基于人体骨架和运动信号特征的暴力行为检测系统及方法与流程
本发明涉及视频图像处理技术,具体涉及一种基于人体骨架和运动信号特征的暴力行为检测系统及方法。
背景技术
随着监控系统的大量使用,视频数据出现爆发性的增长。监控系统的作用是进行目标检测以及异常行为检测。随着数据的急剧增长,传统的依靠人工监控的方式已愈发困难,且效率低下。因此,依靠人工智能的监控系统的研究成为了热点。其中,对于人的暴力行为的检测是非常重要的研究方向。
由于暴力行为的动作比起简单的跑、跳行为要复杂很多,所以如何进行暴力行为检测也是相关研究的难点。目前,传统的暴力行为检测主要是采用基于人工设计特征的方法,虽然识别准确率较高,但是也具有某些缺陷,比如:不能达到实时的效果,易受噪声的影响等。
技术实现要素:
本发明所要解决的技术问题是:提出一种基于人体骨架和运动信号特征的暴力行为检测系统及方法,提高检测的实时性和准确性,且能适应多种不同的监测环境。
本发明解决上述技术问题所采用的技术方案是:基于人体骨架和运动信号特征的暴力行为检测系统,包括:运动区域提取模块、运动类型分类模块、运动信号统计模块和图像预测模块;
所述运动区域提取模块,用于按一定时间间隔连续提取3帧;然后根据相邻两帧的帧差求取人体骨架的关键部位像素的位移向量,提取其中运动的像素,并进行运动区域划分;
所述运动类型分类模块,用于根据每张图中的运动区域数量和方向对运动类型进行分类;
所述运动信号统计模块,用于计算每个运行类型分类下图片的运动信号的统计量;
所述图像预测模块,用于将运动信号的统计量作为特征输入到训练好的svm模型中进行暴力行为的预测。
作为进一步优化,所述运动区域提取模块采用k-means聚类方法进行运动区域的划分。
作为进一步优化,所述运动类型分类模块将运动类型分为:单运动区域、多运动区域同向和多运动区域不同向三类。
作为进一步优化,所述运动信号统计模块计算的运动信号的统计量包括:分别计算幅度、加速度、关联度的最大值、最小值、均值、中值和标准差。
作为进一步优化,所述运动区域提取模块、运动类型分类模块、运动信号统计模块和图像预测模块均被部署于同一个服务器中;或者,运动区域提取模块、运动类型分类模块和运动信号统计模块被部署于同一个服务器中,所述图像预测模块被部署于另一个服务器中。
此外,本发明还提供了一种基于人体骨架和运动信号特征的暴力行为检测方法,其包括以下步骤:
a.按一定时间间隔连续提取3帧,然后根据相邻两帧的帧差求取人体骨架的关键部位像素的位移向量,提取其中运动的像素,并进行运动区域划分;
b.根据每张图中的运动区域数量和方向对运动类型进行分类;
c.计算每个运行类型分类下图片的运动信号的统计量;
d.将运动信号的统计量作为特征输入到训练好的svm模型中进行暴力行为的预测。
作为进一步优化,步骤a中,采用k-means聚类方法进行运动区域的划分。
作为进一步优化,步骤b中,所述运动类型分为:单运动区域、多运动区域同向和多运动区域不同向三类。
作为进一步优化,步骤c中,所述运动信号的统计量的计算方法包括:
根据公式
根据公式a(t)=|m(t)-m(t-1)|,计算出图的加速度a;
根据公式
