文字识别模型建立及文字识别方法、装置、介质及设备与流程
本发明的实施方式涉及信息处理领域,更具体地,本发明的实施方式涉及一种文字识别模型建立及文字识别方法、装置、介质及设备。
背景技术:
文字识别技术是一种利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。随着互联网技术、信息技术的高速发展,以及人工智能在人们日常工作、生活中的普及,越来越多的领域离不开文字识别。从某种意义上讲,文字识别结果的准确性越高,能够使得其他相关领域越加进步、智能。
技术实现要素:
但是,在现有的文字识别技术中,当需要对长度不一的文字行进行识别时,其识别准确度往往较低。
因此在现有技术中,在对长度不一的文字行进行识别时,通常需要将一行文字采用某种方法进行切割,然后对切割后的文字一个一个进行识别,又或者采用其他诸如显示滑动窗口操作、或将所有的文字行拉长到同一个长度进行识别等方法来进行识别。
然而,以上这些现有方法在对长度不一的文字行进行识别的过程中都牺牲了识别结果的准确度,这是非常令人烦恼的过程。
为此,非常需要一种改进的文字识别方法,以使对长度不一的文字行进行识别时能够提高识别结果的准确度,在本上下文中,本发明的实施方式期望提供一种文字识别模型建立及文字识别方法、装置、介质及设备。
在本发明实施方式的第一方面中,提供了一种文字识别模型建立方法,包括:获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息;根据所述每一个行文字图像的长度信息与所述行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值;将所述文字预测值与预先设置的标准结果值进行对比得到偏差值;根据所述偏差值及预设的损失函数对所述cnn、所述变长rnn及所述fc的模型参数进行校正,直到所述偏差值小于或等于预定阈值,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。
在本发明的一个实施例中,所述行文字图像集合中每一个行文字图像的高度为固定值h0,h0>0。
在本发明的另一个实施例中,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值,包括:通过所述cnn获取所述行文字图像集合的第一特征数据;将所述第一特征数据输入所述变长rnn计算得到第二特征数据;将所述第二特征数据输入所述fc计算得到所述文字预测值。
在本发明的又一个实施例中,根据所述偏差值及预设的损失函数对所述cnn、所述变长rnn及所述fc的模型参数进行校正,包括:根据所述偏差值及所述预设的损失函数,按照梯度反向传递方式依次对所述fc的第三模型参数、所述变长rnn的第二模型参数及所述cnn的第一模型参数进行校正。应当理解的是,这里所说的第一模型参数与下文中示例性方法2中将要提到的第一模型无关联,这里所说的第一模型参数是指cnn中的模型参数,而并非指示例性方法2中将要提到的第一模型中的参数。类似地,这里所说的第二模型参数、第三模型参数也分别与下文中示例性方法2中将要提到的第二模型、第三模型无关联,这里所说的第二、第三模型参数分别指变长rnn、fc中的模型参数,而并非指示例性方法2中将要提到的第二、第三模型中的参数。
在本发明的再一个实施例中,在获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息之前,所述建立方法还包括:对包含有文字的图像进行文字区域检测,得到所述文字所在的行区域;截取所述行区域作为所述行文字图像。
在本发明的再一个实施例中,所述行文字图像为单排文字图像,所述单排文字图像包括一个或多个字符。
在本发明的再一个实施例中,所述行文字图像集合包括第一子集,所述第一子集包括字符水平排列的行文字图像;所述第一子集中所有字符的高度方向与字符排列方向垂直。
在本发明的再一个实施例中,所述第一子集中所有字符的顶部朝上;或,所述第一子集中所有字符的顶部朝下;或,所述第一子集中部分字符的顶部朝上且部分字符的顶部朝下。
在本发明的再一个实施例中,所述行文字图像集合包括第二子集,所述第二子集包括字符竖直排列的行文字图像;所述第二子集中所有字符的高度方向与字符排列方向平行。
在本发明的再一个实施例中,所述行文字图像集合包括第三子集,所述第三子集包括一个或多个字符按任意方向排列的行文字图像;所述第三子集包括其中至少部分字符的高度方向与排列方向既不垂直也不平行的行文字图像。
在本发明的再一个实施例中,所述行文字图像集合中至少部分行文字图像的长度不同。
在本发明的再一个实施例中,所述行文字图像集合包括经过增强处理的行文字图像,所述增强处理包括锐化、错切、模糊及预定幅度旋转至少其中之一。
在本发明的再一个实施例中,所述行文字图像集合的第一特征数据包括每个行文字图像对应的多个特征图和特征图参数,每个行文字图像对应的特征图参数包括与缩放后的该行文字图像的高度对应的第一参数、与缩放后的该行文字图像的长度对应的第二参数以及第三参数,所述第三参数表示所述卷积神经网络针对所述行文字图像集合中每个行文字图像所提取的特征图个数。
在本发明的再一个实施例中,所述第一参数的值为1;所述特征图参数包括仅基于所述第二参数和第三参数表示的数据。
在本发明的再一个实施例中,在将所述第一特征数据输入所述变长rnn计算得到第二特征数据的步骤之前,还包括:对仅基于所述第二参数和第三参数表示的数据进行维度转换,以使所述第二参数对应于每个行文字图像循环经过所述变长rnn的次数,使所述第三参数对应于每个行文字图像的输入数据维度。
在本发明实施方式的第二方面中,提供了一种存储有程序的存储介质,所述程序被处理器执行时实现上述文字识别模型建立方法。
在本发明实施方式的第三方面中,提供了一种文字识别方法,包括权利要求1至15中任一项所述的文字识别模型建立方法,还包括:检测待识别图像得到n个文字行图以及每个所述文字行图的长度数据,n为正整数;接收输入所述文字识别模型的所述n个文字行图以及所述n个文字行图的长度数据;对所述文字识别模型输出的结果进行归一化并解码,获得解码后所述n个文字行图各自对应的字符串;通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果。
在本发明的一个实施例中,通过对所述文字识别模型输出的结果进行归一化并解码,还获得解码后所述n个文字行图各自对应的字符串中每个字符的识别概率;其中,所述的通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果的步骤包括:针对每个文字行图对应的解码后的字符串,基于字符的识别概率对该字符串中的字符进行过滤,利用过滤后余下的字符形成该文字行图的识别结果,以通过拼接获得所述待识别图像的文字识别结果。
在本发明的另一个实施例中,当所述待识别图像为水平排列的文字图片时,采用第一模型作为所述文字识别模型,其中,所述第一模型是利用包含有所述第一子集的所述行文字图像集合进行训练得到的;当所述待识别图像为竖直排列的文字图片时,采用第二模型作为所述文字识别模型,其中,所述第二模型是利用包含有所述第二子集的所述行文字图像集合进行训练得到的;当所述待识别图像为任意方向排列的文字图片时,采用第三模型作为所述文字识别模型,其中,所述第三模型是利用包含有所述第三子集的所述行文字图像集合进行训练得到的。
在本发明的又一个实施例中,对该字符串中的字符进行过滤的步骤包括:将识别概率小于或等于预设概率阈值的字符筛除。
