神经网络机器翻译模型的训练方法及装置与流程
本发明涉及机器翻译技术领域,更具体地,涉及神经网络机器翻译模型的训练方法及装置。
背景技术:
为了实现自动的机器翻译,目前常用的技术包括基于神经网络的方法和基于统计的方法,前者为nmt(neuralmachinetranslation,神经网络机器翻译),后者为smt(statisticalmachientranslation,统计机器翻译)。为此,需要收集大规模高质量的平行语料以获得可靠的翻译模型。然而,高质量的平行语料常常只存在于少量的几种语言之间,并且往往受限于某些特定的领域,比如政府文件、新闻等。除了这些特定的领域之外,有些语言本身就资源缺乏,难以从互联网上找到或者获取可用的平行语料。目前nmt已经超越传统的smt,但是主要存在的缺点是为了训练翻译模型需要高度依靠大量的平行语料。
随着互联网的兴起,互联网为nmt带来了新的机遇。互联网上大量的语料,使得覆盖多种语言、领域的平行语料获取成为可能。但是从网上获取的语料中,资源匮乏的语料很少,比如比较容易得到的是新闻的单语语料,可是缺乏资源的几种语言中,获取政府、电影、贸易、教育、体育以及文艺等某一种单个领域很难,特别是医学等方面的语料更难。如果训练的语料和开发集(对用训练语料已训练完的模型进行调优)的语料属于同一个领域,同时测试语料也属于同一个领域,那么对该领域内语料的翻译结果会非常好,但对领域外的语料翻译结果会很差。
在高资源语言上所做的神经网络机器翻译研究虽然取得了卓越的成绩,但是在资源匮乏的语言中,语言本身就很难获取,更不用说是单个特定领域了。其导致的问题是数据稀疏(datasparsity),如果翻译模型没有得到充分训练,则就算利用大规模语言对上的目前最受欢迎的或者能够有效提高神经网络机器翻译的方法,也非常难于用到低资源语言机器翻译上。所以说低资源机器翻译问题是特别需要尽快解决的问题之一。
近年来在nmt中提出了不少的解决低资源语言机器翻译的方法,以及在nmt中迁移学习得到了深入的研究。所有方法可以归纳为如下五种:(1)迁移学习方法,利用了大规模的预先训练好的机器翻译模型来指导小规模语料上的翻译模型。(2)词根替换法,采用了高资源语言对和低资源语言对上找到具有同样词根的单词,然后将低资源语言中的本单词与高资源语言中对应的单词替换。(3)词表共享法,主要是受到领域自适应的灵感启发,在此基础上提出的方法,核心思想是把低资源语言和高资源语言的语言对混合起来,然后生成同一个词表,再去训练低资源语言的方法。(4)单词折叠方法,本方法跟第二个方法比较相似,词根替换法找到具有相同词根的单词相互替换,不过单词折叠是按词级别找到完全相同的单词去替换。(5)半监督方法,充分利用单语语料来改善机器翻译性能。(6)数据增益的方法,通过从源语言端和目标语言端中替换,删除,交换,添加一些单词来生成新的语料的方法,该方法也有一定的帮助,不过效果并不明显。
比如南加州大学的研究人员利用已存在的模型迁移到一个新的模型上。该方法只用了一个高资源语言对上训练出来的一个大模型来初始化低资源语言对上待训练的模型参数并微调参数,实现用随机选好的大规模语料上训练好的大模型来引导在小规模语料上待训的模型。这种方法关心的是低资源语言对上训练出来的模型如何能一次性充分利用那些跟孩子模型高度相似,更加接近的多个高资源语言对上训练出来的父模型。该方法单纯地把迁移学习用到低资源语言nmt,其缺点就是无法一次性的让孩子模型学到多个跟自己直接相关的多个父模型的参数以及多样的知识。
在上述方法的基础上,也有其他研究人员做出了很少的改动,比如直接在词级别上做到了迁移,或者先在特别接近而且共享非常多个通用单词的两种语言(属于同一个语系、语族以及语言分支的两种语言)上做了词根替换,然后再从高资源做了两次迁移。虽然这个方法也有效果,但还无法用到多个高资源语言在语言学,包括句法、语法以及语言特性上的更多的知识。因此这种方法也有两个大显著缺点:第一,对于没有特别接近语言,别说找到共享的单词,即就使连找到词根都很难。第二,用的是不同规模大小的同种语言,虽然做了两次的迁移,但是还是学不到来自于多个高度接近的父模型的参数和知识。