作为进一步优化,步骤c中,运动信号的统计量包括:幅度、加速度、关联度的最大值、最小值、均值、中值和标准差。
本发明的有益效果是:
基于人体骨架与运动信号特征,对输入的视频流进行运动分析,监控到打架斗殴暴力事件时,立马触发报警装置进行报警,管理人员则可以第一时间获得通知,并进行相应的处理,具有实时性;
由于基于人体骨架,对人体关键部位进行运动分析,并且把运动像素的运动幅度、加速度、区域关联度三种运动信号的统计量作为最终特征信息进行预测分析,从而提高预测的准确性。
附图说明
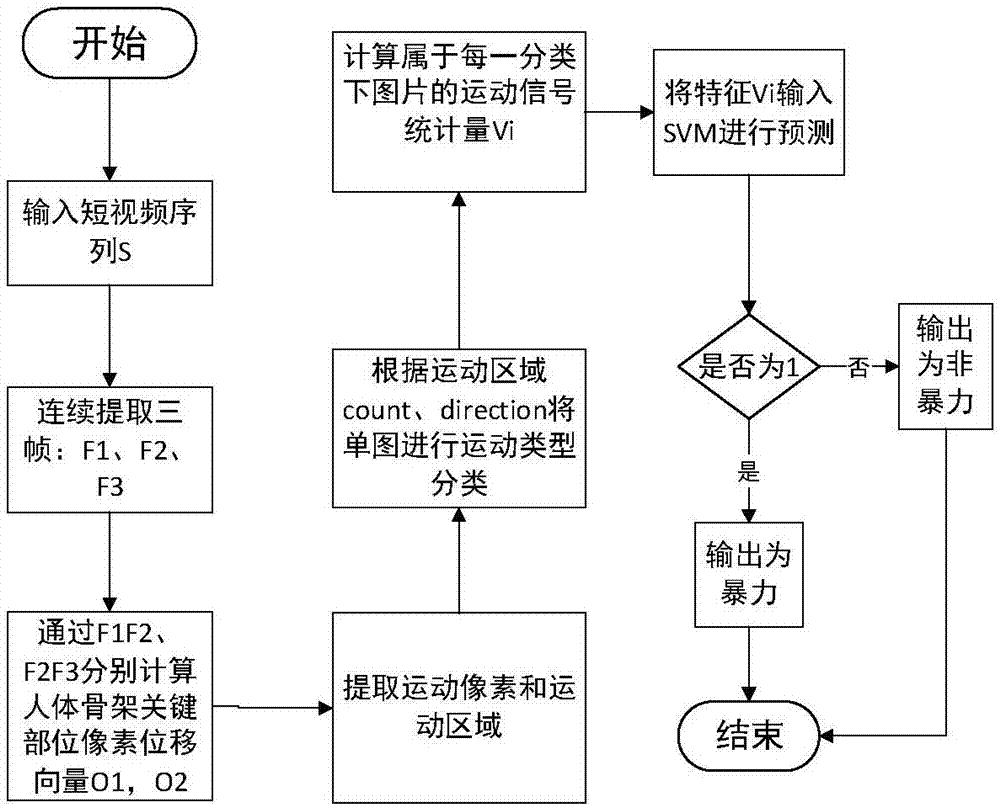
图1为本发明中的暴力行为检测方法流程图;
图2为实施例1中的暴力行为检测系统在集中式处理场景应用示意图;
图3为实施例2中的暴力行为检测系统在分布式处理场景应用示意图。
具体实施方式
本发明旨在提出一种基于人体骨架和运动信号特征的暴力行为检测系统及方法,提高检测的实时性和准确性,且能适应多种不同的监测环境。其通过输入一段短视频序列,依次经过运动区域提取、运动类型分类、计算运动信号统计量和图像预测来检测是否出现暴力事件。其中,在运动区域提取时,基于人体骨架,对人体关键部位进行运动分析,在计算运动信号统计量时,把运动像素的运动幅度、加速度、区域关联度三种运动信号的统计量作为最终特征信息输入至svm模型中。
为便于理解,首先对本发明中可能出现的技术名词进行解释:
1.视频帧:视频都是由静止的画面组成的,这些静止的画面被称为帧。一般来说,帧率低于15帧/秒,连续的运动视频就会有停顿的感觉。我国采用的是电视标准pal制,它规定视频25帧/秒(隔行扫描方式),每帧625个扫描行。帧数越多数据量越大,所以有时为了减少数据量而减慢了帧速,例如只有16帧每秒,可达到一定的满意程度,但是效果略差。
2.人体骨架:人体共有206块骨骼,分为颅骨、躯干骨和四肢骨3个大部分。其中,有颅骨29块、躯干骨51块、四肢骨126块。
3.运动幅度:是指身体或某一部分在一定的基准点距离或角度(可用测量的度数、尺度和线段单位来确定或表示)之间移动的值。它所表现的空间特征则决定于运动动作的任务和要求,肌肉群的数量,肌纤维的弹性及关节的灵活性。
本发明中的基于人体骨架和运动信号特征的暴力行为检测系统,包括:运动区域提取模块、运动类型分类模块、运动信号统计模块和图像预测模块;
所述运动区域提取模块,用于按一定时间间隔连续提取3帧;然后根据相邻两帧的帧差求取人体骨架的关键部位像素的位移向量,提取其中运动的像素,并进行运动区域划分;
所述运动类型分类模块,用于根据每张图中的运动区域数量和方向对运动类型进行分类;
所述运动信号统计模块,用于计算每个运行类型分类下图片的运动信号的统计量;
所述图像预测模块,用于将运动信号的统计量作为特征输入到训练好的svm模型中进行暴力行为的预测。
在具体部署时,所述运动区域提取模块、运动类型分类模块、运动信号统计模块和图像预测模块可以被部署于同一个服务器中;或者,运动区域提取模块、运动类型分类模块和运动信号统计模块被部署于同一个服务器中,图像预测模块被部署于另一个服务器中。
基于上述检测系统,本发明实现的检测方法如图1所示,其包括以下实现步骤:
1、输入短视频序列s;
本步骤中,短视频序列来源于摄像头拍摄的待检测分析的监控视频。
2、连续提取三帧:
本步骤中,可以根据设置的帧间隔连续提取三帧图像f1、f2、f3。
3、计算人体骨架关键部位位移向量:
本步骤中,可以根据相邻两帧的帧差f1f2、f2f3求取人体骨架的关键部位像素的位移向量o1和o2。
4、提取运动像素和运动区域:
本步骤中,提取位移向量中的运动的像素,并采用k-means聚类方法进行运动区域划分。
5、对单图进行运动类型分类:
本步骤中,针对每一张图,根据运动区域的个数和方向将其进行分类,可分为单运动区域、多运动区域同向和多运动区域不同向三类。
6、计算每一个分类的图片的运动信号统计量:
本步骤中,计算每一个分类的图片的幅度、加速度、关联度的最大值、最小值、均值、中值和标准差。
7、将特征输入svm进行预测:
本步骤中,将运动信号统计量作为特征量输入至预先训练好的svm模型中进行预测,并输出结果:若svm预测结果为1,则表示视频为含暴力行为的视频,若svm预测结果为0,则表示视频为不含暴力行为的视频。
实施例1:
本实施例描述的场景是:四个模块都部署在检测服务器上,摄像头一直负责视频流的采集,周期性地将预测结果存入数据库中,客户端则采用轮询的方式去检查是否有暴力事件的发生。参照图2,具体步骤包括:
首先摄像头实时的采集视频流,并且缓存在本地。
检测服务器中的模块一(运动区域提取模块)进行人体骨架的关键部位的运动像素与运动区域的提取,该模块的主要步骤有:
根据预先设置的帧间隔连续地提取三帧f1、f2、f3;
通过f1f2得到出人体骨架的关键运动特征点的位移向量集合o1,通过f2f3得到位移向量集合o2;
因为位移向量不为0,则该像素为运动像素。提取其中的运动像素,并采用聚类方法将运动像素进行运动区域划分;
模块二(运动类型分类模块)根据运动区域的数目和方向将图进行分类:一个单运动区域、两个多运动区域同向、两个多运动区域反向。
模块三(运动信号统计模块)分别计算运动信号,即幅度、加速度、关联度的最大值、最小值、中值,标准差;
根据公式
根据公式a(t)=|m(t)-m(t-1)|,计算出图的加速度a;
根据公式
分别计算视频流的幅度、加速度、关联度的最大值、最小值、均值、中值、标准差,得到最终特征v。
模块四(图像预测模块)将获得的运动信号统计向量v作为特征向量,通过预先训练好的svm模型进行预测,并且输出相应的预测结果。svm提前通过大量样本进行训练。
经过上述一系列的处理步骤之后,检测服务器将检测到的暴力事件存入数据库中。在该实施例中,由于四个模块都部署在同一个服务器中,处理速度相对较慢,适用于一些对实时性要求不是很高的公共场所,比如:街道等。
最后客户端将采用轮询的方式查询数据库,检测一段时间内是否发生暴力行为。如果检测到暴力行为,管理员将通知该地区的值班人员去相应的地点进行查看。
实施例2:
本实施例描述的场景是:模块一、模块二和模块三都部署在同一视频流服务器上,而模块四部署在单独的检测服务器上。摄像头一直负责视频流的采集,视频流服务器主要是完成前三个模块,处理起来比较耗时,因此单独部署。检测服务器则集中进行预测,这样能够将耗时模块单独分离出来,从而提高整个系统的处理能力。最后客户端采用轮询的方式去检查是否有暴力事件的发生。参照图3,具体步骤如下:
首先摄像头实时的采集视频流,并且缓存在本地。
视频流服务器中的模块一(运动区域提取模块)进行运动像素与运动区域的提取,该模块的主要步骤有:
根据预先设置的帧间隔连续地提取三帧f1、f2、f3;
通过f1f2得到出人体骨架的关键运动特征点的位移向量集合o1,通过f2f3得到位移向量集合o2;
因为位移向量不为0,则该像素为运动像素。提取其中的运动像素,并采用聚类方法将运动像素进行运动区域划分;
模块二(运动类型分类模块)根据运动区域的数目和方向将单图进行分类:一个运动区域、两个运动区域同向、两个运动区域不同向。
模块三(运动信号统计模块)分别计算运动信号,即幅度、加速度、关联度的最大值、最小值、中值,标准差;
根据公式
根据公式a(t)=|m(t)-m(t-1)|,计算出单图的加速度a;
根据公式
分别计算视频流的幅度、加速度、关联度的最大值、最小值、均值、中值、标准差,得到最终特征集合v。
视频流服务器计算得到特征集合v后,立即上传给检测服务器;
检测服务器将接收来自多个视频流服务器的特征集合v,然后利用模块四(图像预测模块)通过训练好的svm模型进行预测,并且输出相应的预测结果。svm提前通过大量样本进行训练。
经过上述一系列的处理步骤之后,检测服务器将检测到的暴力事件存入数据库中。在该实施例中,由于前两个耗时模块单独分离出来部署,能够提升整个系统的处理能力,适用于一些对实时性要求高的特殊场所,比如:看守所等。
最后客户端将采用轮询的方式查询数据库,检测一段时间内是否发生暴力行为。如果检测到暴力行为,管理员将通知该地区的值班人员去相应的地点进行查看。
在上述两种实施例方案中,数据库对检测结果的存储方式参见下表:
基于人体骨架和运动信号特征的暴力行为检测存储表
该表总共有六个字段,分别为:
id,即序号,用以标识检测的视频流的编号;
timestamp,即时间戳,用以标识对视频流进行暴力行为检测的时间;
roomid,即仓室的序号,用以标识摄像头所处区域或房间的编号;
cameraid,即摄像头id,用以标识视频流来源的摄像头的编号;
motionsig_statistic,即运动信号统计量,由人体骨架特征的运动信号计算统计获得,用以作为预测模型的输入;
isviolent,即是否为暴力,用以标识视频流的暴力行为检测结果,为1表示视频流含有暴力行为,为0表示视频流不含暴力行为。
在客户端轮询上述存储表时根据roomid和cameraid查询对应某个摄像头的视频流的暴力行为检测结果,根据isviolent字段的值来判断是否存在暴力行为,若isviolent字段的值为1则表示有暴力行为,将自动触发相应报警装置,管理员可以通知相应地区的值班人员前往相应地点进行查看和处理。
由于上述存储表记录了每次针对视频流计算出来的运动信号统计量motionsig_statistic和暴力行为检测结果isviolent,我们的svm模型可以从数据库中提取大量的历史数据进行训练,即不断丰富svm模型的训练样本,从而使svm预测越来越准确。
- 还没有人留言评论。精彩留言会获得点赞!