在本发明的再一个实施例中,所述待识别图像包括字符水平竖直混合排列的文字图片;所述待识别图像的文字识别结果通过如下方式获得:将由所述待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组;分别采用第一模型和第二模型获得所述原图像组的两组文字识别结果以及所述预处理后图像组的两组文字识别结果,作为所述待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;针对所述待识别图像的四组文字识别结果中的每一组,根据该组文字识别结果对应的多个字符串中每个字符的识别概率,获得该多个字符串的平均识别概率作为该组文字识别结果的识别概率;在通过所述第一模型获得的两组文字识别结果中选择识别概率较大的一组作为第一候选结果,及在通过所述第二模型获得的两组文字识别结果中选择识别概率较大的一组作为第二候选结果;根据所述第一候选结果和所述第二候选结果的识别概率获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述根据所述第一候选结果和所述第二候选结果的识别概率获得所述待识别图像的文字识别结果的步骤包括:设定水平阈值,在所述第一候选结果中仅保留识别概率大于该水平阈值的字符,设定竖直阈值,在所述第二候选结果中仅保留识别概率大于该竖直阈值的字符,通过对所述第一候选结果与所述第二候选结果中保留的字符进行拼接,获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述待识别图像包括字符水平竖直混合排列的文字图片,所述待识别图像的文字识别结果通过如下方式获得:将由所述待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组;分别采用第一模型和第二模型获得所述原图像组的两组文字识别结果以及所述预处理后图像组的两组文字识别结果,作为所述待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;设定概率阈值,在所述四组文字识别结果中仅保留识别概率大于所述概率阈值的字符,通过对所述四组文字识别结果中保留的字符进行拼接,获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述n个文字行图的长度部分或全部不同。
在本发明的再一个实施例中,所述文字行图包括图像高度被缩放为预设固定值的图像。
在本发明实施方式的第四方面中,提供了一种存储有程序的存储介质,所述程序被处理器执行时实现上述文字识别方法。
在本发明实施方式的第五方面中,提供了一种文字识别模型建立装置,包括:信息获取单元,适于获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息;模型构建单元,适于根据所述每一个行文字图像的长度信息与所述行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值;对比单元,适于将所述文字预测值与预先设置的标准结果值进行对比得到偏差值;校正单元,适于根据所述偏差值及预设的损失函数对所述cnn、所述变长rnn及所述fc的模型参数进行校正,直到所述偏差值小于或等于预定阈值,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。
在本发明的一个实施例中,所述行文字图像集合中每一个行文字图像的高度为固定值h0,h0>0。
在本发明的另一个实施例中,所述模型构建单元包括:cnn处理子单元,适于通过所述cnn获取所述行文字图像集合的第一特征数据;变长rnn处理子单元,适于将所述第一特征数据输入所述变长rnn计算得到第二特征数据;fc处理子单元,适于将所述第二特征数据输入所述fc计算得到所述文字预测值。
在本发明的又一个实施例中,所述校正单元适于通过如下方式实现对所述cnn、所述变长rnn及所述fc的模型参数的校正:根据所述偏差值及所述预设的损失函数,按照梯度反向传递方式依次对所述fc的第三模型参数、所述变长rnn的第二模型参数及所述cnn的第一模型参数进行校正。
在本发明的再一个实施例中,所述建立装置还包括:预处理单元,适于在获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息之前,对包含有文字的图像进行文字区域检测,得到所述文字所在的行区域;以及截取所述行区域作为所述行文字图像。
在本发明的再一个实施例中,所述行文字图像为单排文字图像,所述单排文字图像包括一个或多个字符。
在本发明的再一个实施例中,所述行文字图像集合包括第一子集,所述第一子集包括字符水平排列的行文字图像;所述第一子集中所有字符的高度方向与字符排列方向垂直。
在本发明的再一个实施例中,所述第一子集中所有字符的顶部朝上;或,所述第一子集中所有字符的顶部朝下;或,所述第一子集中部分字符的顶部朝上且部分字符的顶部朝下。
在本发明的再一个实施例中,所述行文字图像集合包括第二子集,所述第二子集包括字符竖直排列的行文字图像;所述第二子集中所有字符的高度方向与字符排列方向平行。
在本发明的再一个实施例中,所述行文字图像集合包括第三子集,所述第三子集包括一个或多个字符按任意方向排列的行文字图像;所述第三子集包括其中至少部分字符的高度方向与排列方向既不垂直也不平行的行文字图像。
在本发明的再一个实施例中,所述行文字图像集合中至少部分行文字图像的长度不同。
在本发明的再一个实施例中,所述行文字图像集合包括经过增强处理的行文字图像,所述增强处理包括锐化、错切、模糊及预定幅度旋转至少其中之一。
在本发明的再一个实施例中,所述行文字图像集合的第一特征数据包括每个行文字图像对应的多个特征图和特征图参数,每个行文字图像对应的特征图参数包括与缩放后的该行文字图像的高度对应的第一参数、与缩放后的该行文字图像的长度对应的第二参数以及第三参数,所述第三参数表示所述卷积神经网络针对所述行文字图像集合中每个行文字图像所提取的特征图个数。
在本发明的再一个实施例中,所述第一参数的值为1;所述特征图参数包括仅基于所述第二参数和第三参数表示的数据。
在本发明的再一个实施例中,该装置还包括:转换子单元,适于在将所述第一特征数据输入所述变长rnn计算得到第二特征数据之前,对仅基于所述第二参数和第三参数表示的数据进行维度转换,以使所述第二参数对应于每个行文字图像循环经过所述变长rnn的次数,使所述第三参数对应于每个行文字图像的输入数据维度。
在本发明实施方式的第六方面中,提供了一种文字识别装置,其特征在于,包括权利要求27至41中任一项所述的文字识别模型建立装置,还包括:检测单元,适于检测待识别图像得到n个文字行图以及每个所述文字行图的长度数据,n为正整数;接收单元,适于接收输入所述文字识别模型的所述n个文字行图以及所述n个文字行图的长度数据;归一化及解码单元,适于对所述文字识别模型输出的结果进行归一化并解码,获得解码后所述n个文字行图各自对应的字符串;拼接单元,适于通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果。
在本发明的一个实施例中,所述归一化及解码单元适于通过对所述文字识别模型输出的结果进行归一化并解码,还获得解码后所述n个文字行图各自对应的字符串中每个字符的识别概率;其中,所述拼接单元适于针对每个文字行图对应的解码后的字符串,基于字符的识别概率对该字符串中的字符进行过滤,利用过滤后余下的字符形成该文字行图的识别结果,以通过拼接获得所述待识别图像的文字识别结果。
在本发明的另一个实施例中,当所述待识别图像为水平排列的文字图片时,所述文字识别模型建立装置建立第一模型作为所述文字识别模型,其中,所述第一模型是利用包含有所述第一子集的所述行文字图像集合进行训练得到的;当所述待识别图像为竖直排列的文字图片时,所述文字识别模型建立装置建立第二模型作为所述文字识别模型,其中,所述第二模型是利用包含有所述第二子集的所述行文字图像集合进行训练得到的;当所述待识别图像为任意方向排列的文字图片时,所述文字识别模型建立装置建立第三模型作为所述文字识别模型,其中,所述第三模型是利用包含有所述第三子集的所述行文字图像集合进行训练得到的。
在本发明的又一个实施例中,所述拼接单元适于将识别概率小于或等于预设概率阈值的字符筛除。
