一种基于多重余弦定理的文章相关度计算方法与流程
本发明涉及一种基于多重余弦定理的文章相关度计算方法,属于信息处理技术领域。
背景技术
文章相关度的计算是信息处理领域中的一项基本研究工作,主要应用于文章分类、推荐等。
目前,对文章相关度的研究方法主要分为两类:基于统计学和基于语义分析。这两类方法都有各自的优缺点,其中基于统计学的方法需要大量文章作为训练,基于语义分析的方法则需要提前准备较为完整的语义词典。但是现阶段,利用计算机对文章相关度的计算这一技术并不成熟,准确性欠佳、灵活性差等现象一直存在,在很多情况下还需要人工对其进行计算、估计。
技术实现要素:
本发明要解决的技术问题是针对现有技术的局限和不足,提供一种基于多重余弦定理的文章相关度计算方法,主要解决利用计算机对文章相关度的计算这一技术准确性欠佳、灵活性差等现象。
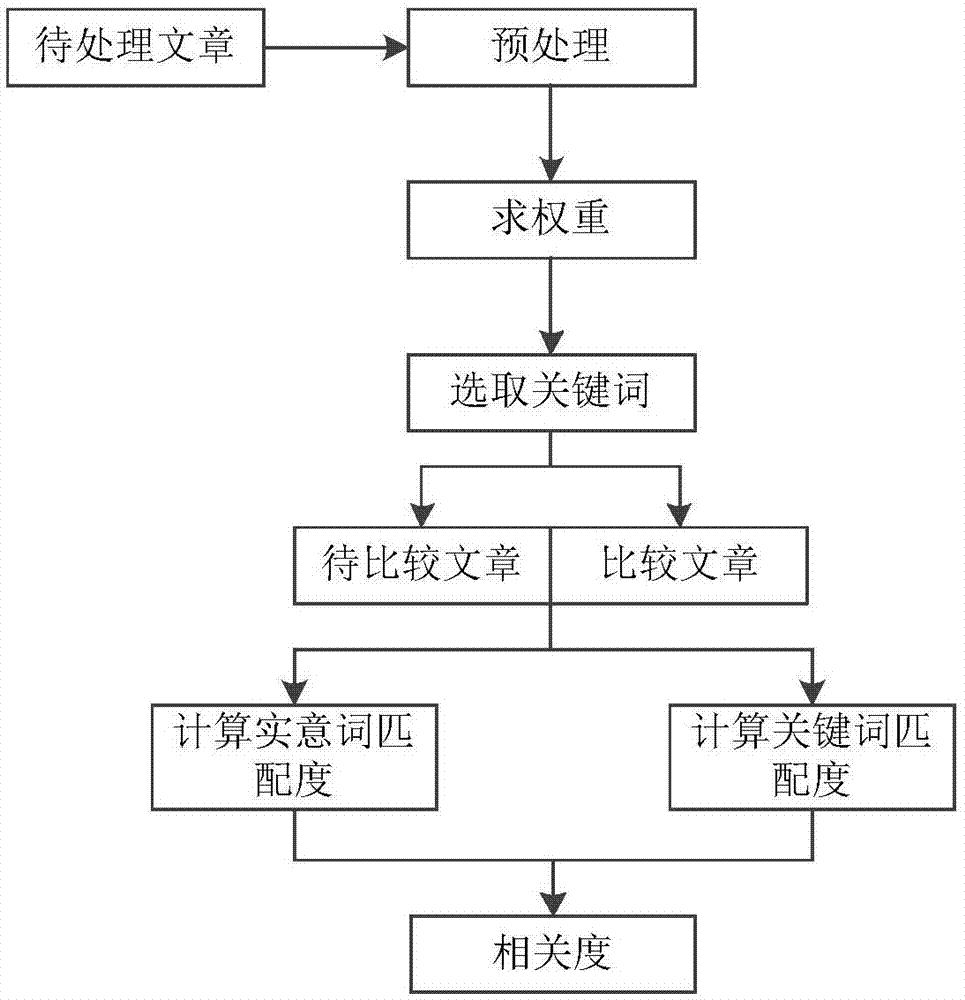
本发明的技术方案是:一种基于多重余弦定理的文章相关度计算方法,该方法具体包括以下步骤:
step0:获取文章集合{x1,x2…xp},对文章x,x∈{x1,x2…xp}进行预处理,并建立文章数据库,具体如step0.1~step0.4所示;
step0.1:对文章x进行分词、去停用词、同义词替换等操作,生成文章的实意词集合x:{x1,x2…xm};
step0.2:以tfidf值为主,该文章中出现该词的词频、词性、词长为辅,遍历step0.1中得到的实意词集合x:{x1,x2…xm},对每个实意词xi,i∈[1,m]求其权重,并生成实意词权重集合y:{y1,y2…ym};
step0.3:以实意词xi,i∈[1,m]为key,权重yi,i∈[1,m]为value,对step0.2中得到的实意词权重yi,i∈[1,m]排序,选取权重最高的n个实意词作为关键词,并生成关键词集合x':{x1',x2'…xn'}和关键词权重集合y':{y1',y2'…yn'};
step0.4:将文章x、实意词集合x:{x1,x2…xm}、实意词权重集合y:{y1,y2…ym}、关键词集合x':{x1',x2'…xn'}及关键词权重集合y':{y1',y2'…yn'}作为元组加入文章数据库;
step1:从文章数据库中获取待比较文章t和比较文章h;
step2:以待比较文章t的实意词集合xt:{t1,t2…tm}和实意词权重集合yt:{y1,y2…ym},生成实意词特征向量ft={ft1,ft2…ftg},同样对比较文章h也以此生成实意词特征向量fh={fh1,fh2…fhg},由余弦定理计算公式(1)确定待比较文章t与比较文章h之间的实意词相关度r1(t,h);
step3:以待比较文章t的关键词集合xt':{t1',t2'…tn'}和关键词权重集合yt':{y1',y2'…yn'},生成关键词特征向量ft'={ft'1,ft'2…ft'g},同样对比较文章h也以此生成关键词特征向量fh'={fh'1,fh'2…fh'g},由余弦定理计算公式(2)确定待比较文章t与比较文章h之间的关键词相关度r2(t,h);
step4:依照公式(3)计算待比较文章t与比较文章h之间的最终相关度r(t,h),其中γ为阈值参数。
进一步地,所述步骤step0.1中,对文本进行分词、去停用词、同义词替换等操作,可以采用分词包、停用词库、同义词库等。
进一步地,所述步骤step0.2中由公式(4)求其权重;式(4)中
wtfidf>wfre>wpro>wlen>0,且wtfidf+wpro+wlen+wfre=1(5)
