一种基于特征向量和笔顺编码的汉字字形相似算法的制作方法
本发明涉及一种基于特征向量和笔顺编码的汉字字形相似算法,属于汉语信息处理技术领域。
背景技术:
文字是人类进行信息交流的主要工具,但由于许多汉字存在形体相似导致错识、错识,所以正确区分出这些易混淆的形近字对汉语教学、汉文编辑、排版、汉文机器识别、汉语广播等业务具有重要意义。
目前,针对汉字字形相似的算法主要分为两类:一类是获取汉字的基础信息,如字形结构、笔画数、笔画顺序等,将这些数据按照一定的编码规则生成数学表达式,再利用特定算法通过对数学表达式的处理进而获得汉字的字形相似度;另一类是采用图像处理技术提取汉字特征,对比差异化特征。但是这两类方法都有各自的缺陷,若使用第一类方法,需设定一些系数来平衡最终的输出结果;若使用第二类方法,对于一些复合字的相似度计算结果较差。
技术实现要素:
本发明要解决的技术问题是针对现有技术的局限和不足,提供一种基于特征向量和笔顺编码的汉字字形相似算法,以解决现有技术准确性欠佳、灵活性差等现象,致力于增加目前依靠计算机进行汉字字形相似度计算的准确性。
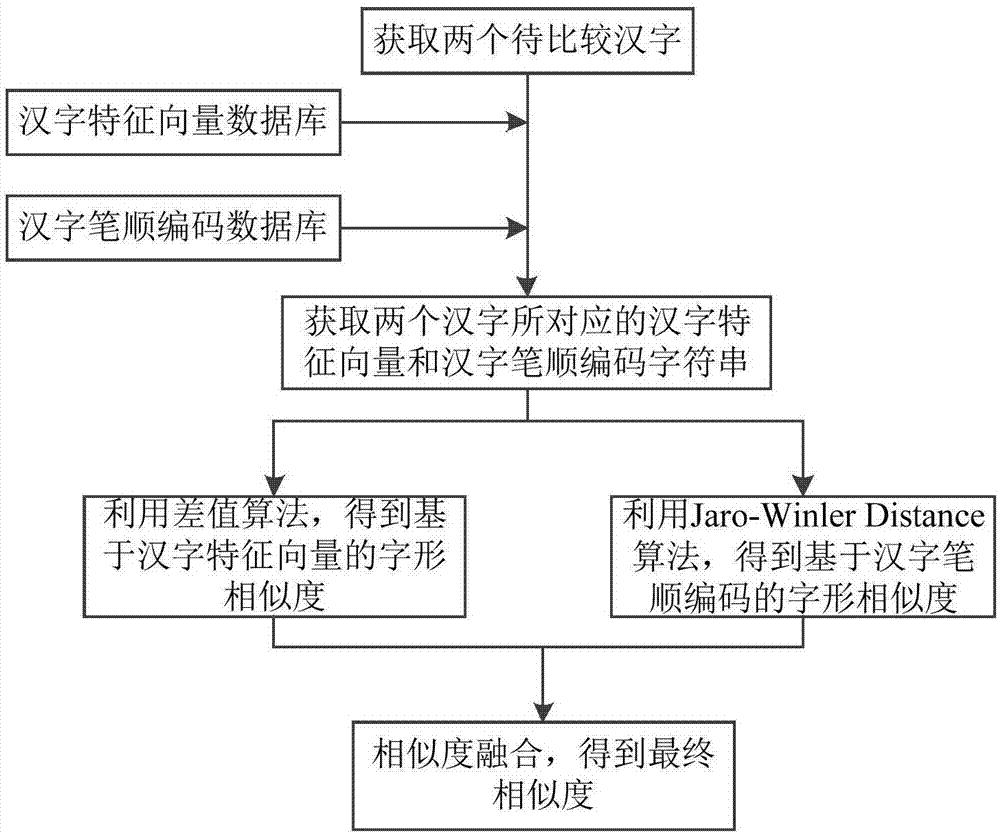
本发明的技术方案是:一种基于特征向量和笔顺编码的汉字字形相似算法,具体步骤为:
step0.1:从ttc字体文件中提取出每个汉字所对应的图片,即汉字图片大小为l×w(单位为像素点),共计n个像素点;将汉字图片作为输入源,生成该汉字所对应的汉字矩阵il×w,该矩阵中的元素值即为该像素点的灰度值;定义ξ为灰度二值化阈值,对矩阵进行公式(1)所示二值化处理,之后将矩阵il×w按照从左至右、从上至下的规则生成该汉字所对应的特征向量{x1,x2,…,xn};将所有汉字及生成的汉字特征向量存入数据库,组建汉字特征向量数据库;
step0.2:按照汉字五笔书写顺序规则,将横、竖、撇、捺、折编码为字母a、b、c、d、e,生成该汉字所对应的笔顺编码字符串x1x2…xz,其中z为该汉字的笔画数,xi为该汉字第i笔的笔画,并且xi∈{a,b,c,d,e},i∈[1,z];将所有汉字及生成的汉字笔顺编码字符串存入数据库,组建汉字笔顺编码数据库;
step1:记x、y为两个将要计算字形相似度的汉字,从汉字特征向量数据库中分别调取这两个汉字所对应的汉字特征向量x:{x1,x2,…,xn}和y:{y1,y2,…,yn},从汉字笔顺编码数据库中分别调取这两个汉字所对应的汉字笔顺编码字符串strx和stry;
step2:将汉字特征向量x:{x1,x2,…,xn}和y:{y1,y2,…,yn}作为输入,由差值算法求得汉字x、y之间基于特征向量的字形相似度sim1(x,y);
step2.1:定义zi=xi-yi,i∈[1,n],生成汉字x、y所对应的差值特征向量
step2.2:通过差值计算公式(2)求得汉字x、y之间基于特征向量的字形相似度sim1(x,y);
step3:将汉字笔顺编码字符串strx和stry作为输入,由jaro-winklerdistance算法求得汉字x、y之间基于笔顺编码的字形相似度sim2(x,y);
step3.1:获取汉字笔顺编码字符串strx和stry的长度lenx和leny,并生成检测矩阵i(x,y)lenx×leny;
step3.2:根据公式(3)计算匹配窗口值mw;
step3.3:由检测矩阵
step3.4:获取汉字笔顺编码字符串strx和stry的最长公共子串strxy,并得到其长度lenxy,根据公式(5)进一步计算汉字笔顺编码字符串strx和stry之间的jaro-winklerdistance,该值即为汉字x、y之间基于笔顺编码的字形相似度sim2(x,y);
其中,bt为是否需要进一步计算的阈值,p为缩放因子;