在本发明的再一个实施例中,所述拼接单元包括:旋转子单元,适于将由所述待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组;第一处理子单元,适于分别采用第一模型和第二模型获得所述原图像组的两组文字识别结果以及所述预处理后图像组的两组文字识别结果,作为所述待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;第二处理子单元,适于针对所述待识别图像的四组文字识别结果中的每一组,根据该组文字识别结果对应的多个字符串中每个字符的识别概率,获得该多个字符串的平均识别概率作为该组文字识别结果的识别概率;在通过所述第一模型获得的两组文字识别结果中选择识别概率较大的一组作为第一候选结果,及在通过所述第二模型获得的两组文字识别结果中选择识别概率较大的一组作为第二候选结果;根据所述第一候选结果和所述第二候选结果的识别概率获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述第二处理子单元包括:第一筛选模块,适于设定水平阈值,在所述第一候选结果中仅保留识别概率大于该水平阈值的字符,第二筛选模块,适于设定竖直阈值,在所述第二候选结果中仅保留识别概率大于该竖直阈值的字符,结果拼接模块,适于通过对所述第一候选结果与所述第二候选结果中保留的字符进行拼接,获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述拼接单元包括:旋转子单元,适于将由所述待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组;第三处理子单元,适于分别采用第一模型和第二模型获得所述原图像组的两组文字识别结果以及所述预处理后图像组的两组文字识别结果,作为所述待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;第四处理子单元,适于设定概率阈值,在所述四组文字识别结果中仅保留识别概率大于所述概率阈值的字符,通过对所述四组文字识别结果中保留的字符进行拼接,获得所述待识别图像的文字识别结果。
在本发明的再一个实施例中,所述n个文字行图的长度部分或全部不同。
在本发明的再一个实施例中,所述文字行图包括图像高度被缩放为预设固定值的图像。
在本发明实施方式的第七方面中,提供了一种计算设备,包括上述任一种存储介质。
根据本发明实施方式的文字识别模型建立及文字识别方法、装置、介质及设备,其能够在对长度不一的文字行进行识别的过程中保证识别结果的准确度,相对于现有技术能够显著提高识别精度以及计算效率。
附图说明
通过参考附图阅读下文的详细描述,本发明示例性实施方式的上述以及其他目的、特征和优点将变得易于理解。在附图中,以示例性而非限制性的方式示出了本发明的若干实施方式,其中:
图1和图2是示出根据本发明实施方式的可以在其中实现的应用场景;
图3是示意性地示出根据本发明实施方式的文字识别模型建立方法的一个示例性处理的流程图;
图4是示意性地示出图3中的步骤s320的一种可能处理的流程图;
图5是示意性地示出根据本发明实施方式的文字识别模型建立方法的另一个示例性处理的流程图;
图6是示意性地示出根据本发明实施方式的文字识别方法的一个示例性处理的流程图;
图7是示意性示出图6中的步骤s680的一种可能处理的流程图;
图8是示意性示出图6中的步骤s680的另一种可能处理的流程图;
图9是示出根据本发明实施方式的文字识别模型建立方法以及文字识别方法的工作原理的示意图;
图10是示意性地示出根据本发明实施方式的文字识别模型建立装置的一个示例的结构框图;
图11是示意性地示出图10中的模型构建单元的一种可能结构的框图;
图12是示意性地示出根据本发明实施方式的文字识别装置的一个示例的结构框图;
图13是示意性地示出图12中的拼接单元的一种可能结构的框图;
图14是示意性地示出图13中的第二处理子单元的一种可能结构的框图;
图15是示意性地示出图12中的拼接单元的另一种可能结构的框图;
图16示意性地示出了根据本发明一实施例的计算机的结构示意图;
图17示意性地示出了根据本发明一实施例的计算机可读存储介质的示意图。
在附图中,相同或对应的标号表示相同或对应的部分。
具体实施方式
下面将参考若干示例性实施方式来描述本发明的原理和精神。应当理解,给出这些实施方式仅仅是为了使本领域技术人员能够更好地理解进而实现本发明,而并非以任何方式限制本发明的范围。相反,提供这些实施方式是为了使本公开更加透彻和完整,并且能够将本公开的范围完整地传达给本领域的技术人员。
本领域技术人员知道,本发明的实施方式可以实现为一种系统、装置、设备、方法或计算机程序产品。因此,本公开可以具体实现为以下形式,即:完全的硬件、完全的软件(包括固件、驻留软件、微代码等),或者硬件和软件结合的形式。
根据本发明的实施方式,提出了一种文字识别模型建立及文字识别方法、装置、介质及设备。
在本文中,需要理解的是,所涉及的术语含义如下:
cnn(convolutionalneuralnetwork)即卷积神经网络,在图像处理方面有着广泛应用,如分类、物体检测等等。
rnn(recurrentneuralnetwork)即循环神经网络,rnn可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。rnn的结构一般是lstm、gru等各种变种。
lstm(longshort-termmemory)是长短期记忆网络,是一种时间递归神经网络,适合于处理和预测时间序列中间隔和延迟相对较长的重要事件。
gru(gatedrecurrentunit),为了克服rnn无法很好处理远距离依赖而提出了lstm,而gru则是lstm的一个变体,当然lstm还有很多其他的变体。gru保持了lstm的效果同时又使结构更加简单,所以它也非常流行。
ctc(connectionisttemporalclassification)损失函数:在传统的语音识别的模型中,对语音模型进行训练之前,往往都要将文本与语音进行严格的对齐操作,或者文字识别的时候需要先进行文字切割,然后进行单字识别。但是很多时候文字切割或者语音就很难对齐,而利用ctc就不需要进行语音对齐或者文字切割,能够对整个序列自动对齐进行识别。
动态批量(dynamicbatching):神经网络在训练或者仅仅前向计算(前向算法的作用是计算输入层结点对隐藏层结点的影响,也就是说,把网络正向的走一遍:输入层—->隐藏层—->输出层,计算每个结点对其下一层结点的影响。)的时候,样本量是变化的,比如一般情况下,训练一个神经网络是拿k张图(k是固定,比如k=32)组成一个批量(batch)送入神经网络中进行训练,这样能加速网络训练的速度;在部署服务的时候k也是固定的(比如k=2),但是在自然场景下一张图中文字行数量是不一定的,比如这张图文字有3行文字,那张图有5行文字,为了能够有效利用计算资源,本发明的实施例根据一张图中文字行数量n,动态的组成一个动态批量(dynamicbatch),动态申请计算资源,然后对这n行文字并行进行识别。
变长rnn(variable-lengthrnn):真实场景中文字行长度不一样,假设一张图中有3行文字,将这3行文字裁剪下来,然后将文字行整体缩放,将文字高度缩放到同一个高度比如32个像素,一般情况这3行文字的长度不一样,这就需要神经网络支持变长rnn模式。
此外,附图中的任何元素数量均用于示例而非限制,以及任何命名都仅用于区分,而不具有任何限制含义。
下面参考本发明的若干代表性实施方式,详细阐释本发明的原理和精神。
发明概述
本发明人发现,在对长度不一的文字行进行识别时,传统的文字识别方法需要先进行单字切割,而切割不仅难做,而且会将整个流程复杂化。比如,如果切割的地方正好是某个字,如把“好”这个字的“女”与“子”切开了,就会影响识别结果的准确度。此外,采用滑动采样窗口的模式进行cnn特征提取、然后送入rnn进行识别的方法,则需要显式地进行滑动窗口操作,同时滑动采样的窗口大小对识别模型也有着很大的影响,操作也比较困难,影响识别结果的准确度。另外,将所有的文字行拉长到同一个长度进行识别的方法,具有一个明显的弊端,如果文字行里面的字很少或很多,就会产生很大的变形,严重影响识别结果的准确度。因此,以上这些现有方法在对长度不一的文字行进行识别的过程中都牺牲了识别结果的准确度。
