一种改进特征选择的算法的制作方法
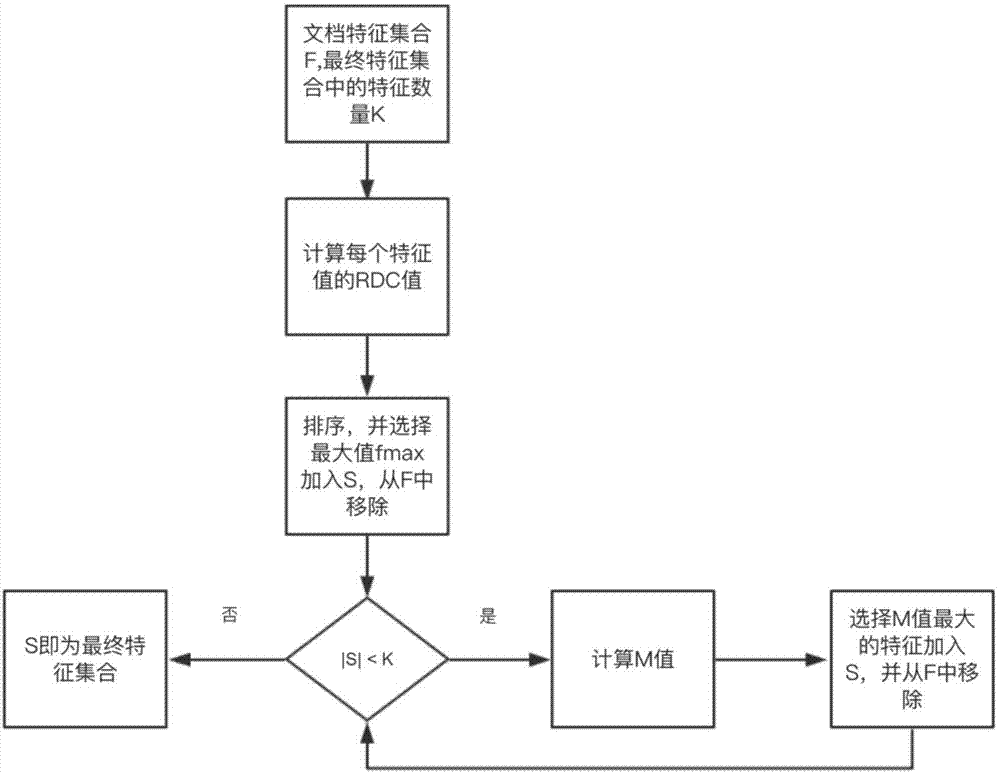
本发明涉及一种改进特征选择的算法,属于特征空间的高维度特征选择
技术领域:
。
背景技术:
:大数据时代缔造者就是互联网,互联网的急速发展使数据量呈现爆炸式增加。在如此大的数据量面前,既给人们带来千载难逢的机遇又给人们带来了极大的挑战。很多有价值的信息被大量的无用数据淹没,使人们很难获得自己需要而且又有价值的信息,因此如何从大量数据中挖掘出人们需要的信息成为研究的重点方向。文本分类己成为一个重要的研究课题,在机器学习、信息检索和垃圾邮件过滤中得到了广泛的研究和应用。在这些领域应用文本分类技术,有许多优点。对于数字图书馆的分类管理,相对于人工方法,大大缩短了文档的归类整理时问。在信息检索领域,借助文本分类技术,将文本信息分为相关和不相关类别,过滤掉无用的检索结果,能明显提高检索的准确率和速度。当前文本分类的技术和理论已比较成熟,并取得了不错的成果。但是随着移动互联网的发展,文本数据出现了许多新的特征。例如以微博、微信、社区和贴吧为主的社交网络流行,短文本数据在逐渐增多。此外,文本的类别数日增多、类别分布不均匀、类别标注困难等新的变化,也给文本分类带来了巨人挑战。文本分类还有很大的改善空间,仍有必要对其进行研究,改善文本分类的效果。在文本分类的过程中,文档通常被建模为一个向量空间,其中每个单词被认为是一个特征。在文档的矢量模型中,特征的值可以是其对应词的频率或词频-逆文档频率(tf-idf)。文本分类中最重要的问题之一是处理特征空间的高维度。特征空间的高维特别是在包含大量单词的文本分类任务中导致增加的计算成本和降低的分类性能。特征选择和提取是降低文本特征空间维度的两种主要方法。特征选择近年来得到关注,旨在从数据中利用一定的策略选择出原始特征集的一个最优子集,从而促进后续其它目标任务的学习。特征选择的目标包含三个方面的意义:(1)提高目标模型的预测性能;(2)减少目标模型的训练时间和预测时间,提高效率;(3)揭示数据中的隐含意义和数据的产生过程。简单来讲就是,特征选择使得数据更加精简有效,同时有助于更好地理解数据。特征选择作为数据处理的首要一步,对于大数据,可减小数据规模,降低目标模型学习的难度,对于高维数据,能对数据降维以克服“维度灾难”问题,防止模型过拟合。尤其是对高维数据的学习中,对数据进行分析和学习的难度和成本相对数据维度呈现指数级增长,必须学习复杂模型,以提高模型的表达能力,同时还需要指数级增长的数据量来支持复杂模型的学习。数据量过小,则会导致模型过拟合,模型的泛化性能差。因此,对数据进行特征选择十分必要,但要在原始特征集的庞大子集空间中找到最优特征集作为对数据的表示,难度极大。特征提取是指通过合并或变换原始类型来生成一小组新特征的过程,而在特征选择中,通过选择最显着的特征来减少空间维度。特征选择方法可以分为四类:过滤器,包装器,嵌入式和混合式方法。过滤器方法对特征空间执行统计分析以选择特征的区分性子集。特征选择方法应该能够识别和移除尽可能多的不相关和冗余特征。大多数特征选择方法可以有效地去除不相关的特征,但是不能处理冗余特征。