另外,google也提出了基于零样本学习(zero-shotlearning)的多语种神经网络机器翻译技术。方法是把所有大规模语料都合并起来形成更大的混合语料,包括低资源语言对也通过“过采样”(oversampling)的方式加入到大规模语料中,然后生成出来大的词表再在低资源语言上做翻译。但模型最后还是无法得到从高度接近的高资源语言对上训练出来的模型的帮助。而且google的方法也没有做到字符级别的统一化或者词级别的统一化,导致在高资源父模型和低资源孩子模型之间共享单词较少。
技术实现要素:
本发明提供一种克服上述问题或者至少部分地解决上述问题的神经网络机器翻译模型的训练方法及装置。
根据本发明的一个方面,提供一种神经网络机器翻译模型的训练方法,包括:
获取多种高资源语言对和低资源语言对;所述多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且所述高资源语言对中的目标语言和低资源语言对中的目标语言相同;
对所述高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作;对于任意一种高资源语言对的源语言,满足操作后的该源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值;
将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;所述预设顺序与各高资源语言对的规模正相关;
根据最后一个训练好的父模型训练所述孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
根据本发明的第二个方面,提供一种神经网络机器翻译模型的训练装置,其特征在于,包括:
语言对获取模块,用于获取多种高资源语言对和低资源语言对;所述多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且所述高资源语言对中的目标语言和低资源语言对中的目标语言相同;
拼写统一化模块,用于对所述高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作;对于任意一种高资源语言对的源语言,满足操作后的该源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值;
父模型训练模块,用于将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;所述预设顺序与各高资源语言对的规模正相关;
孩子模型训练模块,用于根据最后一个训练好的父模型训练所述孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
根据本发明的第三个方面,还提供一种电子设备,包括:
至少一个处理器;以及
与所述处理器通信连接的至少一个存储器,其中:
所述存储器存储有可被所述处理器执行的程序指令,所述处理器调用所述程序指令能够执行第一方面的各种可能的实现方式中任一种可能的实现方式所提供的训练方法。
根据本发明的第四个方面,还提供一种非暂态计算机可读存储介质,所述非暂态计算机可读存储介质存储计算机指令,所述计算机指令使所述计算机执行第一方面的各种可能的实现方式中任一种可能的实现方式所提供的训练方法。
本发明提出的神经网络机器翻译模型的训练方法及装置,神经网络机器翻译模型的训练方法,首先通过选择不同语系、不同语族以及不同语言分支的多种高资源语言对,克服了现有技术中通常采用不同规模大小的同种语言进行迁移学习带来的翻译领域窄的问题,并且所选择的是与低资源语言对存在一定共享单词的比例的高资源语言对,克服了google公司所采用的方法存在的需要占用极高的资源以及因为高资源语言对本身不具有一定共享单词的比例,而导致的存在干扰、准确性较低的问题,进一步地,本发明实施例对高资源语言对和低资源语言对的源语言进行拼写统一化操作,一方面对选择高共享单词的比例的高资源语言对有帮助,另一方面使得高资源语言和低资源语言之间增加了共享单词(sharedwords)的个数;通过按照父模型规模大小的顺序父模型按照迁移学习的方法进行训练,并且将前一个父模型的源语言和目标语言的信息迁移至下一个父模型中,最终保证孩子模型能够一次性继承所有父模型的源语言和目标语言的信息,克服了如果固化父模型目标端将导致孩子模型无法用到自身目标端的词向量的弊端,同时使得孩子模型充分利用跟自己共享单词的比例高的高资源语言对,而能够高效准确地完成机器翻译所面临的资源匮乏问题,具备良好的适用范围以及可扩展性。
