基于视觉SLAM的室内场景下单一目标物体字典模型改进方法与流程
本发明涉及图像处理方法,尤其涉及一种基于视觉slam的室内场景下单一目标物体字典模型改进方法。
背景技术:
随着我国经济的快速发展与工业水平的提升,对于进一步提升生产力水平的需求愈为迫切,因此一系列自动化程度较高的机器人在诸多行业的应用都取得了长足进步。由于视觉slam技术对于设备的要求不高、成本较低并且在室内定位与建图精度良好,能够帮助机器人快速识别周边环境与特定物体,因此例如在室内家务机器人、快递自动分拣机器人、工业装配机器人等等领域均有广泛的应用。
与此同时,当前的视觉slam技术受限于对室内家务、快递分拣等场景的细化研究不足,导致对物体的处理仍较多关注于点、边等局部特征,对于物体类别、结构等信息的关注不足。对于物体语义类别划分与相互联系的视觉slam系统的研究目前正处于初步阶段,由于各类工业应用场景的不同,导致指定类别划分的方法也不尽相同,还未能有可产业化的算法。因此研究在室内场景下结合目标物体信息的兼顾效率与准确度的视觉slam算法的需求日益凸显。
技术实现要素:
发明目的:针对现有技术存在的问题,本发明的目的在于提供一种能够解决室内场景下现有开源视觉slam算法存在跟踪目标时易丢失、复杂场景下的实时性不足、工作效率不高并且易受环境因素影响而精度不高等问题的基于视觉slam的室内场景下单一目标物体字典模型改进方法,为一些类别环境下的特定单一目标物体的同步定位与建图提供了较大的便利。
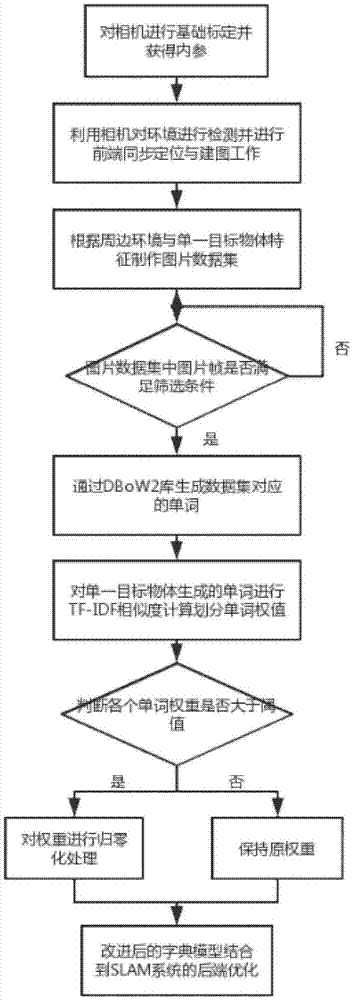
技术方案:一种基于视觉slam的室内场景下单一目标物体字典模型改进方法,包括如下步骤:
(1)对于进行视觉slam的单目或双目相机进行基础标定,获得内参信息后利用该相机对环境进行检测并进行前端同步定位与建图,通过三维特征点得到未经过后端优化的点云地图;
(2)根据周边环境与单一目标物体相关特征制作图片数据集,并利用dbow2库k-means++算法生成数据集对应的单词,为室内场景下视觉slam对单一目标物体建立的点云地图进行回环检测做准备;
(3)针对单一目标物体生成的单词进行tf-idf相似度计算划分单词权值,根据对检测周边环境闭环贡献程度的高低设定阈值,对于与单一目标物体有关的部分单词进行归零化处理,得到单一目标物体字典改进模型;
(4)将改进后的字典模型结合到slam系统的后端优化中,通过对点云地图点在图像帧上的投影与实际像素坐标进行最小化投影误差,优化在室内场景下对于单一目标物体的回环检测的发现与点云地图的闭环融合,提高定位与建图精度。
所述步骤(1)中,对一台单目相机进行标定,获得内参信息,同时通过视觉slam前端进行同步定位与建图,具体步骤为:
(1.1)以环境内的一张黑白棋盘格作为标定物,通过调整标定物与各个相机的方向,为标定物拍摄一些不同方向的照片,并从照片中提取棋盘格角点;
(1.2)设周边环境中某空间点p的相机坐标为[x,y,z]t,其中,x,y,z分别为相机在三维空间立体坐标系中的坐标,则在相机模型中根据三角形相似关系得到成像平面内对应成像点p′坐标为
将该点转换到像素坐标[u,v],有
根据实际情况,合理选择校正参数k1、k2、p1、p2、p3,对相机基础标定的计算中的径向畸变与切向畸变进行纠正;
(1.3)获得标定相机的内参后,使用相机并利用视觉slam软件前端对周边环境进行同时定位与建图。首先由相机拍摄得到关键帧序列设为{fkey},根据关键帧提取得到图像的特征点;其次通过前后两帧关键帧图像构建对极约束;最后根据相机位姿的变化,通过对极几何约束与特征点投影对周边环境进行定位与建图。
