一种基于词性标注的文档相似性度量方法与流程
本发明涉及一种基于词性标注和wordmover’sdistance的文档相似性度量方法。
背景技术:
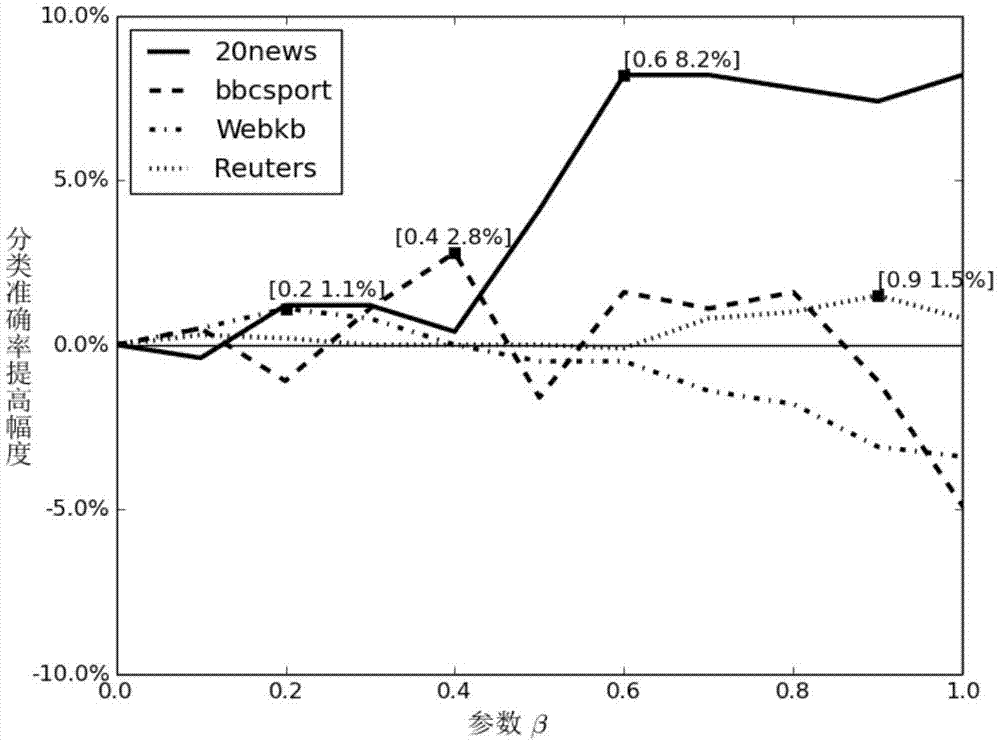
文档距离度量模型广泛地应用在文本聚类、邮件过滤、新闻分类、信息检索等自然语言领域。如何精确地表示文档之间的距离,成为自然语言领域研究的热点问题之一。wordmover’sdistance(wmd)模型是基于词向量和earthmover’sdistance的文档语义距离度量模型,该模型将文档的距离转化为文档中单词“转移”的最小运输代价,具有无超参、可解释性的特点,相比于传统的bag-of-words(bow)、termfrequency–inversedocumentfrequency(tf-idf)、latentsemanticindexing(lsi)等模型,在文本分类任务上具有更高的准确率。原始wmd模型利用具有语义信息的词向量,更多地关注文本中的语义信息,而忽略语法信息的重要性,使得文本距离度量不够准确,因此导致文本分类等任务的准确率不高的问题。技术实现要素:本发明的目的是提供一种基于词性标注和wdm模型的文档相似性度量方法。本发明是一种结合语法信息改进wmd模型的文档距离度量方法,使得文本之间的距离度量更加精确,可以被应用在信息检索、文本分类等自然语言处理任务中,能够大大提高文本分类任务的准确率。词性是单词的重要性质,如动词、名词、形容词、介词等词性。在理想情况下,一个单词的近义词不仅在语义上与其相似,而在语法上也应该同属于一个词性。文档之间的差别不仅体现在语义上,同时也体现在语法上。因此,本发明提出结合语法信息完善wmd模型,使得文档距离更加精确。本发明主要包含两个方面:1)词性编码:使用词性标注工具对训练语料进行词性标注,得到语料的词性标签,提取词性标注的标签序列,使用word2vec等词向量生成模型对词性标签进行编码,得到词性标签向量。2)度量文本距离:对文档进行词性标注,根据文档的词性标签分布和单词分布使用earthmover’sdistance算法度量文档之间的距离。首先,对词性标签进行编码,将每个词性标签标注成实数向量。具体流程如下:设输入为文本语料,输出为词性标签向量。1.使用词性标注工具对文本语料进行标注;2.提取词性标签序列,构造词性标签语料;3.使用word2vec等词向量生成模型对词性标签语料进行训练,得到词性标签向量。在度量两个文本之间的距离时,同时考虑文本单词之间的“转移代价”和文本词性标签之间的“转移代价”,具体生成步骤如下:设输入参数doc1、doc2、wv、tv和β,其中doc1,doc2是待度量距离的两个文本,wv是词向量,tv是词性标签向量。β是调节单词转移所产生代价和标签转移所产生代价的参数。输入结果为doc1和doc2之间的文本距离,1.对输入文本doc1和doc2进行数据清洗,去掉文本中标点、停用词信息;2.计算doc1的单词权重矩阵d1=[d1,d2,…,dm],其中m是doc1出现的词项个数,di代表第i个词项在文本doc1中出现的频率,计算公式是其中第i个词项在文本doc1中出现pi次。用同样方式计算doc2的单词权重矩阵d2=[d1,d2,…,dn],其中n是doc2出现的词项个数。3.