附图说明
图1为根据本发明实施例的神经网络机器翻译模型的训练方法的流程示意图;
图2为根据本发明实施例的神经网络机器翻译模型的训练装置的功能框图;
图3为根据本发明实施例的电子设备的框图。
具体实施方式
下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。以下实施例用于说明本发明,但不用来限制本发明的范围。
为了克服现有技术的上述问题,本发明实施例的发明构思是:通过充分利用多语种高资源语言来引导低资源语言,即鼓励低资源语言模型完全地运用与自己非常接近的多个高资源语言,使得低资源之间或者低资源和高资源语言之间也同样实现较好的翻译效果,比如说有大规模的ar-ch(阿拉伯语至汉语)数据和tr-ch(土耳其语至汉语)的数据,把这些高资源语言对视作父模型,uy-ch当成孩子模型,默认的迁移学习方法一次只能用一个父模型(ar-ch或者tr-ch),即使用了两个也还是一样的语言。其此时每次初始化孩子模型之后还是只能获取一个父模型的信息,无法充分利用多个父模型的信息。
本发明中提出的方法考虑到了低资源语言对上训练的翻译模型如何同时得到多个高资源语言的帮助,或者获取更多有用的信息。因为现有的迁移学习方法,每次只能从一个高资源语言对上训练出来的模型中获取参数并更新自己,而无法获得跟自己更相关更接近的其他更多的高资源语言对上训练出来的模型的帮助。更重要的是,在低资源的语言对上训练模型对nmt来说是个非常大的挑战,原因是缺乏资源导致数据稀疏问题,而且nmt本身对数据的要求就特别高。最终提出了基于多轮迁移学习的低资源神经网络机器翻译算法,有助于在低资源的语言对上训练出来的孩子模型性能上得到提升。
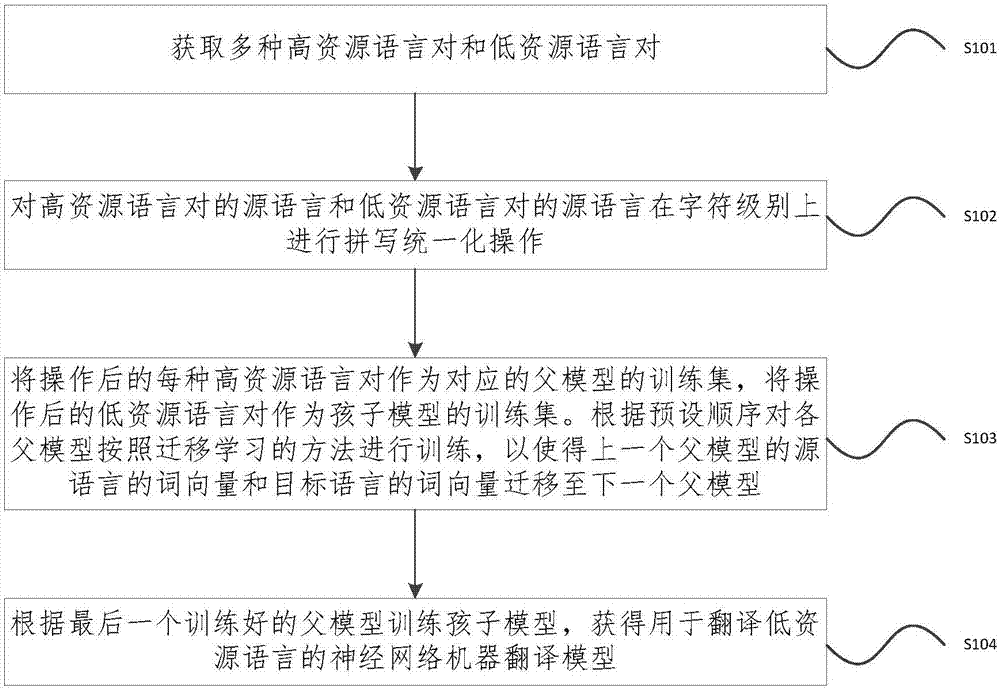
图1示出了本发明实施例的一种神经网络机器翻译模型的训练方法的流程示意图,包括:
s101、获取多种高资源语言对和低资源语言对;多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且高资源语言对中的目标语言和低资源语言对中的目标语言相同。
需要说明的是,由现有技术可知,现有采用迁移算法进行神经网络模型训练时,通常会在采用不同规模大小的同种语言进行迁移学习,但这就导致即使进行多次迁移,孩子模型学到的仅是多个高度近似的父模型的参数和知识,即孩子模型最终的翻译领域很窄。因此本发明实施例为了保证资源丰富的高资源语言对之间的多样性,不再采用仅仅是规模不同的同样语言训练父模型,而是采用不同语系(languagefamily)、不同语族(languagegroup)以及不同语言分支(languagebrach)的资源丰富的高资源(high-resource)语言对。
s102、对高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作。
需要说明的是,现有技术中的词根替换法(wordstemsubstitution)虽然在特别接近的(即有很多共享词又属于同一个语系、语组、以及语言分组的)父模型语言对和孩子模型语言对之间有效,但是跟孩子模型的语言对在句法、词法以及语言结构上有一定差距的不同语系和不同语组的语言之间效果不明显。因此为了尽量减少高资源语言对和低资源语言对在拼写上的区别,在神经网络模型进行训练前必须对高资源语言对中的源语言和低资源语言对中的源语言在字符级别上进行统一的拼写方法(unifiedtransliterationmethod)。通过这样的方式,使得高资源语言和低资源语言之间增加共享单词(sharedwords)的个数。
