一种结合表情识别的智能终端人脸解锁方法与流程
本发明涉及智能屏幕解锁技术领域,具体而言,尤其涉及一种结合表情识别的智能终端人脸解锁方法。
背景技术:
在《2017-2022年中国智能手机市场供需预测及投资战略研究报告》指出,我国智能手机普及率已高达58%,智能手机己经成为人们购物交流、学习工作、上网冲浪的重要渠道。手机里存储了用户大量的隐私数据,如照片视频、办公文件、消费记录、医疗健康等数据,这些数据如果泄露必然会导致个人工作生活甚至经济财产的损失。而手机作为便携性设备很容易遗失或被他人窃取。因此,如何防止手机中敏感信息的泄露成为目前研究的热点。
当前保护手机中隐私数据最常用的方法是身份认证。传统的认证方案都是基于知识的,如pin码认证方案和九宫格图案密码认证方案。但基于知识的认证方法是脆弱的,用户需要在终端上输入密码或者绘制图案,这样解锁速度慢、交互性差而且很容易被他人查看并记录。
为此,基于生物特征的认证方式,如指纹解锁与人脸解锁等得到越来越多的应用。指纹解锁利用指纹的唯一性和永久性,把一个人同他的指纹特征对应起来。但在某些特定的场景下解锁成功率较低,比如手掌有水渍或者汗液比较多时容易解锁失败。
人脸解锁是通过人脸识别或人脸验证技术进行权限管理的一种手段,终端系统可以利用人脸这一生物特征作为权限保护的密码。现有的人脸解锁系统,大多采用如图1所示的框架。首先离线采集某权限用户的若干人脸图像,经过预处理和特征提取后建立该用户的人脸特征库;当具备多个权限用户时,会对每个用户建立单独的特征库;在线解锁时,采集到用户的图像信息,再经过人脸检测和特征提取后,在预先建立的人脸特征库中检索,查找是否存在相似的数据。如果存在相似度大于某阈值(比如0.9)的数据,则认为识别成功,该用户具备权限,解锁成功;如果在库中找不到相似数据,则认为该用户不具备权限,解锁失败。
现有技术中可以实现基于人脸的权限管理,但是仍然存在安全性的漏洞:如果终端设备摄像头拍摄的不是真实的人脸,而是某权限用户的照片或视频,同样可以解锁成功。针对这一安全漏洞,目前主要采用如下处理措施:在现有人脸解锁框架的基础上,加入了眨眼检测机制。即:在解锁过程中,会在屏幕上提示用户做相应的眨眼动作等,如果没有检测到被拍摄人脸的眨眼动作,则认为拍摄的可能是照片,解锁失败。同时,如若解锁成功也仅仅可以避免利用静止照片来解锁的问题。但是还没有解决利用视频或者动态图片等录制人脸信息来破解的问题,也不能解决双胞胎或者长相相似或者经过化妆伪装的人之间的解锁,仍然具有很大的安全隐患。
技术实现要素:
根据上述提出解锁速度慢、交互性差而且很容易被他人查看并记录的技术问题,而提供一种结合表情识别的智能终端人脸解锁方法。本发明主要在人脸检测的基础上加入表情的检测,从而起到大大提高检测的准确性及安全性。
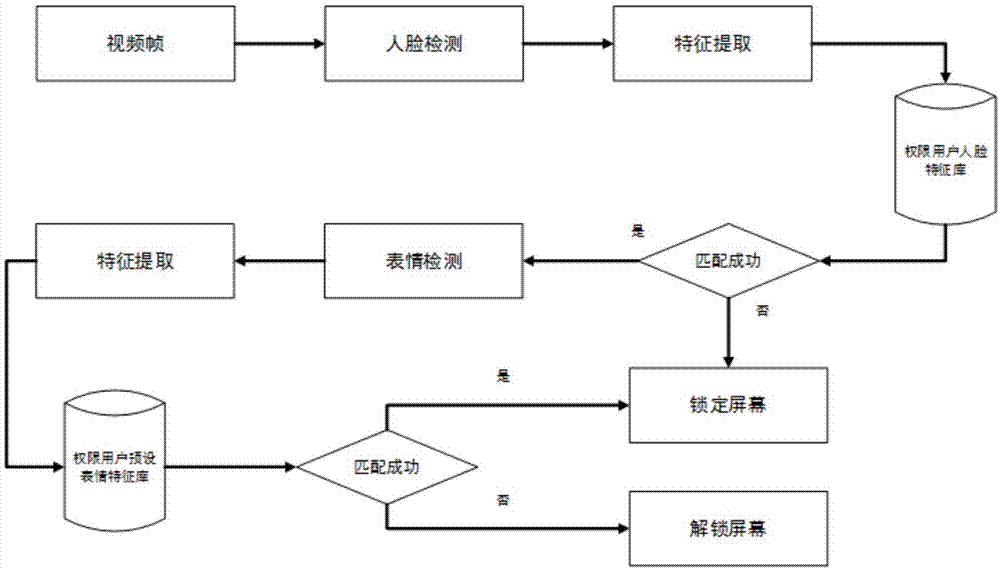
本发明提出一种结合表情识别的智能终端人脸解锁方法,其特征在于,至少包括以下步骤:
s1:根据摄像单元采集到人脸视频图像p,采用灰度投影方法定位人眼瞳孔位置,并通过瞳孔距离对人脸视频图像p进行尺寸归一化处理,得到归一化处理后的人脸视频图像p′;
s2:对所述归一化处理后的人脸视频图像p′,使用基于haar特征的adaboost算法对采集得到的视频中的人脸视频图像p″进行检测,得到所述算法处理后的人脸视频图像p″;
s3:对所述检测到的人脸图像p″经过滤波处理、特征提取、特征降维进行人脸识别,最后将所述降维处理后得到的特征采用支持向量机svm进行分类识别;
s4:若识别成功,则执行步骤s6;否则,执行步骤s5;
s5:将人脸检测错误计数+1;当人脸检测错误计数小于设定阈值x时,则执行步骤s1;当人脸检测错误计数等于阈值x时,屏幕锁定;
s6:对所述摄像单元采集得到的人脸视频图像p进行纹理特征提取,获得用户表情程度最大化的表情关键帧,执行步骤s7;
s7:对获取的表情关键帧图像使用基于haar特征的adaboost算法检测出人脸视频图像p″′,再对所述人脸视频图像p″′进行表情特征提取均匀模式lbp纹理特征与分类识别;
s8:若所述识别后的结果与用户预设表情匹配,则屏幕解锁;否则执行步骤s9;