本发明针对该技术问题提供了一种文字识别模型建立及文字识别方法、装置、介质及设备,该文字识别模型建立及文字识别方法、装置、介质及设备采用变长rnn实现对变长文字行的准确识别,而不需要对单字进行切割或诸如显式地用滑动采样窗口或是将所有的文字行拉长到同一个长度等方法,从而相对于现有技术提高了识别精度;由此可知,本发明实施方式提供的技术方案由于能够在对长度不一的文字行进行识别的过程中保证识别结果的准确性。
本发明实施方式提供的一些可选技术方案,在cnn+变长rnn+ctc的基础模型上,通过改进,能够同时识别水平排列文字与竖直排列方向文字。
另外,本发明实施方式提供的另一些可选技术方案,在cnn+变长rnn+ctc的基础模型上,通过改进,能够识别任意方向的文字。
此外,本发明实施方式提供的其他一些可选技术方案,采用动态批量等技术提升了在对外提供识别服务时处理一张图中文字行中字符数量不定的计算效率问题。
在介绍了本发明的基本原理之后,下面具体介绍本发明的各种非限制性实施方式。
应用场景总览
首先参考图1和图2,示意性地示出了根据本发明实施方式的可以在其中实现的应用场景。
图2中的(1)-(10)分别示出了几种字符排列方向的行文字图像示例。如图2中的(1)、(2)和(9)示出了字符水平排列的行文字图像,(3)、(4)和(10)示出了字符竖直排列的行文字图像,(5)和(6)示出了字符水平竖直混合排列的行文字图像,(7)和(8)示出了字符按任意方向排列的行文字图像。应当理解的是,图2所示的行文字图像示例仅用于举例说明而不用于限制本发明实施例所述的行文字图像,在其他实施例中,也可以存在图2之外的其他情况的行文字图像示例,这里不再一一赘述。
无论字符水平排列或是字符竖直排列的文字,将图像中所有的文字行按需要选择90°后(比如(3)原本是垂直的排列的文字“洗衣服”),全部转换成如(1)这种形式的“高度*长度”(h*w),“高度”(h)是短边,“长度”(w)代表长边,当然此时里面的文字方向不一定,一般情况下:(1)、(2)、(3)和(4)比较常见,(5)或者(6)这两种也偶尔可以见到,(7)或(8)是更加一般的形式(前六种文字排列形式是后面两种的特例),就是里面的每一个文字的方向都是随机的。
如前文所述,针对这种待处理的文字行图像中字符数量不定识别(即对长度不一的文字行进行识别)问题,采用动态批量等技术实现对变长文字行的准确、高效识别;可选地,能够同时识别水平排列文字与竖直排列方向文字以及/或任意方向的文字。
然而,本领域技术人员完全可以理解,本发明实施方式的适用场景不受到该框架任何方面的限制。
示例性方法1
下面结合图3来描述根据本发明示例性实施方式的文字识别模型建立方法。需要注意的是,上述应用场景仅是为了便于理解本发明的精神和原理而示出,本发明的实施方式在此方面不受任何限制。相反,本发明的实施方式可以应用于适用的任何场景。
图3示意性地示出了根据本公开实施例的文字识别模型建立方法的一种示例性的处理流程300。
如图3所示,处理流程300开始后,首先执行步骤s310。
s310、获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息。
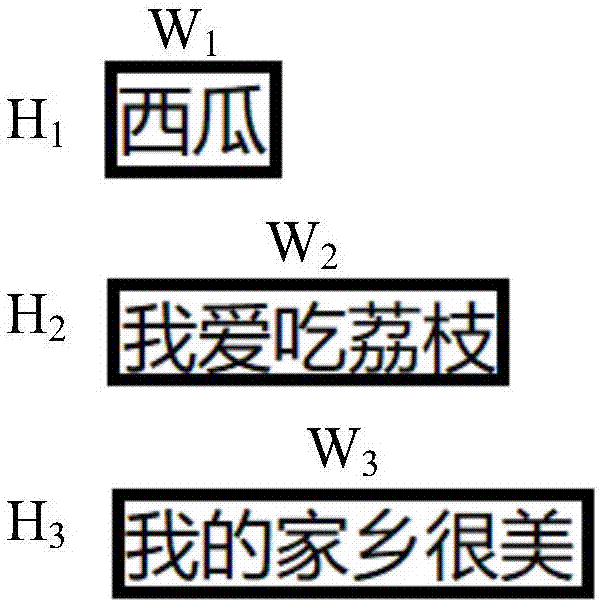
其中,这里所说的行文字图像例如是单排文字图像,每个单排文字图像中可以包括一个或多个字符,如图1中的3个行文字图像所示,从上至下的第一个行文字图像“西瓜”中包括2个中文字符,第二个行文字图像“我爱吃荔枝”中包括5个中文字符,第三个行文字图像“我的家乡很美”中包括6个中文字符。应当理解的是,行文字图像中所包括的字符可以是中文字符、英文字符或符号等任意字符。
作为示例,本发明实施方式中的行文字图像集合中的每一个行文字图像的高度h可以是预设的固定值h0,其中,h0>0,例如h0=32像素(pixel)。换句话说,若行文字图像集合中的某一个或某几个行文字图像的高度并不等于上述预设的固定值h0的话,则可以通过预处理来对该一个或几个行文字图像进行缩放,使得缩放后的上述一个或几个行文字图像的高度为上述固定值h0。由此,行文字图像集合中的各个样本(在下文中,行文字图像集合中的样本即指行文字图像集合中的行文字图像)在经过缩放后具有相同的高度。其中,预设的固定值例如可以根据经验设定,或者也可以通过试验的方式获得,这里不再赘述。
此外,作为示例,本发明实施方式中的行文字图像集合中的至少部分行文字图像的长度例如是不同的。换句话说,本发明实施方式中的行文字图像集合中的各行文字图像的长度是变长的、而非定长的。例如,可以将每个行文字图像的长度表示为w,w>0。
在如图1所示的例子中,假设一个中文字符的长度是w0的话,并假设图1中的3个行文字图像均是经过缩放后的图像,则这3个行文字图像从上至下的长度依次为w1=2w0,w2=5w0,w3=6w0,此外,3个行文字图像的高度均相等,即h1=h2=h3=固定值h0。
这样,通过步骤s310,可以获得行文字图像集合中各样本的长度信息以及所有样本的数量,假设行文字图像集合共包含k个样本,则可以得到这k个样本各自的长度信息w1、w2、…、wk,可以表示成一个大小为k的整数数组l={w1,w2,…,wk},其中k可以是固定的或不固定的,例如,k可以等于100、1000或10000等。
需要说明的是,在本发明的实施例中,所提到的“行文字图像的长度”指的是在字符沿水平排列的情况下,行文字图像水平方向的那个边的长度(通常是行文字图像的较长的边,在本发明的实施例中,这个边的长度在经过缩放后并不是固定的);而提到的“行文字图像的高度”指的是在字符沿水平排列的情况下,行文字图像竖直方向的那个边的长度(通常是行文字图像的较短的边,在本发明的实施例中,这个边的长度在经过缩放后是固定的)。
此外,为了获得大量的样本,使得行文字图像集合中的样本具有丰富性和多样性,可以通过锐化、错切、模糊及预定幅度旋转(例如预定的小幅度旋转,如5度、10度等)等一种或多种增强处理来获得经过增强处理的行文字图像,构成所述行文字图像集合的样本。比如,可将通过现有技术生成的一个行文字图像作为行文字图像集合中的一个样本,然后,再对该行文字图像分别进行上述一种或多种增强处理,由此得到由该图像经过增强处理后的多个图像,也可作为行文字图像集合中的其他多个样本。
此外,行文字图像集合中的样本也可以通过脚本自动生成,或者可以通过收集图片并进行标注的方式来获得,等等。
作为示例,本发明实施方式中的行文字图像集合例如包括第一子集,其中第一子集中包括字符水平排列的行文字图像,第一子集中所有字符的高度方向与字符排列方向垂直。如图2中的(1)和(2)所示的样本为字符水平排列的行文字图像。
在一个例子中,第一子集中所有字符的顶部例如全部朝上,也就是说,在该例子中,第一子集中的样本全部类似如图2中的(1)那样。
在另一个例子中,第一子集中所有字符的顶部例如全部朝下,也就是说,在该例子中,第一子集中的样本全部类似如图2中的(2)那样。
在其他例子中,第一子集中也可以是部分字符的顶部朝上且部分字符的顶部朝下,也就是说,在该例子中,第一子集中的样本可以包括类似如图2中的(1)或(2)那样的样本,也可以包括类似如图2中的(9)所示那样的样本。
作为示例,本发明实施方式中的行文字图像集合例如包括第二子集,其中第二子集包括字符竖直排列的行文字图像,第二子集中所有字符的高度方向与字符排列方向平行。如图2中的(3)和(4)所示的样本为字符竖直排列的行文字图像。
在一个例子中,第二子集中所有字符的顶部例如全部朝左,也就是说,在该例子中,第二子集中的样本全部类似如图2中的(3)那样。
在另一个例子中,第二子集中所有字符的顶部例如全部朝右,也就是说,在该例子中,第二子集中的样本全部类似如图2中的(4)那样。
在其他例子中,第二子集中也可以是部分字符的顶部朝左且部分字符的顶部朝右,也就是说,在该例子中,第二子集中的样本可以包括类似如图2中的(10)所示那样的样本,此外,第二子集也可以包括类似如图2中的(3)或(4)那样的样本。
作为示例,本发明实施方式中的行文字图像集合例如包括第三子集,其中第三子集包括一个或多个字符按任意方向排列的行文字图像,第三子集包括其中至少部分字符的高度方向与排列方向既不垂直也不平行的行文字图像。如图2中的(7)和(8)所示的样本为字符按任意方向排列的行文字图像。