此外虽然google公司在多语种零样本神经网络机器翻译(multilingualzero-shotnmt)技术中提到了多对一(many-to-one)的方法有效,该方法的核心思想在于只要所选择的高资源语言对的种类足够全、规模足够大,就可以训练好低资源语言对的神经网络模型。但这种方式完全没有考虑那些与低资源语言对毫无关联的高资源语言对会在训练集中产生干扰信号,影响低资源语言对翻译的准确性,再加上google公司本身拥有极强的技术实力和海量资源,完全不需要考虑计算和存储训练集的成本,而在常规应用时,一般企业或研究机构会遇到技术实力和资源的瓶颈,因此无法完整实现google公司的方法。因此,为了克服google公司忽略了高资源语言对和低资源语言对之间的共享单词的比例(即相似性)以及计算成本高昂的缺陷,本发明实施例所获取的高资源语言对,本身需要保证满足(拼写统一化)操作后的源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值。
s103、将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集。根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;预设顺序与各高资源语言对的规模正相关。
需要说明的是,本发明实施例在更新孩子模型的参数前的过程属于父模型迁移学习(transferlearning)连续训练的过程,在这一过程中,父模型根据规模的大小,从大到小依次进行训练,即首先训练最大的父模型,然后用已训好的最大的父模型来训练次大的父模型,以此类推。这是因为如果将父模型以规模从小到大的顺序进行训练,规模较小的父模型将无法给规模较大的父模型提供充足的信息。
因为高资源语言对上训练出来的父模型的目标端的语言和低资源语言对上训练出来的父模型的目标端的语言相同,因此,如果固化父模型目标端将导致孩子模型无法用到自身目标端的词向量,因此,为了让孩子模型充分利用父模型目标端,本发明实施例中的第k+1个父模型包含第k个父模型的参数(即源语言的词向量和目标语言的词向量),这样就使得孩子模型具有k+1个(假设父模型的总数为k+1)父模型的参数,实现了一次性初始化便更新孩子模型的参数,达到充分训练的目的。
s104、根据最后一个训练好的父模型训练孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
需要说明的是,由步骤s103可知,最后一个训练好的父模型实际上继承了此前所有父模型的源语言和目标语言的信息,对于孩子模型的训练,训练过程与父模型的训练过程相同,这样就保证孩子模型能够一次性继承所有父模型的源语言和目标语言的信息,有效解决了孩子模型一次得不到多个高资源语言对的上训练出来的模型的帮助的问题。
需要说明的是,本发明实施例中的神经网络机器翻译模型的训练方法,首先通过选择不同语系、不同语族以及不同语言分支的多种高资源语言对,克服了现有技术中通常采用不同规模大小的同种语言进行迁移学习带来的翻译领域窄的问题,并且所选择的是与低资源语言对存在一定共享单词的比例的高资源语言对,克服了google公司所采用的方法存在的需要占用极高的资源以及因为高资源语言对本身不具有一定共享单词的比例,而导致的存在干扰、准确性较低的问题,进一步地,本发明实施例对高资源语言对和低资源语言对的源语言进行拼写统一化操作,一方面对选择高共享单词的比例的高资源语言对有帮助,另一方面使得高资源语言和低资源语言之间增加了共享单词(sharedwords)的个数;通过按照父模型规模大小的顺序父模型按照迁移学习的方法进行训练,并且将前一个父模型的源语言和目标语言的信息迁移至下一个父模型中,最终保证孩子模型能够一次性继承所有父模型的源语言和目标语言的信息,克服了如果固化父模型目标端将导致孩子模型无法用到自身目标端的词向量的弊端,同时使得孩子模型充分利用跟自己共享单词的比例满足一定程度的高资源语言对,而能够高效准确地完成机器翻译所面临的资源匮乏问题,具备良好的适用范围以及可扩展性。
