模型对待归并案情数据的分类精度;最后根据命中类别预设的至少一个串并维度,将待归并案情数据和该命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并,提高了公安领域案件串并工作的精度和效率,同时提高了海量案情数据的利用率。根据上述案情数据的归并方法,本实施例提供一种案情数据的归并装置,参阅图9,该装置包括:获取单元u100,用于通过两种不同算法分别从已知案件类别的案情数据中,获取到第一动词集和第二动词集;生成单元u200,用于根据所述第一动词集和第二动词集,生成与案件类别对应的特征动词集合;训练单元u300,用于利用所述特征动词集合训练获得案情数据分类模型;分类单元u400,用于根据所述案情数据分类模型,获取待归并案情数据的命中类别;归并单元u500,根据所述命中类别预设的至少一个串并维度,将所述待归并案情数据和所述命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并。优选地,获取单元u100具体用于:对案情数据进行切词,并对切词得到的分词添加词性标签;根据词性标签,从所有所述分词中提取动词,以及,对提取到的动词进行去停用词处理,生成候选词集;从候选动词集中获取第一动词集和第二动词集。优选地,获取单元u100具体用于:统计候选词集中每个动词的正向词频和反向词频;根据所述正向词频和反向词频,获取候选词集中每个动词相对于自身所属案件类别的第一分类权重;将所述第一分类权重满足第一预设条件的动词添加至第一动词集中;其中,根据所述动词在其自身所属的案情数据中的词频获得正向词频,根据案情数据总量和包含所述动词的案情数据量获得反向词频。优选地,获取单元u100具体用于:获取候选词集中每个动词相对于自身所属案件类别的第二分类权重;以及,将所述第二分类权重满足第二预设条件的动词添加至第二动词集中;其中,通过以下公式获取所述第二分类权重:其中,a表示与目标动词类别相同,且包含目标动词的案情数据量;b表示与目标动词类别不同,且包含目标动词的案情数据量;c表示与目标动词类别相同,且不包含目标动词的案情数据量;d表示与目标动词类别不同,且不包含目标动词的案情数据量。优选地,生成单元u200具体用于:根据预设规则,确定第一动词集的候选特征动词和第二动词集的候选特征动词;选取第一动词集和第二动词集中相同的候选特征动词,形成与案件类别对应的特征动词集合。优选地,训练单元u300具体用于:将特征动词集合中的特征动词转换为特征向量;根据预设缩放规则,对所述特征向量进行缩放处理,得到训练输入文件;利用所述训练输入文件训练获得案情数据分类模型。优选地,分类单元u400具体用于:对待归并案情数据进行切词,并对切词得到的分词添加词性标签;根据词性标签,从所有所述分词中提取动词,以及,对提取到的动词进行去停用词处理,生成输入词集;将输入词集中的每个动词转换为输入词向量;根据所述预设缩放规则,对所述输入词向量进行缩放处理,得到输入序列;根据输入序列,从所述案情数据分类模型获取与输出序列对应的待归并案情数据的命中类别。优选地,归并单元u500具体用于:分别从待归并案情数据和所述已知案情数据中获取每个串并维度的维度值;匹配两条案情数据的各个串并维度的维度值,确定维度值一致的串并维度为匹配维度;根据匹配维度的数量和匹配维度的预设优先级,确定所述两条案情数据的相似度;将相似度满足预设阈值的案情数据进行归并。优选地,归并单元u500具体用于:分别从待归并案情数据和所述已知案情数据中获取每个串并维度的维度值;匹配两条案情数据的各个串并维度的维度值,确定两条案情数据同一串并维度的维度值的匹配度;如果两条案情数据同一串并维度的维度值的匹配度在预设的匹配区间内,确定所述串并维度为匹配维度;根据匹配维度的数量和匹配维度的预设优先级,确定所述两条案情数据的相似度;将相似度满足预设阈值的案情数据进行归并。由上述实施例可知,本申请提供的案情数据的归并装置,首先基于两种不同的算法,分别从已知案件类别的案情数据中获取第一动词集和第二动词集,并根据第一动词集和第二动词集生成与案件类别对应的特征动词集合,提高了获取特征动词的准确率;其次利用该特征动词集合训练获得案情数据分类模型,通过该案情数据分类模型确定待归并案情数据的命中类别,提高了模型对待归并案情数据的分类精度;最后根据命中类别预设的至少一个串并维度,将待归并案情数据和该命中类别中的已知案情数据进行串并,并根据串并结果进行数据归并,提高了公安领域案件串并工作的精度和效率,同时提高了海量案情数据的利用率。具体实现中,本发明还提供一种计算机存储介质,其中,该计算机存储介质可存储有程序,该程序执行时可包括本发明提供的案情数据的归并的各实施例中的部分或全部步骤。所述的存储介质可为磁碟、光盘、只读存储记忆体(英文:read-onlymemory,简称:rom)或随机存储记忆体(英文:randomaccessmemory,简称:ram)等。本领域的技术人员可以清楚地了解到本发明实施例中的技术可借助软件加必需的通用硬件平台的方式来实现。基于这样的理解,本发明实施例中的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例或者实施例的某些部分所述的方法。本说明书中各个实施例之间相同相似的部分互相参见即可。尤其,对于装置实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例中的说明即可。以上所述的本发明实施方式并不构成对本发明保护范围的限定。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1