s9:将表情检测错误计数+1,当表情检测错误计数器小于设定阈值y时,执行步骤s6;当表情检测错误计数等于阈值y时,锁定屏幕。
进一步的,所述步骤s6中通过纹理特征参数值对应视频帧的变化曲线进行提取;
取所述人脸视频图像p″(n×n)中任意一点(x,y)及偏离它的另一点(x+a,y+b),则得到任意方向及其对应的距离,则所述人脸图像p的图像矩阵f中灰度为i和j的两个像素沿所述定义的方向和距离同时出现的次数为p(i,j),总像素对为n,则矩阵
则逆差矩阵为:
当逆差矩为最小值时,图像纹理变化为最大,则获得用户表情程度最大化的表情关键帧。
进一步的,纹理特征参数值对应视频帧的变化曲线归一化的线性函数转换表达式如下:
其中,x和y分别表示转换前后的线性函数值,maxvalue、minvalue分别表示样本的最大值和最小值,则曲线的谷点为表情关键帧。
进一步的,所述基于haar-like特征的adaboost检测算法:首先通过积分图提取haar-like特征;进而使用adaboost算法迭代获得最能够表征人脸的矩形特征,通过加权投票将弱分类器组成强分类器;再将强分类器组成级联分类器,设置每个节点分类器的阈值,识别人脸图像。
进一步的,所述人脸图像p还需要进行图像的预处理;
首先将所述人脸图像p进行彩色图像灰度化;进而将经检测出的人脸图像经过几何校正,尺寸归一化预处理后将人脸图像归一化处理128像素×128像素的图像;再采用直方图均衡化处理人脸图像,去除光照。
更进一步的,所述直方图均衡化处理是对图像进行非线性拉伸,重新分配图像像素值,使相似灰度范围内的像素数量相同。
所述直方图均衡化公式为:
pr(rk)=rk/n,0≤rk≤;k=0,1,2,3....,l-1
其中,n表示像素的总数,k表示灰度级总数,rk表示第k个灰度级值,则均衡化变换函数为:
其中,nj表示灰度值为j的总像素数,pr(rj)表示灰度值为j的像素比例。
进一步的,所述人脸表情特征提取通过对归一化后的人脸图像提取表情图像的均匀模式lbp纹理特征;
原始lbp算子定义在像素3像素*3像素的邻域内,以邻域中心像素为阈值,相邻的8个像素的灰度值与邻域中心的像素值进行比较,若周围像素大于中心像素值,则该像素点的位置被标记为1,若周围像素小于或等于中心像素值,则该像素点的位置被标记为0。
所述原始lbp算子公式为:
其中,
更进一步的,所述灰度投影方法定位人眼瞳孔位置还包括以下步骤:
s11:根据人脸的五官位置设人脸视频图像p的高度为h,宽度为w,取左上角点为原点,取两眼窗的起始坐标为:左眼
s12:对窗内区域内的人脸视频图像p做直方图分析,取灰度值为像素的5%进行阈值分割;
s13:将窗内图像做水平投影确定眼睛的纵坐标,投影函数为:
其中,i(x,y)表示第x行的灰度投影值,x表示人脸视频图像p的第x行;
s14:将窗内图像做垂直投影确定眼睛的横坐标,投影函数为:
其中,i(x,y)表示第x行的灰度投影值,x表示人脸视频图像p的第x行。
较现有技术相比,本发明具有以下优点:
1、本发明提出了一种结合表情识别的智能终端人脸解锁方法。该方法综合采用人脸和表情等视觉识别先进技术,提高了人脸解锁的复杂程度。
2、本发明在智能终端解锁时加入了权限用户的脸部表情,需要解锁终端的用户做出相应的表情动作,而由于他人并不知道权限用户的表情动作,极大地降低利用了视频或者动态图片等录制人脸等方法破解终端的成功率。
3、本发明在智能终端解锁时加入了权限用户的脸部表情,即使是双胞胎或者长相相似的人,在不知道特定的表情动作的前提下,也无法解锁屏幕。
综上,应用本发明的技术方案能够良好的解决屏幕解锁安全性以及无法识别动态图片的问题。因此,本发明的技术方案解决了现有技术中的问题。基于上述理由本发明可在屏幕解锁或其他解锁安全设备的解锁等领域广泛推广。
附图说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图做以简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动性的前提下,还可以根据这些附图获得其他的附图。
图1为本发明一种结合表情识别的智能终端人脸解锁方法的整体流程示意图。
