一种会话交互方法与流程
本发明涉及计算机技术领域,尤其涉及一种会话交互方法。
背景技术:
目前的计算机会话交互,多数涉及多轮会话,基于预定义的多轮会话规则,允许机器理解用户的意图并从会话流程中挑选合适的应答数据给予用户反馈,一直是人机交互领域努力的方向。
然而,目前存在的人机多轮会话方法技术方案均是基于用户问句与需求结构树中包含的标准需求进行映射,从而输出被命中的叶子节点的标准需求内容。这种方案存在着灵活性和准确性上的不足,无法支持灵活的多条会话流程间的跳转和调用,以及实时动态更新的语料模板,这使得某些场景下的交互难以实现,并且意图匹配模型的准确性较低。
例如,在实际保险行业的多轮会话应用场景中,由于保险本身知识有一定专业性,我们发现用户问题逻辑不清楚,问题比较模糊或者不知道怎么提问,并且保险投保网络复杂,专业术语晦涩难懂等问题,给理解用户自然语言,提供多轮会话交互带来了应用问题,并且对话中,不仅仅包含用户本人的用户画像还包含了用户相关其他用户的画像,比如客户、被推荐人、受益人等。
因此,如何根据用户的信息,例如意图等推荐相应的问题,以便实现更好地人机交互,一直是相关技术领域需要解决的技术问题之一。
技术实现要素:
为了克服现有技术的不足,本发明所解决的技术问题是提供一种能更准确引导客户咨询的会话交互方法。
为解决上述技术问题,本发明所采用的技术方案内容具体如下:
一种会话交互方法,所述方法包括以下步骤:
语句获取:获取用户语句;
第一意图判断:根据所述用户语句进行第一意图判断,所述第一意图判断用于判断所述用户语句是否包含常规问题;若是,则在数据库中调取与所述常规问题相对应的常规答案并输出;若否,则进行第二判断;
第二意图判断:所述第二判断用于判断所述用户语句中是否包含意图,若是,则在数据库中调取与所述意图相应会话流程并输出。
为解决上述技术问题,发明人在本技术方案中,通过两轮的意图判断识别用户语句中的意图,以分别作出相应的输出,从而能够准确识别用户意图,进而更准确地引导客户完成咨询和后续的服务。两次的意图判断分别用于判断用户语句是否直接含有数据库中已有的问题,以及用于判断用户语句是否隐含具体的意图,以防错失用户隐含有具体的意图类型,降低识别错误率,提高识别的全面性和准确率。
优选地,所述第二意图判断具体过程是:
判断所述用户语句中是否包含意图,若是,则在数据库中调取与所述意图相应会话流程并输出;若否,则根据所述用户语句进行意图推测;
若所述意图推测中所得数值大于阈值,则确认具有意图,进而在数据库中调取与所述意图相应会话流程并输出。
需要说明的是,在一些优选的实施方式中,所述第二意图判断的方式包括两个步骤,分别是判断所述用户语句中是否包含意图,以及意图推测;
判断所述用户语句中是否包含意图,指的是判断用户语句中是否直接包括意图类型,例如“车险”“投保”等,进而根据意图类型进行多轮会话的引导;而如果用户语句中不直接包含这些意图类型。发明人在本技术方案中还进一步地提供了意图推测这一步骤,以进一步判断用户语句中是否隐含有意图类型,例如“汽车能保障多久”,则有可能指向“车险”的意图类型。通过上述两步的判断,可以更为准确地识别用户意图,提高识别用户意图的准确率,进而降低用户语句识别的误差和不全面。
优选地,所述语句获取步骤中具体包括:对所获取的用户语句进行文本处理。
更优选地,所述文本处理的方式包括文本分词。
需要说明的是,在一些优选的实施方式中,对用户语句进行判断的预处理步骤包括对用户语句进行文本处理,能够更方便地进行处理和后续的识别判断,提高识别的效率和准确性。
优选地,所述用户语句包括实体信息;所述实体信息包括以下之中的一种或多种:
句向量信息,用于将词向量序列训练并编译;
通用实体信息,用于表示通用的信息;
