一种基于深度信念网络的高压断路器故障诊断方法与流程
本发明属于高压断路器故障诊断方法技术领域,具体提出一种基于深度信念网络的高压断路器故障诊断方法。
背景技术
高压断路器在配电网系统中起着控制及保护的双重作用,故对高压断路器进行故障诊断意义重大。当前已经提出多种诊断方法,但仍存在一些问题和一定的局限性,如专家系统需要丰富的专家经验知识,而这时比较难以获取;神经网络易陷入局部最优;svm是二分类算法,其多分类算法,如一对一svm存在分类重叠和不可分类的情况;而elm虽然训练速度比较快,但是所训练模型诊断的稳定性却要差一些。此外,现有智能故障诊断方法大都对无标签样本的利用率较低,并且学习能力具有局限性,可扩展性比较差。而深度学习作为第三代神经网络,具有较强地从大量无标签样本中提取特征的能力;同时由于其多层的复杂结构及逐层训练的稳定性,能够对大数据量样本进行训练,顺应了大数据时代的潮流,具有广阔的应用前景。
鉴于此,本发明提出一种基于深度信念网络(deepbeliefnetwork,dbn)的高压断路器故障诊断算法,首先通过3层rbm(restrictedboltzmannmachine,rbm)自动提取输入变量之间的相关特性,并采用遗传算法进行模型调优,然后利用3层bp网络进行故障分类预测。该方法可利用工程现场大量无标签样本数据训练学习,提取不同变化趋势下信息特征和潜在的统计规律。
技术实现要素:
本发明提供了一种基于深度信念网络的高压断路器故障诊断方法,能够对大数据量样本进行训练,来实现高压断路器故障诊断功能。
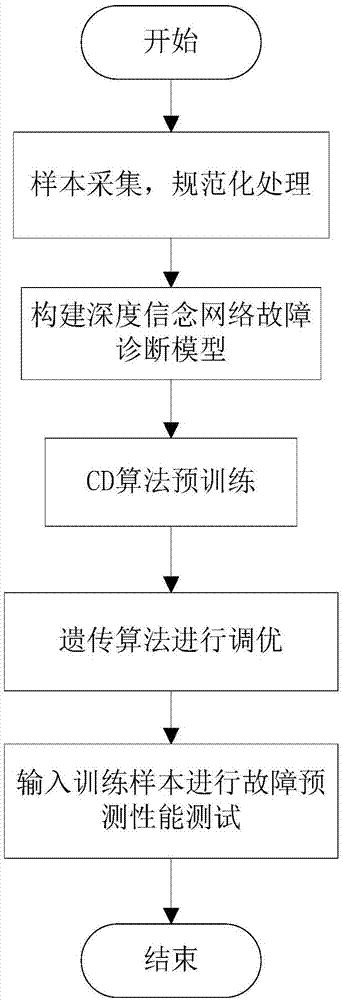
本发明所采用的技术方案是,一种基于深度信念网络的高压断路器故障诊断方法,具体按照以下步骤实施:
步骤1,选取实验所需的数据样本,将标准化处理后的样本数据按照特定比例分为测试样本和训练样本;
步骤2,构建高压断路器dbn深度信念网络故障诊断模型,
步骤3,采用逐层无监督贪婪学习算法(cd算法)对模型中rbm进行预训练,
步骤4,采用遗传算法对整个模型进行微调,即模型参数寻优,
步骤5,将步骤4训练获得的高压断路器故障诊断模型对步骤1中的测试集样本进行故障分类,得出故障分类结果,并统计模型诊断准确率。
本发明的特点还在于:
所述的步骤1具体为,
步骤1.1,本发明将大部分sf6断路器都会监测到的i1,i2,i3,t1,t2,t3,t4,t5,与sf6的压力、密度、微水含量、分解产物含量,通常为so2、h2s含量作为深度信念网络模型的输入。
步骤1.2,对步骤1.1中采集到的数据进行归一化处理,
步骤1.3,将标准化后的样本数据按照特定比例分为预训练集、调优集以及测试集;其中,预训练集为大量无标签样本构成,调优集和测试集为少量带有类标签的样本构成。
步骤2具体的步骤为:
步骤2.1,构建第一层rbm受限玻尔兹曼机单元,
步骤2.2,将第一层rbm1受限玻尔兹曼机单元的隐蔽层h1作为第二层rbm2受限玻尔兹曼机单元的可见层v2,构建第二层rbm2,
步骤2.3,以相同的方式在第二层的基础上搭建第三层rbm3受限玻尔兹曼机单元,自此三层rbm网络模型构建完成,
步骤2.4,构建dbn网络模型的分类层。本发明在rbm3顶部再添加一个三层bp神经网络模型,用于输出分类结果。将rbm3隐蔽层h3节点作为bp神经网络单元的可见层输入端,
步骤2.5,构造基于深度信念网络的高压断路器故障诊断模型,输出层由5个结点单元组成,每个单元代表一种故障类别,数据输入层为v1,由此输入采集到的sf6高压断路器样本数据,其模型输入为20维,即m=20。
所述的步骤2.1具体为,
rbm网络分为两层:即隐含层h和可见层v。隐含层由n个隐含的随机变量构成:h=(h1,h2,h3,hj,…,hn);可见层由m个随机变量构成v=(v1,v2,v3,vi,…,vm),用于表示观测的数据,可见层即是数据输入层,
rbm可视为基于能量的模型,其能量函数定义为