图2(1)-(4)分别为本发明一种结合表情识别的智能终端人脸解锁方法的训练正常表情、高兴、恐惧、惊奇表情的示意图。
图3(1)-(3)为本发明一种结合表情识别的智能终端人脸解锁方法的训练悲伤、愤怒、厌恶表情的示意图。
图4为本发明一种结合表情识别的智能终端人脸解锁方法的整体流程示意图。
具体实施方式
为了使本技术领域的人员更好地理解本发明方案,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分的实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都应当属于本发明保护的范围。
需要说明的是,本发明的说明书和权利要求书及上述附图中的术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序。应该理解这样使用的数据在适当情况下可以互换,以便这里描述的本发明的实施例能够以除了在这里图示或描述的那些以外的顺序实施。此外,术语“包括”和“具有”以及他们的任何变形,意图在于覆盖不排他的包含,例如,包含了一系列步骤或单元的过程、方法、系统、产品或设备不必限于清楚地列出的那些步骤或单元,而是可包括没有清楚地列出的或对于这些过程、方法、产品或设备固有的其它步骤或单元。
如图1-4所示为一种结合表情识别的智能终端人脸解锁方法,至少包括以下步骤:
在本实施方式中,步骤s1:根据摄像单元采集到人脸视频图像p,采用灰度投影方法定位人眼瞳孔位置,并通过瞳孔距离对人脸视频图像p进行尺寸归一化处理,得到归一化处理后的人脸视频图像p′。可以理解为在其它实施方式中的视频图像也可以不进行归一化处理,只要能够将视频图像整合便于计算处理即可。
作为优选的实施方式,人脸图像p还需要进行图像的预处理;首先将人脸图像p进行彩色图像灰度化;进而将经检测出的人脸图像经过几何校正,尺寸归一化预处理后将人脸图像归一化处理128像素×128像素的图像;再采用直方图均衡化处理人脸图像,去除光照。
在本实施方式中,灰度投影方法定位人眼瞳孔位置还包括以下步骤:步骤s11:根据人脸的五官位置设人脸视频图像p的高度为h,宽度为w,取左上角点为原点,取两眼窗的起始坐标为:左眼
作为优选的实施方式步骤s12:对窗内区域内的人脸视频图像p做直方图分析,取灰度值为像素的5%进行阈值分割。可以理解为在其它的实施方式中,灰度值的取值可以按照实际情况进行选择。
作为优选的实施方式步骤s13:将窗内图像做水平投影确定眼睛的纵坐标,投影函数为:
其中,i(x,y)表示第x行的灰度投影值,x表示人脸视频图像p的第x行。
作为优选的实施方式步骤s14:将窗内图像做垂直投影确定眼睛的横坐标,投影函数为:
其中,i(x,y)表示第x行的灰度投影值,x表示人脸视频图像p的第x行。
作为优选的实施方式,步骤s2:对归一化处理后的人脸视频图像p′,使用基于haar特征的adaboost算法对采集得到的视频中的人脸视频图像p″进行检测,得到算法处理后的人脸视频图像p″。
在本实施方式中,直方图均衡化处理是对图像进行非线性拉伸,重新分配图像像素值,使相似灰度范围内的像素数量相同。
直方图均衡化公式为:
pr(rk)=rk/n,0≤rk≤;k=0,1,2,3,....,l-1
其中,n表示像素的总数,k表示灰度级总数,rk表示第k个灰度级值,则均衡化变换函数为:
其中,nj表示灰度值为j的总像素数,pr(rj)表示灰度值为j的像素比例。
作为优选的实施方式步骤s3:对检测到的人脸图像p″经过滤波处理、特征提取、特征降维进行人脸识别,最后将降维处理后得到的特征采用支持向量机svm进行分类识别。
在本实施方式中,对检测到的人脸图像进行中值滤波处理,可以有效的消除图像中的长尾噪声,例如负指数噪声和椒盐噪声。
其中,在本实施方式中,中值滤波公式:
g=med{f(x-1,y-1),f(x,y-1),f(x+1,y-1),f(x-1,y),f(x,y),f(x+1,y),f(x-1,y+1),f(x,y+1),f(x+1,y+1)}
其中,med表示取括号里的中值,f(x,y)表示点(x,y)的像素值。