行业实体信息,用于表示与行业相关的信息。
需要说明的是,作为一种优选实施方式,用户语句包括实体信息以进行区分和判断,实体信息包括句向量信息、通用实体信息和行业实体信息。所述句向量信息的例子可以是“我今天在上海出车祸了,请问汽车的异地车险理赔流程和本地一样吗?”;而通用实体信息,可以是“今天”“上海”等时间地点信息;而行业实体信息,可以是“汽车”“车险”等行业信息。
更优选地,所述用户语句还包括用户画像信息,用于表示用户个人及社交关系的信息。
需要说明的是,系统可以通过获取多次在用户语句中出现的用户画像信息,从而获取用户的社交关系,该方法可以参考现有技术中的人物关系图谱的构建方式,也可以参考如下文所述的发明人设计的具有创造性的获取方式。通过此步骤,系统可以进一步根据用户图像信息完善数据库的会话交互建设,从而进一步准确地判断用户意图,以及后续的信息推送。
进一步地,所述用户画像信息包括个人识别信息、个人属性信息和社交关系信息之中的一种或多种;
所述用户画像信息的获取方式具体包括:
对所述用户画像信息进行关联计算得到关联关系,获取用户语句中的句法依存关系和依存结构,并根据所述关联关系抽取所述个人识别信息、个人属性信息和社交关系信息进行三元组迭代学习,得到用户画像知识图谱。
需要说明的是,根据所述关联关系抽取所述个人识别信息、个人属性信息和社交关系信息进行三元组迭代学习,由于数据结构存在强网络关系,需要获取或检索其他相关节点属性,能够更准确地得到用户图像知识图谱,即上文所述的关系图谱。
在一些实施方式中,对所述用户画像信息进行关联计算的具体方式是:通过pos-cbow方法,并通过改进的w2v进行关联计算。
需要说明的是,在一些更具体的实施方式中,通过pos-cbow方法,并通过改进的w2v进行关联计算,由于综合了实体属性和实体分布,从而能够达到提取实体关联的技术效果。
进一步地,所述第一意图判断的具体方法包括:
所述数据库设有faq数据集;将所述句向量信息、通用实体信息和行业实体信息的拼接矩阵,在所述faq数据集进行匹配,若所述faq数据集中存在相应的常规问题,则输出与所述常规问题相对于的常规答案。
需要说明的是,faq数据集是指包括常规问题和以及与所述常规问题相对于的常规答案的数据库。常规问题例如是“车险一年多少钱?”,而相对应的常规答案可能是“4000元人民币”之类。
而与所述faq数据集进行匹配的方式是将用户语句中所得的句向量信息、通用实体信息和行业实体信息的拼接矩阵,然后在faq数据集进行匹配,能够准确地实现数据库的匹配,而且提高匹配效率。
在一些实施方式中,在所述faq数据集进行匹配时,还包括以下步骤:
将所述拼接矩阵中的所述通用实体信息和行业实体信息替换成最上层实体的编码,再与所述faq数据集进行匹配。
需要说明的是,在一些优选的实施方式中,将先通用实体信息和行业实体信息替换成最上层实体的编码,可以更全面地匹配数据集的内容,如将“私家车”替换成“汽车”,则为替代成上层实体的编码,这样可以进一步准确地识别匹配问题和答案的内容。
进一步地,所述第二意图判断的具体方法包括:
根据所述实体信息和用户图像信息拼接矩阵,通过cnn模型进行文本分类获得意图。
在更具体的实施方式中,上述过程的具体方式是:在用户会话的某个独立句子s∈rnk中,由第n个词k维向量表示,将实体和用户画像对应信息编码到字典中,xi∈rk通过分词和去停用词后word2vec得到词向量,
对文本n-gram形式挖掘特征信息,通过cnn模型,将文本卷积核定义w∈rlk(其中,卷积长度为l),对于文本在每个窗口滑动的特征为fi=f(wixi:i+l-1+b),得到特征图为f=[f1,f2,...fn-l+1]。