其中vi为可见单元的输入值;hj为隐单元的输出值,取值为1时表示该单元处于激活态,为0时表示处于未激活态;wij表示可见单元vi与隐单元hj之间的连接权重,ai表示可见单元vi的偏置,bj表示隐单元hj的偏置,n是隐含层节点数量,m为可见层节点数量,ai,bj,wij均为实数,θ=(a,b,w)构成rbm的模型参数。
(v,h)的联合概率分布pθ(v,h)可以表示为:
zθ为归一化常数,又叫做配分函数。
对于一层rbm所包含的m个可见单元和n个隐单元,给定隐单元与可见单元的条件概率为:
相反,隐单元的条件概率为:
根据式(1.1)(1.2)(1.3)可以推导出隐单元的激活概率为:
类似,可见层节点的第i个节点激活概率为:
式中σ()表示激活函数。
选用修正线性单元函数代替以上传统神经网络的激活函数,即
σ(z)=max(0,z)(1.8)。
所述的步骤3具体为:
步骤3.1,在训练网络中输入无标签样本,初始化可见层单元状态v1,隐含层单元数n,学习速率ε以及训练最大周期t,连接权值w以及偏置向量a和b均随机选取较小的数值;
步骤3.2,将可见单元向量映射到隐单元。对隐含层所有隐单元根据(1.7)计算,从条件分布p(hj|v1)抽取hj∈{0,1}。
步骤3.3,对可见层根据(1.6)式,从p(vi|h1)中抽取vi∈{0,1};
步骤3.4,根据公式(1.7),对隐含层所有隐单元进行计算;
步骤3.5,更新权重及其各偏置值:
w←w+ε[(p(h1=1|v1)v1t-p(h2=1|v2)v2t]
a←a+ε(v1-v2)
b←b+ε(p(h1=1|v1)-p(h2=1|v2))
重复步骤3.2-步骤3.5,达到迭代次数最大值或符合要求的重构误差时,停止该层rbm的训练。
在rbm1中,可见单元数为m=20,隐单元数目提前设定为n=50,训练周期t=50,学习速率ε=0.02。
步骤3.6训练完rbm1后,固定rbm1的参数,将rbm1训练完成的状态,即h1隐含层的状态,作为下一层rbm2的输入,重复上述训练过程,直至完成所有rbm层数的训练,则预训练结束。
所述的步骤4具体为,
步骤4.1,预训练之后,将整个网络等价为bp神经网络,此时,这个bp神经网络的初始权值和偏置已经在预训练中设置完成。设定ga参数:种群大小为m=100,进化终止代数为t=200,初始的交叉率为pc0=0.7,初始的变异率为pm0=0.001;
步骤4.2,经步骤3预训练后,将模型产生的所有参数权值和阈值向量,即wij,ai,bj以及bp分类层参数,作为遗传算法的染色体向量,并在其约束范围内,采用编码法随机生成初始种群;
步骤4.3,将步骤1中获得的调优集样本经归一化后,输入到bp神经网络的输入层,即模型rbm1的可见层,通过bp神经网络前向算法计算出没个种群向量下所对应的适应度函数值。然后,搜索最优种群,使如下适应值指标e最小:
式中:n为训练样本数;ygd是第g组样本的理想输出值;yg是第g组样本的实际输出值,e为m个种群中的适应值。
步骤4.4,若达到了期望的输出,则模型训练完成,并将所有模型参数更新到对应的数据库中。若未能达到了期望的输出,则将模型中现有的连接权和阈值提取出来,用ga对现有的连接权和阈值进行编码;
步骤4.5,进行一次ga运算产生新的群体,然后解码产生新的连接权和阈值来替换原来的值;
步骤4.6,重复步骤4.2步骤4.5,直到输出达到期望或者迭代次数达到为止,将最优染色体解码后替换模型参数,至此基于深度信念网络的高压断路器故障诊断模型训练完毕。
本发明的有益效果是:
1.高压断路器带标签故障样本往往稀缺,工程现场通过在线监测装置会获得大量无标签样本,dbn可以充分利用这些无标签样本进行故障特征学习,大大提高了数据样本的利用效率。
2.利用遗传算法对整个dbn模型进行调优,即保证了模型较高的判断准确率,又不易陷入局部最优。
3.dbn可以通过构建多层网络结构模型来实现对任何复杂函数的模拟情况,具有更强的学习能力,应用于高压断路器故障诊断,有望进一步提高故障诊断性能。