在上述实施例的基础上,作为一种可选实施例,对高资源语言对和低资源语言对在字符级别上进行拼写统一化操作,具体为:
将所有高资源语言对和低资源语言对的源语句进行拉丁化转换,获得对应不同语言的字符;将任意两个表示相同含义的字符中不同的字母替换为相同的字母。
需要说明的是,申请人在进行神经网络机器翻译模型的训练方法的研究过程中发现,很多语言在被转换为拉丁文后的拼写中具有很大的相似性。例如土耳其语、芬兰语和匈牙利语再转换的拉丁语,与维吾尔语转换的拉丁语非常相似。以“学校”为例,土耳其语在转换为拉丁语后的形式为mektep,和维吾尔语在转换为拉丁语后的形式完全一致,而阿拉伯语在转换为拉丁语后的形式为maktab,与mektep也具有较高的相似度,还比如:“浏览室”的阿拉伯语转换为拉丁语后的形式为qiraaaataxana,而波斯语转换为拉丁语后的形式为qiraaaataxana,土耳其语在转换为拉丁语后的形式为kiraathane,而维吾尔语转换为拉丁语后的形式为qiraetxana。通过观察字母级别的差距,发现他们大部分字母都是通用的,不同的拉丁文字母不到7-8个,用同一个符号(symbol)来替换,一下可以改成同样的一种拉丁文映射的标记(token),使得就不同的那些字母保持统一,帮他们缩短在拉丁表示上的差距而增加更多的共享单词,以便孩子模型从这些高资源的父模型中快速地学到更多的知识。以上述的“学校”和“浏览室”为例,统一化后的拉丁语形式分别为“mektep”和“qiraetxana”。
表1示出了申请人对多种高资源语言与低资源语言——维吾尔语在拉丁化转换后的共享单词的比例情况表。
表1中,ar表示阿拉伯语,fa表示波斯语,ur表示乌尔都语,fi表示芬兰语,hu表示匈牙利语,tr表示土耳其语,uy表示维吾尔语,由表1可知,土耳其语在拉丁化后的形式与维吾尔语拉丁化后的形式具有较多的共享单词。
在上述实施例的基础上,作为一种可选实施例,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型,具体为:
对于待训练的第i个父模型,当i=1时,根据第1个父模型的源语言的词向量、目标语言的词向量以及权重矩阵获得第1个父模型中初始化的参数;根据第1个父模型的训练集和初始化的参数训练第1个父模型,记录训练好的第1个父模型中调整后的参数;
当i大于1时,将训练好的第i-1个父模型中调整后的参数代入初始化函数中,获得第i个父模型中初始化的参数;根据第i个父模型的训练集和初始化的参数对第i个父模型进行训练,记录训练完成的第i个父模型的调整后的参数。
下面以一个具体例子来说明本发明实施例中对各父模型案子迁移学习的方法进行训练的流程。在本实例中,获取四种高资源语言对:tr(4.4m)→ch、tr(2.4m)→ch、fi→ch以及hu→ch,其中tr(4.4m)→ch和tr(2.4m)→ch分别表示规模为4.4m和2.5m的土耳其语至汉语的语言对。低资源语言对为维吾尔语至汉语的语言对:uy→ch。
根据上述4种语言对的规模大小,确定对应的父模型顺序为:mtr(4.4m)→ch→mtr(2.4m)→ch→mfi→ch→mhu→ch。其中mtr(4.4m)→ch、mtr(2.4m)→ch、mfi→ch和mhu→ch分别表示四种高资源语言对所对应的父模型。
获取父模型mtr(4.4m)→ch中的初始化参数θtr(4.4m)→ch:
θtr(4.4m)→ch={<etr(4.4m),w,ech>}
其中,etr(4.4m)表示mtr(4.4m)→ch中的源语言端的词向量,w表示权重矩阵,ech表示目标语言端的词向量。
利用高资源语言对的数据集dtr(4.4m)→ch和初始化的参数θtr(4.4m)→ch对模型mtr(4.4m)→ch进行训练,获得尽可能最大化的模型参数
接着利用参数
θtr(2.4m)→ch:
其中,f表示初始化函数。
相应地,父模型mtr(2.4m)→ch训练后的参数为