作为示例,本发明实施方式中的行文字图像集合例如包括第四子集,其中第四子集包括一个或多个字符水平竖直混合排列的行文字图像,第四子集包括其中至少部分字符的高度方向与字符排列方向平行、部分字符的高度方向与字符排列方向垂直的行文字图像。如图2中的(5)和(6)所示的样本为字符水平竖直混合排列的行文字图像,除此之外,第四子集也可以包括类似如图2中的(1)-(4)那样的样本。
步骤s320、根据每一个行文字图像的长度信息与行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值。
根据本发明的实施例,可以通过如图4所示的步骤s410~s430来实现步骤s320中依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值的过程。
如图4所示,在步骤s410中,通过cnn进行特征抽取,来获取行文字图像集合的第一特征数据;然后,执行步骤s420。其中,cnn例如可以是resnet、vgg或其他类型的网络。
作为示例,本发明实施方式中的行文字图像集合的第一特征数据例如包括每个行文字图像对应的多个特征图和特征图参数。每个行文字图像对应的特征图参数例如包括与缩放后的该行文字图像的高度h(即短边长度)对应的第一参数m、与缩放后的该行文字图像的长度w(即长边长度)对应的第二参数t以及第三参数c。其中,第三参数c表示卷积神经网络cnn针对行文字图像集合中每个行文字图像所提取的特征图个数。
换句话说,经过cnn特征提取后,每一个样本所对应的特征图大小为c*m*t(其中m对应h进过cnn后所对应的边,t对应w,c表示特征图的个数,即channels)。
作为示例,本发明实施方式中的第一参数m的值例如可以为1,在这种情况下,上述特征图参数包括仅基于第二参数t和第三参数c表示的数据,即,cnn输出的数据c*m*t=c*1*t=c*t。
在步骤s420中,将当前的第一特征数据输入变长rnn中计算,继续进行特征抽取,从而得到从变长rnn中输出的第二特征数据。然后,在步骤s430中,将变长rnn输出的第二特征数据输入fc中计算,得到文字预测值。
其中,变长rnn结构例如可以是lstm或gru等,可以是单向变长rnn,也可以是双向变长rnn;此外,变长rnn可以是单层,也可以是多层。
作为示例,在执行步骤s420之前,还可以对仅基于上述第二参数t和第三参数c表示的数据进行维度转换,即将c*t维度的数据转换为t*c维度的数据,以使第二参数t对应于每个行文字图像循环经过变长rnn的次数,而使第三参数c对应于每个行文字图像的输入数据维度。
换句话说,对于每一个样本数据t*c,t就是每个样本要循环经过变长rnn的次数,而c就是输入数据的维度。
s330、将文字预测值与预先设置的标准结果值进行对比得到偏差值。
其中,预先设置的标准结果值例如可以是样本的groundtruth(地面实况,在这里指样本的真值)。文字预测值与对应的标准结果值进行比对的过程例如可以采用现有比对技术实现,如现有的比较两个字符串之间的相似度的技术,等等,从而得到二者之间的差异作为所述偏差值。
s340、根据偏差值及预设的损失函数(例如ctc损失函数)对cnn、变长rnn及fc的模型参数进行校正,直到偏差值小于或等于预定阈值。这样,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。其中,预定阈值例如可以根据经验设定,或者也可以通过试验的方式获得,这里不再赘述。
在步骤s330以及s340中,将经过变长rnn层抽取的特征连接fc层,对fc层的结果以及样本的标准结果计算ctcloss(作为目标损失函数的示例)。
作为示例,本发明实施方式中根据偏差值及预设的损失函数对cnn、变长rnn及fc的模型参数进行校正的步骤例如可以包括:根据偏差值及预设的损失函数,按照梯度反向传递方式依次对fc的第三模型参数、变长rnn的第二模型参数及cnn的第一模型参数进行校正,直至计算结果收敛。
由于行文字图像集合的k个样本长度不一,为了保证梯度反向传递的时候模型能正常收敛,校正过程中的前向计算、损失函数计算以及梯度的计算都要根据每一个样本(每一行文字)的实际长度w做动态计算(即变长rnn、ctc等一些关键层的输入包括上一层的输出结果和代表每一张图实际长度的整数数组l)。这样,训练一段时间后,能够获得对应的文字识别模型。
图5示意性地示出了根据本公开实施例的文字识别模型建立方法的另一个示例的处理流程500。
如图5所示,处理流程500中的步骤s510~s540与上文中结合图3所描述的处理流程300的步骤s310~s340的处理相同,能够达到相似的技术效果,这里不再赘述。与处理流程300不同的是,处理流程500在步骤s510之前还包括步骤s502和s504。
其中,在步骤s502中,待处理图像(即待进行文字识别的整个图像)是包含有文字的图像,首先对该待处理图像进行文字区域检测,得到文字所在的行区域,这样,可以得到一个或多个行区域。
然后,在步骤s504中,在待处理图像中截取上述一个或多个行区域分别作为一个或多个行文字图像。
这样,通过步骤s502和s504,可以利用一些包含有文字的图像而获得多个行文字图像,用于构建文字识别模型。
示例性方法2
下面结合图6来描述根据本发明示例性实施方式的文字识别方法。
图6示意性地示出了根据本公开实施例的文字识别方法的一种示例性的处理流程600。
如图6所示,处理流程600开始后,首先通过执行步骤s610~s640来构建文字识别模型。其中,步骤s510~s540例如可与上文中结合图3所描述的处理流程300的文字识别模型建立方法中的步骤s310~s340的处理相同,并能够达到相似的技术效果和功能,这里不再赘述。
在通过步骤s610~s640构建完文字识别模型之后,执行步骤s650~s680。
在步骤s650中,检测待识别图像得到n个文字行图以及每个文字行图的长度数据,n为正整数。然后,执行步骤s660。
在步骤s660中,接收输入文字识别模型的n个文字行图以及n个文字行图的长度数据。然后,执行步骤s670。
作为示例,当待识别图像为水平排列的文字图片时,例如可以采用第一模型作为文字识别模型,其中,第一模型是利用包含有第一子集(例如采用根据本发明实施例的示例性方法1中所提到的第一子集)的行文字图像集合进行训练得到的。这样,对于已知待识别图像类型为水平排列的文字图片的情况,利用第一模型能够简便、快速地获得较为准确的识别结果。
当待识别图像为竖直排列的文字图片时,例如可以采用第二模型作为文字识别模型,其中,第二模型是利用包含有第二子集(例如采用根据本发明实施例的示例性方法1中所提到的第二子集)的行文字图像集合进行训练得到的。这样,对于已知待识别图像类型为竖直排列的文字图片的情况,利用第二模型能够简便、快速地获得较为准确的识别结果。
当待识别图像为任意方向排列的文字图片时,采用第三模型作为文字识别模型,其中,第三模型是利用包含有第三子集(例如采用根据本发明实施例的示例性方法1中所提到的第三子集)的行文字图像集合进行训练得到的。这样,对于已知待识别图像类型为任意方向排列的文字图片的情况,利用第三模型能够简便、快速地获得较为准确的识别结果。
当待识别图像为水平竖直混合排列的文字图片时,例如可以采用第四模型作为文字识别模型,其中,第四模型可以是利用包含有第四子集(例如采用根据本发明实施例的示例性方法1中所提到的第四子集)的行文字图像集合进行训练得到的,或者也可以是利用包含有第一子集和第二子集(可选地还可以包括第四子集)的行文字图像集合进行训练得到的。这样,对于已知待识别图像类型为水平竖直混合排列的文字图片的情况,利用第四模型能够简便、快速地获得较为准确的识别结果。
在步骤s670中,对文字识别模型输出的结果进行归一化并解码,获得解码后n个文字行图各自对应的字符串。然后,执行步骤s680。
作为示例,在步骤s670中,还可以通过对文字识别模型输出的结果进行归一化并解码,来获得解码后n个文字行图各自对应的字符串中每个字符的识别概率。
在步骤s680中,通过对解码后n个文字行图各自对应的字符串进行拼接,获得待识别图像的文字识别结果。
作为示例,本发明实施方式中的步骤s680的处理例如可以通过如下过程实现:针对每个文字行图对应的解码后的字符串,基于字符的识别概率对该字符串中的字符进行过滤,利用过滤后余下的字符形成该文字行图的识别结果,以通过拼接获得待识别图像的文字识别结果。