step4:设step2、step3步骤所计算出的相似度对应权值分别为α、β,权值α、β满足α+β=1的要求,由基于特征向量的字形相似度sim1(x,y)及权值α、基于笔顺编码的字形相似度sim2(x,y)及权值β,由相似度融合算法,即公式(6)计算出汉字x、y之间的最终字形相似度sim(x,y);
sim(x,y)=sim1(x,y)·α+sim2(x,y)·β(6)
进一步地,所述步骤step0.1中,汉字图片大小l×w是由字体文件中提取的汉字字体大小决定;并且汉字矩阵il×w中的元素值i(i,j)、灰度二值化阈值ξ满足公式(7)的要求。
0≤i(i,j),ξ≤255,i∈[1,l],j∈[1,w](7)
进一步地,所述步骤step3.1中汉字笔顺编码字符串strx、stry的长度lenx、leny应满足公式(8)的要求。
lenx,leny∈n+(8)
进一步地,所述步骤step3.3中匹配字符数m的计算,若汉字笔顺编码字符串strx和stry中相同字符相差距离小于匹配窗口值mw,则视为该字符匹配。但应注意,在匹配过程中,需排除被匹配过的字符,若找到匹配字符,则需跳出此次匹配,进行下一字符的匹配。而对于匹配字符换位数n的计算,则需看汉字笔顺编码字符串strx和stry中对于匹配字符集的顺序是否一致,若不一致,则换位数目的一半即为匹配字符换位数n。另外,匹配字符数m和匹配字符换位数n理应满足公式(9)的要求。
进一步地,步骤step3.4中所述进一步计算阈值bt,通常取值为0.7,可根据实际检测结果作小幅度调整,主要是为了提高检测准确性;所述缩放因子p,通常取值为0.1,可根据实际检测结果做小幅度调整,主要是为了避免最终计算结果大于1的情况发生,但本方法新增编码字符串strx和stry中最长距离的倒数
进一步地,所述步骤step2中得到的基于汉字特征向量的字形相似度sim1(x,y)、所述步骤step3中得到的基于汉字笔顺编码的字形相似度sim2(x,y)、所述步骤step4中得到的最终字形相似度sim(x,y),应满足公式(10)的要求,即字形相似度sim1(x,y)、sim2(x,y)、sim(x,y)以一个[0,1]之间的数值反映两个汉字之间的相似程度,且数值越大表示相似程度越高。
0≤sim1(x,y),sim2(x,y),sim(x,y)≤1(10)
本发明的有益效果是:解决了现有技术准确性欠佳、灵活性差等现象,增加了目前依靠计算机进行汉字字形相似度计算的准确性。
附图说明
图1是本发明流程示意图;
图2是本发明建立数据库流程示意图;
图3是本发明所生成的微软雅黑字体汉字图片示意图。
具体实施方式
下面结合附图和具体实施方式,对本发明作进一步说明。
实施例1:如图1-3所示,一种基于特征向量和笔顺编码的汉字字形相似算法,利用汉字结构、轮廓、笔画、书写顺序等特征,建立汉字特征向量数据库和汉字笔顺编码数据库,对任意两个汉字调取其汉字特征向量和汉字笔顺编码字符串,通过差值算法计算出基于汉字特征向量的字形相似度,通过jaro-winklerdistance算法计算出基于汉字笔顺编码的字形相似度,两个相似度分别从不同方面反映了汉字的相似程度,吸取两种算法的优势对其进行融合,得到最终相似度。
具体包括以下步骤:
step0.1:从ttc字体文件中提取出每个汉字所对应的图片,即汉字图片大小为l×w(单位为像素点),共计n个像素点;将汉字图片作为输入源,生成该汉字所对应的汉字矩阵il×w,该矩阵中的元素值即为该像素点的灰度值;定义ξ为灰度二值化阈值,对矩阵进行公式(1)所示二值化处理,之后将矩阵il×w按照从左至右、从上至下的规则生成该汉字所对应的特征向量{x1,x2,…,xn};将所有汉字及生成的汉字特征向量存入数据库,组建汉字特征向量数据库;
具体的:以微软雅黑ttc字体作为输入源,提取出的汉字图片大小为64×64像素,共计n=4096个像素点,并取灰度二值化阈值ξ=1;