简而言之,上述4种父模型的迁移过程可以表示为:
θtr(4.4m)→ch={<etr(4.4m),w,ech>}
由上述最后一个格式可知,低资源语言对上训练的孩子模型中初始化的参数θuy→ch是根据最后一个父模型训练后的参数获得的:
根据最后一个训练好的父模型训练孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型,具体为:
将最后一个训练好的父模型中调整后的参数代入初始化函数中,获得孩子模型中初始化的参数;根据孩子模型的训练集和初始化的参数对孩子模型进行训练,将训练好的孩子模型作为用于翻译低资源语言对的神经网络机器翻译模型。
继续以上述实例进行说明,孩子模型表示为muy→ch,孩子模型的初始化参数表示为θuy→ch’该参数根据最后一个父模型训练后的参数获得的:
类似地,再结合孩子模型的训练集duy→ch对孩子模型进行训练,获得训练好后的孩子模型中的参数:
本发明实施例中的父模型和子模型都属于神经网络机器翻译模型,本发明实施例对神经网络的具体架构不做具体的限定,例如可以采用编码器-解码器框架的rnn神经网络。可以理解的是,编码器用于对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后使用解码器进行解码翻译到目标语言。
本领域技术人员知晓如何利用特定的样本(在本发明实施例中为源语言的语句和目标语言的语句)对神经网络进行训练,并获得训练好的神经网络。为了更清楚地神经网络的训练过程,以下以注意力机制的rnn神经网络为例进行说明:
本发明实施例中的平行句对是指源端句子:x=x1,…,xi,…,xi和目标端句子y=y1,…,yj,…,yj。其中,xi表示源端句子中的第i个单词,yj表示目标端句子的第j个单词,i表示源端句子中单词的总数,j表示目标端句子中单词的总数。
rnn神经网络具体由look-up层、隐藏层以及输出层共3个部分组成。源句子所包含的每个单词通过look-up层转换为对应的词向量表示:
xt=look-up(s)
其中,xt是s的词向量表示,s是每一个时间段t的输入,look-up表示look-up层。
神经网络机器翻译常常将句子级别的翻译概率因式分解为词级别的概率:
其中,θ是一系列的模型参数,y<j是表示已经翻译完成的目标语言单词的个数,比如数翻译到第j个词的话,模型翻译第j个单词的时候需要参考前面的j-1个所有单词信息才能翻译当前的单词,x表示源语句的词向量。
将表达式:
作为训练集时,其中,n和n分别表示第n个词向量维度,n表示词向量维度的总和。标准的训练目标是最大化训练语料的log-likelihood(对数似然估计函数值):
其中,
翻译的决策规则是,没有遇到过的(即没有训练过的)源端句子x,通过以下公式学习模型参数
其中,
也就是说,将目标端用最好的概率
将编码器端采用双向的lstm神经网络单元获取整个源端句子的表示。作为本领域技术人员所熟知的,gru(gatedrecurrentunit)模型作为rnn网络的一个单元,实现两个门的计算,即更新门z和重置门r。更新门用于控制前一时刻的状态信息被带入到当前状态中的程度,更新门的值越大说明前一时刻的状态信息带入越多。重置门用于控制忽略前一时刻的状态信息的程度,重置门的值越小说明忽略得越多。
在获得每个词的词向量表示后,将词向量表示作为编码器的输入,即给隐藏层提供计算所需的信息,隐藏层计算当前的隐状态时,采用loop-up层的输出,即是每一个词的词向量和前面几个隐状态信息来获取,即把词向量映射到一个上下文向量:ht=f(xt,ht-1)其中f是一个抽象函数在给出输入xt和历史状态ht-1的前提下,计算当前新的隐状态。
初始状态h0常常设为0,常见的初始化函数f的选择与下述公式提供的一样,σ是非线性函数(比如:softmax或tanh)ht=σ(wxhxt+wxhht-1),此处softmax是指编码器端计算隐状态时所调用的softmax。编码器端的softmax函数是用于计算隐状态的,求出当前新的隐状态的时候也可以用其他的非线性的激活函数tanh等。