技术实现要素:本发明要解决的技术问题是提供了一种改进特征选择算法,目的是为了克服上述现有技术的不足,该算法能从特征空间中过滤冗余和不相关的特征,选择特征空间中最优特征子集,从而达到降维的目的,进一步提高文本分类的效果。本发明采用的技术方案是:一种改进特征提取的算法,包括如下步骤:step1:输入最终特征空间包含的特征数量k,创建一个新的集合s,f为文档d的所有特征集合;step2:遍历f中的每一个特征fs,计算其相关性值rdc(fs),即使用下列方程组计算rdc值:rdc(wi)=auc(wi,tcm),其中wi为特征词,dfpos(wi)和dfneg(wi)分别是含有词语wi的文档数量和不含有词语wi的文档数量,tcj(wi)表示词语wi在文档j中的数量,auc(wi,tcj)表示特征词wi与词频tcj的roc曲线下面积,tcj-1表示特征词在文档j-1中的数量,tcj+1表示特征词在文档j+1中的数量,tcm表示特征词在最后一个文档m中的数量;step3:根据step2所计算出的rdc值进行排序;step4:选择最大的rdc的特征fmax;step5:添加fmax至集合s;step6:从集合f中移除fmax;step7:遍历集合f,对每一个特征值令sum(fi)=0;step8:遍历集合f,对每一个特征值fi,计算其与s中每一个特征fs的相关度correlation(fi,fs)并且计算step9:对集合f中的每一个特征值fi,使用以下公式计算其m(fi)值,即:m(fi)=rdc(fi)-sum(fi),其中rdc(fi)是特征fi的相关值,并且correlation(fi,fj)表示由它们的相似性值定义的两个特征fi和fj之间的相关性,用pearson相关系数来计算相关值:其中fi,d和fj,d分别是第d个文档的特征词i和j的词频,和分别是fi和fj在文档集合中词频的平均值,correlation(fi,fj)为1时表示最大的正相关,correlation(fi,fj)为-1时表示最大的负相关,其值介于-1与1之间;step10:选择m值最大的特征fmax;step11:增加fmax到集合s;step12:从集合f中移除fmax;step13:重复step8-step12直到集合s中的数量等于k;step14:集合s即为最终选择的特征。本发明的有益效果是:1、本发明的精度比传统方法rdc的精度高;2、本发明从特征空间去除冗余和不相关的特征,实现了进一步特征空间降维。附图说明图1为本发明的方法流程图。具体实施方式下面结合附图和具体实施例,对本发明作进一步的详细说明。实施例1:如图1所示,一种改进特征提取的算法,包括如下步骤:本发明首先使用rdc(相对判别标准)度量来计算每个特征的相关性,然后使用皮尔逊相关系数来计算特征之间的相关值。最后通过计算本发明定义的m值来逐步选择最优特征。具体如下:step1:输入最终特征空间包含的特征数量k(k的值根据实际情况设定,这里不作具体限定),创建一个新的集合s,f为文档d的所有特征集合;step2:遍历f中的每一个特征fs,计算其相关性值rdc(fs),即使用下列方程组计算rdc值:rdc(wi)=auc(wi,tcm),其中wi为特征词,dfpos(wi)和dfneg(wi)分别是含有词语wi的文档数量和不含有词语wi的文档数量,tcj(wi)表示词语wi在文档j中的数量,auc(wi,tcj)表