所述步骤(2)具体包括:
(2.1)使用相机拍摄包含单一目标物体的环境视频,并将视频转化为视频图像帧,构建初步的图片数据集;
(2.2)提取每幅图像帧的orb特征点,筛选生成关键帧,通过筛选具有代表性的图像帧即关键帧,降低数据集的容量,提升后续步骤中生成单词与进行回环检测的效率。所述筛选生成关键帧需满足如下任一条件:
1)若继上一次筛选得到关键帧后,又过了n1帧;
2)当前无筛选得到的关键帧,或已有n2帧的图像帧被丢弃;
3)当前图像帧帧处理得到大于m个orb特征点;
4)当前图像帧特征点与前一关键帧的相似度不超过s;
n1、n2、m、s为常数变量,可根据不同的单一目标物体场景提前设定成不同数值,其中s优选设置为0.85。
(2.3)通过图片数据集利用dbow2库k-means++算法生成数据集对应的单词,具体为在每张关键帧图片中随机选取一个特征为初始聚类中心,通过计算图片中每一个特征点与当前已有聚类中心的最短距离d(x)来进一步得到每个特征点被选为下一个聚类中心的概率p(x);按照轮盘法则选择下一个聚类中心,若聚类中心数量达到设定的阈值k则完成字典词袋的生成,若未达到则继续聚类;每一个聚类中心即为字典中的一个单词。
所述步骤(3)具体包括:
(3.1)对于图片数据集中图片经过筛选得到的单词通过tf-idf相似度计算划分权值:
其中,idfi表示字典中某聚类中心叶子节点即单词ωi中特征数量ni相对于所有特征数量n的比值,表示某单词在字典中出现的频率;
tfi表示某特征在一张图片中出现的频率,n为该图片中出现单词的总个数,ni为单词ωi在该图片中呈现的次数;进而可得ωi在字典中的权重为:
ηi=tfi×idfi
(3.2)在图片数据集中对任意一张图片i,通过对应的单词以及单词的权重构建向量
通过对比数据集中任两张图片的向量来比较两者的相似性:
若s(v1,v2)<ps,其中ps为相似度阈值,则在这两张图片中比较图片权重向量模值
(3.3)生成的字典中,对于单一目标物体,考虑其在周边环境中出现频率较高,对于检测到周边环境闭环的贡献较低,进行如下运算:
若有:ηi=tfi×idfi≤p
则:ηi=0
其中,p为可调整的单词权重阈值;通过对权值较低的单词进行归零化处理来提升字典对于闭环检测相似度计算的准确性。
所述步骤(4)具体包括:
(4.1)在应用改进字典模型的后端优化中,对于图像中的三维点p点,在单目的视觉slam系统中通过拥有7个自由度,即1个尺度因子、3个旋转角度和3个位移的三维点坐标以及位姿变化sim3相似变换群,在检测到闭环条件进行优化时,对其相似变换群进行优化;在应用改进字典模型的后端优化中相机检测到闭环并进行尺度相似变换后,进行闭环融合,融合重复的点云,在covisibilitygraph图优化中插入新的边以连接闭环;
(4.2)在应用改进字典模型的后端优化中发现闭环并进行后端优化后,对于相机的相对位姿与特征点空间位置进行基于局部集束调整(localbundleadjustment)的最优调整;
设相机在运动中对于周边环境的观测方程为zk,j=h(yj,xk,vk,j),其中,zk,j表示传感器于xk位置观测到路标yj时产生的观测数据,vk,j为噪声;由于噪声的存在并不完全成立,将观测误差写成:
ekj=z-h(yj,xk,vk,j)
将其他时刻的误差一并考虑进来,考虑最小二乘模型,则整体误差即代价函数为:
求解上式,对相机姿态和特征点空间位置做出最优调整。