双向birnn的前向(forward)状态按照公式来计算:
进一步说明,翻译模型的decoder(解码)端采用单项rnn,并不是像encoder(编码)端一样双向的rnn。
因为解码器网络也有所对应的隐状态,不过这个隐状态跟编码器网络不同,详细计算过程如下所示:
初始隐状态s0是通过如下方式计算:
其中
上下文词向量在每一个timestep(时间步骤)重新被计算:
其中
hj是源端句子中的第j个符号(隐状态),
在上述实施例的基础上,将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,之前还包括:对所有高资源语言对和低资源语言对进行分词处理的步骤,具体为:
对所有高资源语言对和低资源语言对中的操作后的源语句采用统计机器翻译开源系统moses自带的tokenizer.perl工具进行分词;
对所有高资源语言对和低资源语言对中的目标语句采用thulac(thulexicalanalyzerforchinese)工具包进行中文分词。需要说明的是,thulac工具包是由清华大学自然语言处理以及社会计算国家重点实验室提出的中文分词工具,具有如下几个特点:能力强。利用清华大学集成的目前世界上规模最大的人工分词和词性标注中文语料库(约含5800万字)训练而成,模型标注能力强大。准确率高。该工具包在标准数据集chinesetreebank(ctb5)上分词的f1值可达97.3%,词性标注的f1值可达到92.9%,与该数据集上最好方法效果相当。速度较快。同时进行分词和词性标注速度为300kb/s,每秒可处理约15万字。只进行分词速度可达到1.3mb/s。
除此之外,本发明实施例还包括对源语句和目标语句进行数据处理,比如利用niutrans预处理perlscript工具来清洗数据,即消除非法的中文字符,还比如除了上述清洗步骤之外的再一次重洗数据,以及消除空行、消除非法的不规则的乱码信息以及非中文字母等等。
根据本发明的另一个方面,本发明实施例还提供一种神经网络机器翻译模型的训练装置,参见图2,图2示出了本发明实施例的装置的功能框图,该装置用于前述各实施例的训练用于翻译低资源语言对的神经网络机器翻译模型。因此,在前述各实施例中的方法中的描述和定义,可以用于本发明实施例中各执行模块的理解。
如图所示,包括:
语言对获取模块201,用于获取多种高资源语言对和低资源语言对;多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且高资源语言对中的目标语言和低资源语言对中的目标语言相同;
拼写统一化模块202,用于对高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作;对于任意一种高资源语言对的源语言,满足操作后的该源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值;
父模型训练模块203,用于将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;预设顺序与各高资源语言对的规模正相关;
孩子模型训练模块204,用于根据最后一个训练好的父模型训练孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
本发明实施例中的神经网络机器翻译模型的训练装置,首先通过语言对获取模块201选择不同语系、不同语族以及不同语言分支的多种高资源语言对,克服了现有技术中通常采用不同规模大小的同种语言进行迁移学习带来的翻译领域窄的问题,并且所选择的是与低资源语言对存在一定共享单词的比例的高资源语言对,克服了google公司所采用的方法存在的需要占用极高的资源以及因为高资源语言对本身不具有一定共享单词的比例导致的存在干扰、准确性较低的问题,进一步地,本发明实施例通过拼写统一化模块202对高资源语言对和低资源语言对的源语言进行拼写统一化操作,一方面对选择高共享单词的比例的高资源语言对有帮助,另一方面使得高资源语言和低资源语言之间增加了共享单词(sharedwords)的个数;通过父模型训练模块203按照父模型规模大小的顺序父模型按照迁移学习的方法进行训练,并且将前一个父模型的源语言和目标语言的信息迁移至下一个父模型中,最终保证孩子模型能够一次性继承所有父模型的源语言和目标语言的信息,克服了如果固化父模型目标端将导致孩子模型无法用到自身目标端的词向量的弊端,同时使得孩子模型充分利用跟自己共享单词的比例高度解决的高资源语言对,而能够高效准确地完成机器翻译所面临的资源匮乏问题,具备良好的适用范围以及可扩展性。