计算doc1与doc2之间由单词转移所产生的代价disword:1)根据doc1和doc2中出现的单词,计算单词之间欧式距离矩阵c,其中矩阵c中的元素cij代表文档doc1中第i个单词所对应的词向量wvi与文档doc2第j个单词对应的词向量wvj之间的欧式距离。2)计算doc1和doc2之间由单词转移所产生的代价计算公式如下:目标函数约束条件:其中t是转移矩阵,tij代表文档doc1中第i个单词与文档doc2中第j个单词的转移量,tij≥0。4.对文本doc1进行词性标注,得到文本的词性标注序列,计算doc1的词性标签权重矩阵p1=[p1,p2,…,pm],其中m是词性标签向量中的标签个数,pi代表第i个标签在标注文本doc1中出现的频率,计算公式是其中第i个标签在标注文本doc1中出现ai次。用同样方式计算doc2的词性标签权重矩阵p2。5.计算doc1和doc2之间由标签转移所产生的代价distag:1)根据doc1和doc2的词性标签序列构建词性标签集合s,并计算词性标签集合s之间欧式距离矩阵v,其中vij代表集合s中第i个标签所对应的向量tvi与第j个标签对应的向量tvj之间的欧式距离。2)计算doc1和doc2之间的语义信息转移距离,计算公式如下:目标函数约束条件:其中t′是转移矩阵,t′ij代表文档doc1中第i个词性标注与文档doc2中第j个词性标注的转移量,且t′ij≥0。6.根据以上计算的距离disword和distag,计算文本doc1和doc2之间的距离为disword+β*distag。图2展示了本发明的流程图。为验证本发明是否优于wmd模型,我们在4个数据集20news,bbcsport,reuters和webkb上使用wmd算法和本发明,分别统计二者在文本分类上的准确率。由实验结果如表1所示,在最优参数设置下,与原wmd模型相比,4种数据集的分类任务准确性都高于wmd模型,提升了文本分类任务的效果,因此本发明相比于wmd模型可以得到更加准确地文本距离。本发明设置参数β在[0,1]区间内,以0.1为递增步长。图1和表2展示了本发明对wmd文本分类准确率提升的幅度,如在20news数据集上,在参数β设置为0.6时,本发明能够提高8.9%的文本分类准确率。同时,由实验结果表明,参数β是一个在区间[0,1]的经验值,依据具体的数据集而定。实验结果如下所示。表1本发明和wmd在4种数据集上分类任务的表现数据集wmd算法本发明20news24.4%+2.0%bbcsport79.9%+2.2%reuters86.6%+1.3%webkb65.0%+0.7%表2最优参数设置下提升幅度数据集wmd提升幅度参数设置20news24.4%8.2%0.6bbcsport79.9%2.8%0.4reuters86.6%1.5%0.9webkb65.0%1.1%0.2其中,表1为本发明与wmd模型在4个数据集20news,bbcsport,reuters和webkb的文本分类表现统计。第2列显示wmd模型的文本分类准确率,最后一列显示本发明提高的准确率大小。图1为本发明的参数β对文本分类效果的影响分析,横轴x代表参数设置,区间为[0,1],以0.1为递增步长进行统计。纵轴y代表在该参数设置下,某一数据集相对于wmd模型的分类准确率提高百分比。如对于数据集20news,使用wmd模型进行分类,准确率为24.4%,本发明提高准确率2.0%,相对于wmd模型,准确率提升8.2%。表2为本发明分类任务上最好准确率对应的参数设置和提升幅度展示。