附图说明
图1是本发明方法的流程图;
图2是本发明方法中的rbm模型的结构图;
图3本发明方法中的dbn深度信念网络模型结构图。
具体实施方式
下面结合附图和具体实施方式对本发明进行详细说明。
本发明是一种基于深度信念网络的高压断路器故障诊断方法,如图1所示,具体按照以下步骤实施:
步骤1,选取实验所需的数据样本,将标准化处理后的样本数据按照特定比例分为测试样本和训练样本,具体步骤为,
步骤1.1,本发明将大部分sf6断路器都会监测到的i1,i2,i3,t1,t2,t3,t4,t5(为分、合闸时线圈上的电流波形提取数据),与sf6的压力、密度、微水含量、分解产物含量(通常为so2、h2s含量)作为本文提出的深度信念网络模型的输入。将分合闸操作电压过低、铁心运行有卡涩、操作机构有卡涩、辅助开关动作接触不良、机构正常的常发故障结果作为模型输出。
具体故障类型及编码如表1所示:
表1
步骤1.2,对步骤1.1中采集到的数据进行归一化处理。
步骤1.3,将标准化后的样本数据按照特定比例分为预训练集、调优集以及测试集;其中,预训练集为大量无标签样本构成,调优集和测试集为少量带有类标签的样本构成。
为避免样本集偏斜,同时又能保证得到够多的样本,可以选取多个工程现场记录的相同型号断路器的在线监测数据,这些数据为无标签数据,可以用作预训练样本。
步骤2,构建高压断路器dbn深度信念网络故障诊断模型,具体的步骤为:
步骤2.1,构建第一层rbm受限玻尔兹曼机单元。
rbm是一种二分结构的无向图模型,结构如图2所示。rbm网络分为两层:即隐含层h和可见层v。隐含层由n个隐含的随机变量构成:h=(h1,h2,h3,hj,…,hn);可见层由m个随机变量构成v=(v1,v2,v3,vi,…,vm),用于表示观测的数据,可见层即是数据输入层。网络连接只存在两层之间,同层内部变量之间无连接。
rbm可视为基于能量的模型,其能量函数定义为
其中vi为可见单元的输入值;hj为隐单元的输出值,取值为1时表示该单元处于激活态,为0时表示处于未激活态;wij表示可见单元vi与隐单元hj之间的连接权重,ai表示可见单元vi的偏置,bj表示隐单元hj的偏置,n是隐含层节点数量,m为可见层节点数量,ai,bj,wij均为实数,θ=(a,b,w)构成rbm的模型参数。(v,h)的联合概率分布pθ(v,h)可以表示为:
zθ为归一化常数,又叫做配分函数(partitionfunction)。
由于rbm是层间无连接的二值组成,所以其隐单元和可见单元是相互独立的单元,对于一层rbm所包含的m个可见单元和n个隐单元,给定隐单元与可见单元的条件概率为:
相反,隐单元的条件概率为:
根据式(1.1)(1.2)(1.3)可以推导出隐单元的激活概率为:
类似,可见层节点的第i个节点激活概率为:
式中σ()表示激活函数。常见的激活函数为sigmoid函数和tanh函数,表达见下式。
上述激活函数存在导数及饱和值缩放的特性,一旦进行递推式多层反向传播时,梯度误差会不断衰减,使得学习效率降低。另外,通过relu实现稀疏后的模型能够更好地挖掘相关特征,拟合训练数据。故本文选用修正线性单元函数(rectifiedlinearunits,,relu)函数代替以上传统神经网络的激活函数。
σ(z)=max(0,z)(1.8)
步骤2.2,将第一层rbm1受限玻尔兹曼机单元的隐蔽层h1作为第二层rbm2受限玻尔兹曼机单元的可见层v2,如图2所示。构建第二层rbm2。
步骤2.3,以相同的方式在第二层的基础上搭建第三层rbm3受限玻尔兹曼机单元,自此三层rbm网络模型构建完成。
步骤2.4,构建dbn网络模型的分类层。本发明在rbm3顶部再添加一个三层bp神经网络模型,用于输出分类结果。将rbm3隐蔽层h3节点作为bp神经网络单元的可见层输入端。