进一步的在本实施方式中,提取局部二值模式lbp特征;
lbp公式为:
其中
进一步的在本实施方式中步骤s4:若识别成功,则执行步骤s6;否则,执行步骤s5;
作为优选的实施方式,步骤s5:将人脸检测错误计数+1;当人脸检测错误计数小于设定阈值x时,则执行步骤s1;当人脸检测错误计数等于阈值x时,屏幕锁定;
作为优选的实施方式,s6:对摄像单元采集得到的人脸视频图像p进行纹理特征提取,获得用户表情程度最大化的表情关键帧,执行步骤s7。
在本实施方式中,步骤s6中通过纹理特征参数值对应视频帧的变化曲线
则逆差矩阵为:
当逆差矩为最小值时,图像纹理变化为最大,则获得用户表情程度最大化的表情关键帧。
纹理特征参数值对应视频帧的变化曲线归一化的线性函数转换表达式如下:
其中,x和y分别表示转换前后的线性函数值,maxvalue、minvalue分别表示样本的最大值和最小值,则曲线的谷点为表情关键帧。
作为优选的实施方式,步骤s7:对获取的表情关键帧图像使用基于haar特征的adaboost算法检测出人脸视频图像p″′,再对人脸视频图像p″′进行表情特征提取均匀模式lbp纹理特征与分类识别;基于haar-like特征的adaboost检测算法:首先通过积分图提取haar-like特征;进而使用adaboost算法迭代获得最能够表征人脸的矩形特征,通过加权投票将弱分类器组成强分类器;再将强分类器组成级联分类器,设置每个节点分类器的阈值,识别人脸图像。可以理解为,在其它实施方式中,强分类器的训练方法还可以使用其他的方法只要能够满足能够将清楚的识别人脸图像即可。
作为优选的实施方式步骤s8:若识别后的结果与用户预设表情匹配,则屏幕解锁;否则执行步骤s9;所说的匹配是采用支持向量机svm的方法进行分类识别,svm会给出匹配结果。作为本实施方式的一种实施例,径向基核函数,惩罚因子c选取3,gamma参数g选取0.5。这些都是专业术语技术,而且很普遍。
作为优选的实施方式步骤s9:将表情检测错误计数+1,当表情检测错误计数器小于设定阈值y时,执行步骤s6;当表情检测错误计数等于阈值y时,锁定屏幕。
人脸表情特征提取通过对归一化后的人脸图像提取表情图像的均匀模式lbp纹理特征;
进一步的,作为优选的一种实施方式,还可以设置时间监测装置,设置时间x当采集时间超过时间则锁定屏幕。
上述本发明实施例序号仅仅为了描述,不代表实施例的优劣。
在本发明的上述实施例中,对各个实施例的描述都各有侧重,某个实施例中没有详述的部分,可以参见其他实施例的相关描述。
在本申请所提供的几个实施例中,应该理解到,所揭露的技术内容,可通过其它的方式实现。其中,以上所描述的装置实施例仅仅是示意性的,例如所述单元的划分,可以为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,单元或模块的间接耦合或通信连接,可以是电性或其它的形式。
所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。
另外,在本发明各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。上述集成的单元既可以采用硬件的形式实现,也可以采用软件功能单元的形式实现。
所述集成的单元如果以软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的全部或部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可为个人计算机、服务器或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。
最后应说明的是:以上各实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述各实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分或者全部技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的范围。
- 还没有人留言评论。精彩留言会获得点赞!