进一步地,所述步骤step0.2中,先对词xi,i∈[1,m]查语义词典,获取该词所属词性,对于不同词性的词xi,i∈[1,m],其对应的词性转化值
pron>porv>poradj>porother>0(6)
进一步地,所述步骤step0.2和step0.3中,实意词集合x:{x1,x2…xm}和关键词集合x':{x1',x2'…xn'}应满足公式(7)的要求;式(7)中n值可根据实际分类情况调整,以提高准确性。
m>n>0(7)
进一步地,所述步骤step0(包括step0.1~step0.4)属初始化步骤,在常规计算时只需进行step1~step4即可;若有新增文章,需对新增文章进行步骤step0操作,也可设置为自动学习方式进行。
进一步地,所述步骤step2中,实意词特征向量ft={ft1,ft2…ftg}的长度g为待比较文章t的实意词集合xt:{t1,t2…tm}和比较文章h的实意词集合xh:{h1,h2…hm}的并集集合长度;
g=len(xt∪xh)(8)
同样,所述步骤step3中关键词特征向量ft'={ft'1,ft'2…ft'g}的长度g为待比较文章t的关键词集合xt':{t1',t2'…tn'}和比较文章h的关键词集合xh':{h1',h2'…hm'}的并集集合长度。
g=len(xt'∪xh')(9)
进一步地,所述步骤step2和step3中,计算所得的实意词匹配度r1(t,h)和关键词匹配度r2(t,h)理应满足公式(10)的要求,若不满足,则视为计算错误,需重新计算。
进一步地,所述步骤step4中,阈值参数γ可根据实际计算情况调整其值,以提高准确性。
本发明的有益效果是:解决了现有技术准确性欠佳、分类易出错、灵活性差等现象,增加了目前利用计算机对文章相关度计算的准确性。
附图说明
图1是本发明的流程示意图;
图2是本发明预处理流程示意图;
图3是本发明求权重流程示意。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种基于多重余弦定理的文章相关度计算方法,将文章映射为实意词向量和关键词向量,并重新规划词权重,再利用多重余弦定理对现阶段的文章相关度计算方法进行改进。摒弃单纯利用tfidf值做词权重的方法,而是创新性地将tfidf值、词频、词性、词长等加权累加;另一方面,对文章计算其相关度还使用了多重余弦定理,分别对其计算实意词相关度和关键词相关度,再由相关定义确定其最终相关度。
具体包括以下步骤:
step0:获取文章集合{x1,x2…xp},对文章x,x∈{x1,x2…xp}进行预处理,并建立文章数据库,具体如step0.1~step0.4所示;
step0.1:对文章x进行分词、去停用词、同义词替换等操作,生成文章的实意词集合x:{x1,x2…xm};
step0.2:以tfidf值为主,该文章中出现该词的词频、词性、词长为辅,遍历step0.1中得到的实意词集合x:{x1,x2…xm},对每个实意词xi,i∈[1,m]求其权重,并生成实意词权重集合y:{y1,y2…ym};
step0.3:以实意词xi,i∈[1,m]为key,权重yi,i∈[1,m]为value,对step0.2中得到的实意词权重yi,i∈[1,m]排序,选取权重最高的n个实意词作为关键词,并生成关键词集合x':{x1',x2'…xn'}和关键词权重集合y':{y1',y2'…yn'};