示特征词wi与词频tcj的roc曲线下面积,tcj-1表示特征词在文档j-1中的数量,tcj+1表示特征词在文档j+1中的数量,tcm表示特征词在最后一个文档m中的数量;step3:根据step2所计算出的rdc值进行排序;step4:选择最大的rdc的特征fmax;step5:添加fmax至集合s;step6:从集合f中移除fmax;step7:遍历集合f,对每一个特征值令sum(fi)=0;step8:遍历集合f,对每一个特征值fi,计算其与s中每一个特征fs的相关度correlation(fi,fs)并且计算step9:对集合f中的每一个特征值fi,使用以下公式计算其m(fi)值,即:m(fi)=rdc(fi)-sum(fi),其中rdc(fi)是特征fi的相关值,并且correlation(fi,fj)表示由它们的相似性值定义的两个特征fi和fj之间的相关性,用pearson相关系数来计算相关值:其中fi,d和fj,d分别是第d个文档的特征词i和j的词频,和分别是fi和fj在文档集合中词频的平均值,correlation(fi,fj)为1时表示最大的正相关,correlation(fi,fj)为-1时表示最大的负相关,其值介于-1与1之间;step10:选择m值最大的特征fmax;step11:增加fmax到集合s;step12:从集合f中移除fmax;step13:重复step8-step12直到集合s中的数量等于k;step14:集合s即为最终选择的特征。下面结合具体例子对本发明进行详细说明:表1一个简单的数据集(只有两类种类别)文档类内容文档d1正面猫,鱼文档d2正面猫,老鼠,鱼文档d3正面老鼠,鱼文档d4正面老鼠,猫,鱼,老鼠,鱼文档d5正面鱼,猫,鱼,猫文档d6正面鱼,老鼠文档d7负面狗,老鼠文档d8负面狗,狗文档d9负面鱼,鱼,老鼠文档d10负面老鼠文档d11负面猫,鱼文档d12负面狗,鱼表1中提供了一个简单的合成数据集。该数据集由12个文档组成,包含4个词语,包括'猫','狗','老鼠'和'鱼'。此数据集中的每个文档都属于正面或负面类别。表2该数据集词频文档f1(猫)f2(鱼)f3(老鼠)f4(狗)f5(鱼)文档111001文档211101文档301101文档412202文档522002文档601101文档700110文档800020文档902102文档1000100文档1111000文档1201011表2示出了该数据集的矩阵形式(即矢量模型)。首先,计算各词语的在各个文档中的词频。为了突出该发明的有效性,再次重复其中一个特征f2并作为新特征f5添加到数据集中。因此,特征fi和fj是完全相关的。特征选择的目的是选择具有最低相关性的高度相关特征。f2和f5包含相同的信息,其中一个是多余的。其中一个特征有较高的m值,而另一个冗余特征的m值比较低。以下计算f2和f5的rdc的值是一样的;而计算他们m的值则是不同的。rdc(f1)=(2+5)/2+(5+0)/2=6rdc(f2)=rdc(f5)=(1+0.5)/2+(0.5+0)/2=1rdc(f3)=(0+5)/2+(5+0)/2=5rdc(f4)=(20+5)/2+(5+0)/2=15基于所提出的m的公式重复这些计算,并且相应的结果如下所示,f2和f5的m值并不相同。