有益效果:本发明提供了一种基于视觉slam拓展的室内场景下单一目标物体字典模型改进方案,为一些类别环境下的特定单一目标物体的同步定位与建图提供了较大的便利。以单一目标物体为例,对特定目标物体的特征创建字典,结合目标物体信息改进dbow2算法调整字典权重计算方式,将其应用到slam系统的回环检测中。首先对于相机进行基础标定,获得内参等信息后进行局部定位与建图工作,通过三维特征点得到未经过后端优化的点云地图;之后通过相机采集周边环境与单一目标物体相关的图片数据集,并利用dbow2库k-means++算法生成数据集对应的单词;针对单一目标物体生成的单词进行tf-idf相似度计算划分单词权值,根据对检测周边环境闭环贡献程度的高低设定阈值,对于与单一目标物体有关的部分单词进行归零化处理;最后将改进后的字典模型结合到slam系统的后端优化中,优化在室内场景下对于单一目标物体的回环检测的发现与点云地图的闭环融合,提高定位与建图精度。
附图说明
图1为本发明的方法流程示意图;
图2为相机相对位姿对极约束示意图;
图3为k-means++算法流程图:
图4为改进字典示意图。
具体实施方式
以下结合附图和具体实施例对本发明中的关键技术和具体实现方法进行详细说明。
如图所示为本发明的方法流程示意图。
步骤s1:对一台单目进行基础标定,获得内参等信息,同时通过视觉slam前端进行同步定位与建图。具体包括:
s1.1、以环境内的一张黑白棋盘格作为标定物,通过调整标定物与各个相机的方向,为标定物拍摄一些不同方向的照片,并从照片中提取棋盘格角点;
s1.2、设周边环境中某空间点p的相机坐标为[x,y,z]t,x,y,z分别为相机在三维空间立体坐标系中的坐标。那么在相机模型中根据三角形相似关系得到成像平面内对应成像点p′坐标为
s1.3、获得标定相机的内参后,使用相机并利用视觉slam软件前端对周边环境进行同时定位与建图。首先由相机拍摄得到关键帧序列设为{fkey},根据关键帧提取得到图像的特征点;其次通过前后两帧关键帧图像构建对极约束,如图2所示;其中,o1,o2是相机的光心,i1,i2是相机前后两帧拍摄到的图片,p是周围环境中相机在前后两帧共同观测到的一个特征点,分别投影在i1的p1点上和i2的p2点上,根据对极几何约束可以求解相机的位姿,具体过程如下:
设空间点p在相机o1下的坐标:
p=[x,y,z]
根相机模型,可以获得p1,p2的像素坐标:
其中,z1、z2为特征点p与相机的深度距离;k为相机的内参矩阵;r为相机在两帧间相对运动的3x3旋转矩阵;t为两帧间相对运动的3x1平移矩阵。通过矩阵间运算的求解,可以得到:
最后根据相机位姿的变化,通过对极几何约束与特征点投影对周边环境进行定位与建图。
步骤s2:根据单一目标物体的相关特征制作图片数据集,之后通过图片数据集利用dbow2库k-means++算法生成数据集对应的单词,为室内场景下视觉slam对单一目标物体建立的点云地图进行回环检测做准备。具体包括:
s2.1、使用相机拍摄包含单一目标物体的环境视频,并将视频转化为视频图像帧,构建初步的图片数据集。;
s2.2、在初步处理得到的图片数据集中,提取每幅图像帧的orb特征点,通过筛选具有代表性的图像帧即关键帧,降低数据集的容量,提升后续步骤中生成单词与进行回环检测的效率。筛选生成关键帧所满足的具体条件如下:
(1)若继上一次帅选得到关键帧后,又过了n1帧;
(2)当前无筛选得到的关键帧,或已有n2帧的图像帧被丢弃;
(3)当前图像帧帧处理得到大于m个orb特征点;
(4)当前图像帧特征点与前一关键帧的相似度不超过s;