在池化层中,对特征向量保存最大一维作为特征信息,从n个卷积获取n维向量,映射成固定长度的全局特征向量。
在输出层中,建立一个全链接层,映射到h维意图空间,通过有监督学习优化二元交叉熵损失函数,通过softmax输出的概率映射到h维意图空间的意图-置信度矩阵中。输出结果为意图和置信度,实体集的列表,存储在记忆中。
在一些实施方式中,所述意图的类型包括投保意图、核保意图、理赔意图、续保意图和退保意图之中的一种或多种。
作为优选,在所述第二意图判断步骤中,在数据库中调取与所述意图相应会话流程并输出的具体方式包括:
判断所述意图的类型;
根据所述意图的类型调取所需要的信息并获取所述信息;
根据所述信息输出相应的方案。
作为优选,判断所述意图的类型的具体方式是进行置信度计算,当所述置信度大于某一意图类型的设定值时,则判断属于该意图类型。
需要说明的是,通过置信度计算可以更为准确地识别用户的意图类型,具体地,置信度计算的方法是全连接层向量z的softmax层输出
通过上述置信度计算的判断,可以更准确地得出意图类型的判断结果。
作为优选,获取所述信息的方式是从所述实体信息、用户图像信息之中的一种或两种进行获取;和/或向用户进行询问所述信息并获取。
需要说明的是,在所述第二意图判断步骤中,在判断得到意图类型后,需要根据意图类型进行方案输出,而在此过程中,可能需要综合用户的多种信息,例如年龄、身份证等,而这里有些信息是可以从实体信息、用户图像信息之中的一种或两种进行获取,可以提高信息获取的效率;另外也可以向用户进行询问所述信息并获取,提高信息获取的准确率,从而进一步提高匹配输出的整体准确度。
作为优选,所述信息包括性别、年龄、车牌号、地区、家庭人数之中的一种或多种。
作为进一步优选,所述方案是险种推荐方案。
优选地,所述意图推测的数值的计算方法具体是:
首先通过对问句文本分词和词嵌入训练词向量,然后转换成句向量,和实体信息和用户画像矩阵拼接,通过lstm模型进行训练提取特征,具体过程是当前输入xt进入新的记忆块记忆,通过激活函数映射到输入门it=σ(wtxt+wtht-1+bt),遗忘门ft=σ(wfxt+wfht-1+bf)控制了信息量,并更新记忆块qt=tanh(wqxt+wqht-1+bq),输出信息或会话卡片ot=σ(woxt+woht-1+bo),并且确定了把什么信息保存在新的记忆块中,
与现有技术相比,本发明的有益效果在于:
1、本发明的会话交互方法,通过两轮的意图判断识别用户语句中的意图,以分别作出相应的输出,从而能够准确识别用户意图,进而更准确地引导客户完成咨询和后续的服务;
2、本发明的会话交互方法,第二意图判断的方式包括两个步骤,分别是判断所述用户语句中是否包含意图,以及意图推测,通过上述两步的判断,可以更为准确地识别用户意图,提高识别用户意图的准确率,进而降低用户语句识别的误差和不全面;
3、本发明的会话交互方法,对用户语句进行判断的预处理步骤包括对用户语句进行文本处理,能够更方便地进行处理和后续的识别判断,提高识别的效率和准确性;
4、本发明的会话交互方法,在一些优选的实施方式中,将先通用实体信息和行业实体信息替换成最上层实体的编码,这样可以进一步准确地识别匹配问题和答案的内容;
5、本发明的会话交互方法,在判断得到意图类型后,可以从实体信息、用户图像信息之中的一种或两种进行获取相关信息,可以提高信息获取的效率;另外也可以向用户进行询问所述信息并获取,提高信息获取的准确率,从而进一步提高匹配输出的整体准确度。
6、本发明的会话交互方法,实现对用户对话中上下文所有信息的完整提取,通过实体提取模型和关系抽取,从句子中提取通用实体、行业实体和用户画像,通过深度学习模型,学习出用户的意图和可能的意图,具有较高的准确度。