在上述实施例的基础上,作为一种可选实施例,拼写统一化模块具体包括:
拉丁化转换单元,用于将所有高资源语言对和低资源语言对的源语句进行拉丁化转换,获得对应不同语言的字符;
替换单元,用于将任意两个表示相同含义的字符中不同的字母替换为相同的字母。
在上述实施例的基础上,作为一种可选实施例,父模型训练模块具体包括:
初始父模型训练单元,用于对于待训练的第i个父模型,当i=1时,根据第1个父模型的源语言的词向量、目标语言的词向量以及权重矩阵获得第1个父模型中初始化的参数;根据第1个父模型的训练集和初始化的参数训练第1个父模型,记录训练好的第1个父模型中调整后的参数;
后续父模型训练单元,用于当i大于1时,将训练好的第i-1个父模型中调整后的参数代入初始化函数中,获得第i个父模型中初始化的参数;根据第i个父模型的训练集和初始化的参数对第i个父模型进行训练,记录训练完成的第i个父模型的调整后的参数。
图3示出了本发明实施例的电子设备的结构示意图,如图3所示,处理器(processor)301、存储器(memory)302和总线303;
其中,处理器301及存储器302分别通过总线303完成相互间的通信;处理器301用于调用存储器302中的程序指令,以执行上述实施例所提供的训练方法,例如,包括:获取多种高资源语言对和低资源语言对;多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且高资源语言对中的目标语言和低资源语言对中的目标语言相同;对高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作;对于任意一种高资源语言对的源语言,满足操作后的该源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值;将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;预设顺序与各高资源语言对的规模正相关;根据最后一个训练好的父模型训练孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
本发明实施例提供一种非暂态计算机可读存储介质,该非暂态计算机可读存储介质存储计算机指令,该计算机指令使计算机执行上述实施例所提供的训练方法,例如,包括:获取多种高资源语言对和低资源语言对;多种高资源语言对中的源语言为不同语系、不同语族以及不同语言分支的平行语句且高资源语言对中的目标语言和低资源语言对中的目标语言相同;对高资源语言对的源语言和低资源语言对的源语言在字符级别上进行拼写统一化操作;对于任意一种高资源语言对的源语言,满足操作后的该源语言与操作后的低资源语言对的源语言间的共享单词的比例大于预设阈值;将操作后的每种高资源语言对作为对应的父模型的训练集,将操作后的低资源语言对作为孩子模型的训练集,根据预设顺序对各父模型按照迁移学习的方法进行训练,以使得上一个父模型的源语言的词向量和目标语言的词向量迁移至下一个父模型;预设顺序与各高资源语言对的规模正相关;根据最后一个训练好的父模型训练孩子模型,获得用于翻译低资源语言的神经网络机器翻译模型。
以上所描述的装置实施例仅仅是示意性的,其中作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分的方法。
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
- 还没有人留言评论。精彩留言会获得点赞!