s2.3、通过图片数据集利用dbow2库k-means++算法生成数据集对应的单词。其方法为在每张关键帧图片中随机选取一个特征为初始聚类中心,通过计算图片中每一个特征点与当前已有聚类中心的最短距离d(x)来进一步得到每个特征点被选为下一个聚类中心的概率p(x)。之后按照轮盘法则选择下一个聚类中心,若聚类中心数量达到设定的阈值k则完成字典词袋的生成,若未达到则继续聚类。每一个聚类中心即为字典中的一个单词。
步骤s3:针对单一目标物体生成的单词进行tf-idf相似度计算划分单词权值,根据对检测周边环境闭环贡献程度的高低设定阈值,对于与单一目标物体有关的部分单词进行归零化处理。具体包括:
s3.1、对于图片数据集中图片经过筛选得到的单词通过tf-idf相似度计算划分权值。
其中,idfi表示字典中某聚类中心叶子节点即单词ωi中特征数量ni相对于所有特征数量n的比值,简而言之即为某单词在字典中出现的频率;
tfi表示某特征在一张图片中出现的频率,n为该图片中出现单词的总个数,ni为单词ωi在该图片中呈现的次数。
进而可得ωi在字典中的权重为
ηi=tfi×idfi
s3.2、在图片数据集中对任意一张图片i,通过对应的单词以及单词的权重构建向量
通过对比数据集中任两张图片的向量来比较两者的相似性:
若s(v1,v2)<ps,其中ps为相似度阈值,则在这两张图片中比较图片权重向量模值
s3.3、生成的字典中,对于单一目标物体,考虑其在周边环境中出现频率较高,对于检测到周边环境闭环的贡献较低,故可以进行如下运算:
若有:ηi=tfi×idfi≤p
则:ηi=0
其中p为可调整的单词权重阈值。通过对权值较低的单词进行归零化处理来提升字典对于闭环检测相似度计算的准确性。如图4所示为改进后生成的字典,
图中每一行起始数字为节点的编号;中间数字为orb特征向量,txt文件中为十进制显示,格式为cv_8u;每一行最后一个单精度浮点数即表示该节点单词的权重。
步骤s4:将改进后的字典模型结合到slam系统的后端优化中,通过对点云地图点在图像帧上的投影与实际像素坐标进行最小化投影误差,优化在室内场景下对于单一目标物体的回环检测的发现与点云地图的闭环融合,提高定位与建图精度。具体包括:
s4.1、在应用改进字典模型的后端优化中,对于图像中的三维点p点,在单目的视觉slam系统中通过拥有7个自由度,即1个尺度因子、3个旋转角度和3个位移的三维点坐标以及位姿变化sim3相似变换群,在检测到闭环条件进行优化时,对其相似变换群进行优化。在应用改进字典模型的后端优化中相机检测到闭环并进行尺度相似变换后,进行闭环融合,融合重复的点云,在covisibilitygraph图优化中插入新的边以连接闭环。
s4.2、在应用改进字典模型的后端优化中发现闭环并进行后端优化后,对于相机的相对位姿与特征点空间位置进行基于局部集束调整(localbundleadjustment)的最优调整。
设相机在运动中对于周边环境的观测方程为zk,j=h(yj,xk,vk,j),其中zk,j表示传感器于xk位置观测到路标yj时产生的观测数据,vk,j为噪声。由于噪声的存在并不完全成立,观测误差可写成:
ekj=z-h(yj,xk,vk,j)
将其他时刻的误差一并考虑进来,考虑最小二乘模型,则整体误差即代价函数为:
通过对该式的求解,即可对相机姿态和特征点空间位置做出最优调整。
如表1所示为改进字典模型的orb-slam2算法与未改进字典模型orb-slam2算法在针对单一目标物体电脑的自制数据集中各项数据的对比:
表1
- 还没有人留言评论。精彩留言会获得点赞!