上述说明仅是本发明技术方案的概述,为了能够更清楚了解本发明的技术手段,而可依照说明书的内容予以实施,并且为了让本发明的上述和其他目的、特征和优点能够更明显易懂,以下特举较佳实施例,并配合附图,详细说明如下。
附图说明
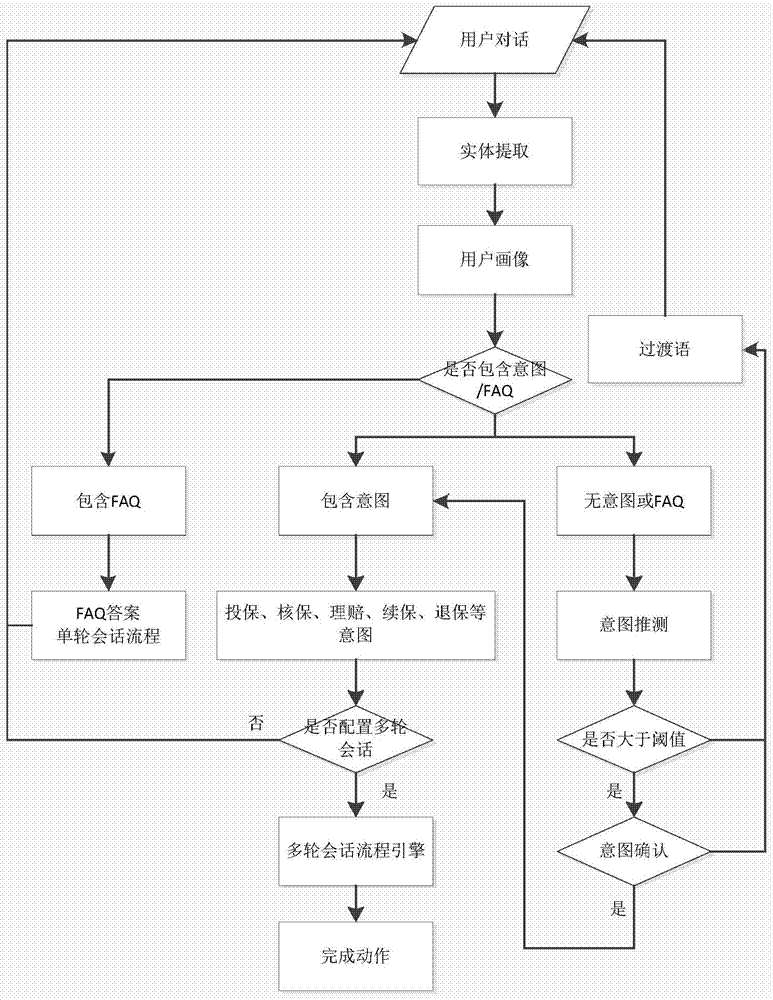
图1为本发明会话交互方法的其中一种实施方式的流程示意图;
图2为本发明会话交互方法的用户知识图谱的一种优选实施方式的示意图;
图3为本发明会话交互方法的第二意图判断的一种优选实施方式的流程示意图;
图4为本发明中调取与所述意图相应会话流程并输出步骤的一种优选实施方式的步骤关系示意图;
图5为图4步骤中的一种优选的流程示意图。
具体实施方式
为更进一步阐述本发明为达成预定发明目的所采取的技术手段及功效,以下结合附图及较佳实施例,对依据本发明的具体实施方式、结构、特征及其功效,详细说明如下:
本发明提供的一种会话交互方法,所述方法包括以下步骤:
语句获取:获取用户语句;
第一意图判断:根据所述用户语句进行第一意图判断,所述第一意图判断用于判断所述用户语句是否包含常规问题;若是,则在数据库中调取与所述常规问题相对应的常规答案并输出;若否,则进行第二判断;
第二意图判断:所述第二判断用于判断所述用户语句中是否包含意图,若是,则在数据库中调取与所述意图相应会话流程并输出。
以上是本发明的其中一种基础实施方式。在本技术方案中,通过两轮的意图判断识别用户语句中的意图,以分别作出相应的输出,从而能够准确识别用户意图,进而更准确地引导客户完成咨询和后续的服务。两次的意图判断分别用于判断用户语句是否直接含有数据库中已有的问题,以及用于判断用户语句是否隐含具体的意图,以防错失用户隐含有具体的意图类型,降低识别错误率,提高识别的全面性和准确率。
结合上述基础实施方式,在第二个方面中,所述第二意图判断具体过程是:
判断所述用户语句中是否包含意图,若是,则在数据库中调取与所述意图相应会话流程并输出;若否,则根据所述用户语句进行意图推测;
若所述意图推测中所得数值大于阈值,则确认具有意图,进而在数据库中调取与所述意图相应会话流程并输出。
在此方面中,所述第二意图判断的方式包括两个步骤,分别是判断所述用户语句中是否包含意图,以及意图推测;判断所述用户语句中是否包含意图,指的是判断用户语句中是否直接包括意图类型,例如“车险”“投保”等,进而根据意图类型进行多轮会话的引导;而如果用户语句中不直接包含这些意图类型。发明人在本技术方案中还进一步地提供了意图推测这一步骤,以进一步判断用户语句中是否隐含有意图类型,例如“汽车能保障多久”,则有可能指向“车险”的意图类型。通过上述两步的判断,可以更为准确地识别用户意图,提高识别用户意图的准确率,进而降低用户语句识别的误差和不全面。
如图1所示是结合上述各个方面的其中一种优选的会话交互方法的流程示意图,具体操作方式已在上述各个方面中具体指出,在此不再赘述。
结合上述基础实施方式,在第三个方面中,所述语句获取步骤中具体包括:对所获取的用户语句进行文本处理。在更进一步具体的实施方式中,所述文本处理的方式包括文本分词。对用户语句进行判断的预处理步骤包括对用户语句进行文本处理,能够更方便地进行处理和后续的识别判断,提高识别的效率和准确性。
结合上述基础实施方式,在第四个方面中,所述用户语句包括实体信息;所述实体信息包括以下之中的一种或多种:
句向量信息,用于将词向量序列训练并编译;
通用实体信息,用于表示通用的信息;
行业实体信息,用于表示与行业相关的信息。
用户语句包括实体信息以进行区分和判断,实体信息包括句向量信息、通用实体信息和行业实体信息。所述词向量的获取在文本分词步骤中完成。所述句向量信息的例子可以是“我今天在上海出车祸了,请问汽车异地车险理赔流程一样吗?”;而通用实体信息,可以是“今天”“上海”等时间地点信息;而行业实体信息,可以是“汽车”“车险”等行业信息。