附图说明图1为参数设置对原始wmd提升幅度的影响分析图;图2为本发明的流程图。具体实施方式以a为原始文本语料,以b和c为待度量距离文档,β是参数,假设b=“thechildrenspeakintheclassroom.”,c=“ashygirlwithahatiscrying”:1)对a进行数据清理,将a中标点符号,如逗号、冒号、分号等去掉;去除a中的停用词,如the、or、is等。2)使用googleword2vec工具进行训练,得到词向量模型,该模型中每一项对应一个单词和它的向量表示,如[apple5.1916605.1837891.4400090.429530-8.0556833.9533510.854346-2.413922-0.9245113.460100-1.180899-0.173409……-5.3767856.9442890.971594-1.491963]3)使用词性标注工具如stanfordpos对语料a进行标注,提取标注序列如“……dtjjnnindtnnvbzvbg……”,并使用googleword2vec工具进行训练,得到标签向量模型,该模型中每一行对应一个标签和它的向量表示,如[nn0.0080050.008839-0.007661-0.0065560.0027330.0060420.0018820.000423…….-0.005165-0.006084-0.0061530.0033940.0004030.002662]4)计算b和c之间语义上的距离disword:a)首先对b和c进行数据清洗,去掉停用词和标点,分别得到b的词项集合为{children,speak,classroom},c的词项集合为{shy,girl,hat,crying}b)计算b和c的单词权重矩阵,分别是c)计算文本b和文本c单词之间的欧式距离矩阵c,例如c12是文本b中第1个单词“speak”对应的词向量和文本c中第2个单词“hat”对应的词向量之间的欧氏距离。d)根据文本b的权重矩阵d1、文本c的权重矩阵d2和距离矩阵c,利用上面第一个公式计算二者之间的距离,得到disword。5)计算b和c之间语法上的距离distag:a)使用词性标注信息对文本b和c进行词性标注,得到“the_dtchildren_nnspeak_vbin_inthe_dtclassroom_nn”,c=“a_dtshy_jjgirl_nnwith_ina_dthat_nnis_vbzcrying_vbg”,分别抽取标签得到集合{dt,nn,vb,in}和{dt,jj,nn,in,vbz,vbg}b)计算b和c的标签权重矩阵,分别是c)计算文本b和文本c标签集合之间的欧式距离矩阵c,例如c22是文本b中第2个标签“vb”对应的向量和文本c中第2个标签“nn”对应的向量之间的欧氏距离。d)根据文本b的权重矩阵p1、文本c的权重矩阵p2和距离矩阵c,利用上面第二个公式计算二者之间的距离,得到distag。6)计算disword+β*distag,得到文本b和文本c之间的距离。以上实施仅用以说明本发明的技术方案而非对其进行限制,本领域的普通技术人员可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明的精神和范围,本发明的保护范围应以权利要求书所述为准。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1