其中,对该字符串中的字符进行过滤时,例如可将识别概率小于或等于预设概率阈值的字符筛除。预设概率阈值例如可以根据经验设定,或者也可以通过试验的方式获得,这里不再赘述。
在一个例子中,当待识别图像包括字符水平竖直混合排列的文字图片时,可以通过如图7所示的步骤s710~s750来获得待识别图像的文字识别结果。
如图7所示,在步骤s710中,将由待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组。
然后,在步骤s720中,分别采用第一模型和第二模型获得原图像组的两组文字识别结果以及预处理后图像组的两组文字识别结果,作为待识别图像的四组文字识别结果。其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率。
在步骤s730中,针对待识别图像的四组文字识别结果中的每一组,根据该组文字识别结果对应的多个字符串中每个字符的识别概率,获得该多个字符串的平均识别概率作为该组文字识别结果的识别概率。
在步骤s740中,在通过第一模型获得的两组文字识别结果中选择识别概率较大的一组作为第一候选结果,及在通过第二模型获得的两组文字识别结果中选择识别概率较大的一组作为第二候选结果。
在步骤s750中,根据第一候选结果和第二候选结果的识别概率获得待识别图像的文字识别结果。
其中,在步骤s750中,例如可以设定水平阈值(例如0.7)和竖直阈值(例如0.7),在第一候选结果中仅保留识别概率大于该水平阈值的字符,而在第二候选结果中仅保留识别概率大于该竖直阈值的字符,这样,通过对第一候选结果与第二候选结果中保留的字符进行拼接,从而获得待识别图像的文字识别结果。水平阈值和竖直阈值可以相同,也可以不同。此外,水平阈值和竖直阈值可以根据经验值设定,或者可以通过试验的方式确定,这里不再赘述。
其中,在对第一候选结果与第二候选结果中保留的字符进行拼接时,可以按照每个保留的字符对应的原文字顺序进行拼接,比如,第一候选结果中保留的字符x1在对应的文字行图中的对应文字是第3个字,而第二候选结果中保留的字符y1在对应的文字行图中的对应文字是第5个字,则在拼接结果中,字符x1应当排在字符y1之前。
在另一个例子中,当待识别图像包括字符水平竖直混合排列的文字图片时,也可以通过如图8所示的步骤s810~s850来获得待识别图像的文字识别结果。
如图8所示,在步骤s810中,将由待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组。
在步骤s820中,分别采用第一模型和第二模型获得原图像组的两组文字识别结果以及预处理后图像组的两组文字识别结果,作为待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率。
然后,在步骤s830中,通过设定概率阈值(例如0.7),在四组文字识别结果中仅保留识别概率大于概率阈值的字符,通过对四组文字识别结果中保留的字符进行拼接,获得待识别图像的文字识别结果。其中,概率阈值可以根据经验值设定,或者可以通过试验的方式确定,这里不再赘述。此外,在对四组文字识别结果中保留的字符进行拼接时,可以按照每个保留的字符对应的原文字顺序进行拼接。
作为示例,n个文字行图的长度可以部分或全部不同。
此外,文字行图可以包括图像高度被缩放为预设固定值的图像。
此外,图9示出了根据本发明实施方式的文字识别模型建立方法以及文字识别方法的一个优选示例的工作原理。
在图9中,①对应训练的过程,也就是上文所述的示例性方法1中的文字识别模型建立方法;②对应实际部署前向推理的过程,也就是上文所述的示例性方法2中的文字识别方法。
下面分别描述上述①和②两个过程。
①训练过程
如图9所示,在该优选示例中,在利用行文字图像集合进行训练来构建文字识别模型的过程中,可以首先收集样本来获得对应的行文字图像集合。
然后,可以随机取k(k可以固定,也可以不固定)张图片组成一个训练batch(批量训练),以及一个大小为k的整数数组(其中每一个整数代表每一张图的实际长度w),每张图片作为一个样本。
接着,可以对每一张图片随机进行数据增强处理(如锐化、错切、模糊、小幅度旋转等等)。
然后,通过cnn网络进行特征抽取,经过cnn特征抽取后,每一个样本所对应的特征图大小为c*m*t。
令m=1,将c*m*t=c*1*t=c*t的数据,进行维度转换变成t*c,继续通过变长rnn进行特征抽取。其中,如图9所示,t={t1,t2,...,tk}表示每个行文字图像需要经过变长rnn的次数,即,第一个行文字图像需要经过变长rnn的次数为t1,第二个行文字图像经过变长rnn的次数为t2,以此类推,本质上w1/t1=w2/t2=w3/t3...是一个固定的比例,跟网络设计有关。
将经过变长rnn层抽取的特征连接fc层,对fc层的结果以及样本的真值计算目标损失函数ctcloss。由于随机选取的k张图长度不一,为了保证梯度反向传递的时候模型能正常收敛,前向计算、损失函数计算和梯度的计算都要根据每一张图片的实际长度w做动态计算(即rnn、ctc等一些关键层的输入包括上一层的输出结果和代表每一张图实际长度的整数数组l)。这样,训练一定的时间,可以获得对应的文字识别模型。
②实际部署前向推理过程
该过程,也即水平识别模型的前向计算过程。
在真实场景中,从服务端输入一张图(即上文所述的待识别图像),请求识别。通过一定的文字检测算法,检测出图片中的文字,获得n行长短不一的文字,通过对该n行长短不一的文字进行截取,获得n个文字行图。
然后,将上述n个文字行图大小缩放到h*w,其中h为固定(如32像素),w为变长。将上述n个文字行图组成一个动态批量(dynamicbatch),以及一个大小为n的整数数组,其中,w1、w2、…、wn分别表示上述n个文字行图各自的长度。
接着,将图像数据(上述动态批量)以及l’送入到训练获得的网络模型,依次通过cnn、rnn、fc层,将fc层的输出通过softmax层,根据实际情况解码softmax后的值(解码器decoder可以使用beamsearch或者greedysearch等),对于每个文字行图获得一串识别的字符串,同时获得每条字符串中每一个字的识别概率。例如,可以用s=s1s2…sm表示一条识别出的字符串,其中,s表示这条字符串,si表示这条字符串中的第i个字符,i=1,2,…,m,其中m表示这条字符串中的字符个数;此外,可以用p=p1p2…pm表示这条字符串中每一个字符的识别概率,其中p表示这条字符串对应的各字符的识别概率,pi表示这条字符串中的第i个字符的识别概率,pi对应于s中的si,pi在0.0到1.0之间取值。
根据实际业务需求,可以过滤或者保留一定概率的预测字符,得到最后结果。由于检测出来的n个文字行图长度不一,前向计算要根据每个文字行图(每一行文字)的实际长度w做动态计算(即rnn等一些关键层的输入包括上一层的输出结果和代表每一张图实际长度的整数数组l’)。
需要说明的是,在图9所示的例子中,行文字图像集合可以采用上文所述的第一子集、第二子集、第三子集或第四子集,这样,可以分别获得对应的第一模型、第二模型、第三模型或第四模型。或者,行文字图像集合也可以采用上述第一至第四子集中的两个或多个的组合,从而获得不同的模型,用于识别不同类型的文字图片。
需要注意的是,图9中①的训练过程中输入的是k个行文字图像的长度数据所组成的数组,而在②的实际部署前向推理过程中输入的则是n个文字行图的长度数据所组成的数组(未在图中示出该数组)。
类似地,在图9中①的训练过程中用t={t1,t2,...,tk}表示k个行文字图像中的每一个行文字图像需要经过变长rnn的次数;对应地,在②的实际部署前向推理过程中,可以用t’={t’1,t’2,...,t’n}(图中未示出)表示n个文字行图中的每一个文字行图需要经过变长rnn的次数。
示例性装置1
在介绍了本发明示例性实施方式的文字识别模型建立方法以及文字识别方法之后,接下来,参考图10对本发明示例性实施方式的文字识别模型建立装置进行说明。