根据公式:中,特征的最终m的值与相关性(方程等式右边的第一项)和冗余度(方程等式右边的第二项)相关。当两个特征f2和f5非常相似时,它们之间的相关性将接近于1.因此,如果在fj之前选择fi,则fi分配的冗余值将低于fj。表3rdc与本发明所提出的m值方法f1(猫)f2(鱼)f3(老鼠)f4(狗)f5(鱼)rdc615151m5.902-0.1934.6315-0.84表3比较了这些特征的rdc和m值。可以看出,f2和f5的rdc值一样,而这两个特征则有不同的m值。在本例中,f2和f5特征完全相同,但f5的m值比f2的m值低,而却有相同的rdc值。使用m值,f2和f5的选择或舍弃取决于阈值k(最终特征子集的预定义数量k)。如果k=3,f2和f5都不选择,而选择k=4,则f2被选择,而f5被舍弃,并且如果k=5,则f2和f5都被选择。该实例的整体流程:对于文档d4,k=4:step1:初始化集合s,集合f为d4的所有特征值,即{老鼠,猫,鱼,老鼠,鱼};step2:对于集合f中的每个值。使用公式计算其相关度rdc值f(猫)=6,f(鱼)=1,f(老鼠)=5,f(狗)=15,f(鱼)=1;step3:根据rdc进行排序{f(狗)=15,f(猫)=6,f(老鼠)=5,f(鱼)=1,f(鱼)=1}step4:选择rdc值最大的特征fmax(狗);step5:将f(狗)添加到集合s中;step6:将f(狗)从集合f中移除;step7:遍历集合f,对每一个特征sum(fi)=0;step8:对集合f中的每一个特征,联合s中的f(狗)计算correlation(fi,f(狗))即correlation(f(猫),f(狗))=sum(猫)+correlation(f(猫),f(猫))sum(fi)=sum(f(猫))+correlation(f(猫),f(狗))correlation(f(鱼),f(狗))=sum(鱼)+correlation(f(鱼),f(猫))sum(fi)=sum(f(鱼))+correlation(f(鱼),f(狗))correlation(f(老鼠),f(狗))=sum(老鼠)+correlation(f(老鼠),f(猫))sum(fi)=sum(f(老鼠))+correlation(f(老鼠),f(狗))correlation(f(鱼),f(狗))=sum(鱼)+correlation(f(鱼),f(猫))sum(fi)=sum(f(鱼))+correlation(f(鱼),f(狗));step9:对集合f中的每个值计算其m值,分别为m(猫)=5.902,m(鱼)=-0.193,m(老鼠)=4.63,m(鱼)=-0.84;step10:选择m值最大的那个特征值,即m(猫)=5.902,把f(猫)放入集合s中;step11:将f(猫)从集合f中移除;step12:重复step8-step11至集合s中的数量等于4。最终所选的特征空间为{狗,老鼠,猫,鱼}。本发明不仅选择特征空间中最相关的特征,而且使用相关性度量考虑它们之间的冗余,能从特征空间中过滤冗余和不相关的特征,选择特征空间中最优特征子集,将特征空间降维,从而提高文本分类的性能。以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1