用于嵌入式设备的实例分割方法及装置、手机端与流程
本申请涉及计算机视觉领域,具体而言,涉及一种用于嵌入式设备的实例分割方法及装置。
背景技术:
随着计算机视觉的快速发展,物体检测和语意分割已经有了很大的进展,很多物体检测和分割方法都是基于fast/fasterrcnn以及fcn全卷积网络衍生而来,同时这些方法兼具灵活性和鲁棒性,并且在很短的时间内能完成训练。相比语意分割和物体检测,实例分割有着更大的难度,它的难点在于准确的检测每个物体的同时,还要去分割它们。总的来说,实例分割包括了:物体检测,物体分类以及物体分割三个功能。实例分割的完善有助于无人车,增强现实,视频分析等领域的快速发展,目前比较完善的方法有maskrcnn,它是在fasterrcnn的基础上,增加了物体分割分支,实现了实例分割功能,并且在coco数据集上测试,具有较高的准确度。
发明人发现,由于采用maskrcnn在12g显存gpu上运行仅有5fps帧率,这对于无人车等对实时性要求高的系统来说,这无法达到要求。尤其在嵌入式设备上,很多设备目前并没有配置gpu,所以算法逻辑只能运行在cpu上。比如,经测试,maskrcnn在iphonex的运行时间为6s,无法达到实时。所以,如何在保持maskrcnn的准确率的基础上,提高maskrcnn的运行速度是有待解决的技术问题。
针对相关技术中实例分割的准确率和速度无法做到兼容的问题,目前尚未提出有效的解决方案。
技术实现要素:
本申请的主要目的在于提供一种用于嵌入式设备的实例分割方法及装置,以解决实例分割的准确率和速度无法做到兼容的问题。
为了实现上述目的,根据本申请的一个方面,提供了一种用于嵌入式设备的实例分割方法。
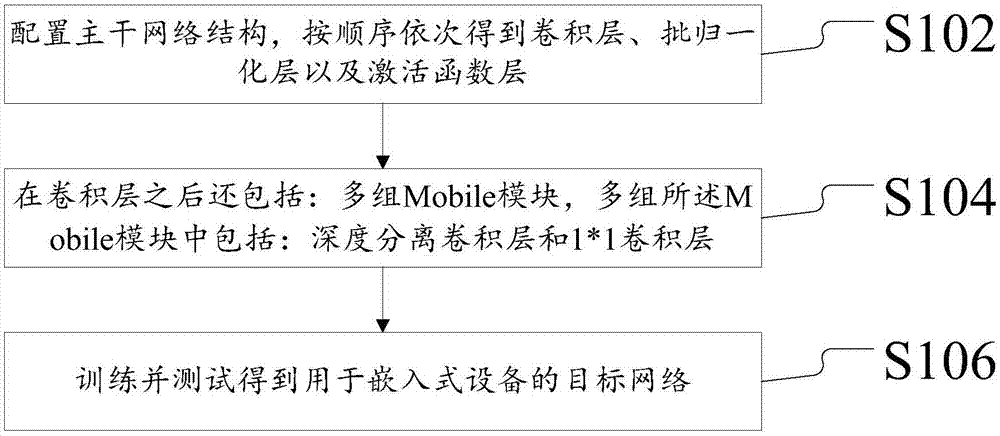
根据本申请的用于嵌入式设备的实例分割方法包括:配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层;在卷积层之后还包括:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层;以及训练并测试得到用于嵌入式设备的目标网络。
进一步地,深度分离卷积层包括:3*3深度分离卷积层。
进一步地,方法还包括:通过增加fpn结构得到多尺度网络结构。
进一步地,方法还包括:设计损失函数,其中,损失函数中包括:rpn的类别损失,rpn的回归框损失,fastrcnn的类别损失,fastrcnn的回归框损失,mask分支的像素点类别损失中的任意一种。
进一步地,所述训练的过程包括:使用imagenet数据集训练、使用微软coco数据集训练、使用针对预设任务的数据集训练。
进一步地,所述测试的过程包括:fastrcnn的输出是rpn的输出,mask分支的输入是fastrcnn的输出。
为了实现上述目的,根据本申请的另一方面,提供了一种用于嵌入式设备的实例分割装置。
根据本申请的用于嵌入式设备的实例分割装置包括:配置模块,用于配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层;在卷积层之后还包括:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层;以及训练测试模块,用于训练并测试得到用于嵌入式设备的目标网络。
进一步地,装置还包括:多尺度模块,用于通过增加fpn结构得到多尺度网络结构。
进一步地,装置还包括:损失函数模块,用于设计损失函数,其中,损失函数中包括:rpn的类别损失,rpn的回归框损失,fastrcnn的类别损失,fastrcnn的回归框损失,mask分支的像素点类别损失中的任意一种。
为了实现上述目的,根据本申请的另一方面,提供了一种手机端,包括:所述的实例分割装置。
在本申请实施例中,采用配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层的方式,通过在卷积层之后还包括:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层,达到了训练并测试得到用于嵌入式设备的目标网络的目的,从而实现了嵌入式设备上执行准确、高速地完成实例分割的技术效果,进而解决了实例分割的准确率和速度无法做到兼容的技术问题。经过测试,在手机上,本方法可以实现6fps的帧率,大约200ms一帧,相比原版maskrcnn,本申请有了30倍左右的提升,同时准确率只降低了5%。
附图说明
构成本申请的一部分的附图用来提供对本申请的进一步理解,使得本申请的其它特征、目的和优点变得更明显。本申请的示意性实施例附图及其说明用于解释本申请,并不构成对本申请的不当限定。在附图中:
图1是根据本申请实施例的用于嵌入式设备的实例分割方法示意图;
图2是根据本申请实施例的用于嵌入式设备的实例分割装置示意图;以及
图3是根据本申请实施例中的多组mobile模块结构示意图。
具体实施方式
为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本申请一部分的实施例,而不是全部的实施例。基于本申请中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本申请保护的范围。
需要说明的是,本申请的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本申请的实施例。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
在本申请中,术语“上”、“下”、“左”、“右”、“前”、“后”、“顶”、“底”、“内”、“外”、“中”、“竖直”、“水平”、“横向”、“纵向”等指示的方位或位置关系为基于附图所示的方位或位置关系。这些术语主要是为了更好地描述本申请及其实施例,并非用于限定所指示的装置、元件或组成部分必须具有特定方位,或以特定方位进行构造和操作。
并且,上述部分术语除了可以用于表示方位或位置关系以外,还可能用于表示其他含义,例如术语“上”在某些情况下也可能用于表示某种依附关系或连接关系。对于本领域普通技术人员而言,可以根据具体情况理解这些术语在本申请中的具体含义。
此外,术语“安装”、“设置”、“设有”、“连接”、“相连”、“套接”应做广义理解。例如,可以是固定连接,可拆卸连接,或整体式构造;可以是机械连接,或电连接;可以是直接相连,或者是通过中间媒介间接相连,又或者是两个装置、元件或组成部分之间内部的连通。对于本领域普通技术人员而言,可以根据具体情况理解上述术语在本申请中的具体含义。
需要说明的是,在不冲突的情况下,本申请中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本申请。
本申请中的方法实现了实例分割功能,具体包括:1)物体检测;2)物体识别;3)物体分割等三个子功能。本申请在移动端运行时间大约一帧200ms,准确度相比原maskrcnn仅下降5%。
如图1所示,该方法包括如下的步骤s102至步骤s106:
步骤s102,配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层;
配置主干网络结构时首先是一个普通卷积层,接下来采用的是13组不同大小的{3*3深度分离卷积层+1*1卷积层},然后是批归一化层,最后是relu激活函数层。
优选地,使用mobilenets结构替换了maskrcnn中的resnet结构,采用该结构在参数量和计算量都有所节省。
步骤s104,在卷积层之后还包括:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层;以及
多组mobile模块采用不同的大小。同时在一个mobile模块中包括了一个深度分离卷积层和一个1*1卷积层。
步骤s106,训练并测试得到用于嵌入式设备的目标网络。
对模型进行训练、测试之后得到目标网络的结果可以用于嵌入式设备中。
在训练过程中,做到了端到端的训练,减少了训练所需的时间,和人工成本。
从以上的描述中,可以看出,本申请实现了如下技术效果:
在本申请实施例中,采用配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层的方式,通过在卷积层之后还包括:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层,达到了训练并测试得到用于嵌入式设备的目标网络的目的,从而实现了嵌入式设备上执行准确、高速地完成实例分割的技术效果,进而解决了实例分割的准确率和速度无法做到兼容的技术问题。本申请相比原版maskrcnn,模型大小为27m,原版maskrcnn模型大小为256m,减少为原本的1/10,同时速度提升了将近30倍,准确率降低5%。
为了解决相关卷积网络在嵌入式设备上运行速度慢的问题,在本申请的实施例中将卷积网络中的预设深度残差结构resnet替换为mobilenets结构。mobilenets结构经测试在移动端cpu上的表现性能良好。同时为了增加物体检测和分割的多尺度性,保留了原卷积网络中的fpn模块。
根据本申请实施例,作为本实施例中的优选,深度分离卷积层包括:3*3深度分离卷积层。