step0.4:将文章x、实意词集合x:{x1,x2…xm}、实意词权重集合y:{y1,y2…ym}、关键词集合x':{x1',x2'…xn'}及关键词权重集合y':{y1',y2'…yn'}作为元组加入文章数据库;
step1:从文章数据库中获取待比较文章t和比较文章h;
step2:以待比较文章t的实意词集合xt:{t1,t2…tm}和实意词权重集合yt:{y1,y2…ym},生成实意词特征向量ft={ft1,ft2…ftg},同样对比较文章h也以此生成实意词特征向量fh={fh1,fh2…fhg},由余弦定理计算公式(1)确定待比较文章t与比较文章h之间的实意词相关度r1(t,h);
step3:以待比较文章t的关键词集合xt':{t1',t2'…tn'}和关键词权重集合yt':{y1',y2'…yn'},生成关键词特征向量ft'={ft'1,ft'2…ft'g},同样对比较文章h也以此生成关键词特征向量fh'={fh'1,fh'2…fh'g},由余弦定理计算公式(2)确定待比较文章t与比较文章h之间的关键词相关度r2(t,h);
step4:依照公式(3)计算待比较文章t与比较文章h之间的最终相关度r(t,h),其中γ为阈值参数。
进一步地,所述步骤step0.1中,对文本进行分词、去停用词、同义词替换等操作,可以采用分词包、停用词库、同义词库等。
进一步地,所述步骤step0.2中由公式(4)求其权重;式(4)中
wtfidf>wfre>wpro>wlen>0,且wtfidf+wpro+wlen+wfre=1(5)
进一步地,所述步骤step0.2中,先对词xi,i∈[1,m]查语义词典,获取该词所属词性,对于不同词性的词xi,i∈[1,m],其对应的词性转化值
pron>porv>poradj>porother>0(6)
进一步地,所述步骤step0.2和step0.3中,实意词集合x:{x1,x2…xm}和关键词集合x':{x1',x2'…xn'}应满足公式(7)的要求;式(7)中n值可根据实际分类情况调整,以提高准确性。
m>n>0(7)
进一步地,所述步骤step0(包括step0.1~step0.4)属初始化步骤,在常规计算时只需进行step1~step4即可;若有新增文章,需对新增文章进行步骤step0操作,也可设置为自动学习方式进行。
进一步地,所述步骤step2中,实意词特征向量ft={ft1,ft2…ftg}的长度g为待比较文章t的实意词集合xt:{t1,t2…tm}和比较文章h的实意词集合xh:{h1,h2…hm}的并集集合长度;
g=len(xt∪xh)(8)
同样,所述步骤step3中关键词特征向量ft'={ft'1,ft'2…ft'g}的长度g为待比较文章t的关键词集合xt':{t1',t2'…tn'}和比较文章h的关键词集合xh':{h1',h2'…hm'}的并集集合长度。
g=len(xt'∪xh')(9)
进一步地,所述步骤step2和step3中,计算所得的实意词匹配度r1(t,h)和关键词匹配度r2(t,h)理应满足公式(10)的要求,若不满足,则视为计算错误,需重新计算。
进一步地,所述步骤step4中,阈值参数γ可根据实际计算情况调整其值,以提高准确性。
本发明将词长也作为衡量词权重的一个指标。据研究,中文词语长度服从一定条件下的χ2分布,也就是说,长度越长的词汇,越不容易出现在文本中,这也就决定了长度越长的词汇具有很好的类区分能力。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!