结合上述基础实施方式,在第五个方面中,所述用户语句还包括用户画像信息,用于表示用户个人及社交关系的信息。系统可以通过获取多次在用户语句中出现的用户画像信息,从而获取用户的社交关系,该方法可以参考现有技术中的人物关系图谱的构建方式,也可以参考如下文所述的发明人设计的具有创造性的获取方式。通过此步骤,系统可以进一步根据用户图像信息完善数据库的会话交互建设,从而进一步准确地判断用户意图,以及后续的信息推送。在一些更具体的实施方式中,所述用户画像信息包括个人识别信息、个人属性信息和社交关系信息之中的一种或多种。
结合上述基础实施方式,在第六个方面中,所述用户画像信息的获取方式具体包括:对所述用户画像信息进行关联计算得到关联关系,获取用户语句中的句法依存关系和依存结构,并根据所述关联关系抽取所述个人识别信息、个人属性信息和社交关系信息进行三元组迭代学习,得到用户画像知识图谱。根据所述关联关系抽取所述个人识别信息、个人属性信息和社交关系信息进行三元组迭代学习,由于数据结构存在强网络关系,需要获取或检索其他相关节点属性,能够更准确地得到用户图像知识图谱,即上文所述的关系图谱。在更具体的一些实施方式中,对所述用户画像信息进行关联计算的具体方式是:通过pos-cbow方法,并通过改进的w2v进行关联计算。通过pos-cbow方法,并通过改进的w2v进行关联计算,由于综合了实体属性和实体分布,从而能够达到提取实体关联的技术效果。
如图2所示是用户图像构成的用户画像知识图谱的其中一种优选实施方式的示意图,比如说通过获取用户语句“我爸爸今年66岁了,去年膀胱癌痊愈了,请问可以买孝欣老年人防癌险吗?”首先进行实体提取,提取通用实体、行业实体、用户画像知识图谱并进行矩阵化编码。具体可先做文本分词,比如:“我|爸爸|今年|66岁|了,去年|膀胱癌|痊愈|了|,请问|可以|买|孝欣老年人防癌险|吗?”。其次通过pos-cbow方法通过改进的w2v进行关联计算,获取句法依存关系和依存结构,通过关系抽取实体、属性、关系,通过三元组迭代学习更多模板,比如上句中得到我和妈妈,年龄是6岁,疾病膀胱癌,投保偏好孝欣老年人防癌险。通过保险领域语料训练本体关联关系,获得图2中所述的用户画像知识图谱。在互联网保险应用场景中,可能存在代理人为他的客户投保,用户给朋友推荐好的保险产品,客户为自己父母小孩投保的等问题,涉及到关联本体,因此需要通过上下文,建立用户画像知识图谱,解决了会话中的主体和实体比较多的关系复杂的问题。此方法的通过知识图谱构建用户画像,解决了比如用户查询“我客户的保单”或者“我推荐了哪些朋友”或者“我家庭的保险覆盖了哪些保障范围”等情景。
结合上述基础实施方式,在第七个方面中,所述第一意图判断的具体方法包括:所述数据库设有faq数据集;将所述句向量信息、通用实体信息和行业实体信息的拼接矩阵,在所述faq数据集进行匹配,若所述faq数据集中存在相应的常规问题,则输出与所述常规问题相对于的常规答案。faq数据集是指包括常规问题和以及与所述常规问题相对于的常规答案的数据库。常规问题例如是“车险一年多少钱?”,而相对应的常规答案可能是“4000元人民币”之类。而与所述faq数据集进行匹配的方式是将用户语句中所得的句向量信息、通用实体信息和行业实体信息的拼接矩阵,然后在faq数据集进行匹配,能够准确地实现数据库的匹配,而且提高匹配效率。在一些实施方式中,在所述faq数据集进行匹配时,还包括以下步骤:将所述拼接矩阵中的所述通用实体信息和行业实体信息替换成最上层实体的编码,再与所述faq数据集进行匹配。在一些优选的实施方式中,将先通用实体信息和行业实体信息替换成最上层实体的编码,可以更全面地匹配数据集的内容,如将“私家车”替换成“汽车”,则为替代成上层实体的编码,这样可以进一步准确地识别匹配问题和答案的内容。