根据本申请实施例,作为本实施例中的优选,方法还包括:通过增加fpn结构得到多尺度网络结构。将mobilenets与fpn相结合,保证了参数量急剧减少的同时,准确率不会降低太多,同时使得主干网络mobilenets具备多尺度的性能,增加了对小尺寸物体的分割能力。
根据本申请实施例,作为本实施例中的优选,方法还包括:设计损失函数,其中,损失函数中包括:rpn的类别损失,rpn的回归框损失,fastrcnn的类别损失,fastrcnn的回归框损失,maskrcnn分支的像素点类别损失中的任意一种。
根据本申请实施例,作为本实施例中的优选,所述训练的过程包括:使用imagenet数据集训练、使用微软coco数据集训练、使用针对预设任务的数据集训练。本申请的实施例提供一套训练策略,其中预训练部分涉及的训练数据均为公开数据集,所以本申请的实施例的训练策略具有普适性特点。
根据本申请实施例,作为本实施例中的优选,所述测试的过程包括:fastrcnn的输出是rpn的输出,mask分支的输入是fastrcnn的输出。本申请的实施例中提供的测试策略,将mask分支接在fastrcnn分支之后,保证了分割的准确性。
需要说明的是,在附图的流程图示出的步骤可以在诸如一组计算机可执行指令的计算机系统中执行,并且,虽然在流程图中示出了逻辑顺序,但是在某些情况下,可以以不同于此处的顺序执行所示出或描述的步骤。
根据本申请实施例,还提供了一种用于实施上述用于嵌入式设备的实例分割方法的装置,如图2所示,该装置包括:配置模块101,用于配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层;在卷积层之后还配置:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层;以及训练测试模块102,用于训练并测试得到用于嵌入式设备的目标网络。
在本申请实施例的配置模块101中配置主干网络结构时首先是一个普通卷积层,接下来采用的是13组不同大小的{3*3深度分离卷积层+1*1卷积层},然后是批归一化层,最后是relu激活函数层。
优选地,使用mobilenets结构替换了maskrcnn中的resnet结构,采用该结构在参数量和计算量都有所节省。
在本申请实施例的配置模块101中多组mobile模块采用不同的大小。同时在一个mobile模块中包括了一个深度分离卷积层和一个1*1卷积层。
在本申请实施例的训练测试模块102中对模型进行训练、测试之后得到目标网络的结果可以用于嵌入式设备中。
在训练过程中,做到了端到端的训练,减少了训练所需的时间,和人工成本。
作为本实施例中的优选,装置还包括:多尺度模块103,用于通过增加fpn结构得到多尺度网络结构。将mobilenets与fpn相结合,保证了参数量急剧减少的同时,准确率不会降低太多,同时使得主干网络mobilenets具备多尺度的性能,增加了对小尺寸物体的分割能力。
作为本实施例中的优选,装置还包括:损失函数模块104,用于设计损失函数,其中,损失函数中包括:rpn的类别损失,rpn的回归框损失,fastrcnn的类别损失,fastrcnn的回归框损失,mask分支的像素点类别损失中的任意一种。
此外,在本申请的另一实施例中,还提供了手机端,包括:所述的实例分割装置。所述的实例分割装置包括:
配置模块,用于配置主干网络结构,按顺序依次得到卷积层、批归一化层以及激活函数层;
在卷积层之后还配置:多组mobile模块,多组所述mobile模块中包括:深度分离卷积层和1*1卷积层;以及
训练测试模块,用于训练并测试得到用于嵌入式设备的目标网络。
本申请的实现原理如下:在本申请中以maskrcnn作为例子对本申请的实现原理进行详细地说明。
为了解决maskrcnn在嵌入式设备上运行速度慢的问题,在本申请中的方案是把maskrcnn中的resnet101替换为较为轻量级的网络mobilenets结构,经测试在移动端cpu上的表现性能良好,同时为了增加物体检测和分割的多尺度性,本申请保留了原maskrcnn的fpn模块;在本申请中所使用的maskrcnn全称是mmrcnn(mobilemaskrcnn的缩写)。经测试,在iphonex上,本方法可以实现6fps的帧率,大约200ms一帧,相比原版maskrcnn,本申请有了30倍左右的提升,同时准确率只降低了5%。
总的来说,本发明mmrcnn,实现了实例分割功能,包括:1)物体检测;2)物体识别;3)物体分割,三个子功能,本发明在移动端运行时间大约一帧200ms,准确度相比原maskrcnn仅下降5%。
本发明分为主干网络结构设计,多尺度网络结构设计,损失函数设计,训练阶段,以及测试阶段五个部分:
1)主干网络结构设计:本发明替换了原版maskrcnn中的resnet结构,使用mobilenet结构,该结构在参数量和计算量都有所节省。
宏观上,本发明使用26层网络结构,每层结构称作一个单元,按顺序包括:卷积层,批归一化层,修正线性单元(rectifiedlinearunit,relu),其中26层网络还可以看成13个mobile模块,每个模块由一个深度分离卷积单元和一个1x1卷积单元组成。
细节上,假设输入特征图大小为sfxsfxin,经过一次卷积,输出的特征图大小为sfxsfxout,传统的卷积操作,其卷积核k的大小为:skxskxinxout,其中sf是特征图的尺寸,sk是卷积核的尺寸,in是输入特征图的通道数,out是输出特征图的通道数,一次卷积操作的过程如下:in个skxsk个卷积核与in个输入特征图做卷积,得到的结果相加,得到一张输出特征图,同理,一共out次操作,得到out个输出特征图,用公式表示这个过程如下:
根据公式,可以计算出传统卷积层的计算量为:
skxskxinxoutxsfxsf
参数量为:
skxskxinxout
对应一次传统卷积的是个mobile模块(深度分离卷积+1x1卷积),其中深度分离卷积的具体实现如下:其卷积核k的大小为:skxskxin,卷积核只跟对应通道的输入特征图做卷积,得到输出特征图,所以输出的特征图大小为sfxsfxin,用公式表示这个过程如下:
根据公式,可以计算出深度分离卷积的计算量为:
skxskxinxsfxsf
参数量为:
skxskxin
深度分离卷积之后,是一层传统的批归一化层,和激活层,然后是1x1卷积层,1x1卷积层的卷积核大小为1x1xinxout,操作跟传统卷积一致,计算量为1x1xinxoutxsfxsf,参数量为1x1xinxout。
综上,mobile模块(mobilenets网络结构)总的计算量为:skxskxinxsfxsf+1x1xinxoutxsfxsf=(skxsk+out)xinxsfxsf,参数量:skxskxin+1x1xinxout=(skxsk+out)xin,相比传统卷积,计算量是(skxsk+out)/skxskxout=1/out+1/(skxsk),参数量是(skxsk+out)/skxskxout=1/out+1/(skxsk),在计算量和参数量都有所减少。
本申请的方法相比原版maskrcnn,模型大小为27m,原版maskrcnn模型大小为256m,减少为原本的1/10,同时速度提升了将近30倍,准确率降低5%。
2)多尺度网络结构设计:为了增加网络的多尺度,在mobilenets的基础上结合了fpn结构,具体实施时,比如,fpn的特征图金字塔选取的特征图分别来自mobilenets的13个模块中的第3模块,第5模块,第11模块和第14模块的输出,具体的操作与传统fpn一致,如此,网络结构便具有多尺度的特性。
3)损失函数设计:损失函数一共由5部分组成,分别包括rpn的类别损失,rpn的回归框损失,fastrcnn的类别损失,fastrcnn的回归框损失,mask分支的像素点类别损失,其中mask分支输出大小为28x28,分别对28x28个像素点做分类。
4)训练过程:训练分成3部分:1.分主干网络预训练,本发明使用imagenet数据集进行预训练,输入图片大小为224x224,批大小为128,初始学习率为0.1;2.整个mmrcnn在微软coco数据集上训练,得到一个能实例分割80类的模型,输入图片大小为1024x1024,批大小为2,初始学习率为0.01;3.针对具体的任务的数据集进行微调训练,数据集不限,需要包括图片中需分割的物体的类别,位置,轮廓,输入大小为1024x1024,初始学习率为0.001。
5)测试过程:测试过程与训练过程的不同在于,训练过程fastrcnn分支与mask分支是并行训练,两个分支的输入都是rpn的输出,而测试时,fastrcnn的输出仍然时rpn的输出,而mask分支的输入为fastrcnn的输出。
显然,本领域的技术人员应该明白,上述的本申请的各模块或各步骤可以用通用的计算装置来实现,它们可以集中在单个的计算装置上,或者分布在多个计算装置所组成的网络上,可选地,它们可以用计算装置可执行的程序代码来实现,从而,可以将它们存储在存储装置中由计算装置来执行,或者将它们分别制作成各个集成电路模块,或者将它们中的多个模块或步骤制作成单个集成电路模块来实现。这样,本申请不限制于任何特定的硬件和软件结合。
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!