步骤2.5,构造如图3所示的基于深度信念网络的高压断路器故障诊断模型。输出层由5个结点单元组成,每个单元代表一种故障类别,数据输入层为v1,由此输入采集到的sf6高压断路器样本数据,其模型输入为20维(即m=20)。
步骤3,采用逐层无监督贪婪学习算法(cd算法)对模型中rbm进行预训练。
步骤3.1,在训练网络中输入无标签样本,初始化可见层单元状态v1,隐含层单元数n,学习速率ε以及训练最大周期t,连接权值w以及偏置向量a和b均随机选取较小的数值。
步骤3.2,将可见单元向量映射到隐单元。对隐含层所有隐单元根据(1.7)计算,从条件分布p(hj|v1)抽取hj∈{0,1}。
步骤3.3,对可见层根据(1.6)式,从p(vi|h1)中抽取vi∈{0,1};
步骤3.4,根据公式(1.7),对隐含层所有隐单元进行计算;
步骤3.5,更新权重及其各偏置值:
w←w+ε[(p(h1=1|v1)v1t-p(h2=1|v2)v2t]
a←a+ε(v1-v2)
b←b+ε(p(h1=1|v1)-p(h2=1|v2))
重复步骤3.2-步骤3.5,达到迭代次数最大值或符合要求的重构误差时,停止该层rbm的训练。
因为归一化因子z的存在(公式1.3),联合概率分布p求解较为复杂。故本发明提出采用对比散度(contrastivedivergence,cd)算法,在训练过程中,首先将显元向量映射到隐元,然后用隐元重构显元向量,再将显元向量映射到隐元,重复执行以上步骤t次,最终实现对rbm的快速训练学习。在rbm1中,可见单元数为m=20,隐单元数目提前设定为n=50,训练周期t=50,学习速率ε=0.02。
步骤3.6训练完rbm1后,固定rbm1的参数,将rbm1训练完成的状态(即h1隐含层的状态)作为下一层rbm2的输入,重复上述训练过程,直至完成所有rbm层数的训练,则预训练结束。这个过程中每层rbm的学习过程相互独立,大大简化了模型的训练过程。
步骤4,采用遗传算法对整个模型进行微调,即模型参数寻优。
步骤4.1,预训练之后,将整个网络等价为bp神经网络,此时,这个bp神经网络的初始权值和偏置已经在预训练中设置完成。设定ga参数:种群大小为m=100,进化终止代数为t=200,初始的交叉率为pc0=0.7,初始的变异率为pm0=0.001。
步骤4.2,经步骤3预训练后,将模型产生的所有参数权值和阈值向量(即wij,ai,bj以及bp分类层参数)作为遗传算法的染色体向量,并在其约束范围内,采用编码法随机生成初始种群。
步骤4.3,将步骤1中获得的调优集样本经归一化后,输入到bp神经网络的输入层,即模型rbm1的可见层,通过bp神经网络前向算法计算出没个种群向量下所对应的适应度函数值。然后,搜索最优种群,使如下适应值指标e最小:
式中:n为训练样本数;ygd是第g组样本的理想输出值;yg是第g组样本的实际输出值,e为m个种群中的适应值。
步骤4.4,若达到了期望的输出,则模型训练完成,并将所有模型参数更新到对应的数据库中。若未能达到了期望的输出,则将模型中现有的连接权和阈值提取出来,用ga对现有的连接权和阈值进行编码;
步骤4.5,进行一次ga运算产生新的群体,然后解码产生新的连接权和阈值来替换原来的值;
步骤4.6,重复步骤4.2步骤4.5,直到输出达到期望或者迭代次数达到为止,将最优染色体解码后替换模型参数,至此基于深度信念网络的高压断路器故障诊断模型训练完毕。
步骤5,将步骤4训练获得的高压断路器故障诊断模型对步骤1中的测试集样本进行故障分类,得出故障分类结果,并统计模型诊断准确率。
经过实验发现,网络结构层数和训练周期与预测准确率有一定关系。当rbm增加至3层时,预测正确率大幅提升,由3层增加至7层,准确率提升效果微弱。当网络结构确定时,随着训练周期增加,预测准确率呈上升趋势,且趋势逐渐变缓。综合模型预测效果及运算效率,本文确定rbm网络结构为3层,训练周期为250。
通过试验结果表明,该算法可以充分利用无标签数据,采用遗产算法,更容易找到全局最优解,可有效提升故障分类的准确率。
- 还没有人留言评论。精彩留言会获得点赞!