step0.2:按照汉字五笔书写顺序规则,将横、竖、撇、捺、折编码为字母a、b、c、d、e,生成该汉字所对应的笔顺编码字符串x1x2…xz,其中z为该汉字的笔画数,xi为该汉字第i笔的笔画,并且xi∈{a,b,c,d,e},i∈[1,z];将所有汉字及生成的汉字笔顺编码字符串存入数据库,组建汉字笔顺编码数据库;
step1:记x、y为两个将要计算字形相似度的汉字,从汉字特征向量数据库中分别调取这两个汉字所对应的汉字特征向量x:{x1,x2,…,xn}和y:{y1,y2,…,yn},从汉字笔顺编码数据库中分别调取这两个汉字所对应的汉字笔顺编码字符串strx和stry;
具体的:记汉字x为“钢”,汉字y为“铟”,从汉字特征向量数据库中分别调取这两个汉字所对应的汉字特征向量,即
x={0,0,0,…,1,0,0,…,1,1,0,…,0,0,0}
y={0,0,0,…,0,1,0,…,1,0,1,…,0,0,0}
另外,从汉字笔顺编码数据库中分别调取这两个汉字所对应的汉字笔顺编码字符串strx=caaaebecd、stry=caaaebeacda;
step2:将汉字特征向量x:{x1,x2,…,xn}和y:{y1,y2,…,yn}作为输入,由差值算法求得汉字x、y之间基于特征向量的字形相似度sim1(x,y);
step2.1:定义zi=xi-yi,i∈[1,n],生成汉字x、y所对应的差值特征向量
具体的:
step2.2:通过差值计算公式(2)求得汉字x、y之间基于特征向量的字形相似度sim1(x,y);
具体的:
step3:将汉字笔顺编码字符串strx和stry作为输入,由jaro-winklerdistance算法求得汉字x、y之间基于笔顺编码的字形相似度sim2(x,y);
step3.1:获取汉字笔顺编码字符串strx和stry的长度lenx和leny,并生成检测矩阵i(x,y)lenx×leny;
具体的:
step3.2:根据公式(3)计算匹配窗口值mw;
具体的:
step3.3:由检测矩阵
具体的:
disj=0.9394
step3.4:获取汉字笔顺编码字符串strx和stry的最长公共子串strxy,并得到其长度lenxy,根据公式(5)进一步计算汉字笔顺编码字符串strx和stry之间的jaro-winklerdistance,该值即为汉字x、y之间基于笔顺编码的字形相似度sim2(x,y);
其中,bt为是否需要进一步计算的阈值,p为缩放因子;
具体的:取bt=0.7,p=0.1,则最长公共子串lenxy=caaaebe,其长度lenxy=7;
sim2(x,y)=disjw=0.9779
step4:设step2、step3步骤所计算出的相似度对应权值分别为α、β,权值α、β满足α+β=1的要求,由基于特征向量的字形相似度sim1(x,y)及权值α、基于笔顺编码的字形相似度sim2(x,y)及权值β,由相似度融合算法,即公式(6)计算出汉字x、y之间的最终字形相似度sim(x,y);
sim(x,y)=sim1(x,y)·α+sim2(x,y)·β(6)
取权值α=0.5,β=0.5,经融合后最终相似度为:
由以上结果可以表明,汉字“钢”和“铟”的最终计算所得字形相似度为0.9188,相对于单独使用特征向量得到的相似度(0.8596),既不显得粗糙,又较为合理;相对于单独使用笔顺编码得到的相似度(0.9779),既不显得不那么浮夸,又较符合基于人体视觉判定的效果。
另外,关于相似度sim1(x,y)、sim2(x,y)对应权值的取值α、β,应以实际情况进行多次检测、适当调整后合理取值。
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
- 还没有人留言评论。精彩留言会获得点赞!