参见图10,示意性地示出了根据本发明一个实施例的文字识别模型建立装置1000的结构示意图,该装置可以设置于终端设备中,例如,该装置可以设置于台式计算机、笔记型计算机、智能移动电话以及平板电脑等智能电子设备中;当然,本发明实施方式的装置也可以设置于服务器中。本发明实施方式的装置1000可以包括下述组成单元:信息获取单元1010、模型构建单元1020、对比单元1030和校正单元1040。
如图10所示,信息获取单元1010适于获取行文字图像集合中每一个行文字图像的长度信息与行文字图像的数量信息。
作为示例,行文字图像可以为单排文字图像,单排文字图像包括一个或多个字符。
作为示例,行文字图像集合中每一个行文字图像的高度可以为固定值h0,h0>0。
作为示例,行文字图像集合可以包括第一子集,第一子集包括字符水平排列的行文字图像;第一子集中所有字符的高度方向与字符排列方向垂直。
其中,第一子集中所有字符的顶部可以全部朝上,或者,第一子集中所有字符的顶部可以全部朝下,或者,第一子集中可以部分字符的顶部朝上且部分字符的顶部朝下。
作为示例,行文字图像集合可以包括第二子集,第二子集包括字符竖直排列的行文字图像;第二子集中所有字符的高度方向与字符排列方向平行。
作为示例,行文字图像集合可以包括第三子集,第三子集包括一个或多个字符按任意方向排列的行文字图像;第三子集包括其中至少部分字符的高度方向与排列方向既不垂直也不平行的行文字图像。
作为示例,行文字图像集合也可以包括上文描述的第四子集,这里不再赘述。
此外,作为示例,行文字图像集合中至少部分行文字图像的长度可以是不同的。
此外,行文字图像集合中里可以包括经过增强处理的行文字图像,增强处理包括锐化、错切、模糊及预定幅度旋转至少其中之一。预定幅度例如可以根据经验设定,或者也可以通过试验的方式获得,这里不再赘述。
如图10所示,模型构建单元1020适于根据每一个行文字图像的长度信息与行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值。
作为示例,本发明实施方式中的模型构建单元1020可以具有如图11所示的结构。如图11所示,模型构建单元1020可以包括cnn处理子单元1020-1、变长rnn处理子单元1020-2和fc处理子单元1020-3。
其中,cnn处理子单元1020-1可以通过cnn获取行文字图像集合的第一特征数据,变长rnn处理子单元1020-2可以将第一特征数据输入变长rnn计算得到第二特征数据,此外,fc处理子单元1020-3可以将第二特征数据输入fc计算得到文字预测值。
对比单元1030适于将文字预测值与预先设置的标准结果值进行对比得到偏差值。
校正单元1040适于根据偏差值及预设的损失函数对cnn、变长rnn及fc的模型参数进行校正,直到偏差值小于或等于预定阈值,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。
需要说明的是,cnn处理子单元1030-1、变长rnn处理子单元1030-2和fc处理子单元1030-3例如可以分别执行上文中结合图5所描述的步骤s410~s430的处理,并能够实现相类似的功能和技术效果,这里不再一一赘述。
作为示例,本发明实施方式中的校正单元1040可以通过如下方式实现对cnn、变长rnn及fc的模型参数的校正:根据偏差值及预设的损失函数,按照梯度反向传递方式依次对fc的第三模型参数、变长rnn的第二模型参数及cnn的第一模型参数进行校正。
作为示例,建立装置还可以包括预处理单元(图中未示出),该预处理单元可以在获取行文字图像集合中每一个行文字图像的长度信息与行文字图像的数量信息之前,对包含有文字的图像进行文字区域检测,得到文字所在的行区域,并截取行区域作为行文字图像。
作为示例,行文字图像集合的第一特征数据例如包括每个行文字图像对应的多个特征图和特征图参数,每个行文字图像对应的特征图参数包括与缩放后的该行文字图像的高度对应的第一参数、与缩放后的该行文字图像的长度对应的第二参数以及第三参数,第三参数表示卷积神经网络针对行文字图像集合中每个行文字图像所提取的特征图个数。
其中,第一参数的值例如为1;特征图参数可以包括仅基于第二参数和第三参数表示的数据。
作为示例,上述文字识别模型建立装置1000还可以包括转换子单元(图中未示出),转换子单元可以在将第一特征数据输入变长rnn计算得到第二特征数据之前,对仅基于第二参数和第三参数表示的数据进行维度转换,以使第二参数对应于每个行文字图像循环经过变长rnn的次数,使第三参数对应于每个行文字图像的输入数据维度。
需要说明的是,根据本发明实施例的文字识别模型建立装置1000中的信息获取单元1010、模型构建单元1020、对比单元1030和校正单元1040以及子单元等组成部分例如可以分别执行上文中结合图3所描述的文字识别模型建立方法中的对应的步骤s310~s340以及子步骤等的处理,并能够实现相类似的功能和技术效果,这里不再一一赘述。
示例性装置2
在介绍了本发明示例性实施方式的文字识别模型建立装置之后,接下来,参考图12对本发明示例性实施方式的文字识别装置进行说明。
参见图12,示意性地示出了根据本发明一个实施例的文字识别装置1200的结构示意图,该装置可以设置于终端设备中,例如,该装置可以设置于台式计算机、笔记型计算机、智能移动电话以及平板电脑等智能电子设备中;当然,本发明实施方式的装置也可以设置于服务器中。本发明实施方式的装置1200包括如上结合图10所描述的文字识别模型建立装置1000,还包括下述组成单元:检测单元1210、接收单元1220、归一化及解码单元1230和拼接单元1240。
其中,检测单元1210适于检测待识别图像得到n个文字行图以及每个所述文字行图的长度数据,n为正整数。
接收单元1220适于接收输入所述文字识别模型的所述n个文字行图以及所述n个文字行图的长度数据。
归一化及解码单元1230适于对所述文字识别模型输出的结果进行归一化并解码,获得解码后所述n个文字行图各自对应的字符串。
此外,拼接单元1240适于通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果。
作为示例,n个文字行图的长度可以部分或全部不同。
此外,文字行图包括图像高度可以被缩放为预设固定值的图像。
作为示例,归一化及解码单元1230可以通过对文字识别模型输出的结果进行归一化并解码,还获得解码后n个文字行图各自对应的字符串中每个字符的识别概率;其中,拼接单元1240可以针对每个文字行图对应的解码后的字符串,基于字符的识别概率对该字符串中的字符进行过滤,利用过滤后余下的字符形成该文字行图的识别结果,以通过拼接获得待识别图像的文字识别结果。
作为示例,当待识别图像为水平排列的文字图片时,文字识别模型建立装置例如可以建立第一模型作为文字识别模型,其中,第一模型是利用包含有第一子集的行文字图像集合进行训练得到的。
此外,当待识别图像为竖直排列的文字图片时,文字识别模型建立装置例如可以建立第二模型作为文字识别模型,其中,第二模型是利用包含有第二子集的行文字图像集合进行训练得到的。
另外,当待识别图像为任意方向排列的文字图片时,文字识别模型建立装置例如可以建立第三模型作为文字识别模型,其中,第三模型是利用包含有第三子集的行文字图像集合进行训练得到的。
此外,当待识别图像为水平竖直混合排列的文字图片时,文字识别模型建立装置例如可以建立上文所描述的第四模型作为文字识别模型,这里不再赘述。
作为示例,拼接单元1240可以将识别概率小于或等于预设概率阈值的字符筛除。
在一个例子中,拼接单元1240可以包括如图13所示的结构。
如图13所示,拼接单元1240包括旋转子单元1240-1、第一处理子单元1240-2以及第二处理子单元1240-3。
其中,旋转子单元1240-1可将由待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组。
第一处理子单元1240-2可以分别采用第一模型和第二模型获得原图像组的两组文字识别结果以及预处理后图像组的两组文字识别结果,作为待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;