在一些具体的实施例中,例如在faq识别中,由输入由句向量、通用实体、行业实体拼接矩阵,在faq中对用户的问题和qa中的问题匹配,句中实体替换为最上层实体的编码,比如将糖尿病替换成疾病,宝马320li替换成汽车,最后通过相似度对比模型,寻找大于某个相似度阈值的qa问题,见图5。比如,用户问“请问宝马320li可以投保吗?”和qa中的“汽车可以投保吗”模板相似度最高,通过qa条件设置不同答案。比如“众安车险可以投保200万以下的车辆”。
结合上述基础实施方式,在第八个方面中,所述第二意图判断的具体方法包括:
根据所述实体信息和用户图像信息拼接矩阵,通过cnn模型进行文本分类获得意图,图3是表示该过程的其中一种实施方式的流程示意图。
具体步骤为:
在用户会话的某个独立句子s∈rnk中,由第n个词k维向量表示,将实体和用户画像对应信息编码到字典中,xi∈rk通过分词和去停用词后word2vec得到词向量,
对文本n-gram形式挖掘特征信息,通过cnn模型,将文本卷积核定义w∈rlk(其中,卷积长度为l),对于文本在每个窗口滑动的特征为fi=f(wixi:i+l-1+b),得到特征图为f=[f1,f2,...fn-l+1]。
在池化层中,对特征向量保存最大一维作为特征信息,从n个卷积获取n维向量,映射成固定长度的全局特征向量。
在输出层中,建立一个全链接层,映射到h维意图空间,通过有监督学习优化二元交叉熵损失函数,通过softmax输出的概率映射到h维意图空间的意图-置信度矩阵中。输出结果为意图和置信度,实体集的列表,存储在记忆中。
在一些实施方式中,所述意图的类型包括投保意图、核保意图、理赔意图、续保意图和退保意图之中的一种或多种。
作为优选,在所述第二意图判断步骤中,在数据库中调取与所述意图相应会话流程并输出的具体方式包括:
判断所述意图的类型;
根据所述意图的类型调取所需要的信息并获取所述信息;
根据所述信息输出相应的方案。
作为优选,判断所述意图的类型的具体方式是进行置信度计算,当所述置信度大于某一意图类型的设定值时,则判断属于该意图类型。通过置信度计算可以更为准确地识别用户的意图类型,具体地,置信度计算的方法是全连接层向量z的softmax层输出
通过上述置信度计算的判断,可以更准确地得出意图类型的判断结果。
在一些其他优选的实施方式之中,获取所述信息的方式是从所述实体信息、用户图像信息之中的一种或两种进行获取;和/或向用户进行询问所述信息并获取。在所述第二意图判断步骤中,在判断得到意图类型后,需要根据意图类型进行方案输出,而在此过程中,可能需要综合用户的多种信息,例如年龄、身份证等,而这里有些信息是可以从实体信息、用户图像信息之中的一种或两种进行获取,可以提高信息获取的效率;另外也可以向用户进行询问所述信息并获取,提高信息获取的准确率,从而进一步提高匹配输出的整体准确度。作为更进一步地优选方案,所述信息包括性别、年龄、车牌号、地区、家庭人数之中的一种或多种。在其他的一些优选方案中,所述方案是险种推荐方案。
以下结合一种具体的实施方式以说明上述获取和判断过程:
会话流程规则包含了触发器、节点、条件、和动作。
定义触发条件规则:定义意图名称和置信度的规则,比如intent=核保andconfidence_degree>0.8。
定义节点规则:定义节点名称,每个节点包括了条件,动作和记忆:
定义条件:其中,条件表达式定义条件if...elseif/elseif/..等逻辑表达式,实体映射和对齐定义了实体与用户画像的映射,以及实体的对齐。比如条件定义为age<55,而用户画像中通过“我爸52年生的获取“我爸”年龄“52年生”的属性,将条件定义中的age和“我爸”的“年龄”映射,并将“52年生”对齐为66岁,从用户画像中,判断条件不满足age<55。
对于终端用户输入的问句会做以下两步处理:
第一步,用户的问句由意图识别模型进行处理,得出置信度最高的意图与对应实体,例如:用户输入问句“50岁的男性能否投保?”。
第二步,将用户输入中与该意图所对应实体相关的内容,与实体之间做一层映射,作为该会话流程的部分上下文信息,存放于适合高频访问的存储介质中,作为后续步骤中规则匹配的数据源之一。
定义动作:定义了3种类型,卡片,包括了选择卡片、文本卡片、图文卡片、图文列表、图片等卡片,通过卡片和用户交互,获取信息,并进行信息映射,目的是用于收集结构化和非结构化数据,外部数据,以及响应并反馈结果;跳转,可以跳转到其他节点或url或人工等;api返回值,通过api返回给服务器收集到的用户画像信息,获取请求,比如保险推荐等。
具体例子请见图4。比如,触发器触发了多轮会话,节点1判断有没有身份证,如果通过api获取,读取用户画像。节点2,条件判断如果没有获取身份证,则给卡片选择性别,并跳转到节点3,给卡片选择年龄;如果获取了身份证,直接跳转到节点4。节点4需要输入车牌,节点5判断地区是否在指定地区里,读取用户画像并跳转到节点6,否则,给出选择卡片,选择地区。节点6选择家庭人数,节点7车险推荐,若调用推荐api失败,则返回错误信息。
从上面的例子看,多轮会话可以通过节点的逻辑判断,完成各个节点的跳转,并且可以支持实体和用户画像的映射和实体的对齐,支持选择卡片、文本卡片、图文卡片、图文列表、图片等丰富的交互卡片。
对于上述步骤,下面详细说明下图执行模块:
根据获取的意图在预置的会话流程中做匹配,查询相应的会话流程配置。一个会话流程配置由多个交互步骤节点构成,其中至少包含一个起始节点和一个结束节点。
每个节点由节点主体、一个触发器、多组条件行为对及内存网络组成。
节点主体为一个节点需要采集的内容的key值,节点主体与用户针对该主体的输入会以键值对的形式追加到会话流程上下文中,存储到存储介质中。上下文的结构见图5。
触发器决定了是否会执行到该节点。当该触发器的条件被满足时,机器程序会将该节点的预置内容推送给用户,交由用户继续输入,完成该步用户交互。触发器由触发器主体和触发条件构成,触发器主体有三种类型,分别是意图类型(以@符号标识)、实体类型(以#符号标识)和数据类型(以_符号标识)。其中数据类型由用户预先定义并存储于内存介质中,预先分配内存中特定的命名空间memory,用户定义的数据x会以memory.x为key值存储于内存中,该memory.x键值对的生命周期等同于整个会话流程,应用范围为机器端到用户端。
结合上述实施方式,在第九个方面,所述意图推测的数值的计算方法具体是:
首先通过对问句文本分词和词嵌入训练词向量,然后转换成句向量,和实体信息和用户画像矩阵拼接,通过lstm模型进行训练提取特征,具体过程是当前输入xt进入新的记忆块记忆,通过激活函数映射到输入门it=σ(wtxt+wtht-1+bt),遗忘门ft=σ(wfxt+wfht-1+bf)控制了信息量,并更新记忆块qt=tanh(wqxt+wqht-1+bq),输出信息或会话卡片ot=σ(woxt+woht-1+bo),并且确定了把什么信息保存在新的记忆块中,
上述实施方式仅为本发明的优选实施方式,不能以此来限定本发明保护的范围,本领域的技术人员在本发明的基础上所做的任何非实质性的变化及替换均属于本发明所要求保护的范围。
- 还没有人留言评论。精彩留言会获得点赞!