第二处理子单元1240-3可以执行如下处理:针对待识别图像的四组文字识别结果中的每一组,根据该组文字识别结果对应的多个字符串中每个字符的识别概率,获得该多个字符串的平均识别概率作为该组文字识别结果的识别概率;在通过第一模型获得的两组文字识别结果中选择识别概率较大的一组作为第一候选结果,及在通过第二模型获得的两组文字识别结果中选择识别概率较大的一组作为第二候选结果;根据第一候选结果和第二候选结果的识别概率获得待识别图像的文字识别结果。
作为示例,如图14所示,第二处理子单元1240-3例如包括第一筛选模块1401、第二筛选模块1402和结果拼接模块1403。
其中,第一筛选模块1401适于设定水平阈值,在第一候选结果中仅保留识别概率大于该水平阈值的字符。第二筛选模块1402适于设定竖直阈值,在第二候选结果中仅保留识别概率大于该竖直阈值的字符。结果拼接模块1403适于通过对第一候选结果与第二候选结果中保留的字符进行拼接,获得待识别图像的文字识别结果。
在另一个例子中,拼接单元1240可以包括如图15所示的结构,包括旋转子单元1240-1、第三处理子单元1240-4和第四处理子单元1240-5。其中,旋转子单元1240-1适于将由待识别图像获得的n个文字行图组成原图像组,将每一个文字行图中的文字旋转180°后,获得对应的预处理后图像组;第三处理子单元1240-4适于分别采用第一模型和第二模型获得原图像组的两组文字识别结果以及预处理后图像组的两组文字识别结果,作为待识别图像的四组文字识别结果;其中,每组文字识别结果包括对应的多个字符串以及每个字符串中各字符的识别概率;第四处理子单元1240-5适于设定概率阈值,在四组文字识别结果中仅保留识别概率大于概率阈值的字符,通过对四组文字识别结果中保留的字符进行拼接,获得待识别图像的文字识别结果。
需要说明的是,根据本发明实施例的文字识别装置1200中的各组成单元以及子单元等组成部分例如可以分别执行上文中结合图6-8中任一个所描述的文字识别方法中的对应步骤以及子步骤等的处理,并能够实现相类似的功能和技术效果,这里不再一一赘述。
图16示出了适于用来实现本发明实施方式的示例性计算机系统/服务器1600(计算设备)的框图。图16显示的计算机系统/服务器1600仅仅是一个示例,不应对本发明实施例的功能和使用范围带来任何限制。
如图16所示,计算机系统/服务器1600以通用计算设备的形式表现。计算机系统/服务器1600的组件可以包括但不限于:一个或者多个处理器或者处理单元1601,系统存储器1602,连接不同系统组件(包括系统存储器1602和处理单元1601)的总线1603。
计算机系统/服务器1600典型地包括多种计算机系统可读介质。这些介质可以是任何能够被计算机系统/服务器1600访问的可用介质,包括易失性和非易失性介质,可移动的和不可移动的介质。
系统存储器1602可以包括易失性存储器形式的计算机系统可读介质,例如随机存取存储器(ram)1621和/或高速缓存存储器1622。计算机系统/服务器1600可以进一步包括其它可移动/不可移动的、易失性/非易失性计算机系统存储介质。仅作为举例,rom1623可以用于读写不可移动的、非易失性磁介质(图16中未显示,通常称为“硬盘驱动器”)。尽管未在图16中示出,可以提供用于对可移动非易失性磁盘(例如“软盘”)读写的磁盘驱动器,以及对可移动非易失性光盘(例如cd-rom,dvd-rom或者其它光介质)读写的光盘驱动器。在这些情况下,每个驱动器可以通过一个或者多个数据介质接口与总线1603相连。系统存储器1602中可以包括至少一个程序产品,该程序产品具有一组(例如至少一个)程序模块,这些程序模块被配置以执行本发明各实施例的功能。
具有一组(至少一个)程序模块1624的程序/实用工具1625,可以存储在例如系统存储器1602中,且这样的程序模块1624包括但不限于:操作系统、一个或者多个应用程序、其它程序模块以及程序数据,这些示例中的每一个或某种组合中可能包括网络环境的实现。程序模块1624通常执行本发明所描述的实施例中的功能和/或方法。
计算机系统/服务器1600也可以与一个或多个外部设备1604(如键盘、指向设备、显示器等)通信。这种通信可以通过输入/输出(i/o)接口1605进行。并且,计算机系统/服务器1600还可以通过网络适配器1606与一个或者多个网络(例如局域网(lan),广域网(wan)和/或公共网络,例如因特网)通信。如图16所示,网络适配器1606通过总线1603与计算机系统/服务器1600的其它模块(如处理单元1601等)通信。应当明白,尽管图16中未示出,可以结合计算机系统/服务器1600使用其它硬件和/或软件模块。
处理单元1601通过运行存储在系统存储器1602中的程序,从而执行各种功能应用以及数据处理,例如,执行并实现文字识别模型建立方法中的各步骤;例如,获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息;根据所述每一个行文字图像的长度信息与所述行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值;将所述文字预测值与预先设置的标准结果值进行对比得到偏差值;根据所述偏差值及预设的损失函数对所述cnn、所述变长rnn及所述fc的模型参数进行校正,直到所述偏差值小于或等于预定阈值,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。又如,除此之外,检测待识别图像得到n个文字行图以及每个所述文字行图的长度数据,n为正整数;接收输入所述文字识别模型的所述n个文字行图以及所述n个文字行图的长度数据;对所述文字识别模型输出的结果进行归一化并解码,获得解码后所述n个文字行图各自对应的字符串;通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果。
本发明实施方式的计算机可读存储介质一个具体例子如图17所示。
图17的计算机可读存储介质为光盘1700,其上存储有计算机程序(即程序产品),该程序被处理器执行时,会实现上述方法实施方式中所记载的各步骤,例如,获取行文字图像集合中每一个行文字图像的长度信息与所述行文字图像的数量信息;根据所述每一个行文字图像的长度信息与所述行文字图像的数量信息,依次通过卷积神经网络cnn、变长循环神经网络rnn和全连接层fc得到文字预测值;将所述文字预测值与预先设置的标准结果值进行对比得到偏差值;根据所述偏差值及预设的损失函数对所述cnn、所述变长rnn及所述fc的模型参数进行校正,直到所述偏差值小于或等于预定阈值,将当前经过校正后的所述cnn、所述变长rnn及所述fc作为所述文字识别模型。又如,除此之外,检测待识别图像得到n个文字行图以及每个所述文字行图的长度数据,n为正整数;接收输入所述文字识别模型的所述n个文字行图以及所述n个文字行图的长度数据;对所述文字识别模型输出的结果进行归一化并解码,获得解码后所述n个文字行图各自对应的字符串;通过对解码后所述n个文字行图各自对应的字符串进行拼接,获得所述待识别图像的文字识别结果。各步骤的具体实现方式在此不再重复说明。
应当注意,尽管在上文详细描述中提及了文字识别模型建立装置的若干单元、模块或子模块,但是这种划分仅仅是示例性的并非强制性的。实际上,根据本发明的实施方式,上文描述的两个或更多模块的特征和功能可以在一个模块中具体化。反之,上文描述的一个模块的特征和功能可以进一步划分为由多个模块来具体化。
此外,尽管在附图中以特定顺序描述了本发明方法的操作,但是,这并非要求或者暗示必须按照该特定顺序来执行这些操作,或是必须执行全部所示的操作才能实现期望的结果。附加地或备选地,可以省略某些步骤,将多个步骤合并为一个步骤执行,和/或将一个步骤分解为多个步骤执行。
虽然已经参考若干具体实施方式描述了本发明的精神和原理,但是应该理解,本发明并不限于所公开的具体实施方式,对各方面的划分也不意味着这些方面中的特征不能组合以进行受益,这种划分仅是为了表述的方便。本发明旨在涵盖所附权利要求的精神和范围内所包括的各种修改和等同布置。
- 还没有人留言评论。精彩留言会获得点赞!